
设计贴合业务的高性能高可用中间件系统
一、单机高性能网络模型
1、传统网络模型
传统网络模型主要有PPC和TPC,以及PPC变种的prefork和TPC变种的prethread。
(1)PPC 和 prefork 示意:
PPC是Process per connection的缩写,即每个连接一个进程,顾名思义,来一个连接就需要fork一个进程;
prefork是 processes are forked before connection 的缩写。一个进程的创建成本非常高,而prefork是在PPC上的改进,就是提前创建几个进程,有连接进来后,直接使用创建好的进程。
PPC的缺点是 fork 代价高,性能低;父子进程通信要用 IPC(进程通信),因此监控统计等实现会比较复杂;另外OS 的上下文切换会限制并发连接数,一般并发数也就几百,搞了会造成频繁上下文切换。
案例:世界上第一个 Web 服务器 CERN;httpd 采用 PPC模式。Apache MPM prefork 模式,默认256个连接。
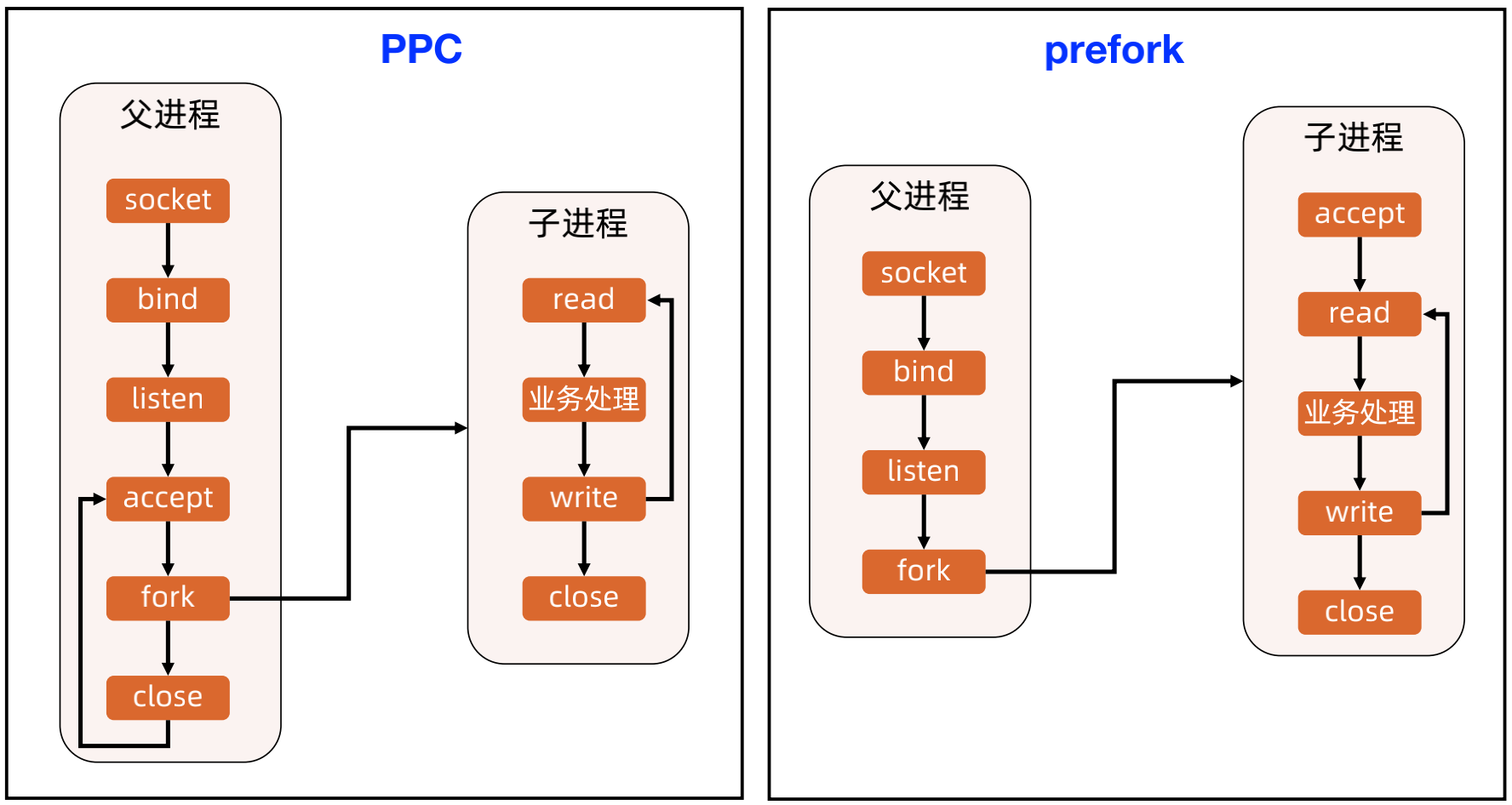
(2)TPC 和 prethread 示意
TPC是指 Thread per connection,也就是每个连接一个线程,顾名思义,来一个连接就要创建一个线程;
prethread是 thread are created before connectionde 的缩写,因为线程的创建成本也比较高高,而prethread的改进就是提前创建几个线程放入线程池,当有连接进来时,直接使用线程池中的连接。
优点:实现简单;无需 IPC,线程间通信即可;无需 fork,线程创建代价低。这主要是因为线程创建的代价要比进程创建的代价低,另外IPC通讯还是比较重的。
缺点:线程互斥和共享比 PPC/prefork 要复杂;某个线程故障可能导致整个进程退出;OS 的上下文切换会限制并发连接数,一般几百,但比 PPC/prefork 要多,有时可能达到一两千。
案例:Apache 服务器 MPM worker 模式就是 prethread模式的变种(多进程 + prethread),默认支持16(进程) × 25(线程)= 400 个并发处理线程。
这里Apache 将 prethread 改为多进程 + prethread,主要是因为如果使用一个进程多线程的情况,一旦出现了某个线程故障导致整个进程退出的情况就会造成特别严重的情况,因此才做了方案整合。
2、Reactor 网络模型
Reactor:基于多路复用的事件响应网络编程模型。
多路复用:多个连接复用同一个阻塞对象,例如 Java 的 Selector、epoll 的 epoll_fd(epoll_create 函数创建)。
事件响应:不同的事件分发给不同的对象处理,Java 的事件有 OP_ACCEPT、OP_CONNECT、OP_READ、OP_WRITE。
优缺点:实现比传统网络模型要复杂;可以支持海量连接。
分类:
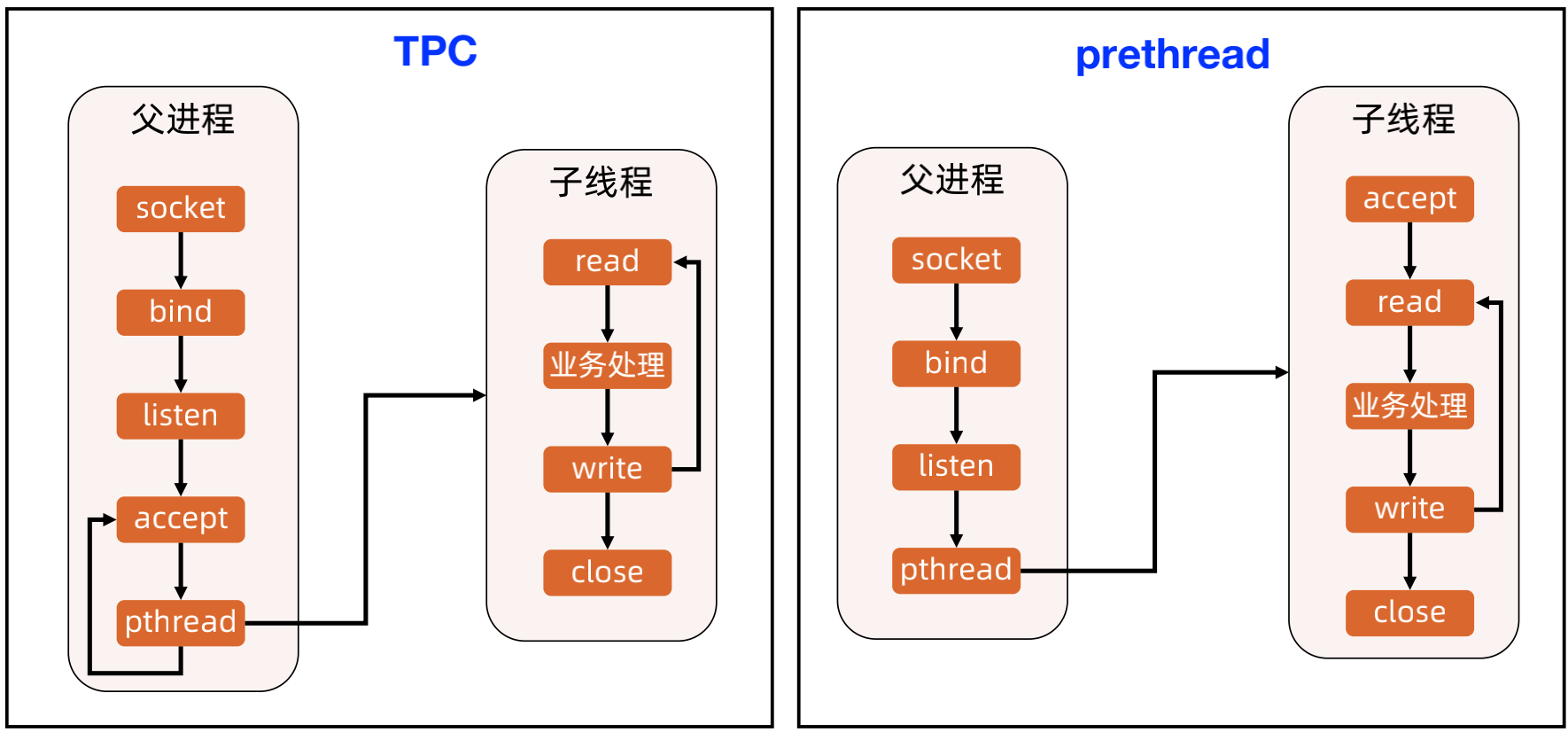
(1)Reactor 模式1 - 单 Reactor 单进程/单线程
优点:实现简单,无进程通信,无线程互斥和通信;无上下文切换,某些场景下性能可以做到很高。
缺点:只有一个进程,无法发挥多核 CPU 的性能;只能采取部署多个系统来利用多核 CPU,但这样会带来运维复杂度;Handler 在处理某个连接上的业务时,整个进程无法处理其他连接的事件,可能导致性能瓶颈。
案例:Redis。
步骤:
a、Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发。
b、如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件。
c、如果不是连接建立事件,则 Reactor 会调用连接对应的Handler(第2步中创建的 Handler)来进行响应。
d、Handler 会完成 read → 业务处理 → send的完整业务流程。
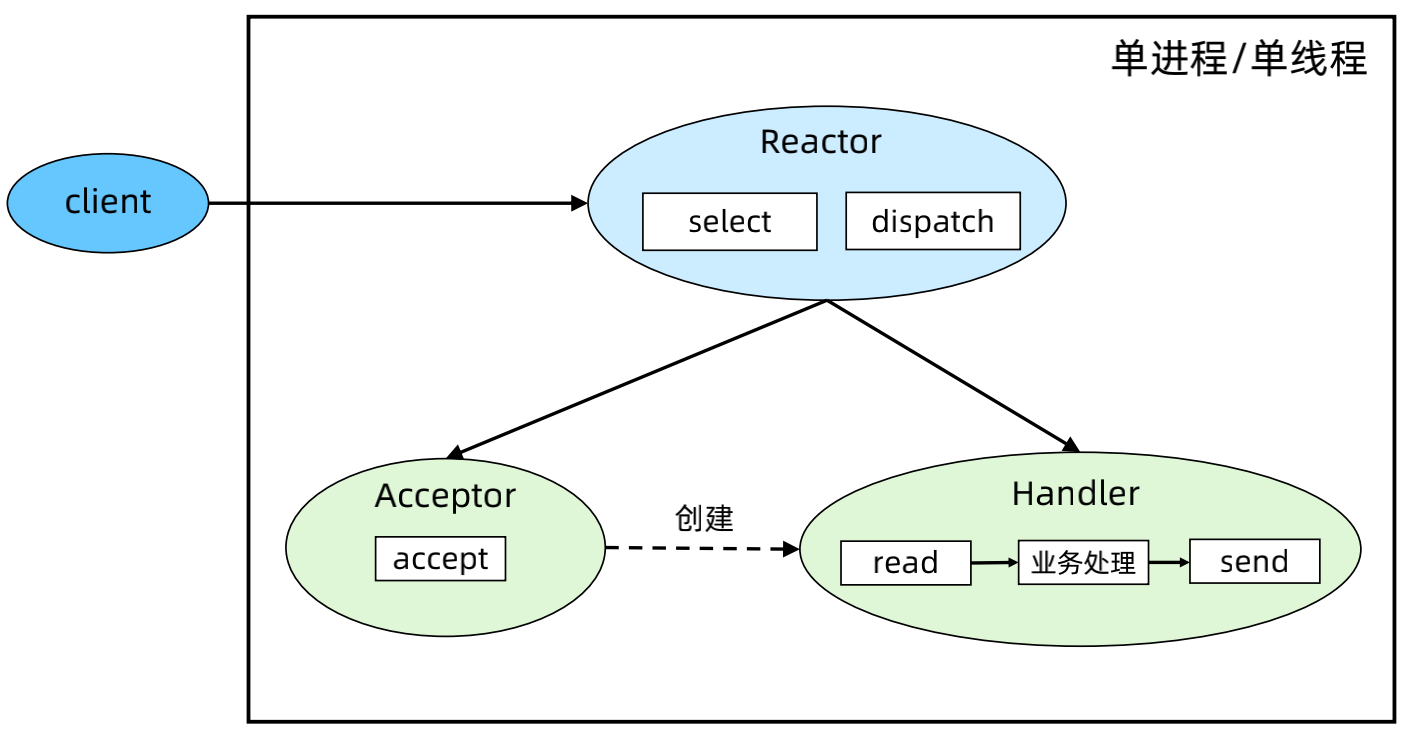
(2)Reactor 模式2 - 单 Reactor 多线程
优点:充分利用了多核 CPU 的优势,性能高。
缺点:多线程数据共享和访问比较复杂;Reactor 承担所有事件的监听和响应,只在主线程中运行,瞬时高并发时会成为性能瓶颈。
步骤:
a、主线程中,Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发。
b、如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件。
c、如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler(第2步中创建的 Handler)来进行响应。
d、Handler 只负责响应事件,不进行业务处理;Handler 通过 read 读取到数据后,会发给 Processor 进行业务处理。
e、Processor 会在独立的子线程中完成真正的业务处理,然后将响应结果发给主进程的 Handler 处理;Handler 收到响应后通过 send 将响应结果返回给 client。
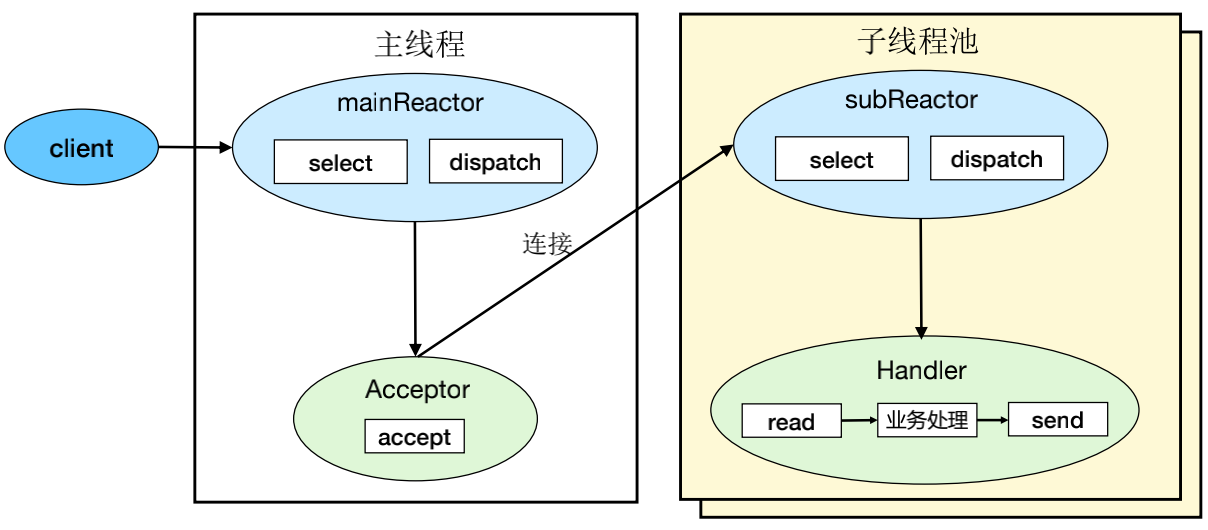
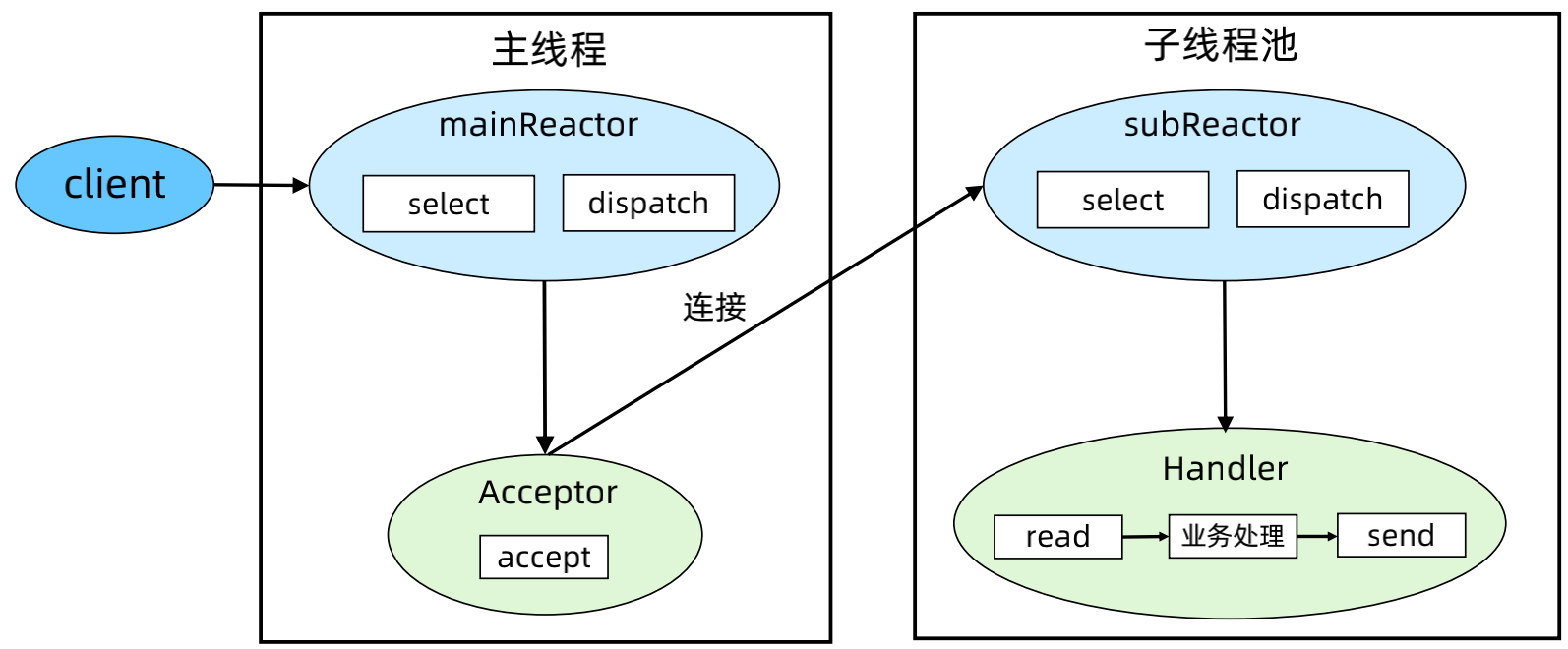
(3)Reactor 模式3 - 多 Reactor 多进程/线程
优点:充分利用了多核 CPU 的优势,性能高;实现简单,父子进程(线程)交互简单,subReactor子进程(线程)间无互斥共享或通信。
缺点:没有明显的缺点,虽然自己实现会很复杂,但是目前已经有非常成熟的开源方案。
案例:Memcached、Netty、Nginx 等,注意:实现细节都有一些差异,例如Memcached 用了事件队列、Nginx 是子进程 accept。
步骤:
a、父进程中 mainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 接收,将新的连接分配给某个子进程。
b、子进程的 subReactor 将 mainReactor 分配的连接加入连接队列进行监听,并创建一个 Handler 用于处理连接的各种事件。
c、当有新的事件发生时,subReactor 会调用连接对应的 Handler(即第2步中创建的 Handler)来进行响应。
d、Handler 完成 read → 业务处理 → send 的完整业务流程。
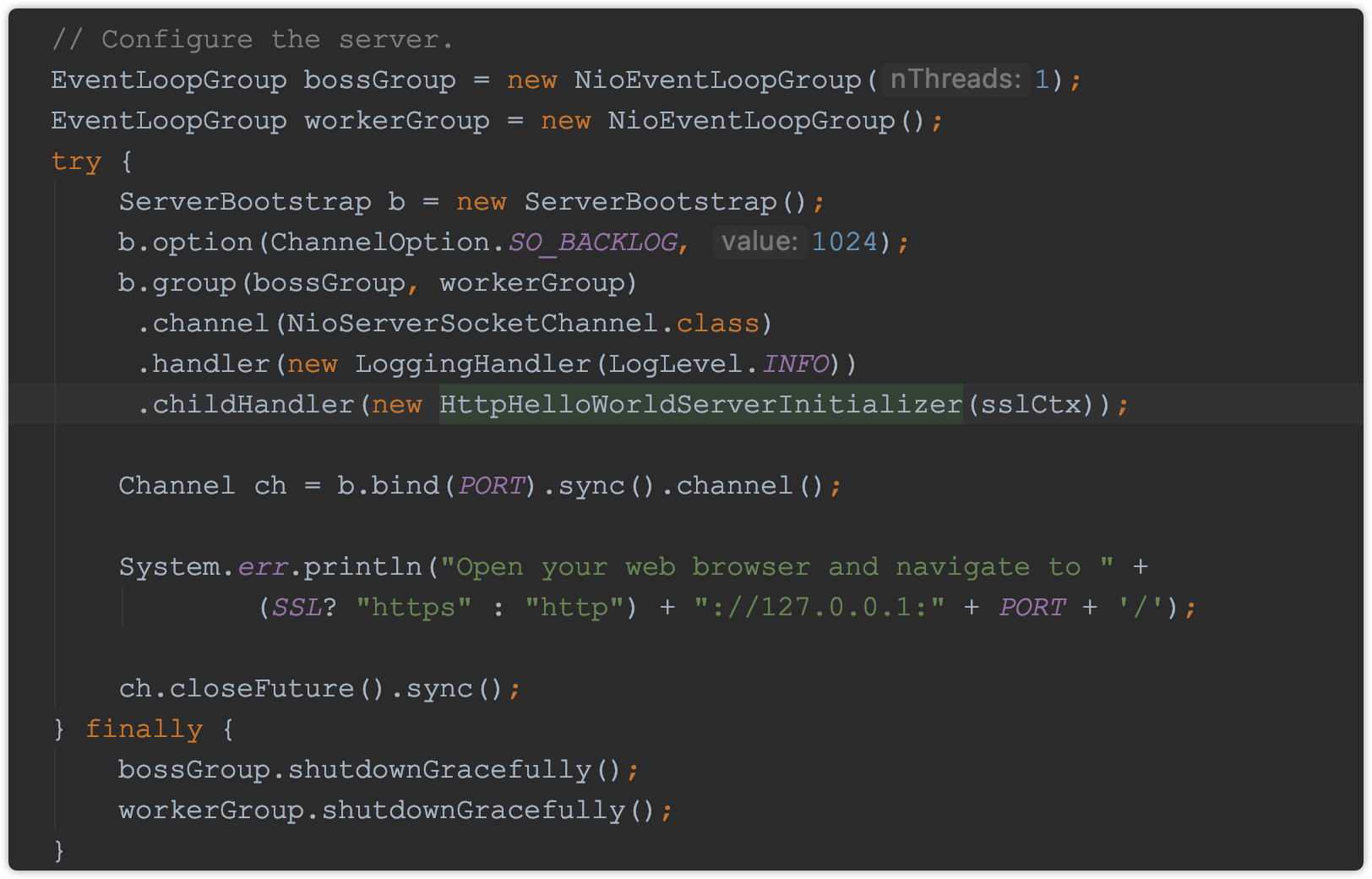
(4)Netty 代码示例 - example/http/helloworld
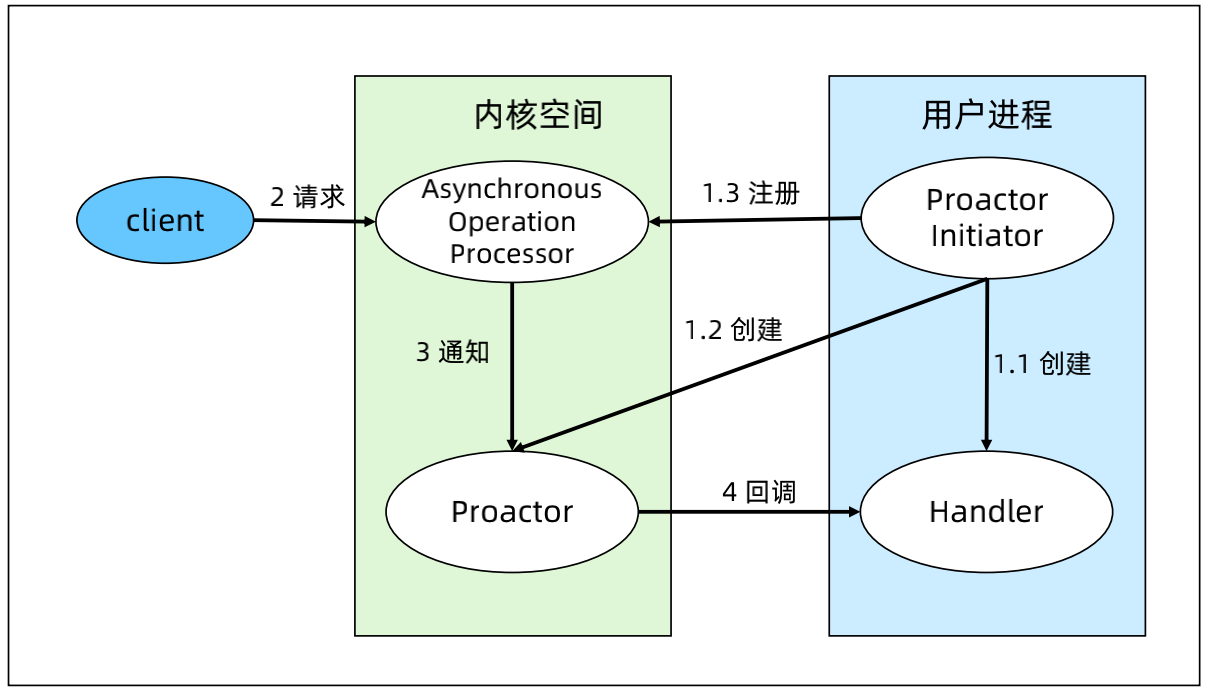
3、Proactor 网络模型
步骤:
(1)Proactor Initiator 负责创建 Proactor 和 Handler,并将Proactor和 Handler 都通过 Asynchronous Operation Processor 注册到内核。
(2)Asynchronous Operation Processor 负责处理注册请求,并完成I/O 操作。
(3)Asynchronous Operation Processor 完成 I/O 操作后通知Proactor。
(4)Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理。
(5)Handler 完成业务处理,Handler 也可以注册新的Handler 到内核进程。
优点:理论上性能要比 Reactor 更高一些,但实测性能差异不大,大约10%以内。
缺点:操作系统实现复杂,Linux 目前对 Proactor 模式支持并不成熟。程序调试复杂。
案例:Windows IOCP。
4、网络模型对比
三类网络模型对比:
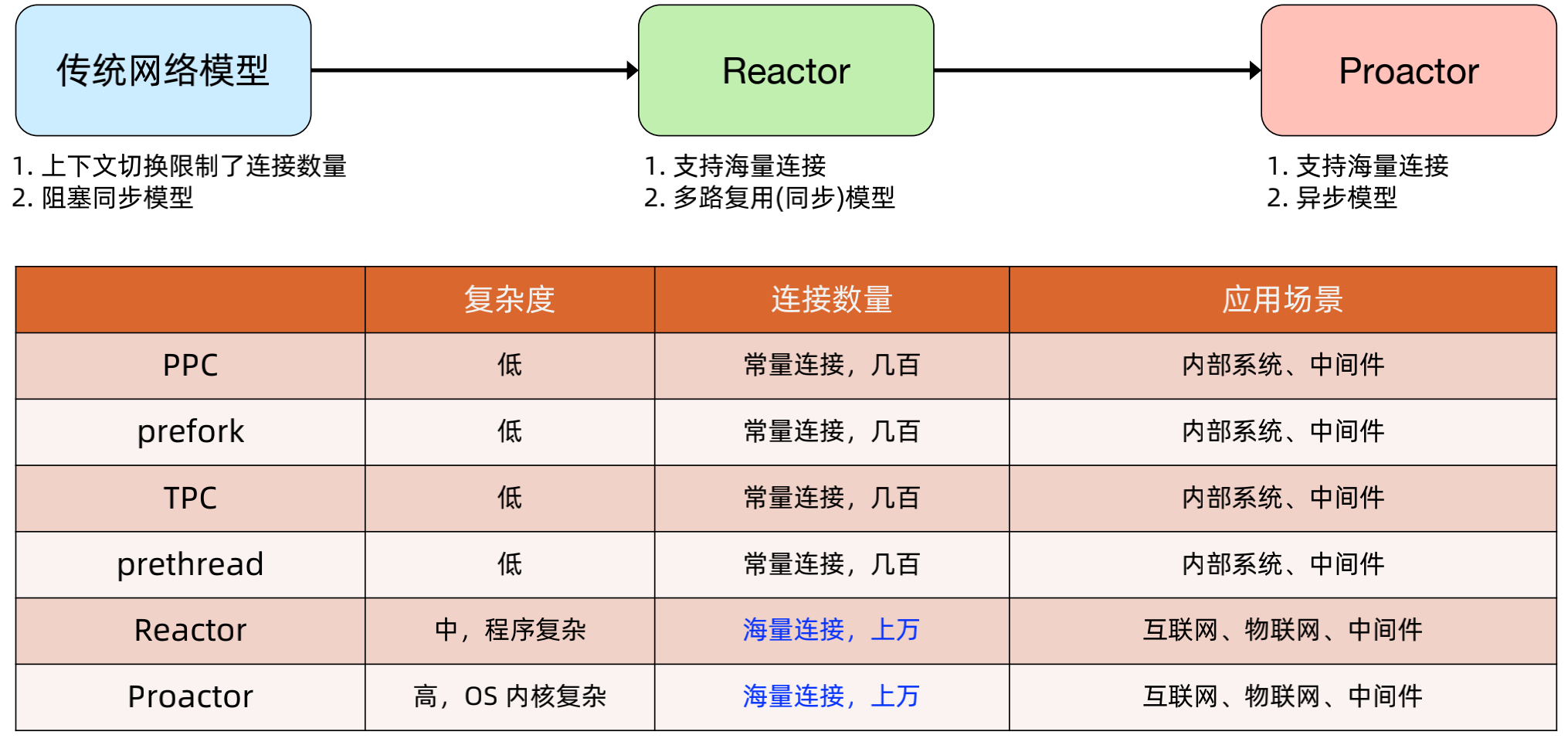
三类网络模型实战技巧:
“多 Reactor 多线程” 是目前已有技术中接近完美的技术方案!1. 所有场景;2. 所有平台;3. 性能和 Proactor 接近。
直接用开源框架,千万不要自己去实现,例如 Netty、libevent(memcached 网络框架)、libuv(node.js 底层网络框架)。
二、基于 ZooKeeper 实现高可用架构
1、 ZooKeeper 高可用相关特性
ZooKeeper 介绍:
Zookeeper是一个分布式的、开源的协同服务系统,是为分布式应用来服务的,应用场景 包括同步、服务命名、集群管理等。
Zookeeper本身就是一个分布式系统,自身就是高可用的,可以从下图看到,Zookeeper有多个server节点,其中有一个是leader节点,其他的是follower或者observer节点,这些节点从leader节点中复制数据。
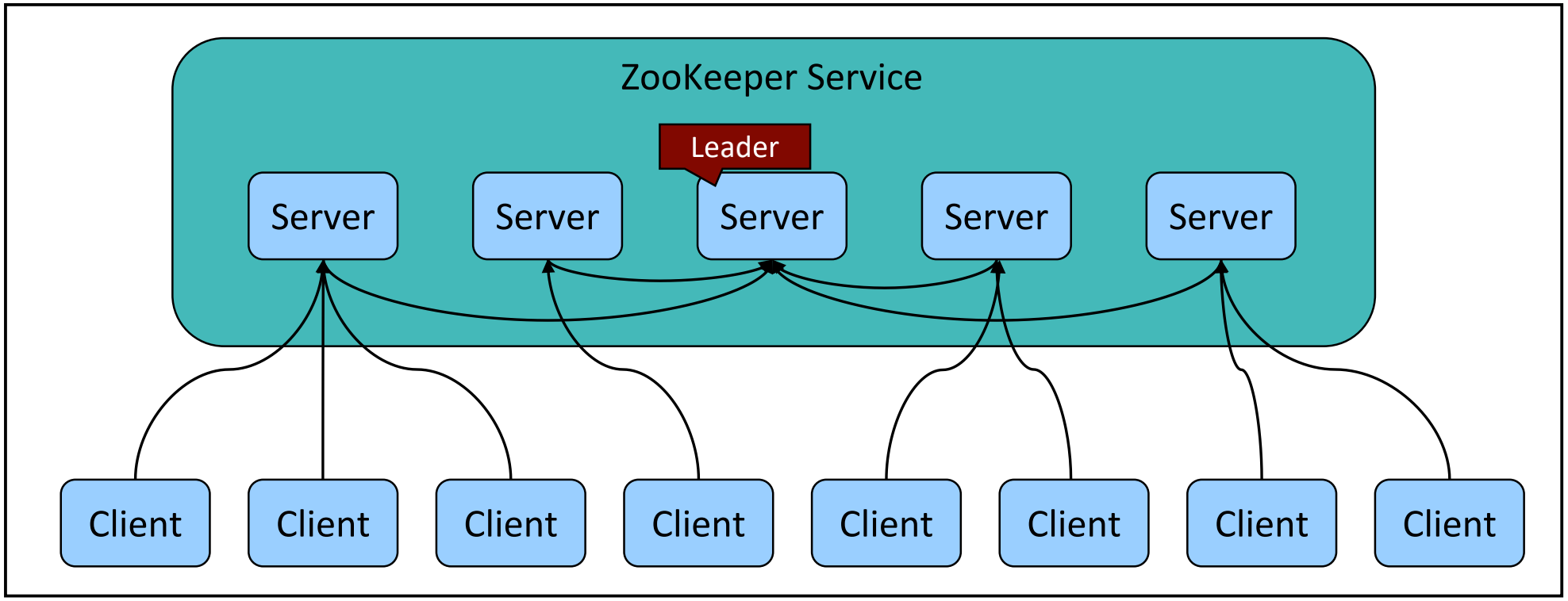
ZooKeeper 技术本质:
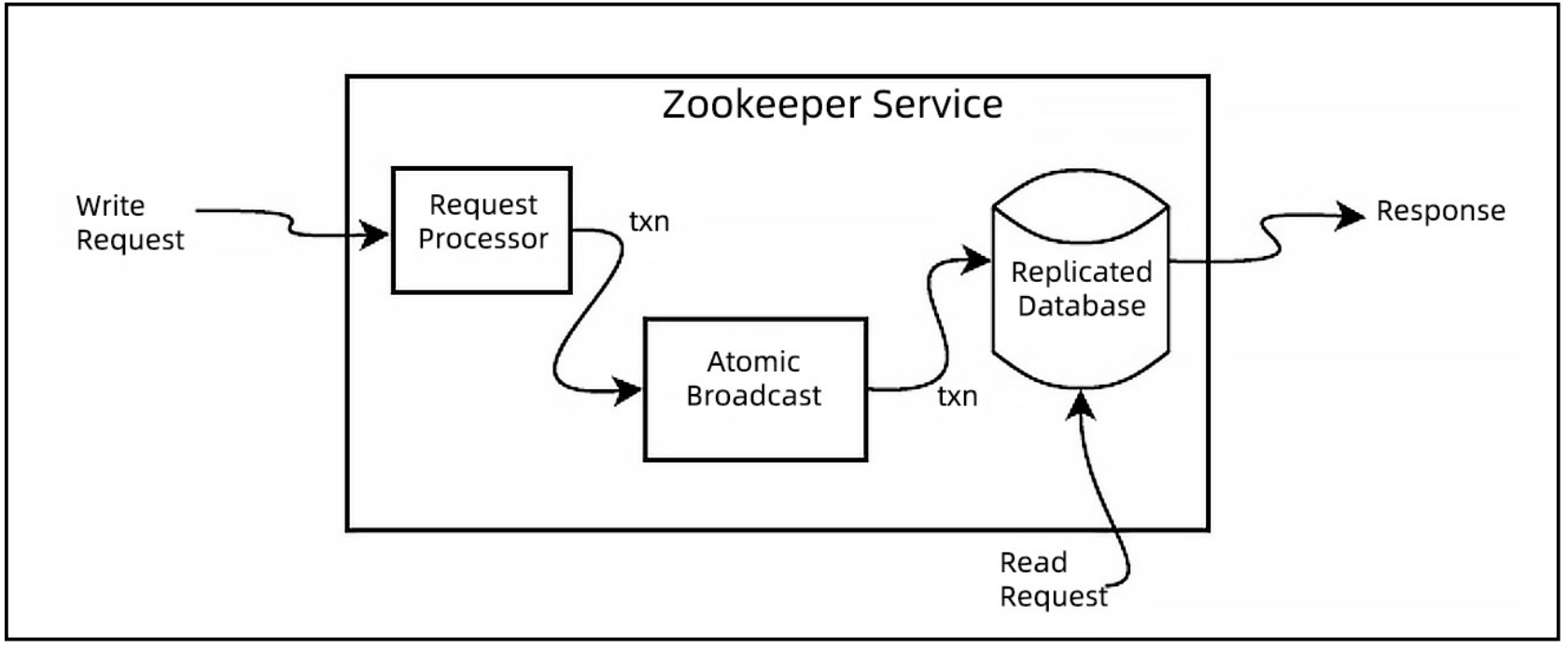
Zookeeper基于ZAB协议来实现分布式一致性的系统,核心是Atomic Broadcast,即原子广播,其通过原子广播的协议来实现分布式一致性,其使用超时机制,从而突破了FLP机制。
ZAB协议并不是Paxos算法,ZAB协议是primary-backup systems,由leader节点接收写请求,然后通过原子广播发送给其他节点,而Paxos是 state machine replication,也就是状态复制机,其没有leader节点,所有的节点都可以接收命令,当前节点将接受的命令再发送给其他节点。
(ZAB is not Paxos, it is primarily designed for primary-backup systems, like Zookeeper, rather than for state machine replication)
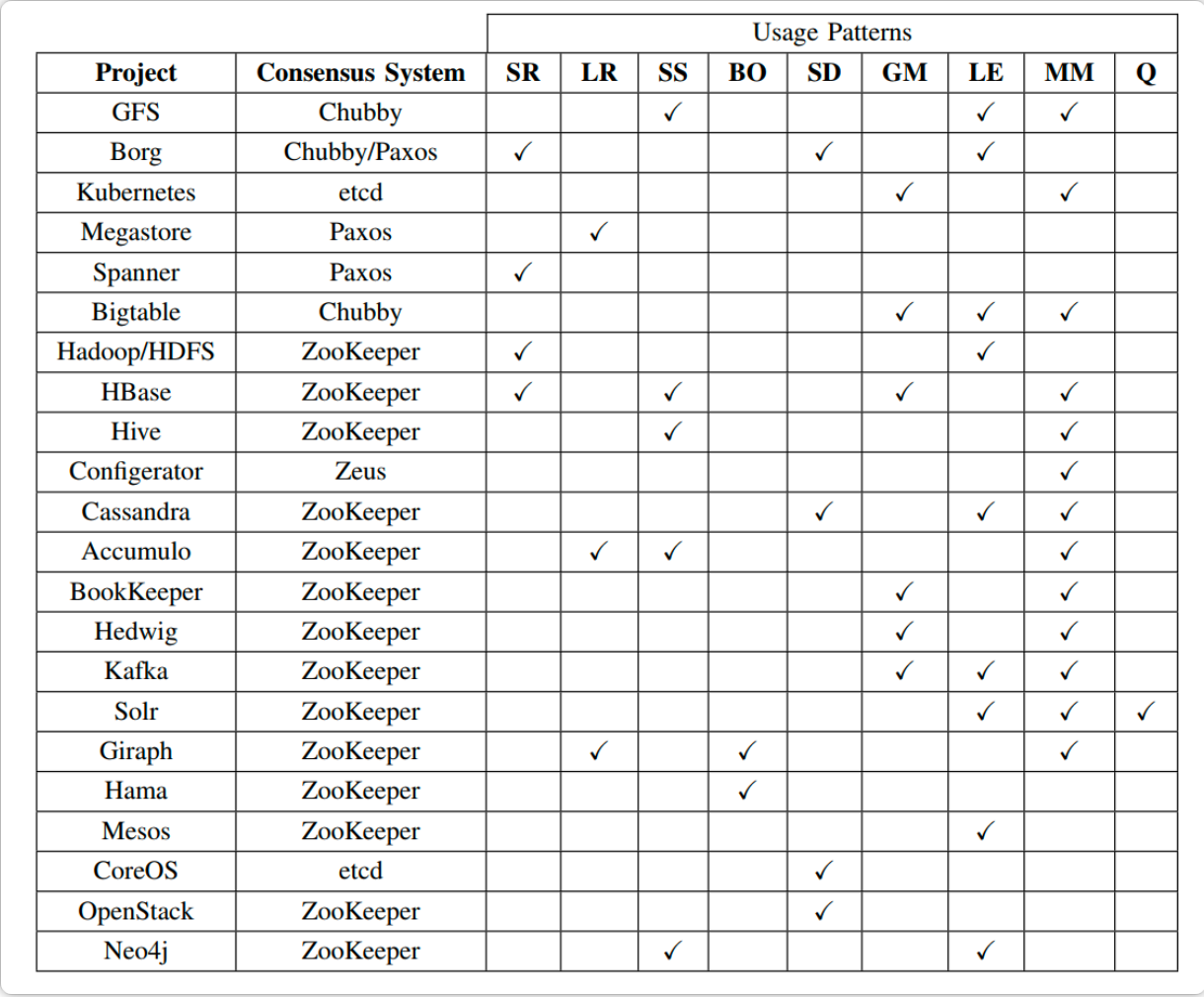
ZooKeeper 应用:
从下图可以看到,除了 Google用的是Paxos,K8S和CoreOS用的是ETCD外,其余的大部分开原软件用的都是Zookeeper,因此其应用程度很高,我们在做分布式系统时,完全可以使用。
ZooKeeper 数据模型:
Zookeeper的数据是以类似文件系统来保存一个个Node,Node包括临时节点和非临时节点、顺序节点和非顺序节点,因此总共有四类节点:持久顺序节点、持久非顺序节点、临时顺序节点、临时非顺序节点
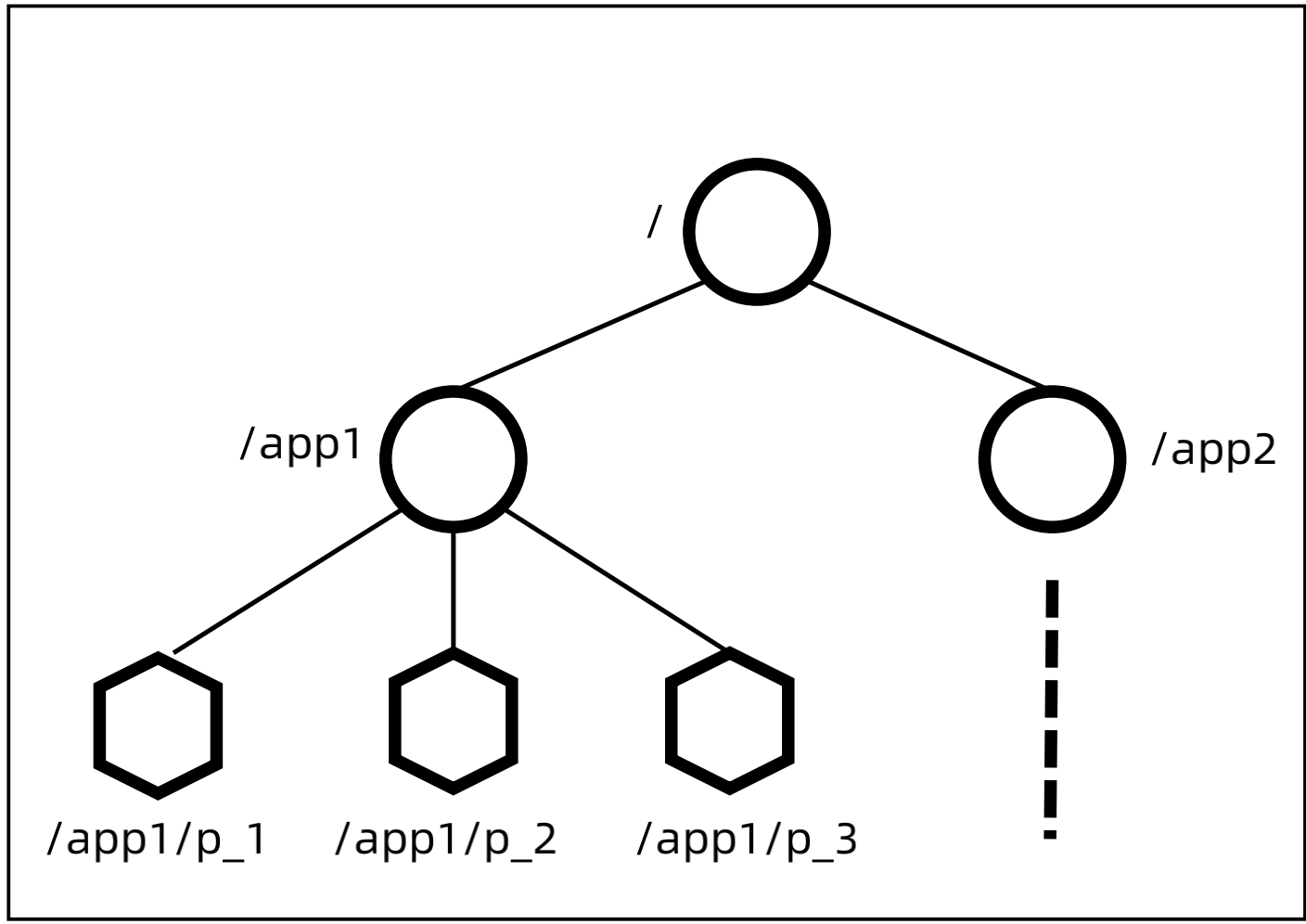
ZooKeeper 设计步骤:
(1)设计 path:/app1/p_1
(2)选择znode 类型:Ephemeral(临时)、Sequence(有序)、Normal
(3)设计znode 数据:节点里面存放什么数据
(4)设计Watch:client 关注什么事件,事件发生后如何处理
2、ZooKeeper 实现主备切换
主备切换基本架构
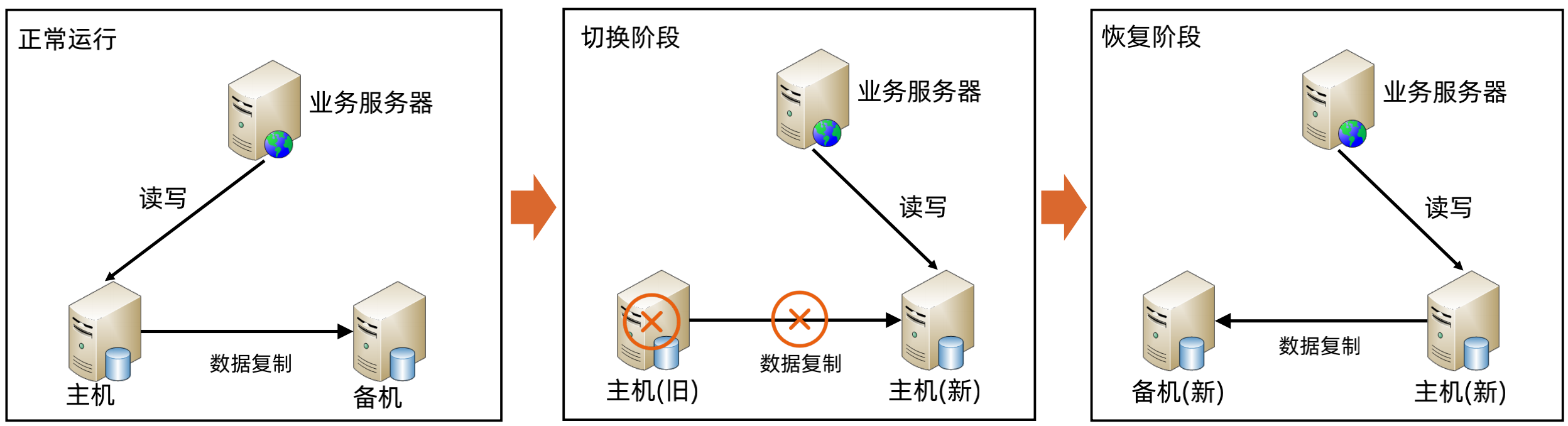
主备切换 ZooKeeper 方案
(1)设计 Path
由于只有2个角色,因此直接设置两个 znode 即可:master、slave,样例:/com/taobao/book/operating/master, /com/taobao/book/operating/slave。
(2)选择节点类型
当 master 节点挂掉的时候,原来的 slave 升级为 master 节点,因此用 ephemeral 类型的znode。
(3)设计节点数据
由于 slave 成为 master 后,会成为新的复制源,可能出现数据冲突,因此 slave 成为master 后,节点写入成为 master 的时间,这样方便人工修复冲突数据。
(4)设计 Watch
a、节点启动的时候,尝试创建 master znode,创建成功则切换为master,否则创建 slaveznode,成为 slave;
b、如果 slave 节点收到 master znode 删除的事件,就自己去尝试创建 master znode,创建成功,则自己成为 master,删除自己创建的slave znode。
代码样例:
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, groupNodePath, true); pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { @Override public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception { if(event.getType().equals(PathChildrenCacheEvent.Type.CHILD_REMOVED)){ String childPath = event.getData().getPath(); System.out.println("child removed: " + childPath); if(masterNodePath.equals(childPath)){ switchMaster(client, masterNodePath, slaveNodePath); } } else if(event.getType().equals(PathChildrenCacheEvent.Type.CONNECTION_LOST)) { System.out.println("connection lost, become slave"); role = "slave"; } else if(event.getType().equals(PathChildrenCacheEvent.Type.CONNECTION_RECONNECTED)) { System.out.println("connection connected……"); if(!becomeMaster(client, masterNodePath)){ becomeSlave(client, slaveNodePath); } } else{ System.out.println("path changed: " + event.getData().getPath()); } } });
private void switchMaster(CuratorFramework client, String masterNodePath, String slaveNodePath){ if(becomeMaster(client, masterNodePath)){ try { client.delete().forPath(slaveNodePath); } catch (Exception e) { System.out.println("failed to delete slave node when switch master: " + slaveNodePath); } } }
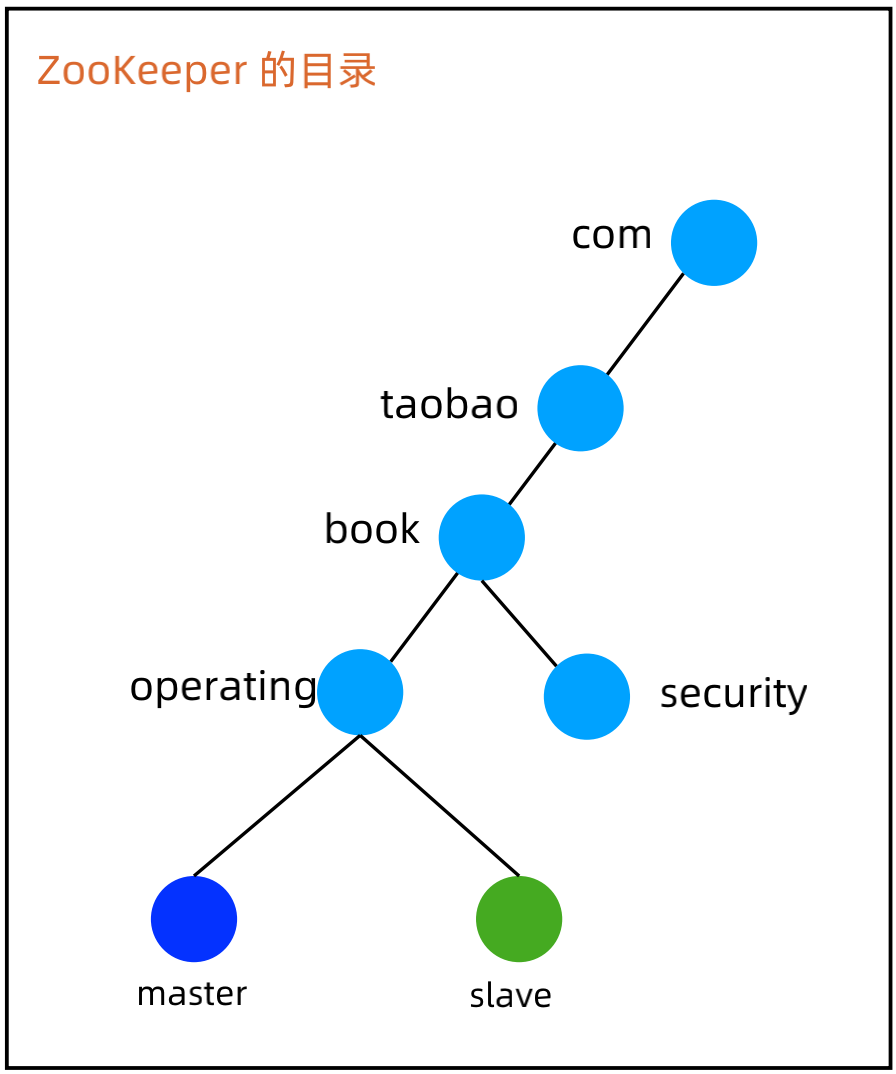
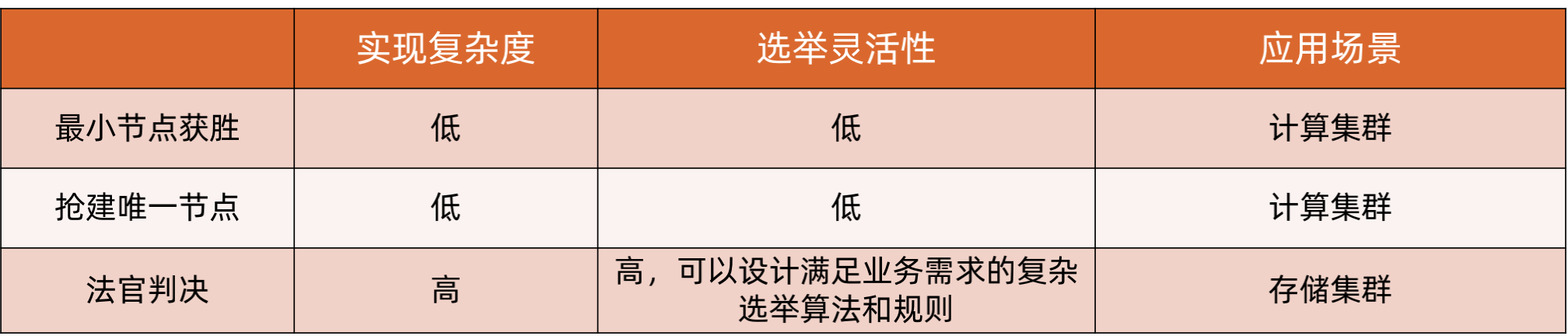
3、ZooKeeper 实现集群选举-最小节点获胜
(1)设计 Path
集群共用父节点 parent znode,集群中的每个节点在 parent 目录下创建自己的 znode。
(2)选择节点类型
当 Leader 节点挂掉的时候,持有最小编号 znode 的集群节点成为新的 Leader,因此用ephemeral_sequential 类型 znode。
(3)设计节点数据
可以根据业务需要灵活写入各种数据。
(4)设计 Watch
a、节点启动或者重连后,在 parent 目录下创建自己的 ephemeral_sequntial znode;
b、创建成功后扫描 parent 目录下所有 znode,如果自己的 znode 编号是最小的,则成为Leader,否则 watch parent 目录;
c、当 parent 目录有节点删除的时候,首先判断其是否是 Leader 节点,然后再看其编号是否正好比自己小1,如果是则自己成为 Leader,如果不是继续 watch。
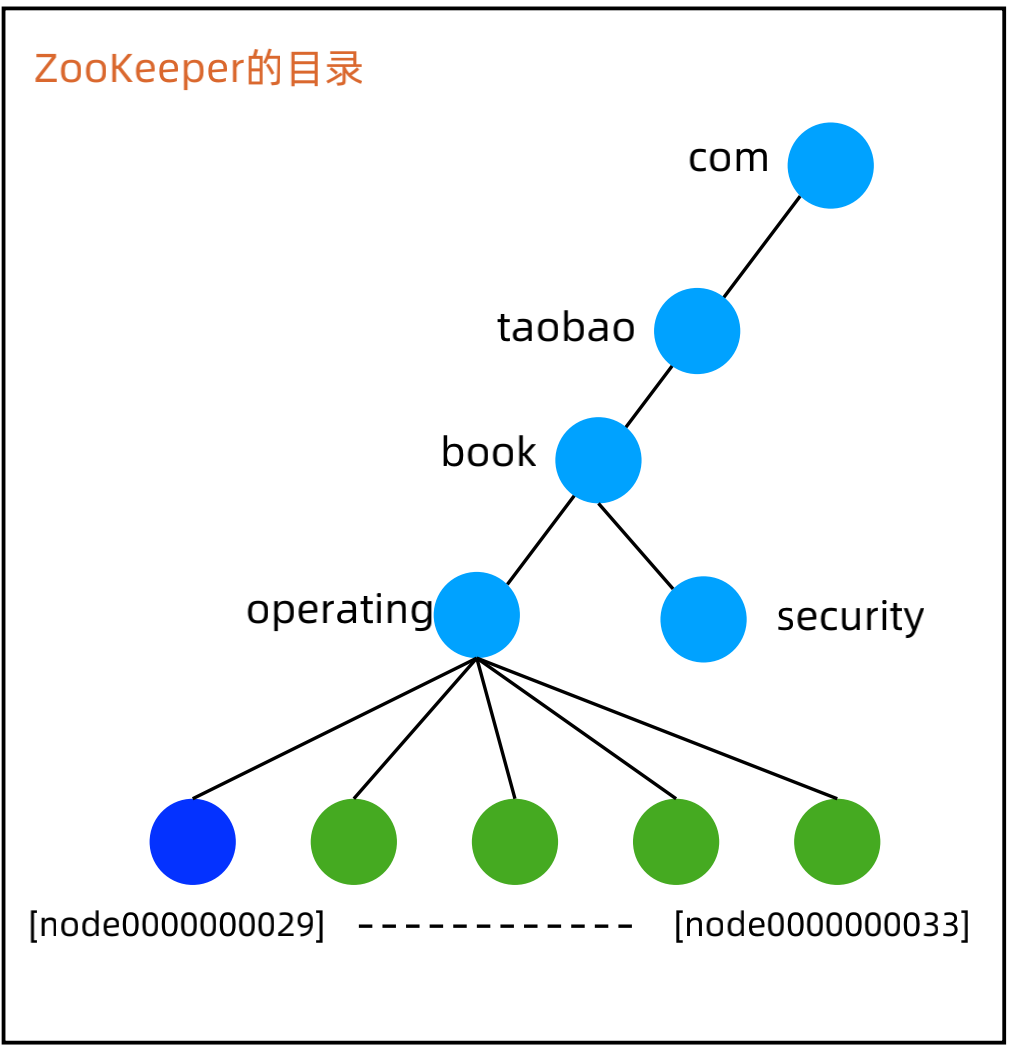
4、ZooKeeper 实现集群选举-抢建唯一节点
(1)设计 Path
集群所有节点只有一个 leader znode,本质上就是一个分布式锁。
(2)选择 znode 类型
当 Leader 节点挂掉的时候,剩余节点都来创建 leader znode,看谁能最终抢到 leader znode,因此用ephemeral 类型。
(3)设计节点数据
可以根据业务需要灵活写入各种数据。
(4)设计 Watch
a、节点启动或者重连后,尝试创建 leader znode,尝试失败则watch leader znode;
b、当收到 leader znode 被删除的事件通知后,再次尝试创建 leader znode,尝试成功则成为 leader ,失败则 watch leader znode。
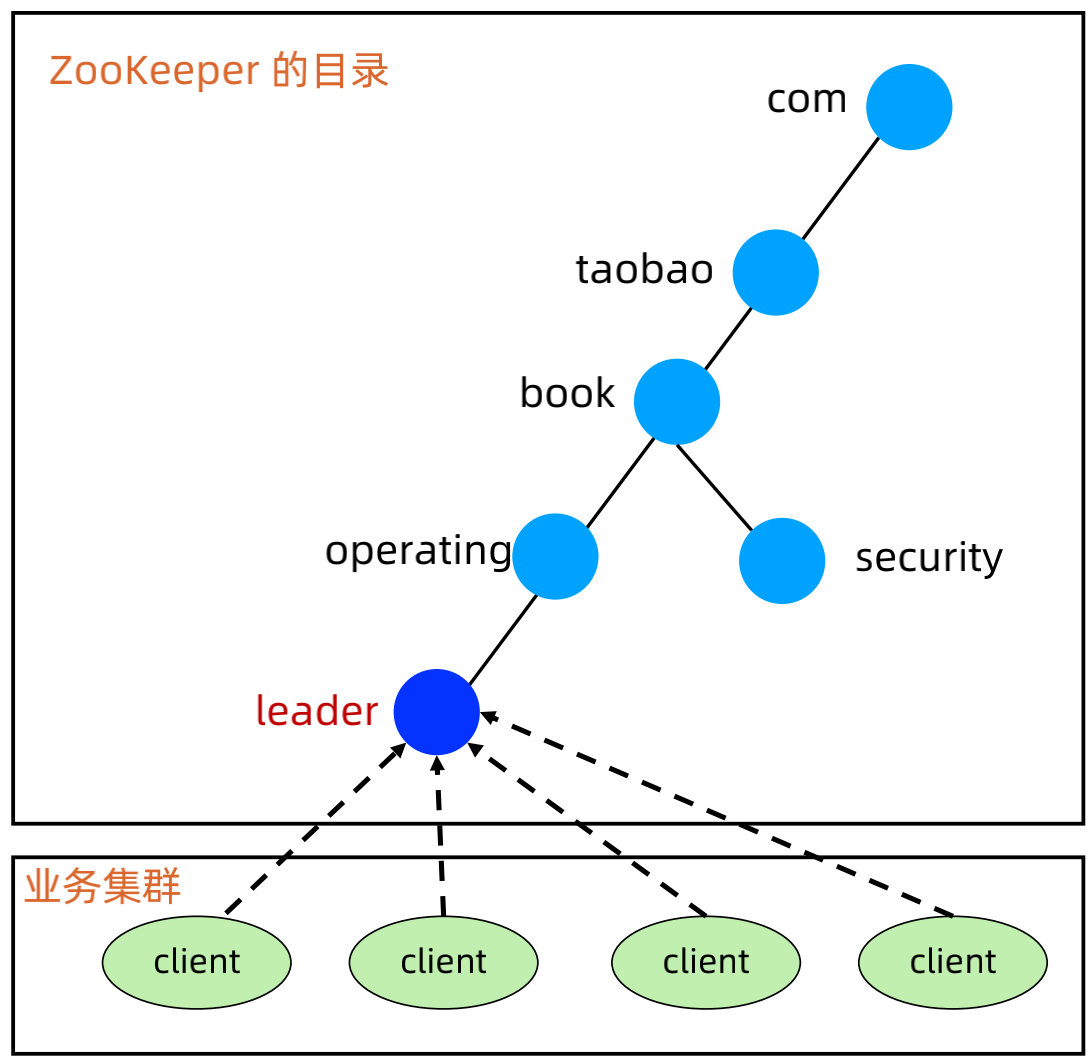
5、ZooKeeper 实现集群选举-法官判决
(1)设计Path
集群共用父节点 parent znode,集群中的每个节点在 parent 目录下创建自己的 znode。
(2)选择节点类型
当 Leader 节点挂掉的时候,持有最小编号 znode 的集群节点成为“法官”,因此用 ephemeral_sequential 类型znode。
(3)设计节点数据
可以根据业务需要灵活写入各种数据,例如写入当前存储的最新的数据对应的事务 ID。
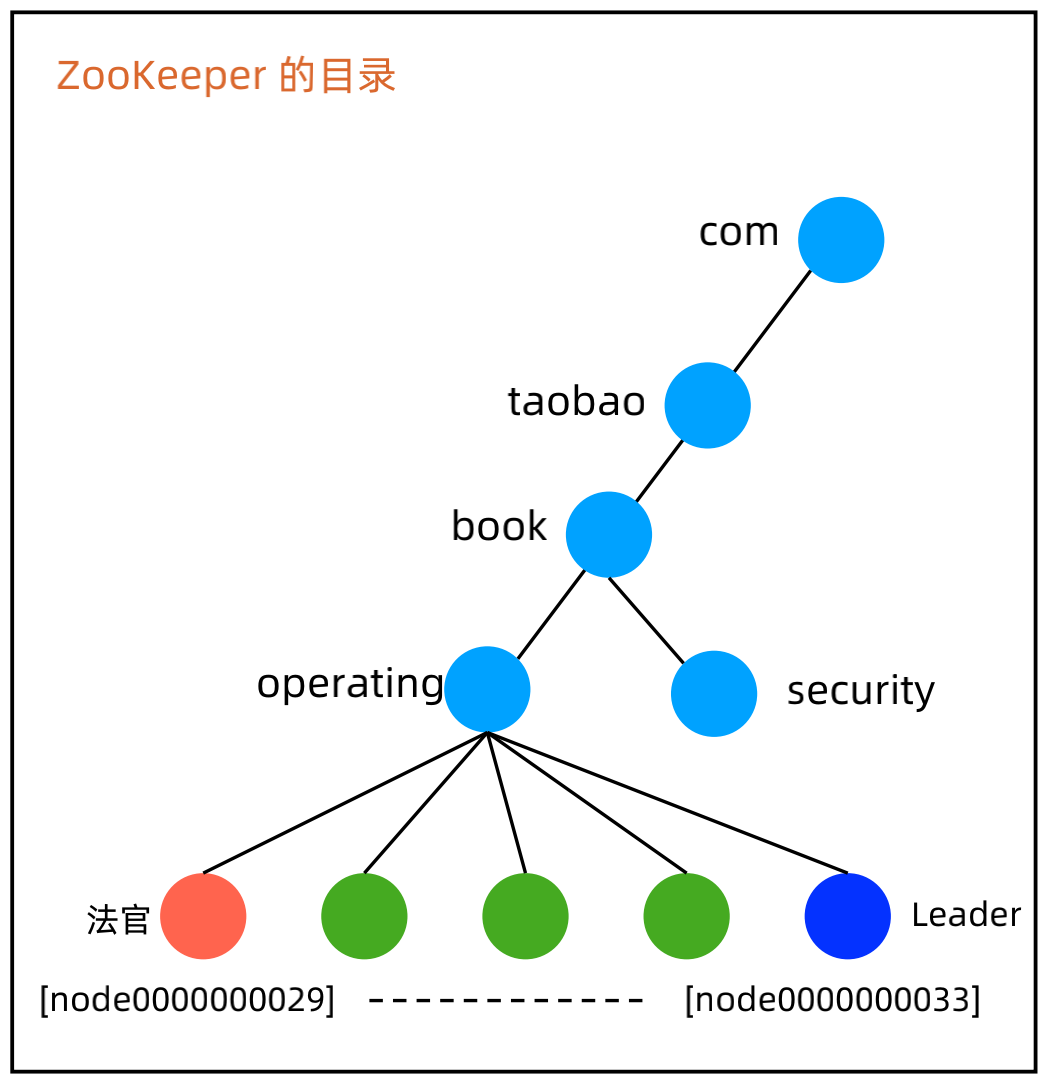
(4)节点设计:
a、parent znode:图中的 operating,代表一个集群,选举结果写入到这里,例如:leader=server6。
b、法官 znode:图中的橙色 znode,最小的 znode,持有这个 znode 的节点负责选举算法/规则。
c、成员 znode:图中的绿色 znode,每个集群节点对应一个,在选举期间将选举需要的信息写入到自己的 znode。例如:Redis 存储集群,各个 slave 节点可以将自己存储的数据最新的 trxID 写入到 znode,然后法官节点将 trxID 最大的节点选为新的 Leader。
d、Leader znode:图中的深蓝色 znode,集群里面只有一个,由法官选出来。
(5)设计Watch
a、节点启动或者重连后,在 parent 目录下创建自己的 ephemeral_sequntial znode,并 watchparent 目录;
b、当 parent 目录有节点删除的时候,所有节点更新自己的 znode 里面和选举相关的数据;
c、“法官”节点读取所有 znode 的数据,根据规则或者算法选举新的 Leader,将选举结果写入 parent znode;
d、所有节点 watch parent znode,收到变更通知的时候读取 parent znode 的数据,发现是自己则成为 Leader。
ZooKeeper 集群模式对比
三、复制集群架构设计技巧
1、Redis Sentinel 设计技巧
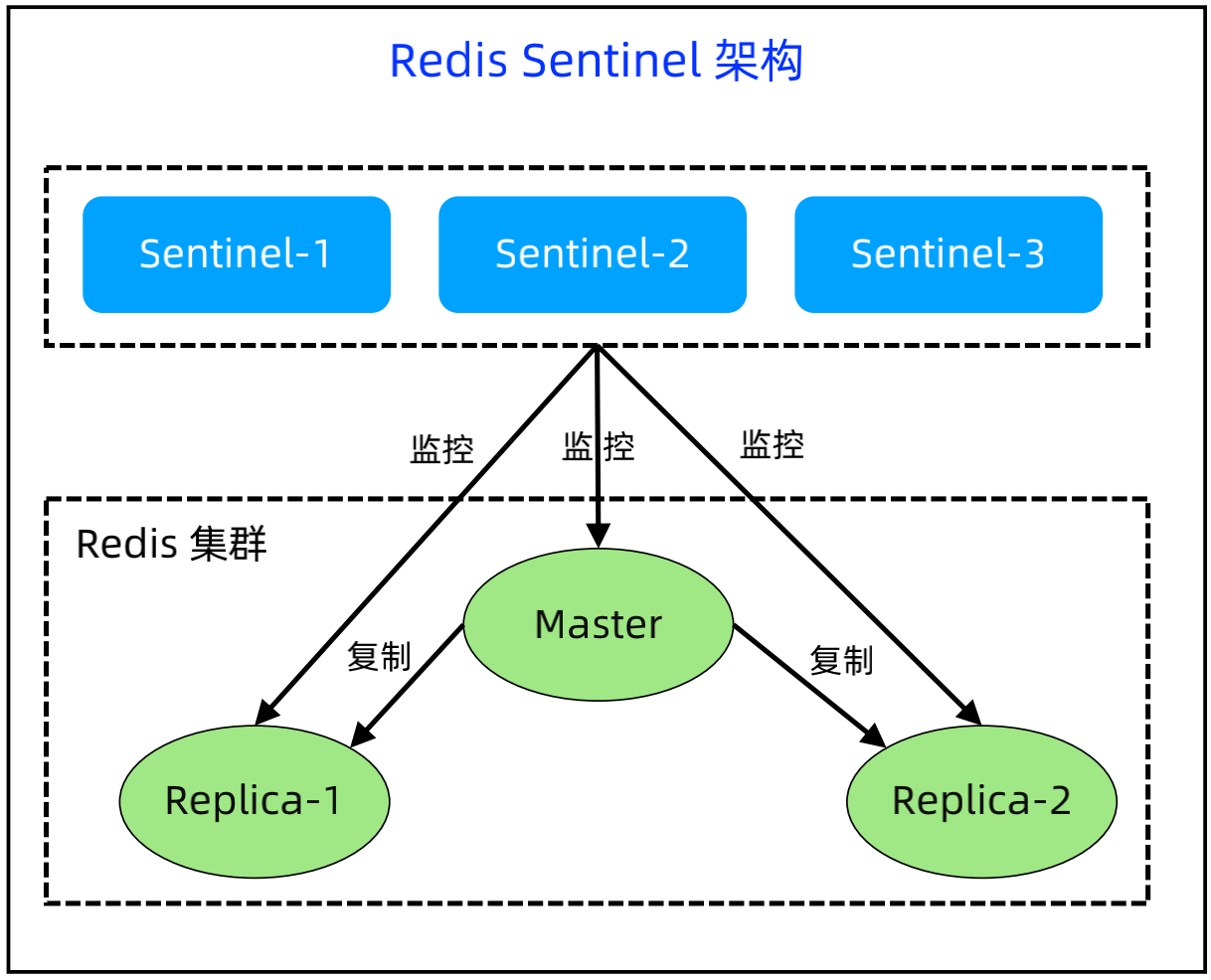
(1)Redis Sentinel 基本架构:
Sentinel 可以监控 Redis 节点的状态;可以通过 API 进行集群状态通知;可以实现故障自动切换;同时Sentinel 为 client 提供发现 master 节点的发现功能,如果发生了切换,Sentinel 会通知 client 新的 master 地址。
实现细节:Sentinel 的选举是 Raft 算法;Sentinel 是独立运行的程序,但不是独立的代码,例如sentinel启动时,使用如下命令:redis-server /path/to/sentinel.conf --sentinel
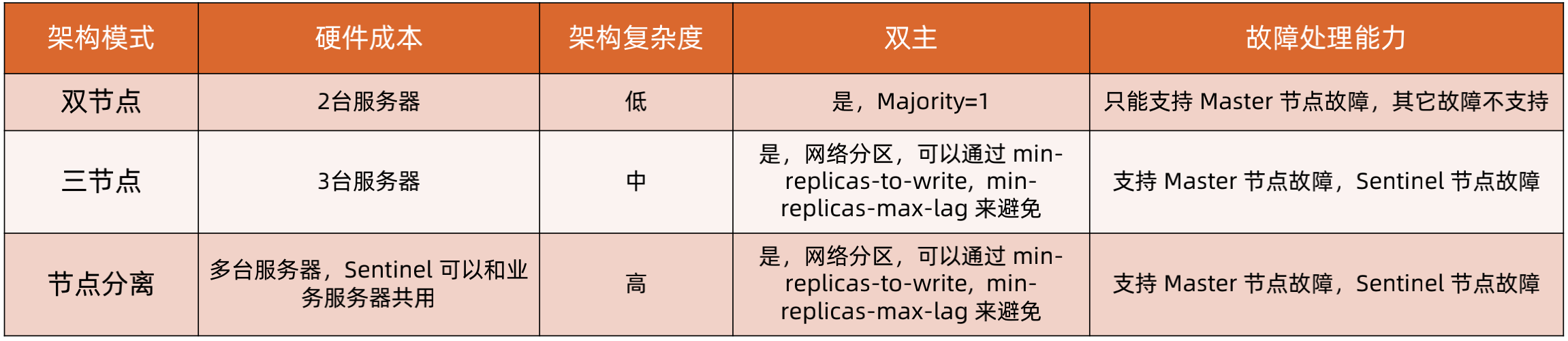
(2)Sentinel 架构模式 - 双节点(只做说明,实际不会这么部署)
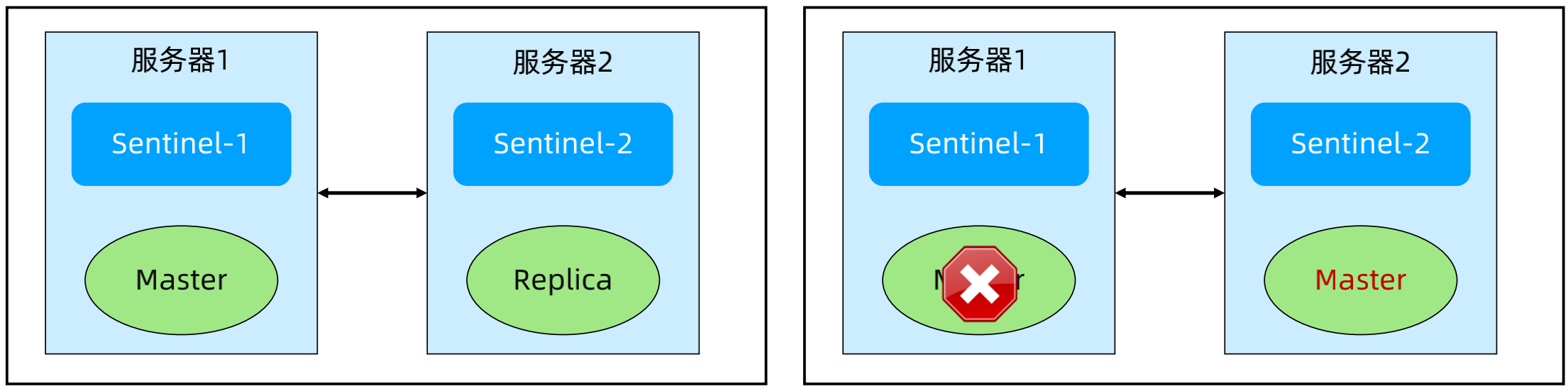
正常:两台服务器,每台服务器上分别部署 Sentinel和 Redis 节点。(Quorum:Sentinel 对 master 故障达成一致意见的投票数;Majority:Sentinel 之间选举 leader 需要的投票数)
故障场景1:Master 挂掉,Sentinel 都正常。故障影响:Replica 被提升为 Master。
故障场景2:服务器1挂掉,quorum=1,majority=2。故障影响:无论服务器2是否挂掉,集群都宕机。
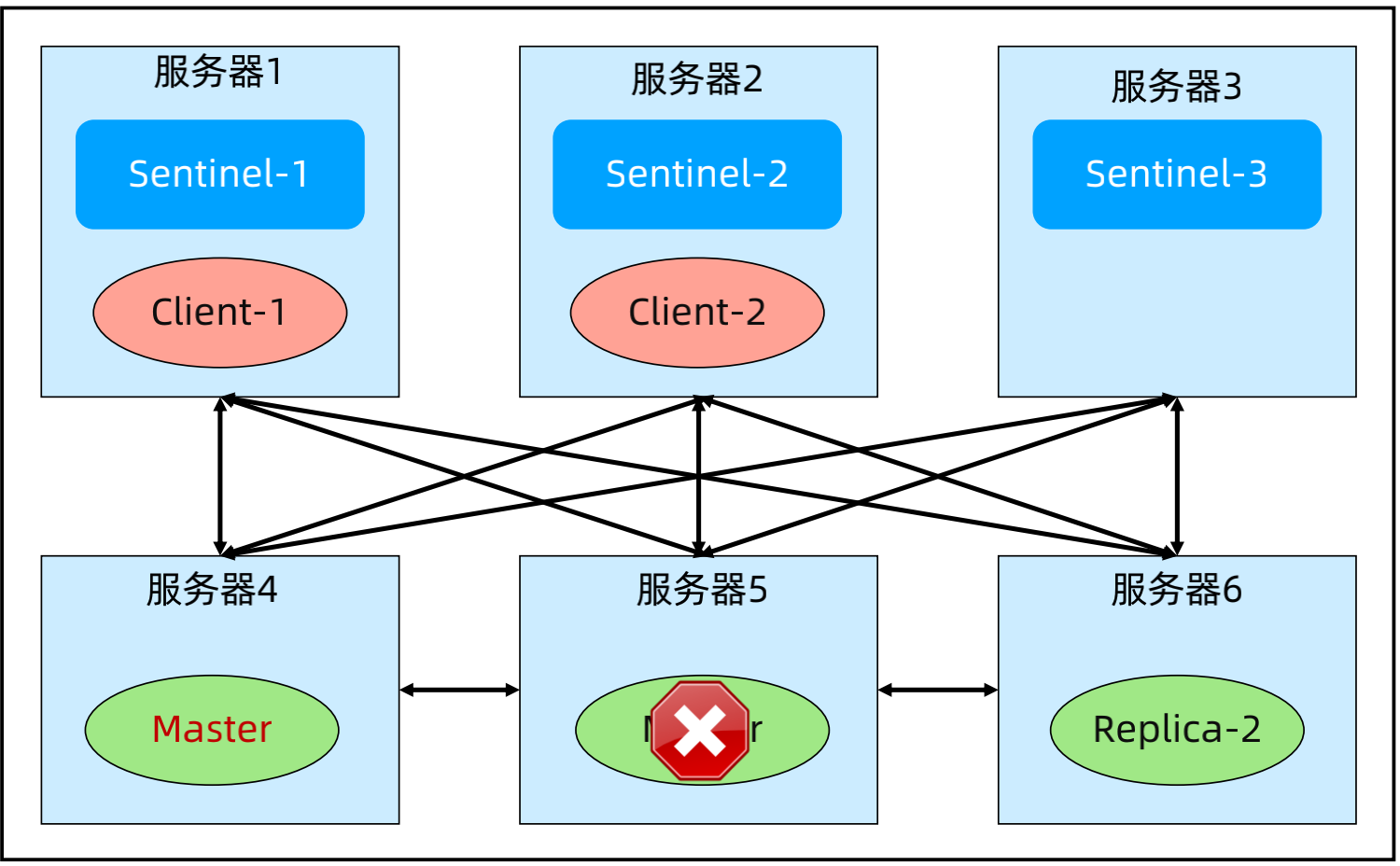
故障场景3:服务器1和服务器2的连接挂掉,quorum=1,majority=1。故障影响:双主(脑裂)。
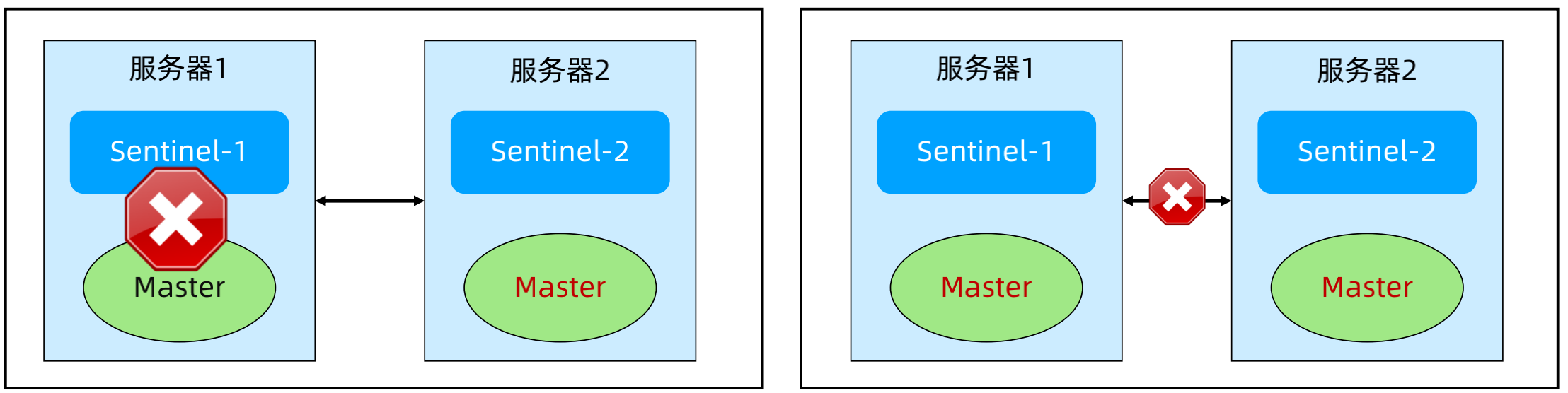
(3)Sentinel 架构模式 - 三节点
正常:三台服务器,每台服务器上分别部署 Sentinel 和Redis 节点。
故障场景1:Master 挂掉,Sentinel 都正常。故障影响:其中1个 Replica 被提升为 Master。
故障场景2:服务器1挂掉,quorum = 2,majority=2。故障影响:其中1个 Replica 被提升为 Master。
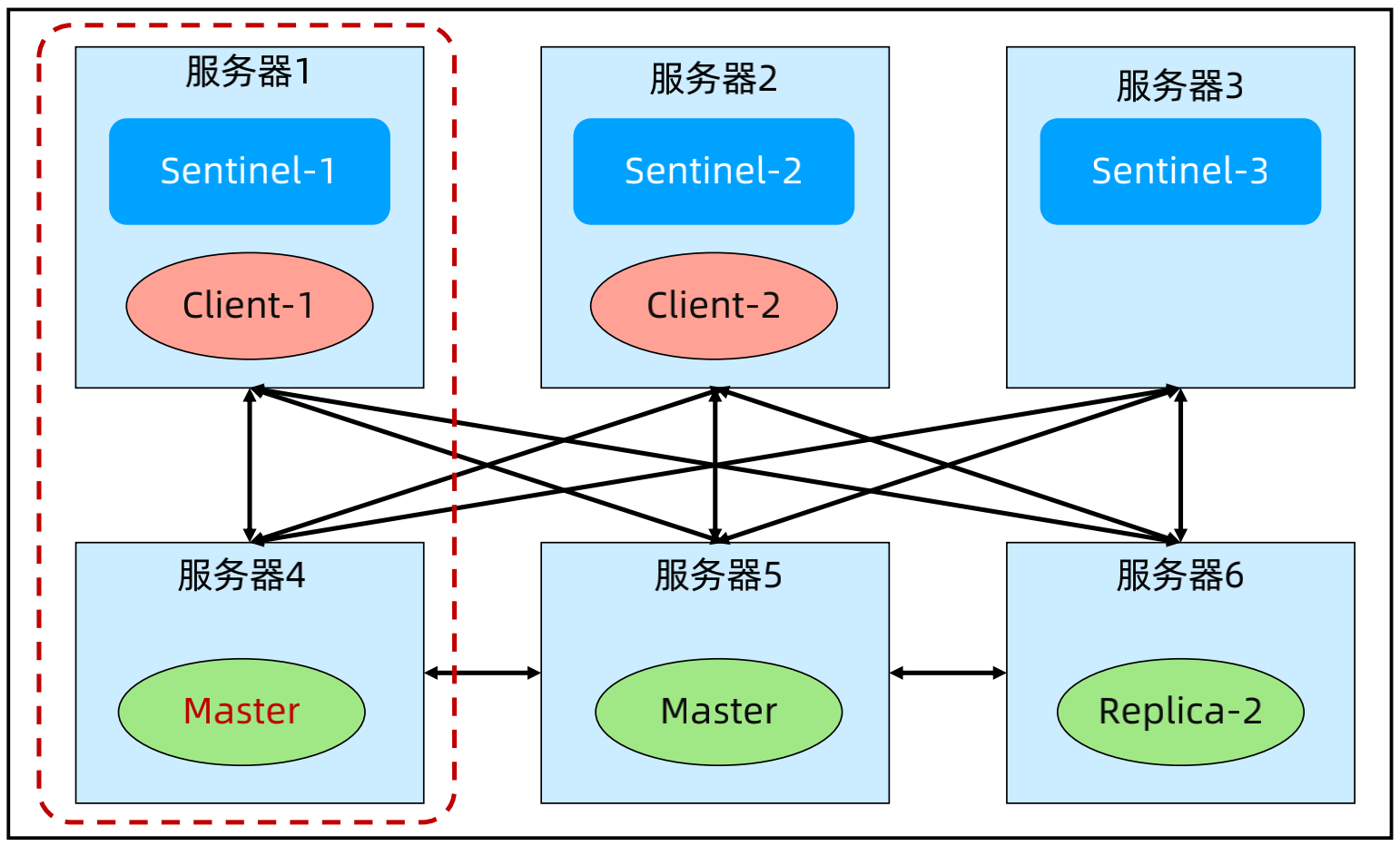
故障场景3:服务器1与服务器2和服务器3断连。故障影响:其中1个 Replica 被提升为 Master,可能出现双主。解决方案:min-replicas-to-write 1; min-replicas-max-lag 10。
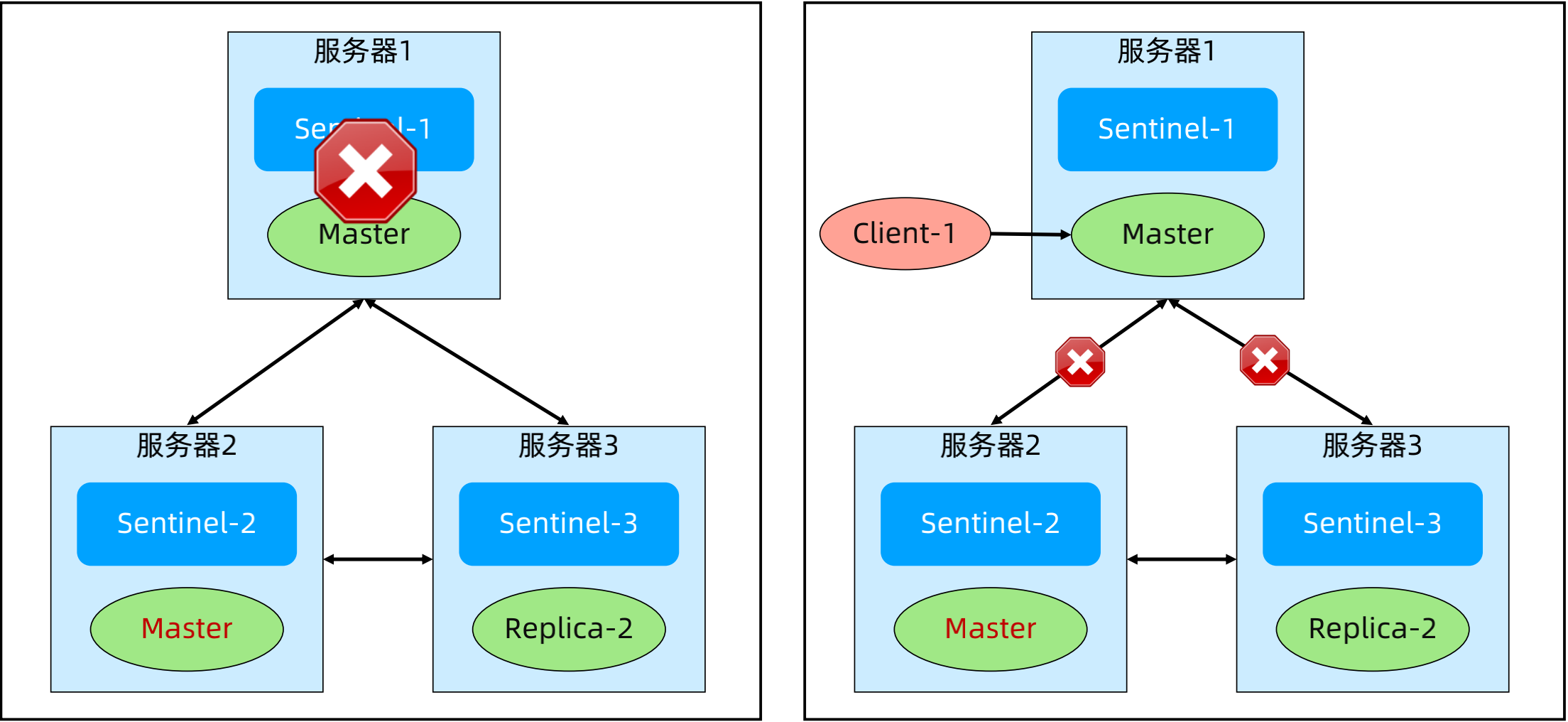
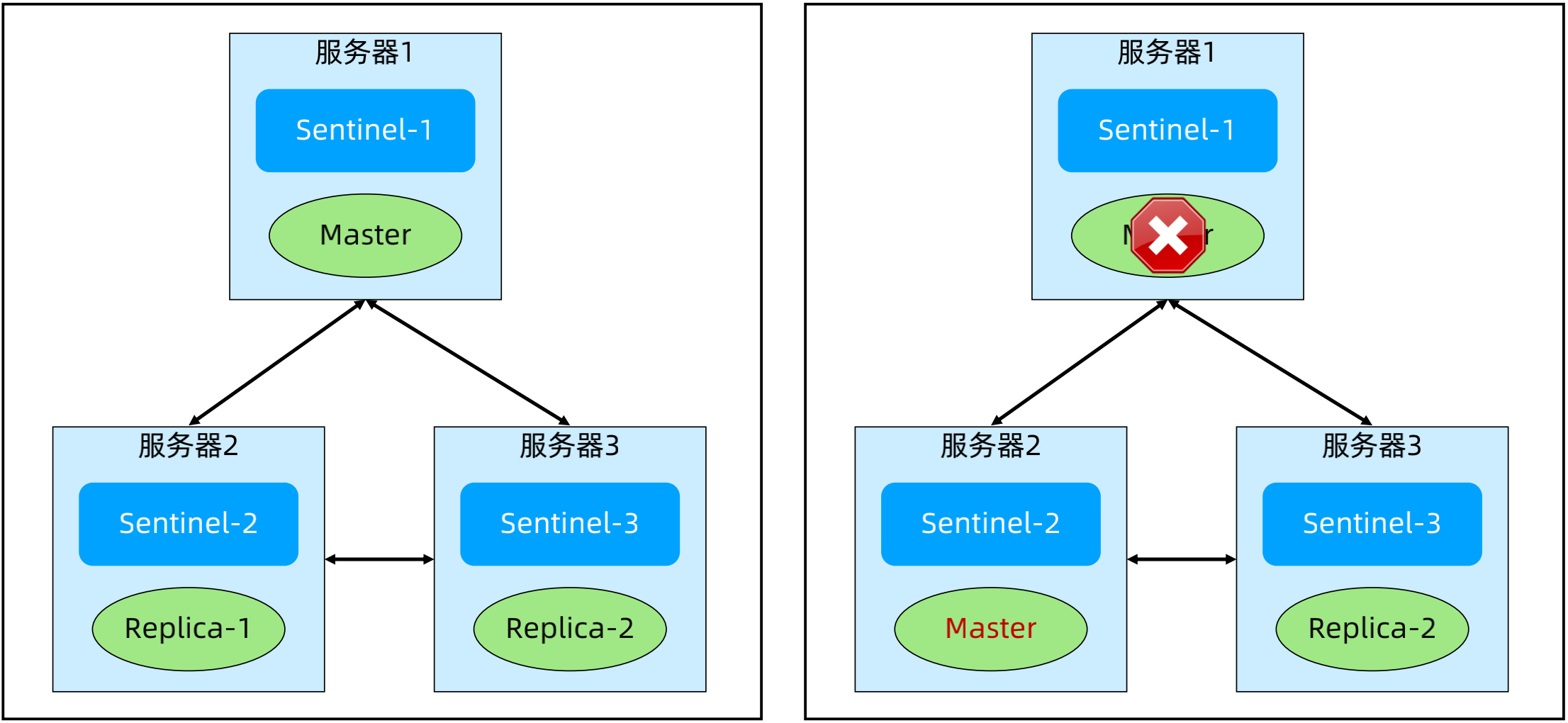
(4)Sentinel 架构模式 - 分离部署
正常:Sentinel 和 Redis 分开部署,可以将 Sentinel 和 Redis 客户端所在的应用部署在一起,也可以独立部署。
故障场景1:Master 挂掉,Sentinel 都正常。故障影响:其中1个 Replica 被提升为 Master。
故障场景2:服务器1和服务器4形成分区,剩余的服务器形成另外一个分区。故障影响:双主(脑裂)。解决方案:min-replicas-to-write 1; min-replicas-max-lag 10
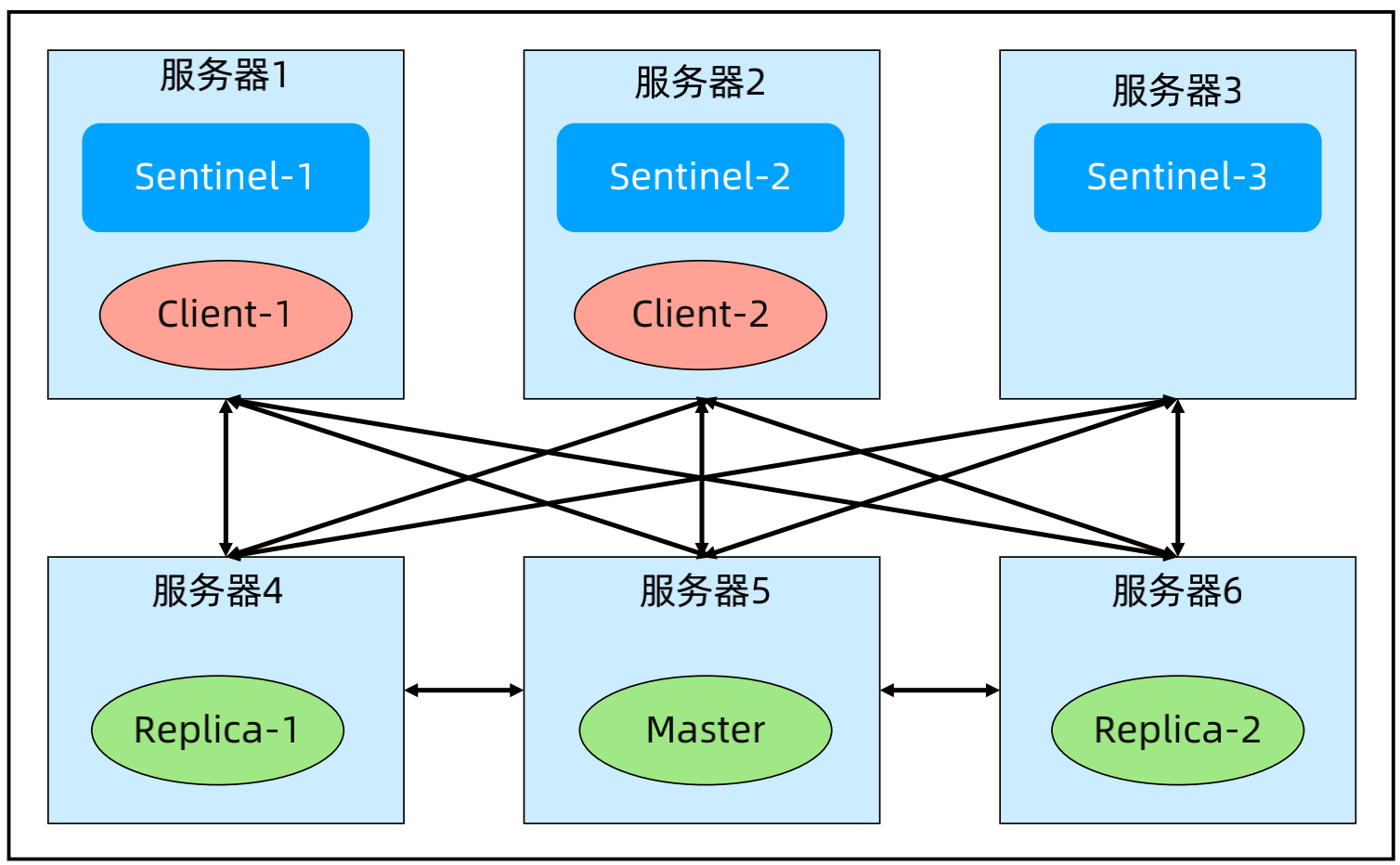
(5)Redis 集群架构模式对比
2、MongoDB Replication 设计技巧
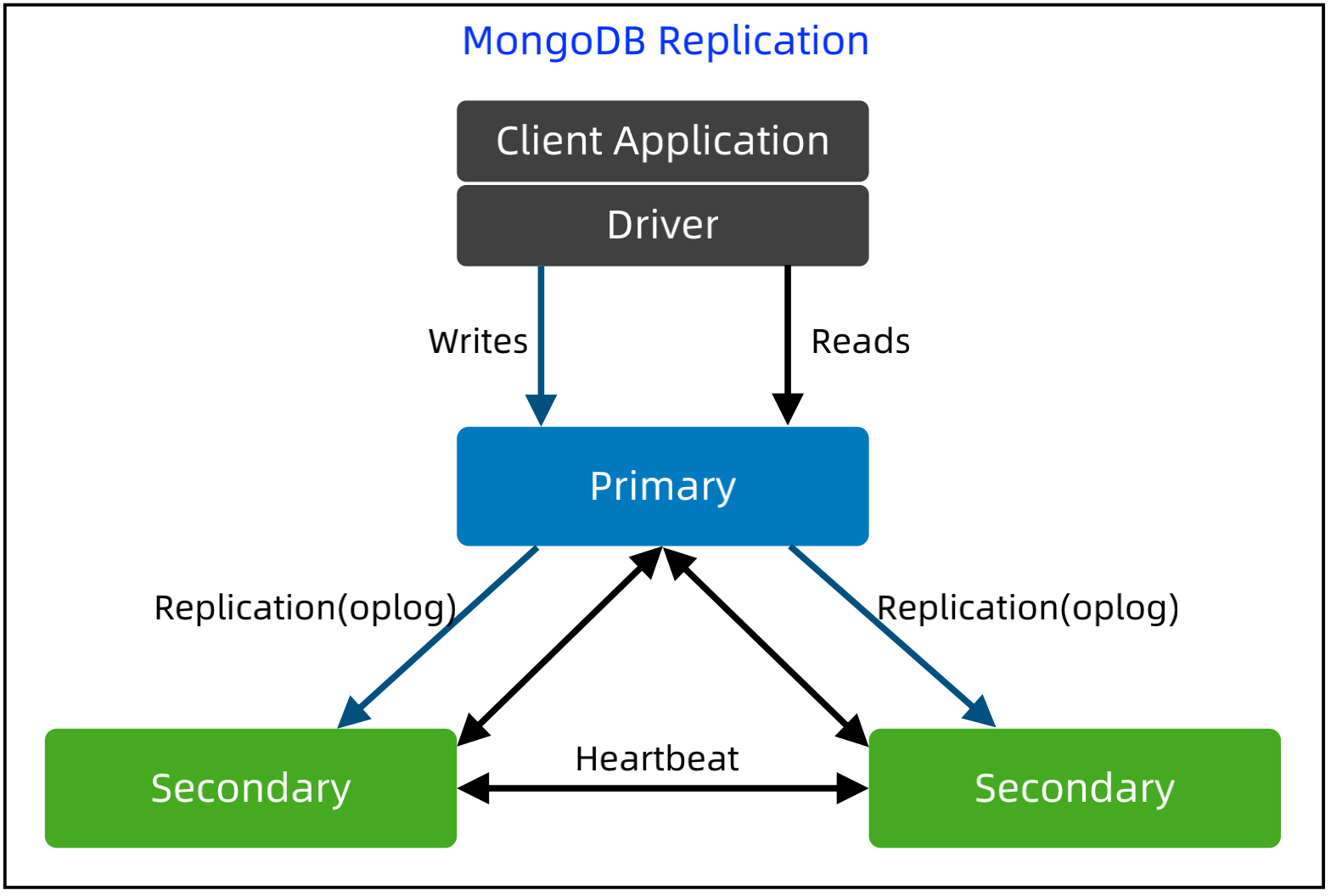
MongoDB Replication 基本架构
基本实现:
Primary 处理所有 Write 请求,Secondary可以处理 Read 请求,或者只复制数据;数据复制采用异步复制,复制的是 oplog。
选举算法:3.2.0 以前基于 bully 算法,3.2.0开始基于 Raft 算法。
最多50个节点,但最多只有7个节点参与选举。
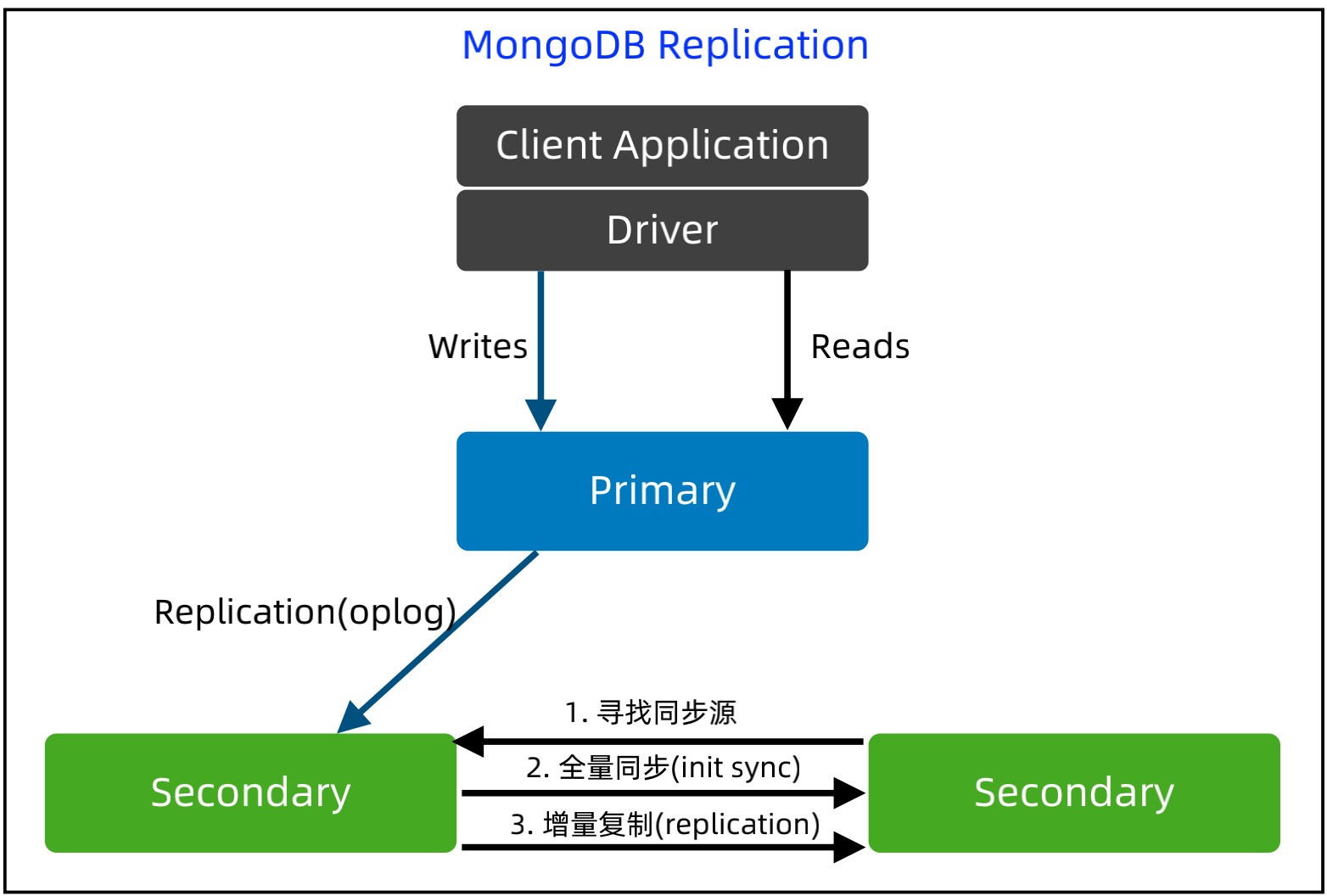
MongoDB Replication - 新节点同步流程
基本实现:
第1步:寻找同步源,MongoDB 支持级联复制,复制源不一定是 Primary,而是通过算法选出来的。
第2步:全量复制数据和 oplog。
第3步:同步全量复制后的增量数据,异步复制oplog。
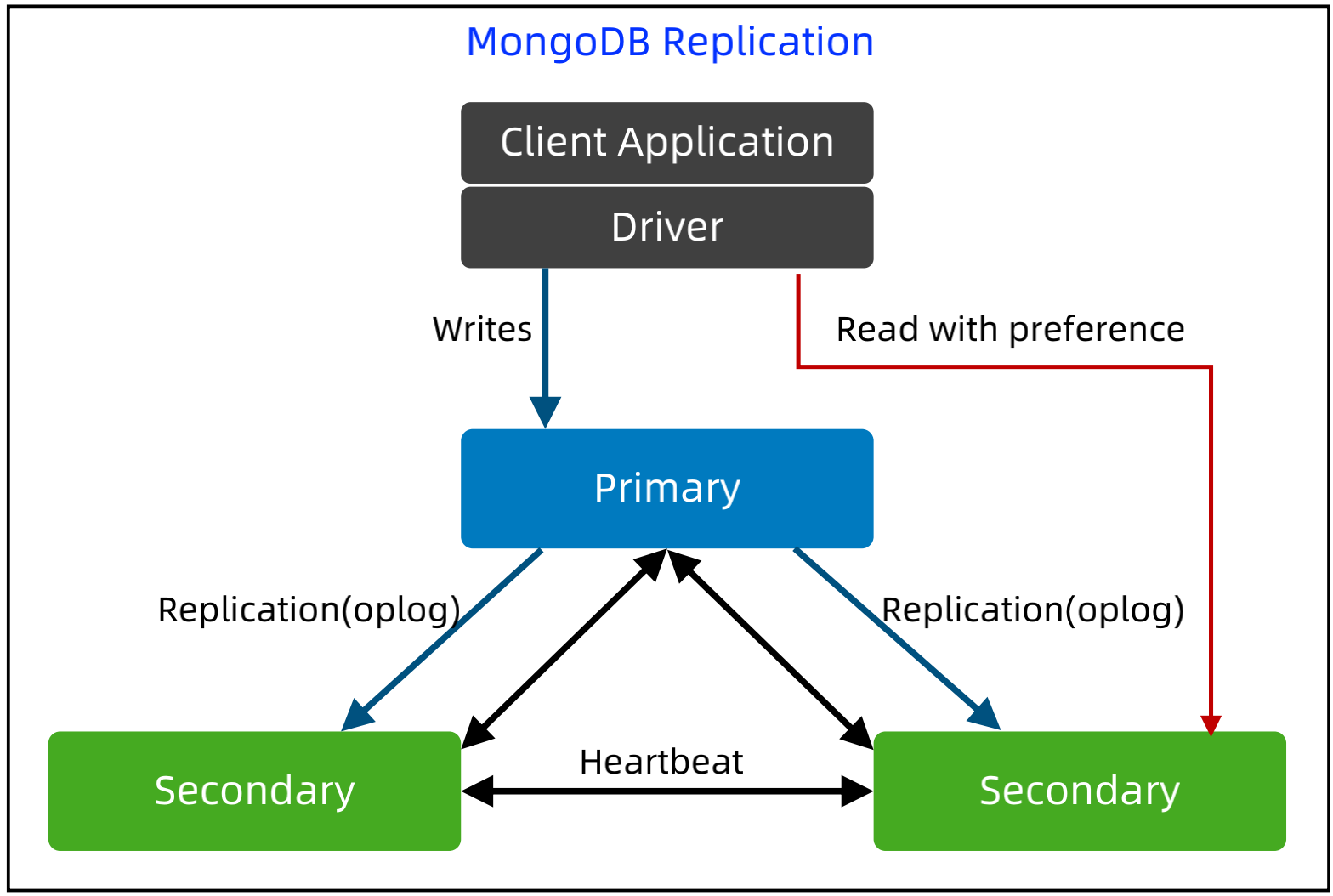
MongoDB Replication 架构技巧 - Read preference
基本实现:
默认读 Primary,但是可以通过 API 或者连接配置参数指定 read preference 来读取 Secondary,如果读Sencondary,可能读不到最新数据。为了保证事务一致性,事务必须读 Primary。
包含5种 preference:primary,primaryPreferred, secondary,secondaryPreferred, nearest.
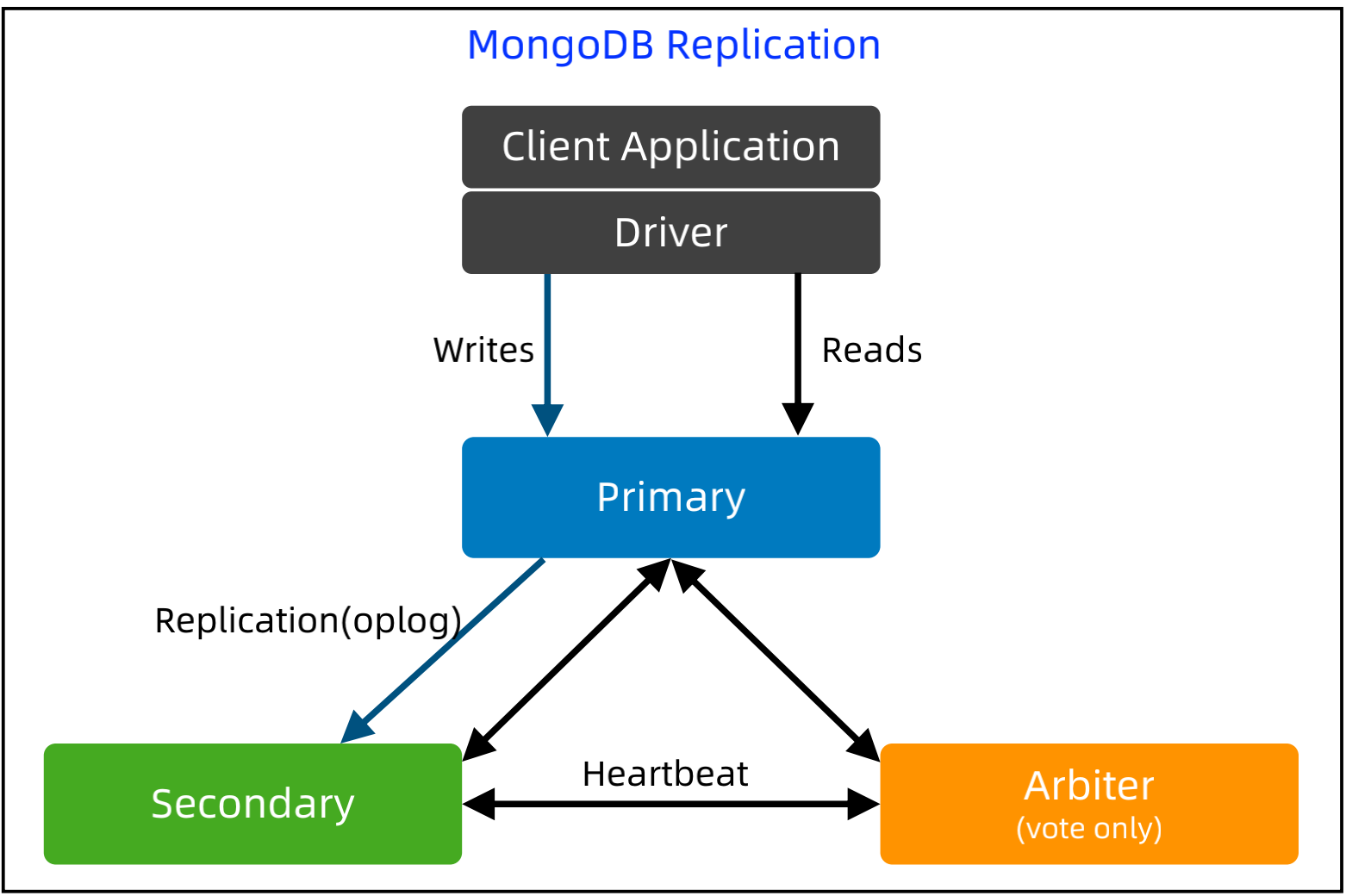
MongoDB Replication 架构技巧 - Arbiter
基本实现:
Arbiter 只投票,不复制数据。Arbiter 永远是 Arbiter,相当于“仲裁者”。引入Arbiter主要是为了在主从架构时做集群选举。
四、分片架构设计技巧
1、Elasticsearch 集群设计技巧
ES基本架构:
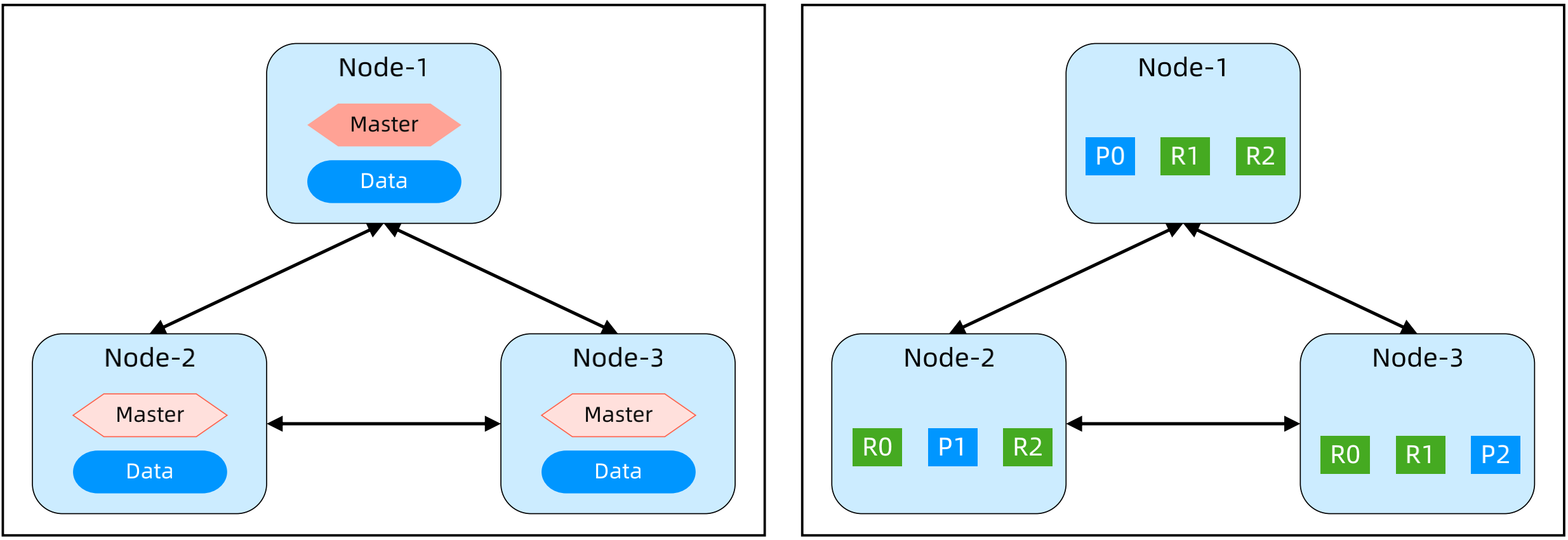
节点可以配置为不同角色,通过选举 Master 管理集群。Coordinating:协调节点;Master:管理节点;Data:数据存储节点;
数据是按照索引分片的,而不是按照节点分片,每个分片可以有多个副本来保证高可用,例如图中 P0 有2个 R0 副本。
ES 的选举:
先根据节点的 clusterStateVersion 比较,clusterStateVersion 越大,优先级越高。clusterStateVersion 相同时,进入 compareNodes,其内部按照节点的 ID 比较(ID 为节点第一次启动时随机生成)。
Zen Discovery 采用了很多分布式共识算法中的想法,但只是有机地采用,并没有严格按照理论所规定的那个模型,7.0 是基于Raft 但不全是 Raft。
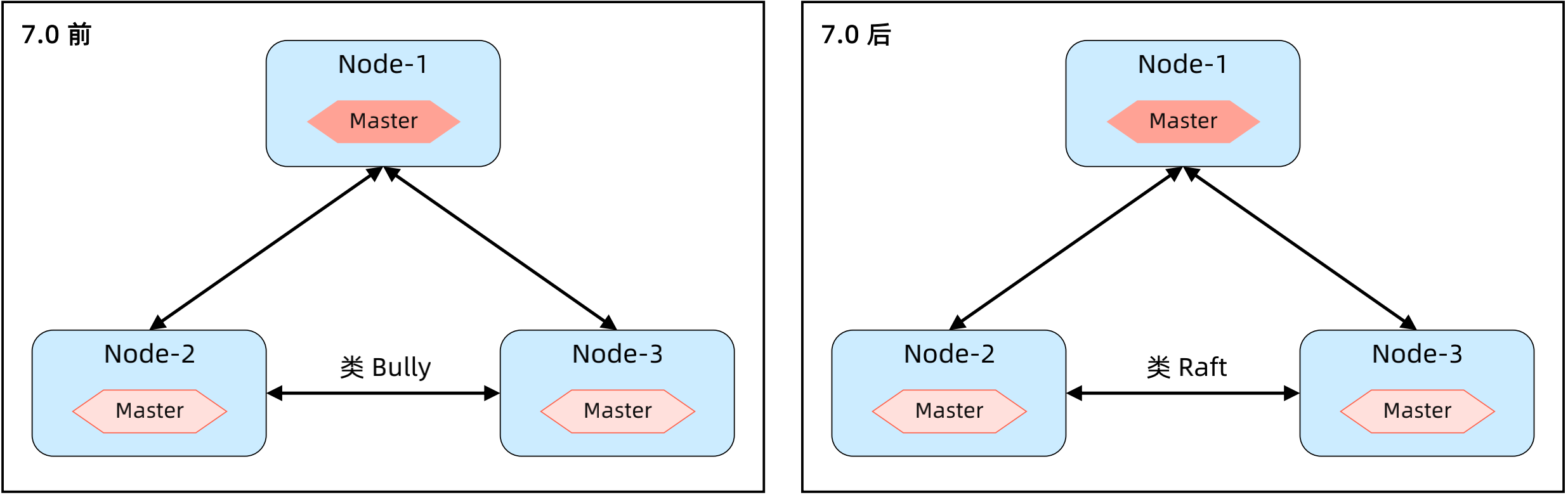
ES 的部署架构模式 – Master 和 Data 混合部署
节点同时配置为 Master 和 Data;每个节点都可以接收和处理客户端请求,写入操作会转发到数据主分片的 Node;适用于数据量不大的业务。
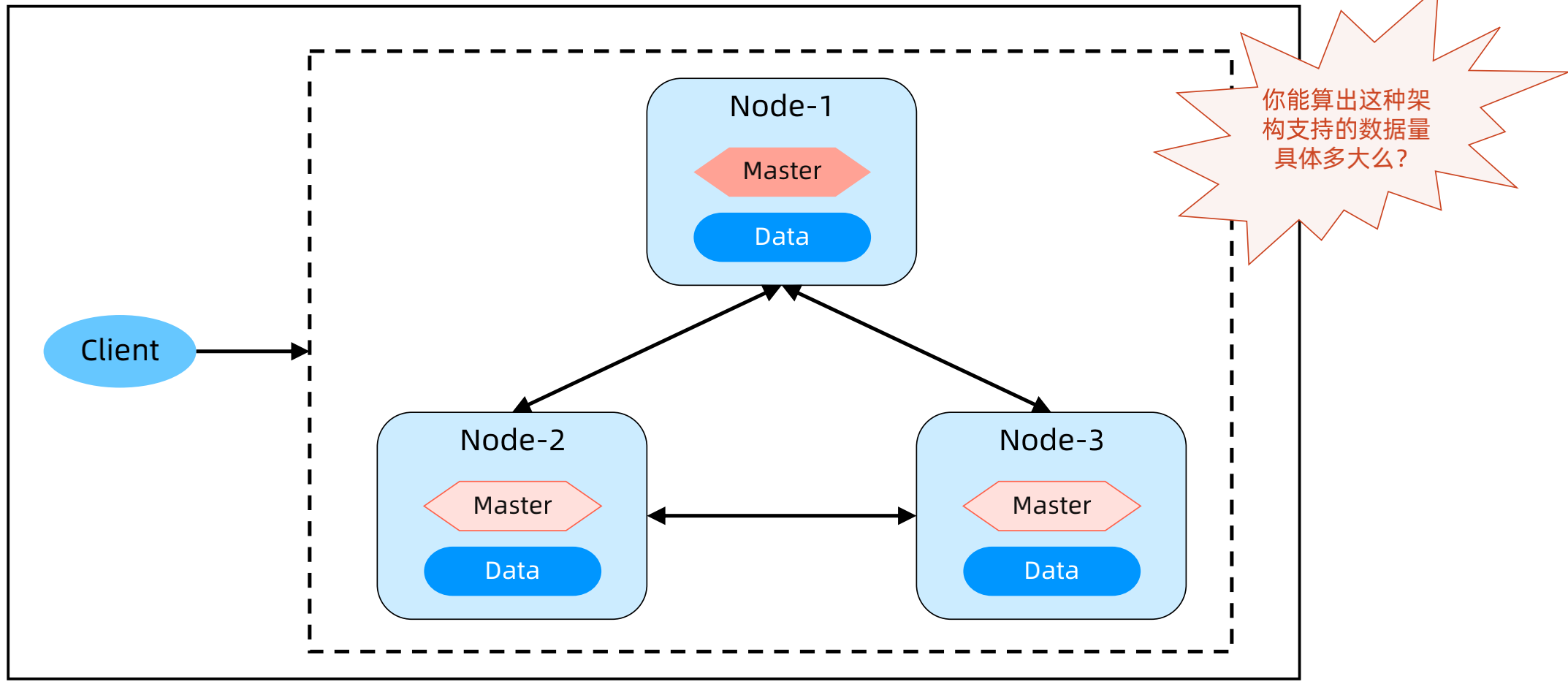
ES 的部署架构模式 – Master 和 Data 分离部署
Master 节点和 Data 节点分离配置,Master 节点数量3个或者5个,Data 节点数量可以几十个;
Master 节点不处理读写请求,只负责集群管理,Data 节点处理读写请求和数据存储;
适用于数据量比较大的业务。
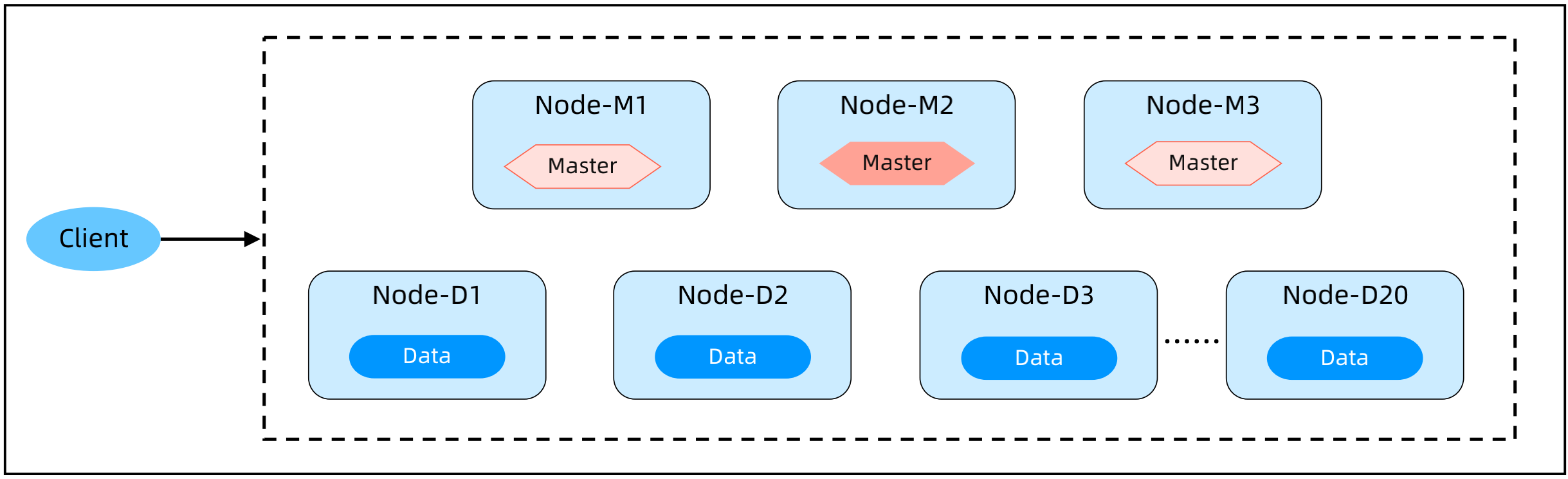
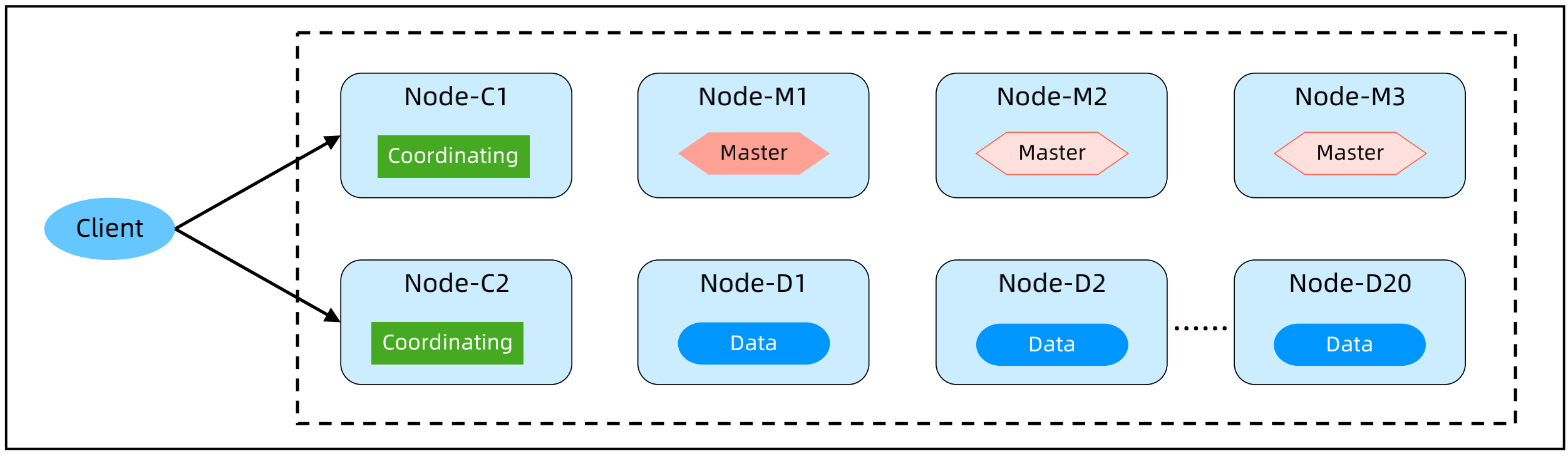
ES 的部署架构模式 – Coordinating 分离部署
Master 节点数量3个或者5个,Data 节点数量可以几十个,Coordinating 节点2个以上;
Master 节点不处理读写请求,只负责集群管理,Coordinating 负责读写聚合,Data 节点负责数据存储;
适用于数据量比较大,读写请求比较复杂的业务。
ES 部署架构模式 - Cross cluster replication
配置两个集群为 Cross cluster replication,Leader 负责数据读写,Follower 复制数据,负责数据读取;
适用场景:本地化、聚合存储
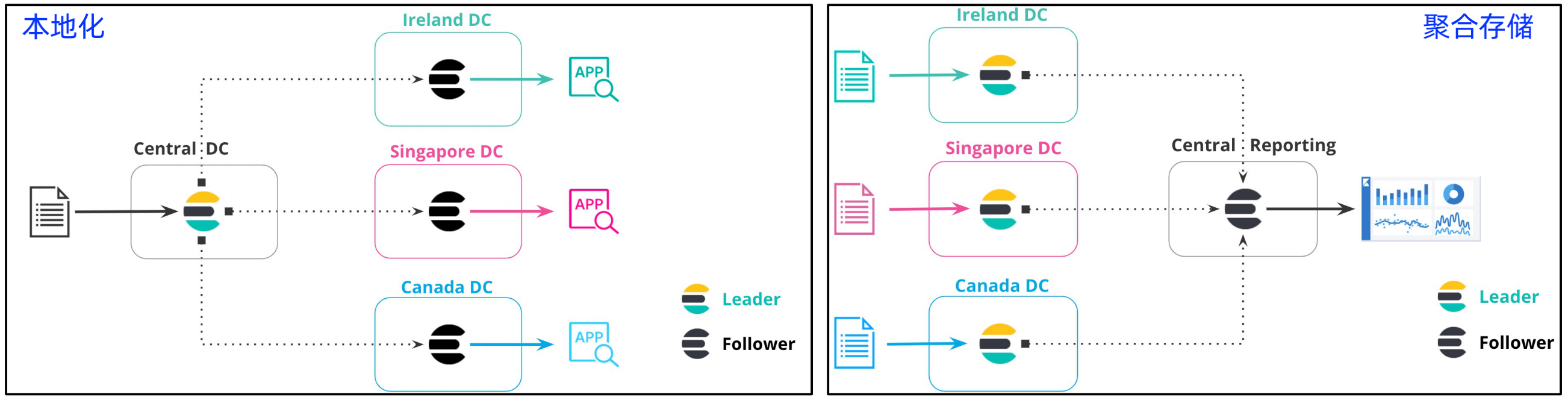
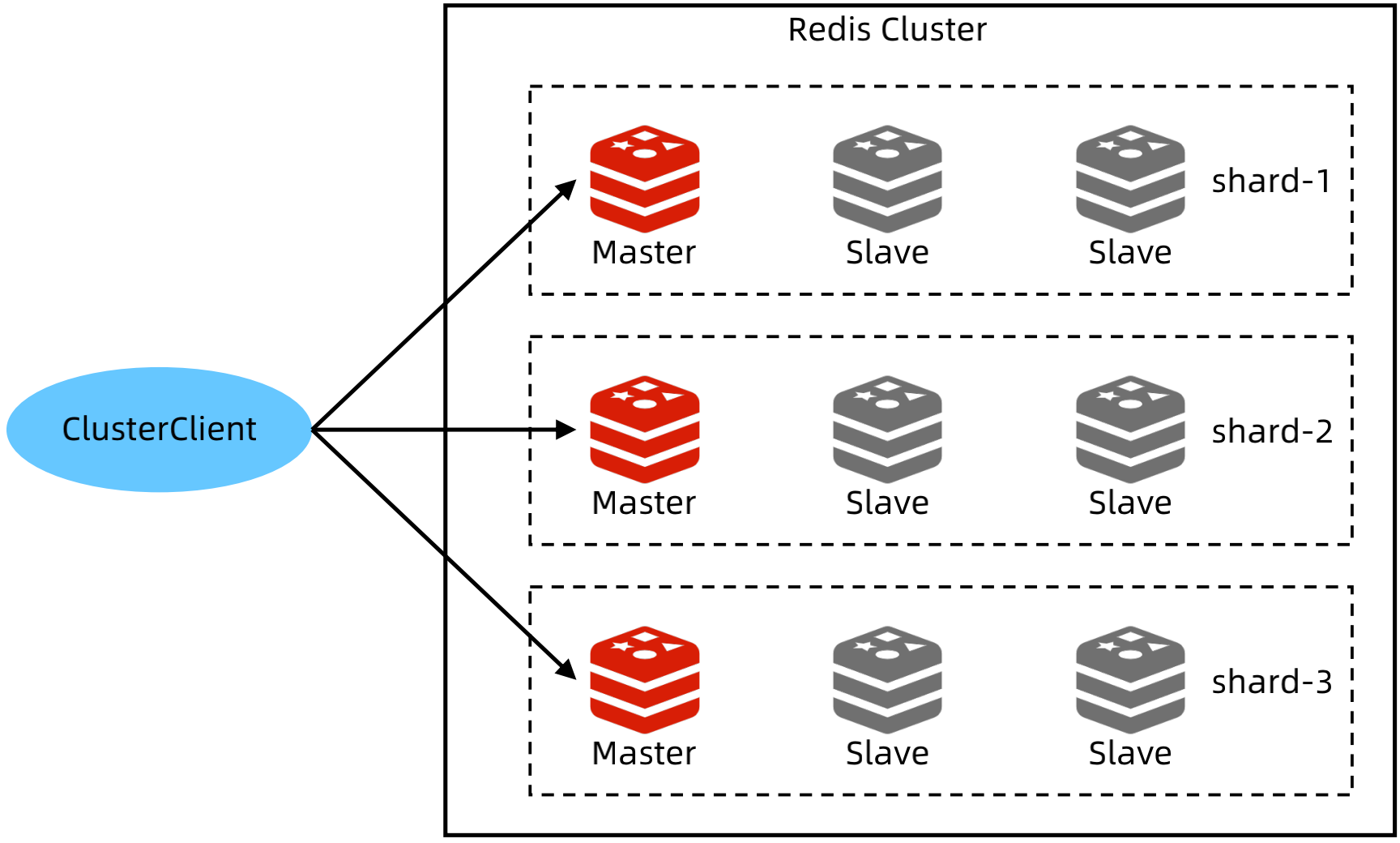
2、Redis cluster 设计技巧
Redis Cluster 基本架构
Cluster 分为多个分片,不同分片保存不同数据;每个分片内部通过主备复制来保证可用性;分片内部自动实现 Master 选举,但不依赖Sentinel,Cluster 本身具备分片选举的能力;
客户端连接集群需要特定的实现,例如jedisCluster,因为 Cluster 有特有的 Redis 命令。
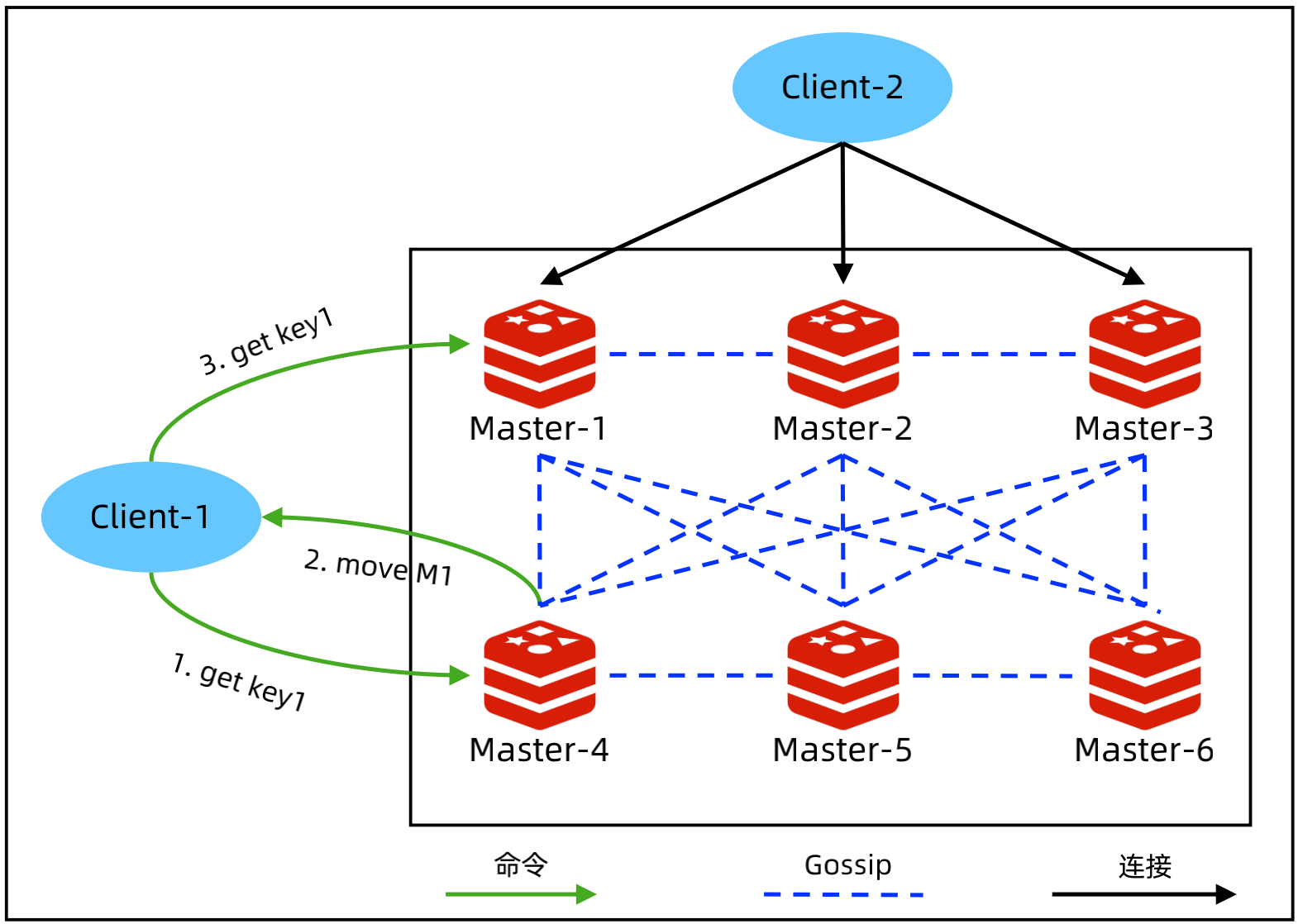
Redis 数据分布和路由
所有 key 按照 Hash 算法分为16384个槽位,然后将槽位分配给分片;节点之间通过 Gossip 交换信息,节点变化的时候会自动更新集群信息;每个节点都有所有 key 的分布信息;
Client 连接任意节点,由节点用 move 指令来告诉实际的数据位置
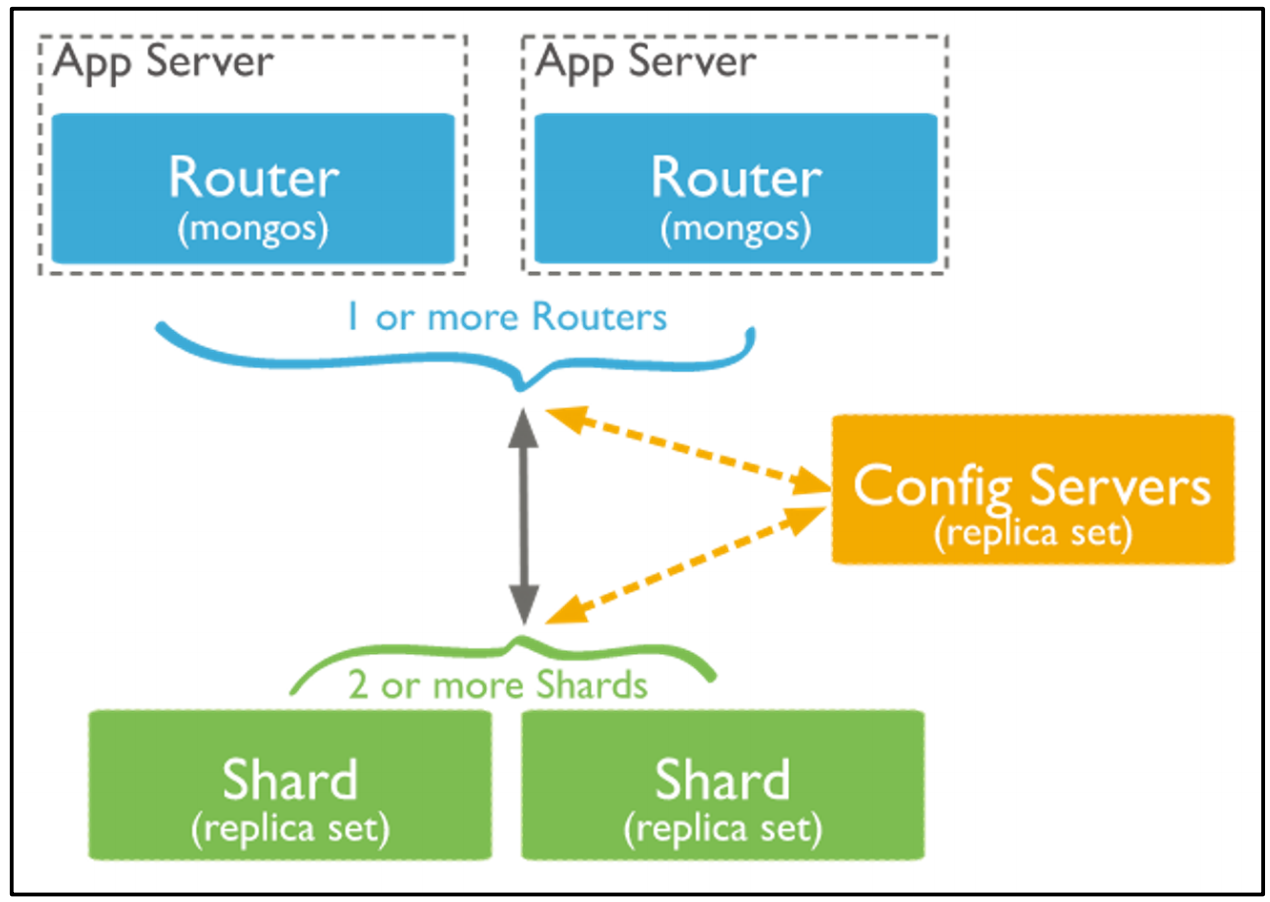
3、MongoDB/HDFS 集群设计技巧
MongoDB sharding 架构
mongos:独立部署的代理程序,应用程序请求发给 mongos;可以和应用程序部署在一起,也可以和 Shard 服务器部署在一起;为了提升性能,mongos 会缓存 Config Server 上保存的 cluster配置信息.
Config Server:存储集群的元数据;自身通过 replica set 保证高可用;当 Config Server 挂掉的时候,cluster 进入 read only。
Shard:存储分片数据的服务器;自身通过 replica set 保证高可用,如果全部挂掉,分片就无访问了。
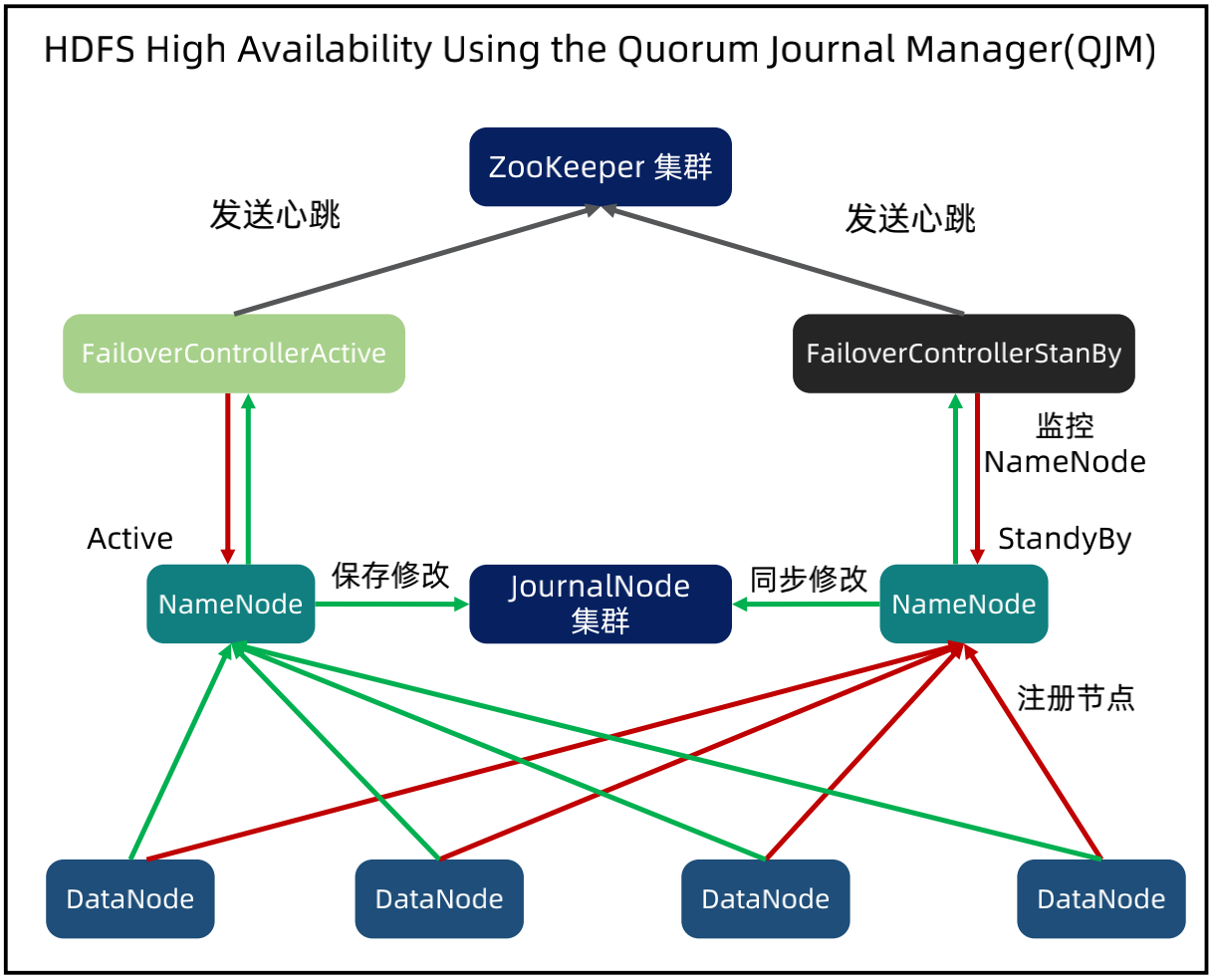
HDFS 架构
NameNode:集群管理节点,保存集群元数据,管理集群(平衡、分配等)。
DataNode:存储实际的数据,数据按照 block 存储。
JournalNode:当 Active NameNode 修改集群状态后,会写日志到 JournalNode 集群里面;StandBy NameNode 会监听 JournalNode,发生变化的时候会拉取日志;JournalNode 至少3个,达到多数日志复制写入才算成功。
FailoverController:NameNode 节点内的一个独立进程,监控 NameNode 状态;依赖 ZooKeeper 做高可用。
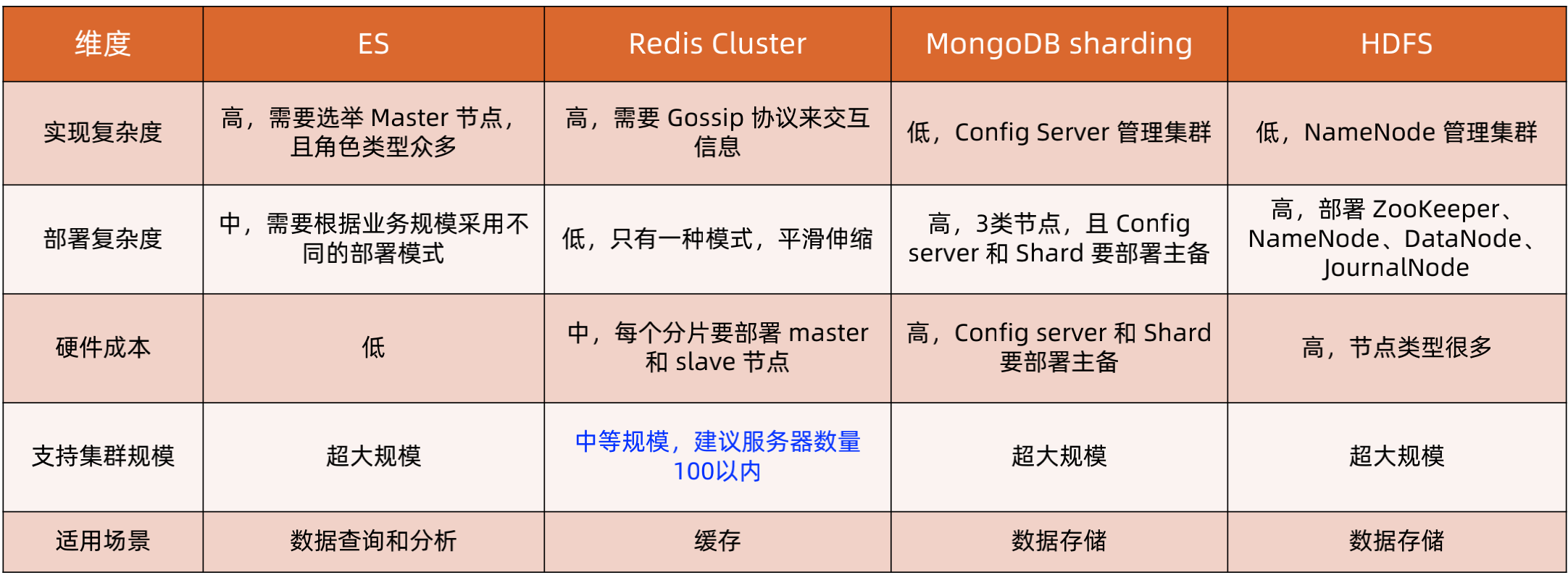
各个架构的简单分析对比
五、常见集群算法解析
1、Gossip 协议
定义:Gossip protocol,又叫 Epidemic Protocol (流行病协议),也叫“流言算法”、“疫情传播算法”等。其名称已经形象的说明了算法的原理和工作方式。
其可以应用在分布式网络无集中管理节点的场景,也可以用于节点间点对点传播信息。典型的应用是P2P、Bitcoin(比特币)、Apache Cassandra、Redis cluster等
优点:简单(体现在扩展性、容错性、去中心化);扩展性:(网络节点可任意增加和修改);容错性:(无中心节点,任意节点宕机不影响协议运行);去中心化:(任意节点都可以发送消息)。
缺点:只能保证最终一致性;且需要花费一定时间达到最终一致性;由于消息传递的特性,会造成消息冗余;不适合超大规模集群(超过1000);恶意节点传播垃圾信息。
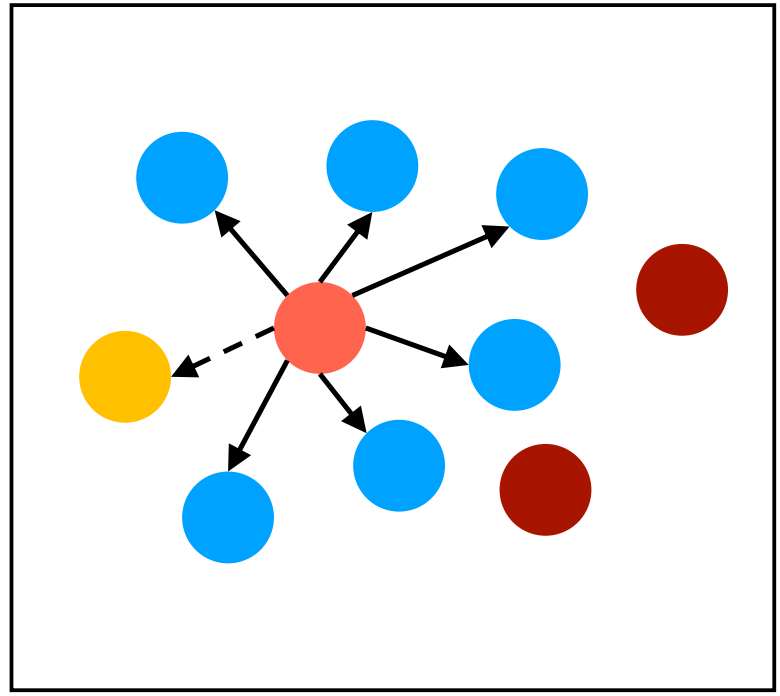
(1)Gossip 模式1 - Direct Mail
直邮模式:通知所有邻居更新信息,邻居节点收到消息后不会转发。
优点:简单。
缺点:
难以达到最终一致性(节点消息可能丢失(图中黄色节点);节点可能并没有连接(图中深红色节点)。)
容错性低:需要缓存发送失败的消息。
种子节点压力大
应用场景:社交网络(朋友的朋友并不一定是你的朋友)。
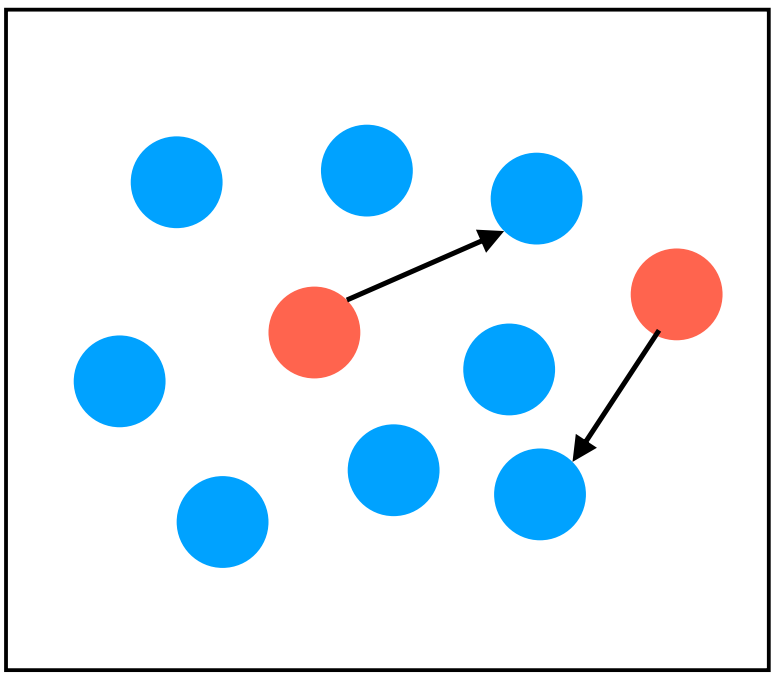
(2)Gossip 模式2 - Anti-Entropy
反熵模式:集群中的节点,每隔一段时间随机选择1个节点,互相交换所有数据,然后进行同步,消除数据不一致。
优点:最终一致性。
缺点:
信息同步的成本高:checksum;updated list。
达到最终一致性的耗时较长。
应用场景:节点数量不多,实现最终一致性,例如存储系统多副本一致性。
(3)Gossip 模式3 - Rumor mongering
谣言传播:收到更新消息后,自己成为“受感染节点”,周期性的传播更新消息,如果发现其它节点已经知道了消息,则按照一定概率将自己变为 removed,不再传播消息。
优点:最终一致性;传播信息少;达到一致性所需时间少。
缺点:有一定概率可能不一致,因为判断为removed是使用算法判断的,有可能判断错误;节点数量不能太多,Redis 官方文档最大1000。
应用场景:节点经常变化的集群。

2、Bully 选举算法
Bully 算法:当一个进程发现协调者(或 Leader)不再响应请求时,就判定其出现故障,于是它就发起选举,选出新的协调者,即当前活动进程中进程号最大者。Bully 的中文意思是“霸凌”,但实际实现的时候,找最小的节点也可以,关键点在于“最”。
Bully 算法的关键假设:系统是同步的;进程在任何时候都可能失败,包括算法在执行的过程中;进程失败后停止工作,重启后重新工作;有失败监控者,它可以发现失败的进程;进程之间消息传递是可靠的;每一个进程知道自己和其他每一个进程的 ID 以及地址。
Bully 算法选举过程:
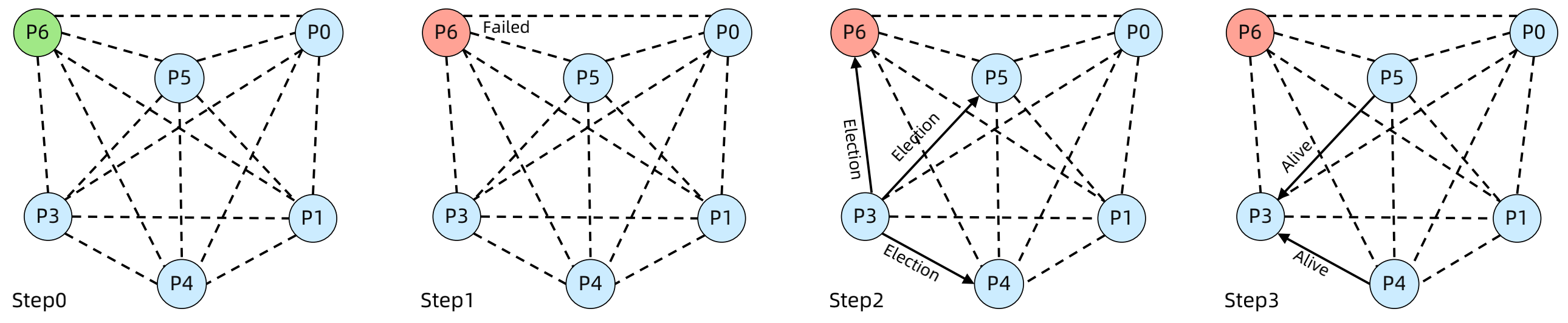
step0:初始状态,P6 为 Leader;
step1:P6 故障;
step2:P3 检测到 P6 故障,发起选举,向 P4、P5、P6 发送 Election 消息;
step3:P4、P5 回复 P3 Alive 消息,说明自己还活着,P3 退出选举,等待 Victory 消息。
step4:P4向P5、P6发送 Election 消息;
step5:P5回复P4 Alive 消息,P4退出选举,等待 Victory 消息;
step6:P5向P6发送 Election 消息;
step7:P5未收到 Alive 消息,成功当选,向所有节点发送 Victory 消息,选举结束。

3、Raft 选举算法
关键点:容易理解(Raft 作者说几个研究人员研究了1年还不是很明白 Paxos);算法明确划分为选举、复制、安全三个子问题。
(1)Raft 实现1 - leader 选举
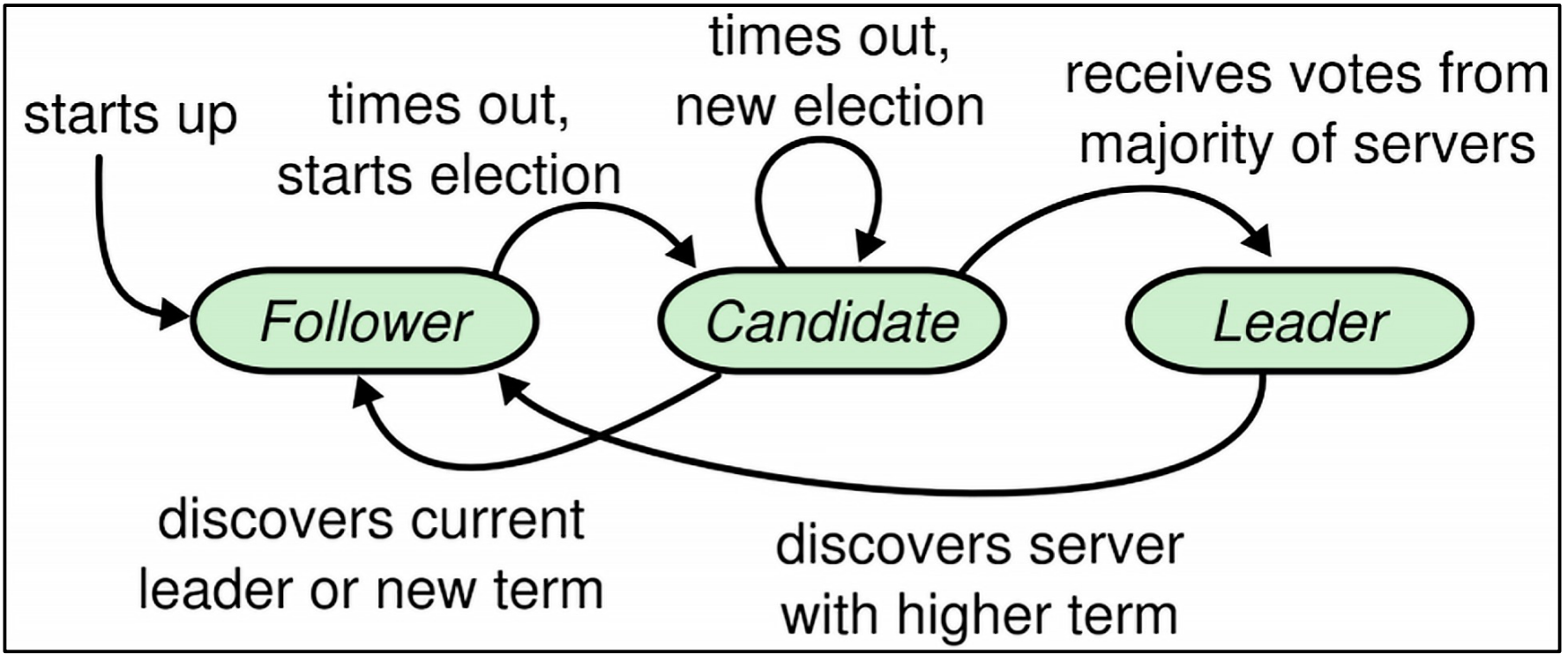
Raft中有三种节点:leader、follower、candidate,当集群正常时,存在Leader和follower,当leader故障时,可以选举成为leader的节点就会变为candition(候选人)节点。
在标准的Raft协议中,leader的级别是非常高的,只有leader节点可以接收读写请求,而follower节点只能备份数据和leader宕机后的选举;如果集群出现故障,再没有选举出来leader之前,集群是不可用的。
但是标准协议在实际应用时又很难达到性能要求,因此会做一些调整,例如etcd号称使用raft算法,但是其不需要分布式一致性协调的操作就允许直接发给follower节点。
(2)Raft 实现2 - 日志复制
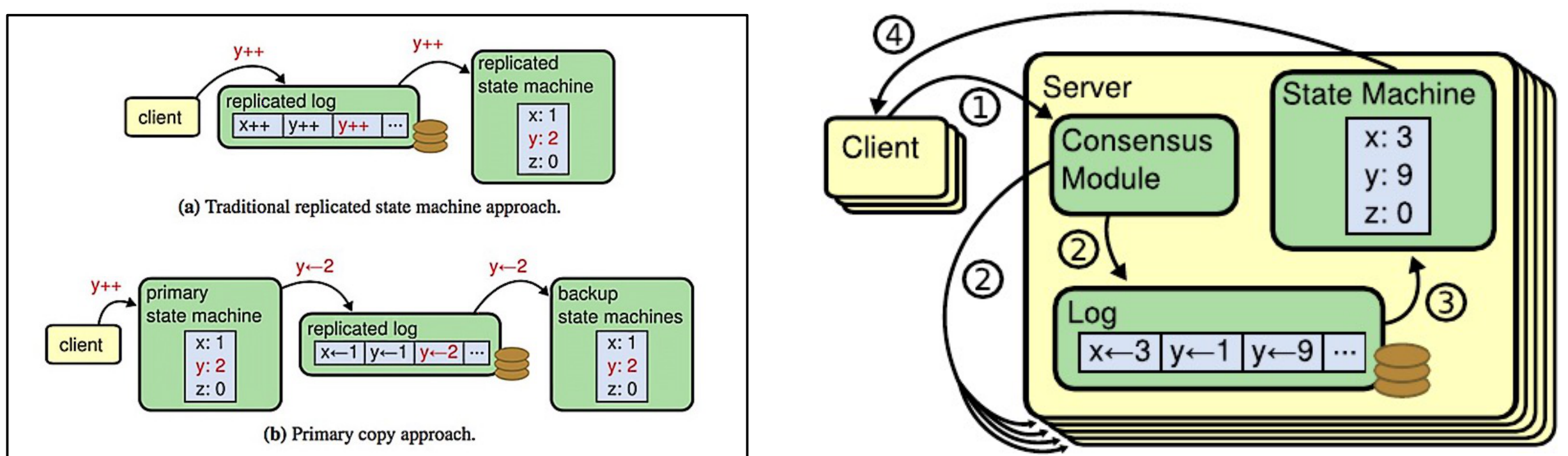
首先说两种数据复制方式:State machine replication:复制状态机,复制的是命令而不是数据,典型代表:Raft和Paxos。例如下图中复制的是x++或者y++的操作,至于命令执行后的结果是什么,是需要每个节点在自己的状态机中应用这条命令,才能计算出来。
Primary-backup system:主备复制,复制的是命令执行后的数据,具体执行是由primary(leader or master)来执行的,然后将执行结果同步给follower节点,典型代表:ZooKeeper 的 ZAB。
两者差别:是否能够容忍“非拜占庭错误”。也就是说如果集群中一个节点出现问题,当前节点中的数据异常,其他的节点是否能够识别出问题,对于Primary-backup system来说,follower复制的都是leader的计算结果,如果leader节点出现问题,那么follower节点是不能发现问题的,也就是不能够容忍拜占庭错误;而对于State machine replication来说,follower复制的是命令,每个节点都需要计算最后投票决定,如果其他节点没有被破坏,就可以很容易发现被破坏的节点,也就是说可以容忍拜占庭错误。
Raft的实现:每个节点都有一个状态机和一致性模块,由一致性模块保证分布式一致性,节点之间复制的是 client 发送的命令,无论读写请求都需要进行一致性处理,因此可以容忍非拜占庭故障。
Raft vs ZAB vs Paxos
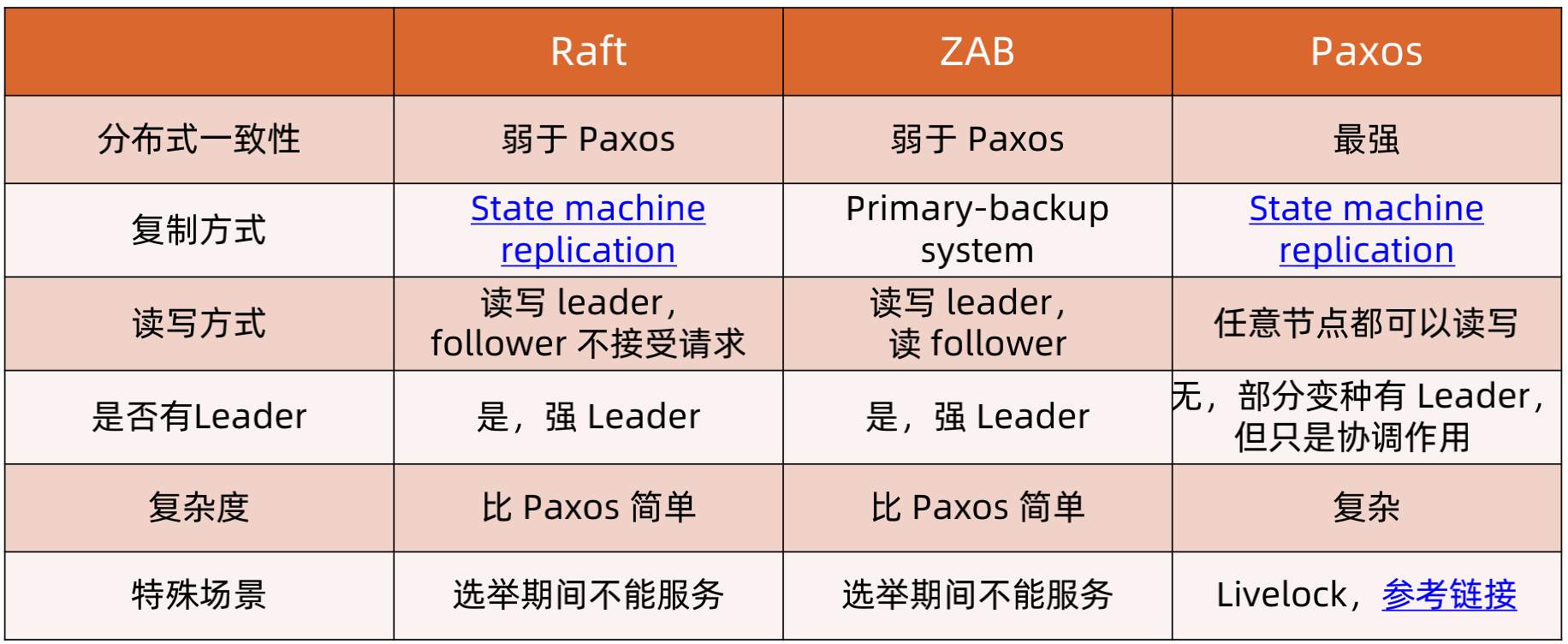
Raft、ZAB、Paxos算法的对比主要可以从分布式一致性、复制方式、读写方式、是否有Leader、复杂度、特殊场景六个方面进行对比。
分布式一致性,Raft和ZAB都是弱一致性,而Paxos是强一致性
复制方式:Raft和Paxos是State machine replication,复制的是命令,而zab是primary-backup system,复制的是计算后的结果
读写方式:Raft是读写Leader,follower不接受请求,zab写只能写leader,读可以读leader和follower,pasos的任意节点都可以读写。
是否有leader:Raft和ZAB都是有leader的,并且是强leader;而Paxos没有Leader,不过有的变种Paxos是存在leader的,但是也是弱leader,只负责协调。
复杂度:Raft和ZAB比Paxos要简单
特殊场景:Raft和ZAB选举期间不能服务;而Paxos可能存在活锁。
Raft vs ZooKeeper的选择:
如果你想内嵌分布式选举或者一致性功能,或者基于业务特性做一些小调整,选择 Raft,例如 MongoDB、etcd 等;
如果你想实现分布式选举或者一致性,但是不想自己去实现协议代码,选择 ZooKeeper,例如 HDFS、Cassandra 等;
如果你不确定,请选择 ZooKeeper。
Raft 的资源:
六、消息队列代码实战
1、基于 Netty 搭建网络模型
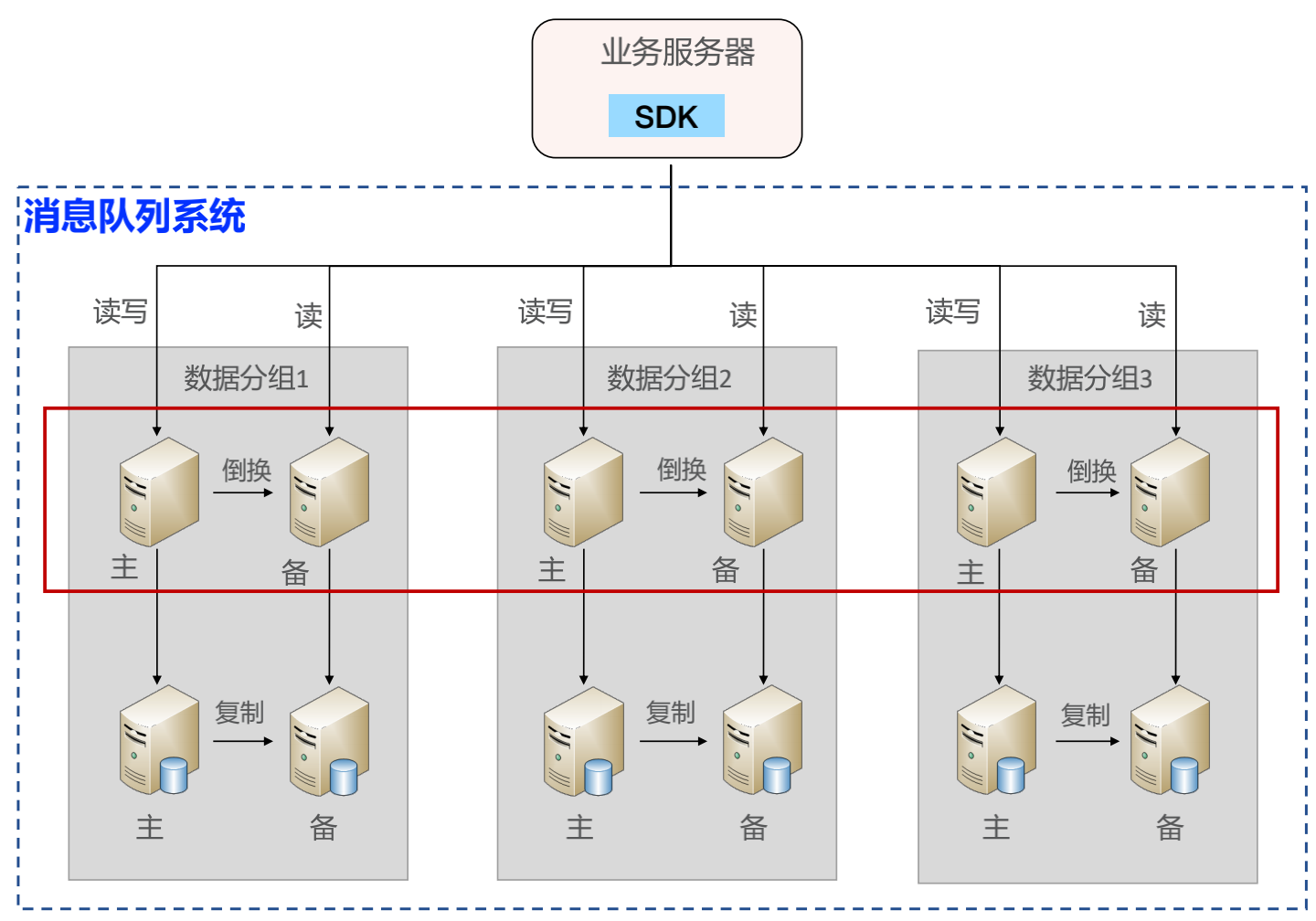
自研集群 + MySQL 存储:Java 语言编写消息队列服务器;消息存储采用 MySQL;SDK 轮询服务器进行消息写入;SDK 轮询服务器进行消息读取;MySQL 双机保证消息尽量不丢;使用 Netty 自定义消息格式,并且支持HTTP 接口。
Java 语言开发,选择 Netty 作为底层网络框架,采用多 Reactor 多线程模式。
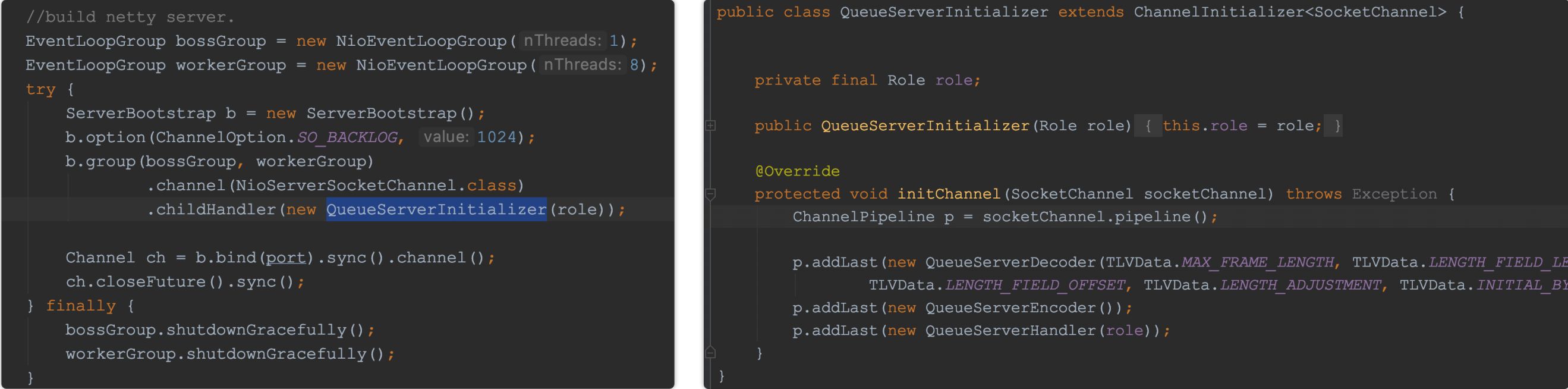
通讯协议:
gRPC:成熟框架,通过 IDL 支持多语言;性能好,底层使用 HTTP/2;基于 Protocol Buffer,性能好,可扩展;实现要复杂一些。
TLV:实现简单;可扩展;性能不如 gRPC。
HTTP:实现简单;可扩展;支持异构系统,无需嵌入 SDK;性能不如 gRPC 和 TLV。
代码示例:
2、基于 ZooKeeper 主备切换方案
(1)设计 Path
分片之间互相独立,每个分片只有2个角色:master 和 slave,因此分片目录设计为:/com/arch/queue/{systemName}/{groupName}。
(2)选择节点类型
当 master 节点挂掉的时候,原来的 slave 要激活,接收client的读消息请求,因此用 ephemeral 类型的 znode。
(3)设计节点数据
由于数据只从 MySQL 主机复制到 MySQL 备机,因此不需要解决冲突问题,无需写入节点数据。
(4)设计 Watch
master 节点只会创建 master znode,slave 只会创建 slave znode,且 master 无需关注 slave 状态,slave 需要 watch master状态。
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号