
线上问题排查及GC排查案例
一、线上问题分类及排查手段
如果发现线上服务变慢等情况,应该如何排查?
1、查询业务日志:
可以发现这类问题:请求压力大,波峰,遭遇降级,熔断等等, 基础服务、外部 API 依赖出现故障。
2、查看系统资源和监控信息:
硬件信息、操作系统平台、系统架构;
排查 CPU 负载、内存不足,磁盘使用量、硬件故障、磁盘分区用满、IO 等待、IO 密集、丢数据、并发竞争等情况;
排查网络:流量打满,响应超时,无响应,DNS 问题,网络抖动,防火墙问题,物理故障,网络参数调整、超时、连接数。
3、查看性能指标,包括实时监控、历史数据。可以发现假死,卡顿、响应变慢等现象;
排查数据库, 并发连接数、慢查询、索引、磁盘空间使用量、内存使用量、网络带宽、死锁、TPS、查询数据量、redo 日志、undo、 binlog 日志、代理、工具 BUG。可以考虑的优化包括: 集群、主备、只读实例、分片、分区;
可能还需要关注系统中使用的各类中间件。
4、排查系统日志, 比如重启、崩溃、Kill 。
5、APM,比如发现有些链路请求变慢等等。
6、排查应用系统
排查配置文件: 启动参数配置、Spring 配置、JVM 监控参数、数据库参数、Log 参数、内存问题,比如是否存在内存泄漏,内存溢出、批处理导致的内存放大等等;
GC 问题, 确定 GC 算法,GC 总耗时、GC 最大暂停时间、分析 GC 日志和监控指标: 内存分配速度,分代提升速度,内存使用率等数据,适当时修改内存配置;
排查线程, 理解线程状态、并发线程数,线程 Dump,锁资源、锁等待,死锁;
排查代码, 比如安全漏洞、低效代码、算法优化、存储优化、架构调整、重构、解决业务代码 BUG、第三方库、XSS、CORS、正则;
7、可以在性能测试中进行长期的压测和调优分析。
8、其他:
假设我们有一个提供高并发请求的服务,系统使用 Spring Boot框架,指标采集使用MicroMeter ,监控数据上报给 Datadog 服务。
当然,Micrometer支持将数据上报给各种监控系统, 例如: AppOptics, Atlas,Datadog, Dynatrace, Elastic, Ganglia, Graphite, Humio, Influx, Instana, JMX,KairosDB, New Relic, Prometh eus, SignalFx, Stackdriver, StatsD, Wavefront 等等。有关MicroMeter的信息可参考:https://micrometer.io/doc
二、线上问题分析实战
(一)问题现象描述
最近一段时间,通过监控指标发现,有一个服务节点的最大GC暂停时间经常会达到400ms以上。
如下图所示:
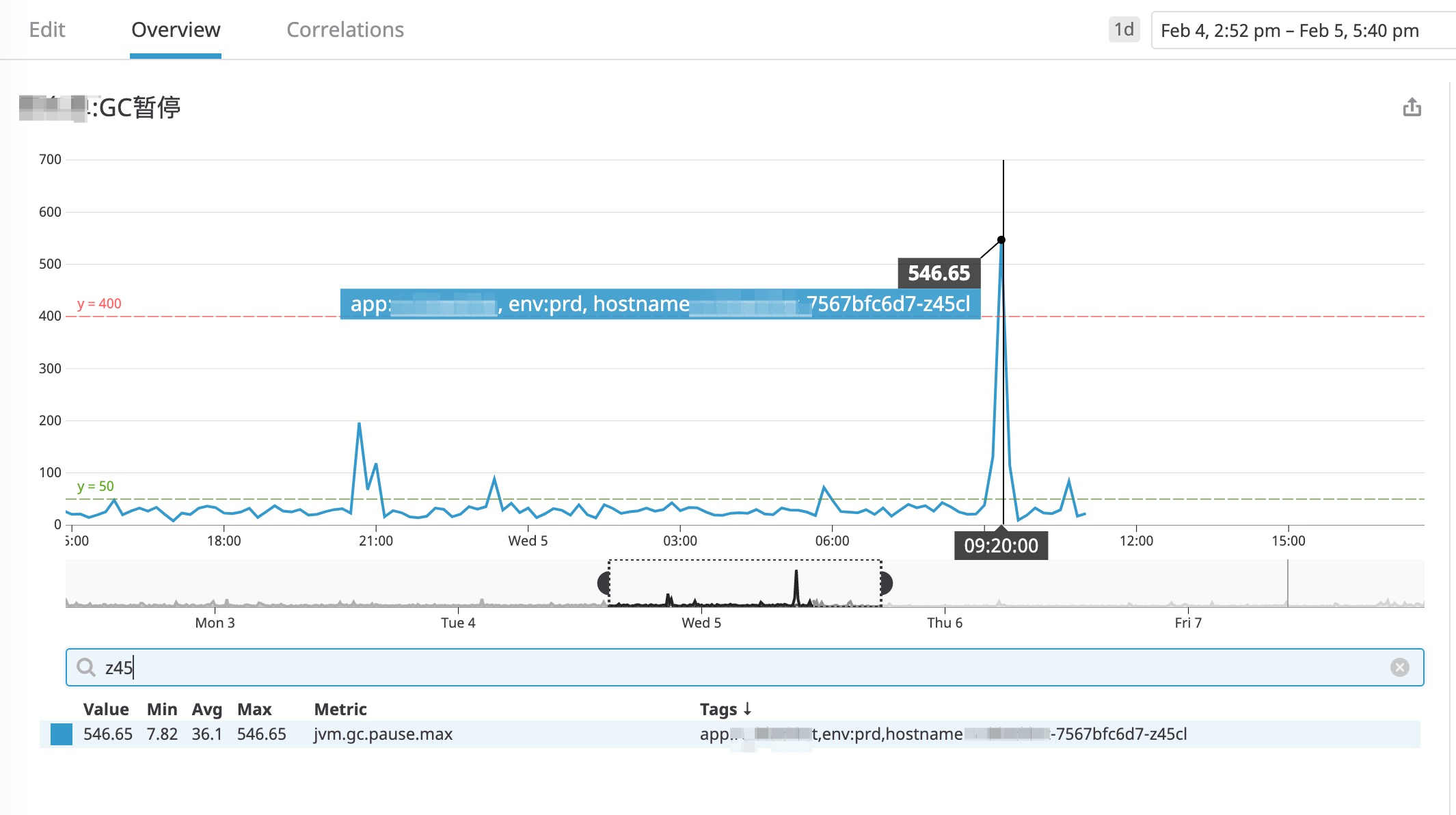
从图中可以看到,GC暂停时间的峰值达到了 546ms ,这里展示的时间点是 2020年02月04日09:20:00 左右。客户表示这种情况必须解决,因为服务调用的超时时间为1秒,要求最大GC暂停时间不超过200ms,平均暂停时间达到100ms以内,对客户的交易策略产生了极大的影响。
(二)排查与分析
1、CPU负载
CPU的使用情况如下图所示:
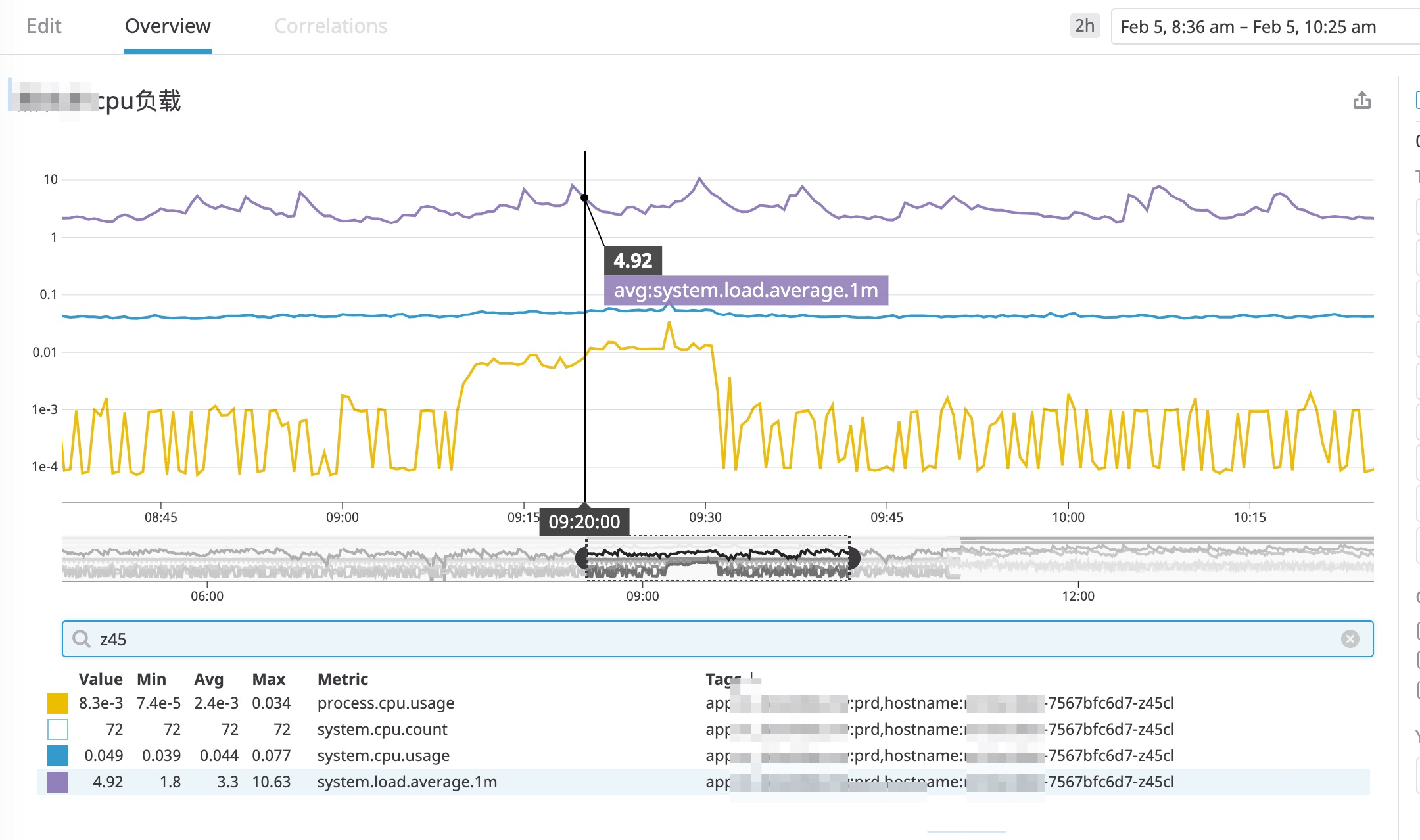
从图中可以看到:系统负载为 4.92 , CPU使用率 7% 左右,其实这个图中隐含了一些重要的线索,但我们此时并没有发现什么问题。
2、GC内存使用情况
然后我们排查了这段时间的内存使用情况:
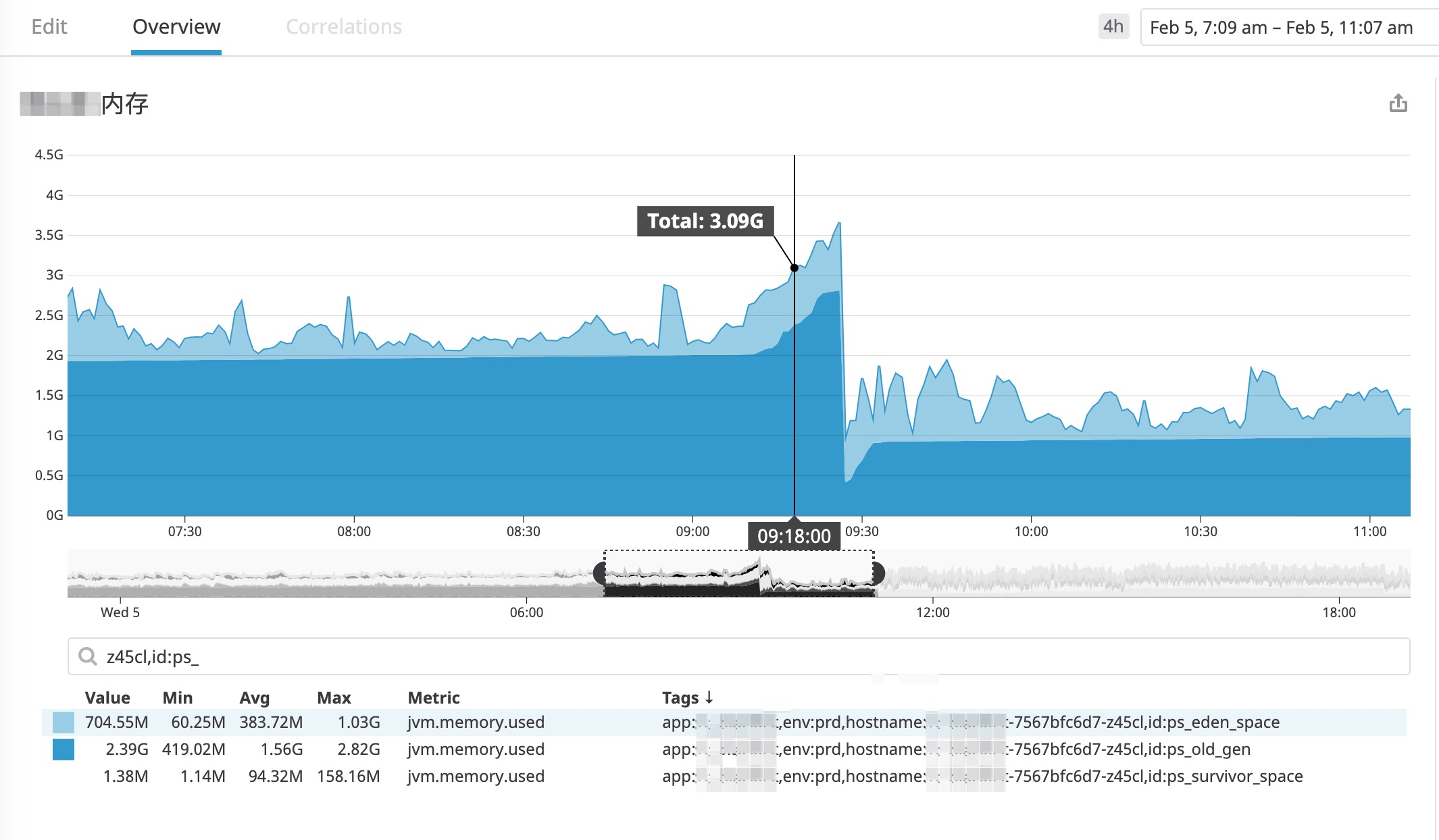
从图中可以看到,大约 09:25 左右 old_gen 使用量大幅下跌,确实是发生了FullGC 。但 09:20 前后,老年代空间的使用量在缓慢上升,并没有下降,也就是说引发最大暂停时间的这个点并没有发生FullGC。当然,这些是事后复盘分析得出的结论。 当时对监控所反馈的信息并不是特别信任,怀疑就是触发了FullGC导致的长时间GC暂停。
为什么有怀疑呢,因为Datadog这个监控系统,默认10秒钟上报一次数据。 有可能在这10秒内发生些什么事情但是被漏报了(当然,这是不可能的,如果上报失败会在日志系统中打印相关的错误)。
再分析上面这个图,可以看到老年代对应的内存池是 " ps_old_gen ",通过前面的学习,我们知道, ps 代表的是 ParallelGC 垃圾收集器。
3、JVM启动参数
查看JVM的启动参数,发现是这样的:
‐Xmx4g ‐Xms4g
我们使用的是JDK8,启动参数中没有指定GC,确定这个服务使用了默认的并行垃圾收集器。于是怀疑问题出在这款垃圾收集器上面,因为很多情况下 ParallelGC 为了最大的系统处理能力,即吞吐量,而牺牲掉了单次的暂停时间,导致暂停时间会比较长。
(三)处理
怎么办呢? 准备换成G1,毕竟现在新版本的JDK8中G1很稳定,而且性能不错。然后换成了下面的启动参数:
# 这个参数有问题,启动失败 ‐Xmx4g ‐Xms4g ‐XX:+UseG1GC ‐XX:MaxGCPauseMills=50ms
结果启动失败, 忙中出错,参数名和参数值都写错了。修正如下:
‐Xmx4g ‐Xms4g ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50
接着服务启动成功,等待健康检测自动切换为新的服务节点,继续查看指标。
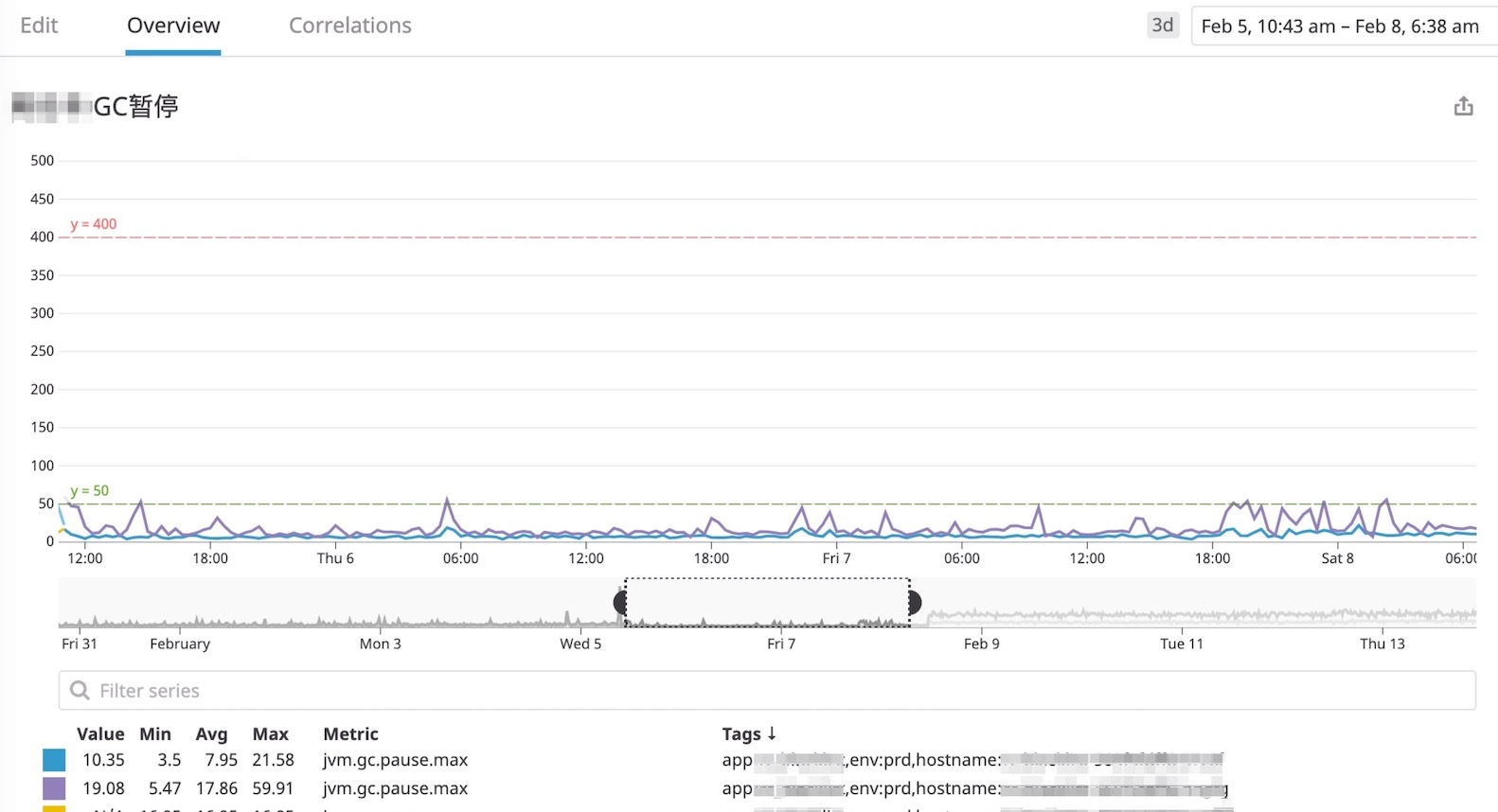
看看暂停时间,每个节点的GC暂停时间都降下来了,基本上在50ms以内,比较符合我们的预期。嗯!事情到此结束了?远远没有。
(四)产生新的问题
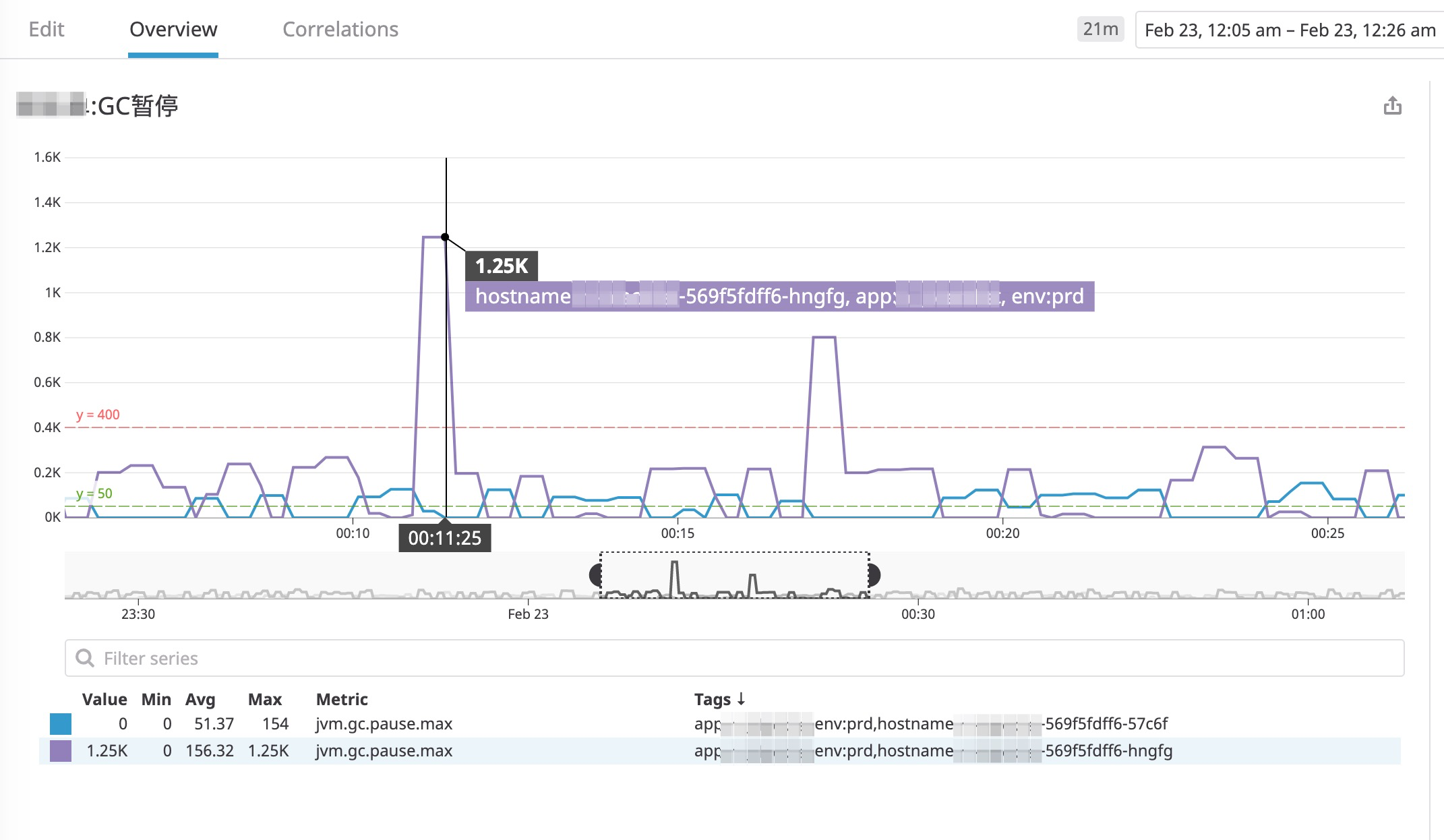
过了一段时间,我们发现了个下面这个惊喜(也许是惊吓),如下图所示:

中奖了,运行一段时间后,最大GC暂停时间达到了 1300ms 。情况似乎更恶劣了。继续观察,发现不是个别现象:
(五)继续排查与分析
1、注册GC事件监听
于是想了个办法,通过JMX注册GC事件监听,把相关的信息直接打印出来。关键代码如下所示:
// 每个内存池都注册监听 for (GarbageCollectorMXBean mbean : ManagementFactory.getGarbageCollectorMXBeans()) { if (!(mbean instanceof NotificationEmitter)) { continue; // 假如不支持监听... } final NotificationEmitter emitter = (NotificationEmitter) mbean; // 添加监听 final NotificationListener listener = getNewListener(mbean); emitter.addNotificationListener(listener, null, null); }
通过这种方式,我们可以在程序中监听GC事件,并将相关信息汇总或者输出到日志。再启动一次,运行一段时间后,看到下面这样的日志信息:
{ "duration":1869, "maxPauseMillis":1869, "promotedBytes":"139MB", "gcCause":"G1 Evacuation Pause", "collectionTime":27281, "gcAction":"end of minor GC", "afterUsage": { "G1 Old Gen":"1745MB", "Code Cache":"53MB", "G1 Survivor Space":"254MB", "Compressed Class Space":"9MB", "Metaspace":"81MB", "G1 Eden Space":"0" }, "gcId":326, "collectionCount":326, "gcName":"G1 Young Generation", "type":"jvm.gc.pause" }
情况确实有点不妙。这次实锤了,不是FullGC,而是年轻代GC,而且暂停时间达到了 1869 毫秒。一点道理都不讲,我认为这种情况不合理,而且观察CPU使用量也不高。找了一大堆资料,试图证明这个 1869 毫秒 不是暂停时间,而只是GC事件的结束时间减去开始时间。
2、打印GC日志
既然这些手段不靠谱,那就只有祭出我们的终极手段:打印GC日志。修改启动参数如下
‐Xmx4g ‐Xms4g ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50 ‐Xloggc:gc.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps
重新启动,希望这次能排查出问题的原因。
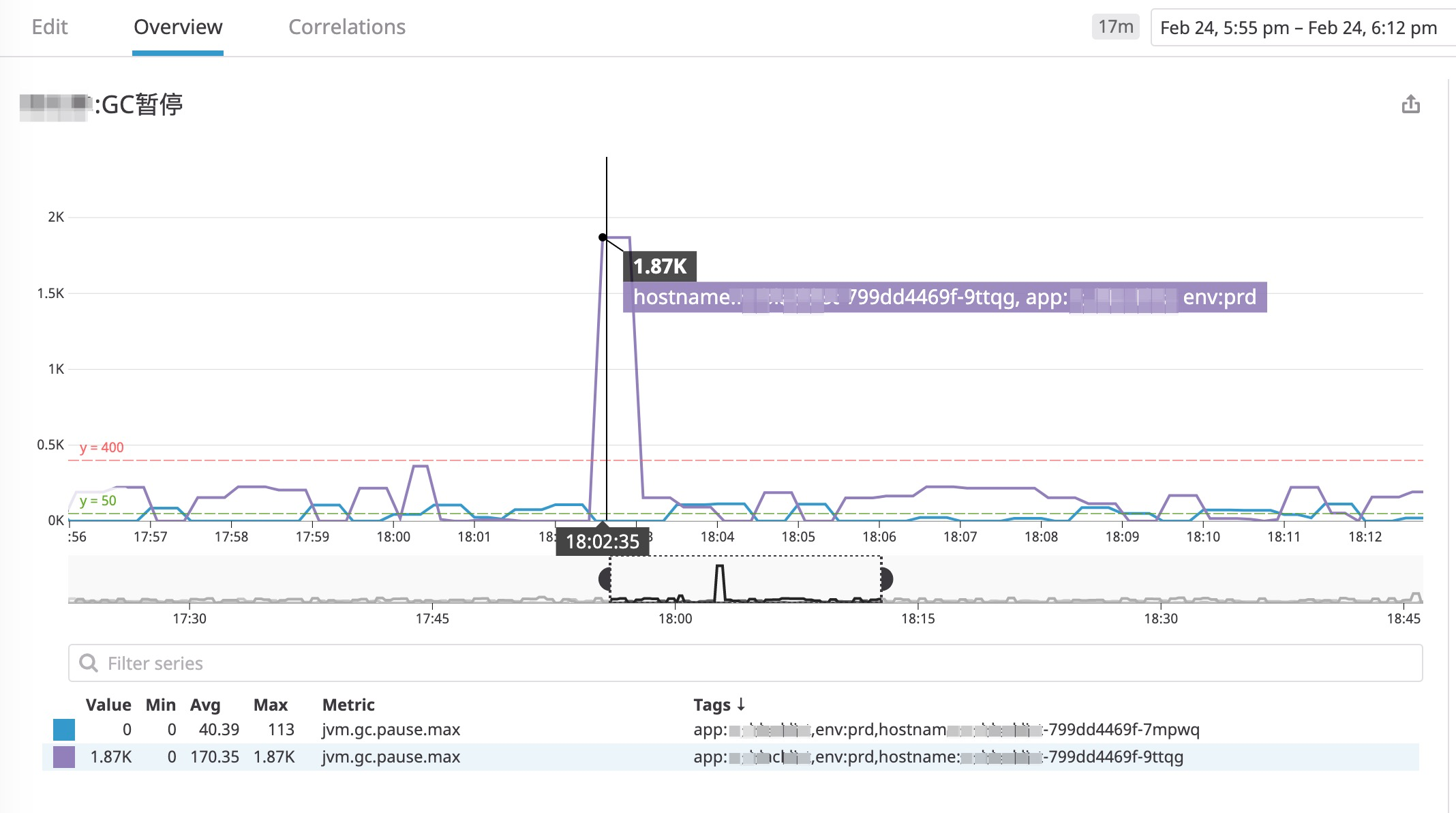
运行一段时间,又发现了超长的暂停时间。
3、分析GC日志
因为不涉及敏感数据,那么我们把GC日志下载到本地进行分析。定位到这次暂停时间超长的GC事件,关键的信息如下所示:
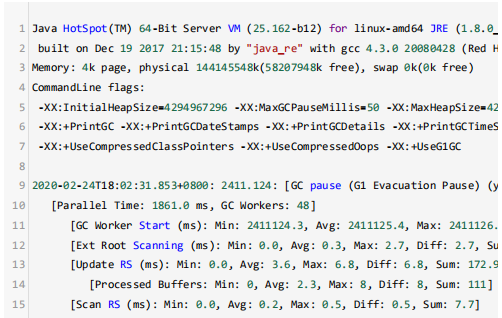
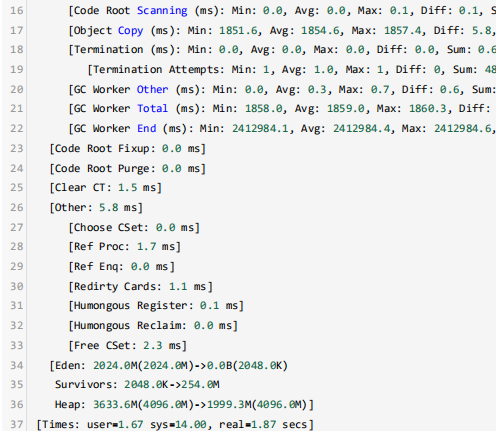
前后的GC事件都很正常,也没发现FullGC或者并发标记周期,但找到了几个可疑的点。
physical 144145548k(58207948k free) JVM启动时,物理内存 137GB, 空闲内存55GB.
[Parallel Time: 1861.0 ms, GC Workers: 48] 垃圾收集器工作线程 48个。
user=1.67 用户线程耗时 1.67秒;
sys=14.00 系统调用和系统等待时间 14秒;
real=1.87 secs 实际暂停时间 1.87 秒;
GC之前,年轻代使用量2GB,堆内存使用量3.6GB, 存活区2MB,可推断出老年代使用量 1.6GB;
GC之后,年轻代使用量为0,堆内存使用量2GB,存活区254MB, 那么老年代大约1.8GB,那么内存提升量为200MB左右 。
这样分析之后,可以得出结论:
年轻代转移暂停,复制了400MB左右的对象,却消耗了1.8秒,系统调用和系统等待的时间达到了14秒。
JVM看到的物理内存137GB。。。
推算出JVM看到的CPU内核数量 72个,因为 GC工作线程 72* 5/8 ~= 48个。
看到这么多的GC工作线程我就开始警惕了,毕竟堆内存才指定了4GB。
按照一般的CPU和内存资源配比,常见的比例差不多是 4核4GB , 4核8GB 这样的。看看对应的CPU负载监控信息:
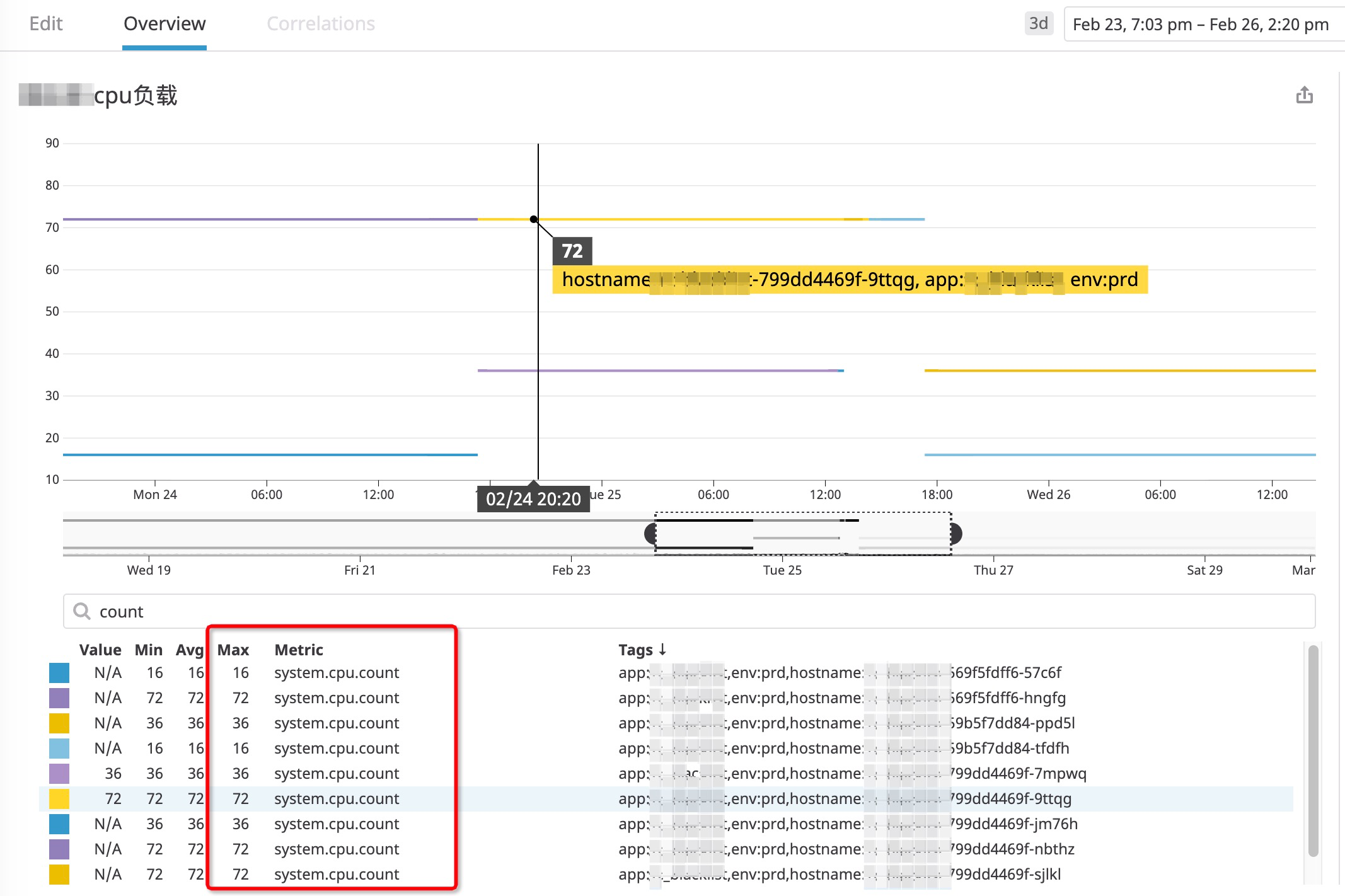
通过和运维同学的沟通,得到这个节点的配置被限制为 4核8GB 。这样一来,GC暂停时间过长的原因就定位到了:K8S的资源隔离和JVM未协调好,导致JVM看见了72个CPU内核,默认的并行GC线程设置为: 72* 5/8 + 3 = 48 个 ,但是K8S限制了这个Pod只能使用4个CPU内核的计算量,致使GC发生时,48个线程在4个CPU核心上发生资源竞争,导致大量的上下文切换。
处置措施为:限制GC的并行线程数量。事实证明,打印GC日志确实是一个很有用的排查分析方法。
(六)限制GC的并行线程数量
下面是新的启动参数配置:
‐Xmx4g ‐Xms4g ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50 ‐XX:ParallelGCThreads=4 ‐Xloggc:gc.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps
这里指定了 ‐XX:ParallelGCThreads=4 , 为什么这么配呢? 我们看看这个参数的说明。
‐XX:ParallelGCThreads=n 设置STW阶段的并行 worker 线程数量。如果逻辑处理器小于等于8个,则默认值 n 等于逻辑处理器的数量。如果逻辑处理器大于8个,则默认值 n 等于处理器数量的 5/8+3 。 在大多数情况下都是个比较合理的值。 如果是高配置的 SPARC 系统,则默认值 n 大约等于逻辑处理器数量的 5/16 。
‐XX:ConcGCThreads=n 设置并发标记的GC线程数量。 默认值大约是 ParallelGCThreads 的四分之一。一般来说不用指定并发标记的GC线程数量,只用指定并行的即可。
重新启动之后,看看GC暂停时间指标:
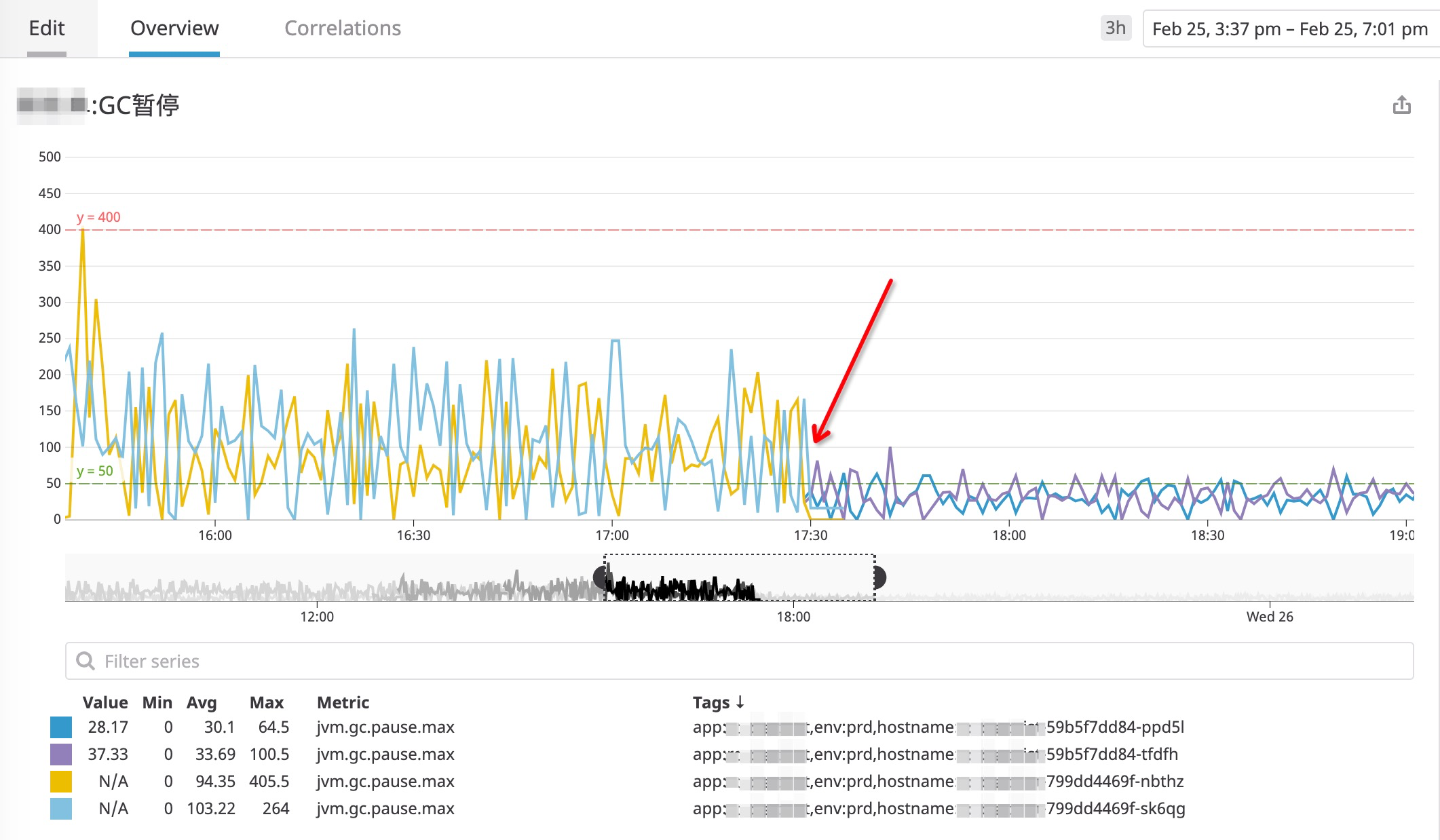
红色箭头所指示的点就是重启的时间点, 可以发现, 暂停时间基本上都处于50ms范围内。后续的监控发现,这个参数确实解决了问题。
后续经过一段时间的运行,因为数据量爆发,定时任务执行时,每次从数据库加载几百万条数据到内存进行处理。。。
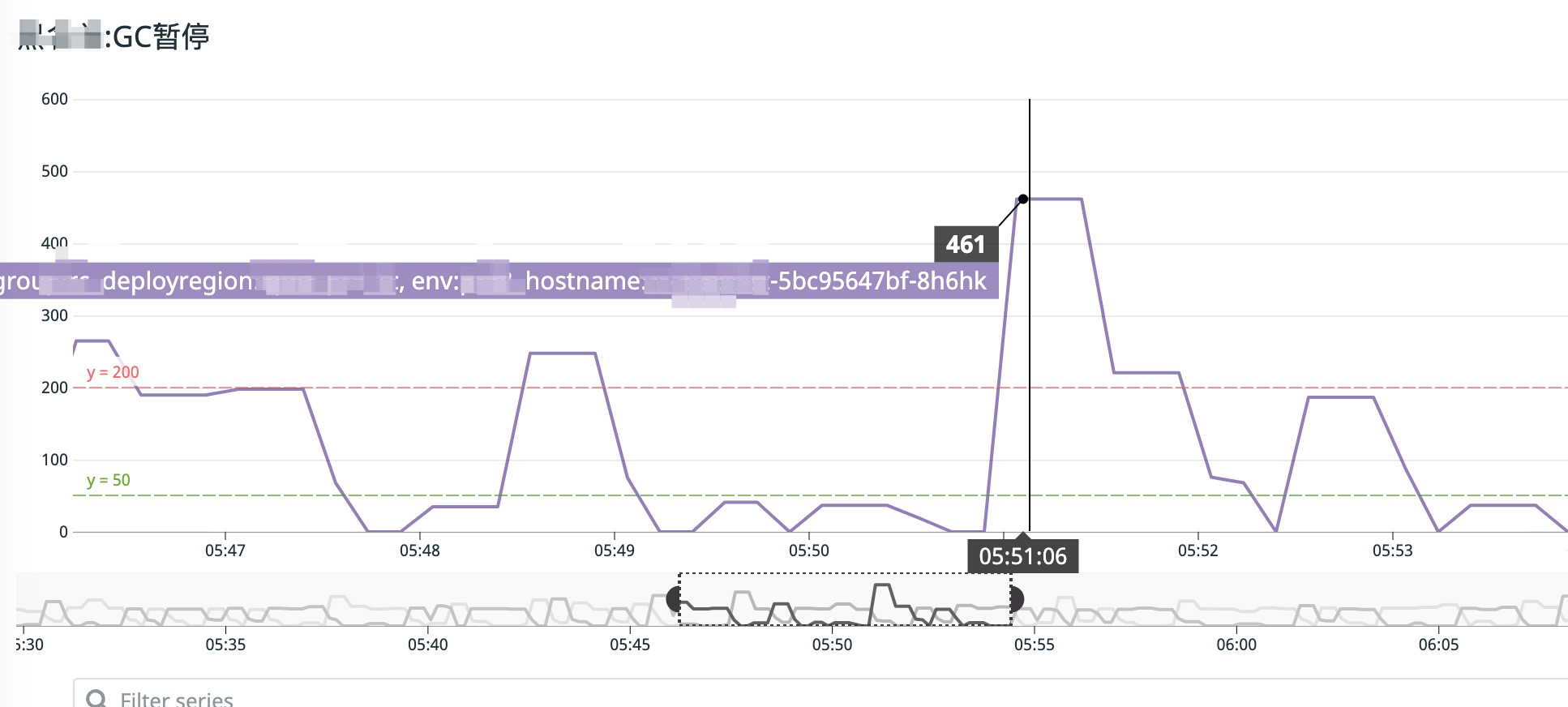
(七)总结
通过这个案例,我们可以看到,JVM问题排查和性能调优主要基于监控数据来进行。还是那句话: 没有量化,就没有改进 。
简单汇总一下这里使用到的手段:
指标监控
指定JVM启动内存
指定垃圾收集器
打印和分析GC日志
GC和内存是最常见的JVM调优场景, GC的性能维度:
延迟,GC中影响延迟的主要因素就是暂停时间。
吞吐量,主要看业务线程消耗的CPU资源百分比,GC占用的部分包括: GC暂停时间,以及高负载情况下并发GC消耗的CPU资源。
系统容量,主要说的是硬件配置,以及服务能力。
只要这些方面的指标都能够满足,各种资源占用也保持在合理范围内,就达成了我们的预期。
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号