
Zookeeper--理论及客户端
一、重要理论
(一)数据模型
zk 数据存储结构与标准的 Unix 文件系统非常相似,都是在根节点下挂很多子节点。zk 中没有引入传统文件系统中目录与文件的概念,而是使用了称为 znode 的数据节点概念。 znode 是 zk 中数据的最小单元,每个 znode 上都可以保存数据,同时还可以挂载子节点,形 成一个树形化命名空间
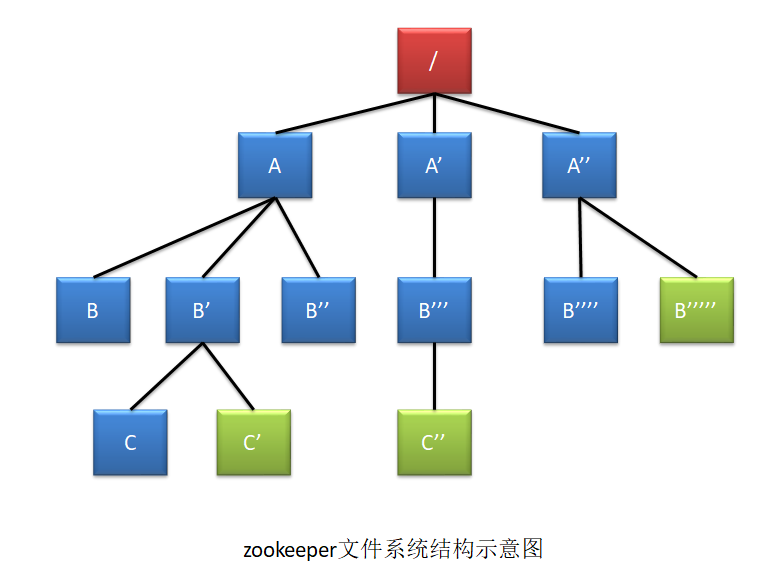
节点类型:
持久节点:节点创建后,会一直保存在zk中,直到被删除
持久顺序节点:一个父节点可以为它的第一级子节点维护一份顺序,以记录子节点的创建顺序。在创建子节点时,会在子节点的名称后面加上数字后缀作为节点的名字。序号由10个数字组成,初始值为0。
临时节点:临时节点的生命周期和会话绑定在一起,会话消失,该节点也随之消失。临时节点只能作为子节点不能作为父节点,也就是说临时节点上不能创建子节点。
临时顺序节点:添加了创建序号的临时节点
节点状态:
cZxid:Created Zxid,表示当前znode被创建的事务ID
ctime:Created time,表示当前znode被创建的时间
mZxid:Modified Zxid,表示当前znode最后一次被修改的事务id
mtime:Modified time,表示当前znode最后一次被修改的时间
pZxid:表示当前znode的子znode列表发生了变更的事务ID,注意,这里说的是子znode列表,子znode中内容发生变更,pZxid不会发生变更
cversion:Children version,表示子节点的版本号,该版本号用于充当乐观锁
dataversion:当前znode数据的版本号,该版本号用于充当乐观锁
aclversion:表示当前znode的的权限acl的版本号,该版本用于充当乐观锁
ephemeralOwner:若当前znode为持久节点,该值为0,若当前znode为临时节点,该值为创建该znode的会话sessionId,当会话消失后,会根据会话的sessionId来查找与会话相关的临时节点进行删除
datalength:当前znode中存储数据的长度
numchildern:当前znode所包含的子节点的数量
(二)会话
会话是zk中最重要的概念之一,客户端与服务端之间的任何交互操作都与会话相关。
zk客户端启动时,首先会与zk服务器建立一个TCP长连接,连接一旦建立,客户端会话的生命周期也就开始了。
1、会话的三种状态:
CONNECTING:连接中,Client要创建一个链接,首先要在本地创建一个zk对象,用于表示其所连接上的server
CONNECTED:已连接,连接成功后,连接成功后,该链接的各种临时数据都会被初始化到zk对象中
CLOSED:已关闭,连接关闭后,这个代表Server的zk对象会被删除
2、会话的源码解析
3、会话连接超时管理--客户端维护
zk客户端维护着会话超时管理,主要管理的有两大类:读超时和连接超时
读超时指的是:当客户端长时间没有收到服务端请求响应或者心跳。
连接超时:当客户端发出链接请求后,长时间没有收到服务端的ack响应
4、会话连接事件
客户端与服务端连接成功后,有可能出现连接丢失、会话转移、会话失败这些问题
连接失败:因为网络抖动等原因导致客户端长时间收不到服务端的心跳回复,就会导致客户端的连接失败。如果出现连接失败,zk客户端会从zk的地址列中中逐个尝试重新连接,直到连接成功,或是按照指定的重试策略终止。
会话转移:当发生连接失败,客户端又以原来的sessionID重新连接上后,但是新连接的服务器不是原来的服务器,那么客户端就需要更新本地zk对象中的相关信息,例如服务器的ip等,这就是会话转移
会话失败:若客户端连接丢失后,在会话超时范围内没有连接上服务器,则服务器会将该会话从服务器中删除。在服务端删除会话后,客户端仍然使用之前的sessionID进行连接,那么服务器会给客户端发送一个连接关闭响应,表示这个会话已经结束。客户端在收到响应后,要么关闭连接,要么重新发起新的会话ID的连接。
5、会话空闲超时管理--服务端维护
zk服务器为每一个连接都维护了上一次交互后空闲的时间和超时时间,一旦空闲时间超时,服务端就会将会话的sessionID从服务器端清楚,这也就是为什么客户端要向服务端发送心跳的原因。
服务端采用了分桶策略对会话空闲超时进行管理
分桶策略:将空闲超时时间相近的会话放到同一个桶中来进行管理,以减少管理的复杂度,在检查超时时,只需要检查桶中剩余的会话即可,因为没有超时的会话已经被移除了桶,而桶中存在的会话就是超时的会话。zk对于会话空闲超时的管理并非是精确的,即并非一超时马上就执行相关的超时操作。
分桶的依据:公式如下所示,一个桶的大小为ExpirationTime时间,只要ExpirationTime落入到同一个桶中,系统就会对其中的会话超时进行统一管理。
ExpirationTime= CurrentTime + SessionTimeout BucketTime = (ExpirationTime/ExpirationInterval + 1) * ExpirationInterval
(三)ACL
ACL全称为Access Control List(访问控制列表),是一种细粒度的权限管理策略,可以针对任意的用户和组进行权限管理。
zk利用ACL控制znode节点的访问权限,如节点的创建、删除、修改、读取,以及子节点列表的读取、设置节点权限等。
UGO(user、group、other)是一种粗粒度的权限管理策略。
Linux的ACL分为两个维度:组和权限,且目录的子目录或文件可以继承父目录的ACL。而zk的ACL可以分为三个维度:授权策略scheme、授权对象id、用户权限permission,并且子znode不会集成父节点的权限。
1、授权Scheme
授权策略用于确定权限验证过程中使用的检验策略(简单来说就是通过什么来进行权限校验),在zk中最常用的策略有四种:
(1)IP:根据IP地址进行权限校验
(2)digest:根据用户名密码进行权限校验
(3)world:对所有用户不做任何校验
(4)super:超级用户可以对任意节点做任意操作,这种模式打开客户端的方式都与上面三种情况不同,其需要在打开客户端时添加一个系统属性。
2、授权对象ID
授权对象指的是权限赋予的用户,不同的策略授权具有不同的授权对象,授权策略与授权对象的对应关系如下所示:
(1)IP:授权对象是IP地址
(2)digest:授权对象是用户名+密码
(3)world:授权对象只有一个,anyone
(4)super:与sigest一样,其授权对象也是用户名+密码
3、权限Permission
权限是严重用户对znode是否有对应的操作权限,zk自带的有5中权限(zk支持自定义权限):
(1)c:Create,允许授权对象在当前znode下新增子节点
(2)d:Delete,允许授权对象在当前znode下删除子节点
(3)r:Read,允许授权对象读取当前znode节点的内容,及子节点列表
(4)w:Write,允许授权对象修改当前节点的内容,及子节点列表
(5)Acl:允许授权对象对当前节点进行ACL权限设置
(四)Wtcher机制
zk通过Watcher机制实现了发布订阅模式。
1、Watcher事件原理
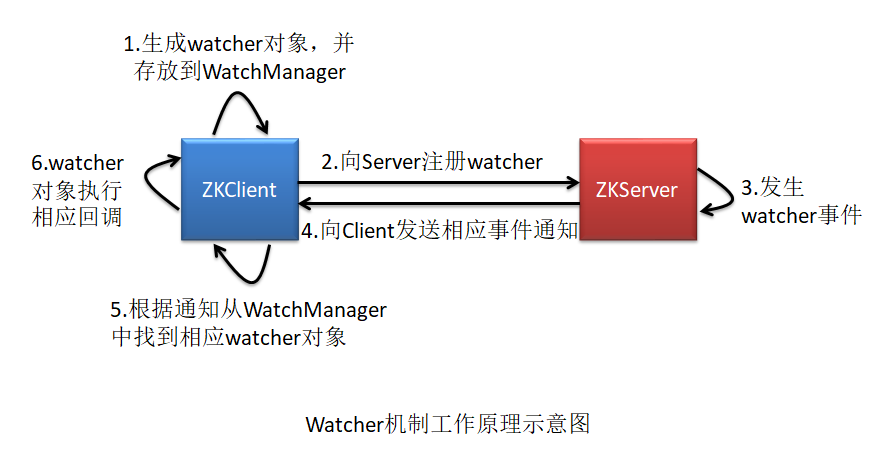
2、Watcher事件
在同一个事件类型中,不同的通知状态代表不同的含义
| 客户端所处状态 | 事件类型(常量值) | 触发条件 | 说明 |
| SyncConnected | None(-1) | 客户端与服务器成功建立连接 | 此时客户端和服务端处于连接状态 |
| NodeCreated(1) | Watcher监听的对应数据节点被创建 | ||
| NodeDeleted(2) | Watcher监听的对应数据节点被删除 | ||
| NodeDataChanged(3) | Watcher监听的对应节点数据被改变 | ||
| NodeChildrenListChanged(4) | Watcher监听的对应节点子节点列表发生变更 | ||
| DisConnected(0) | None(-1) | 客户端与服务端断开连接 | 此时客户端与服务端处于断开连接状态 |
| Expired(-112) | None(-1) | 会话失效 | 此时客户端会话失效,通常会收到SessionExpireException |
| AuthFailed | None(-1) | 使用错误的scheme进行权限检查 | 通常会收到AuthFailedException |
3、watcher属性
zk的watcher机制具有非常重要的特性:
一次性:一旦一个watcher被触发,zk就会将其从客户端的WatcherManager中剔除,服务端中也会删除该watcher,zk的watcher机制不适合监听变化非常频繁的场景。
轻量级:真正传递给Server的是一个非常简易版的watcher,回调逻辑放在客户端,没有在服务端
二、客户端命令
1、服务端操作
# 启动zk服务 ./bin/zkServer.sh # 查看zk服务状态 ./bin/zkServer.sh status
2、客户端连接zk
# 连接本机 ./bin/zkCli.sh # 连接远程zk服务 ./bin/zkCli.sh -server 192.168.124.11:2181
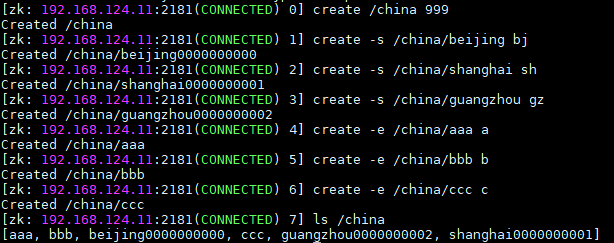
3、查看子节点列表:ls + 目录

4、创建节点,-create
# 创建永久节点,并赋值 create /china 999 # 创建顺序节点 create -s /china/beijing bj create -s /china/shanghai sh create -s /china/guangzhou gz # 创建临时节点 create -e /china/aaa a create -e /china/bbb b create -e /china/ccc c
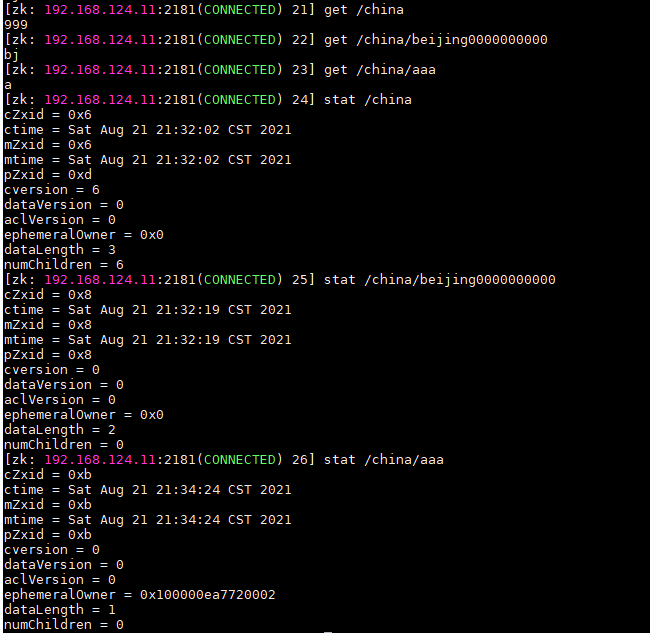
5、获取节点信息
# 获取节点数据 get /china # 获取节点操作信息(事务ID等) stat /china
6、更新节点
set /china 6789
7、删除节点
delete /china/guangzhou0000000002

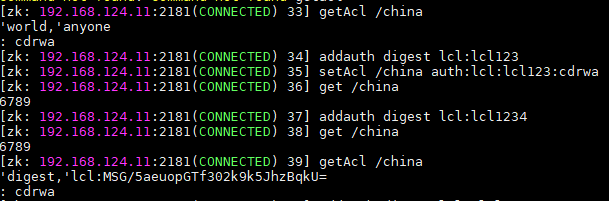
8、acl操作
# 获取权限信息 getAcl /china # 添加策略 addauth digest lcl:lcl123 # 添加授权对象和权限 setAcl /china auth:lcl:lcl123:cdrwa
三、ZKClient
ZkClient 是一个开源客户端,在 Zookeeper 原生 API 接口的基础上进行了包装,更便于 开发人员使用。内部实现了 Session 超时重连,Watcher 反复注册等功能。像 dubbo 等框架 对其也进行了集成使用。
(一)客户端介绍
客户端中的方法均是zkclient类中提供的方法。
1、创建会话(构造函数)
直接调用zkclient的构造方法即可

全量参数解释如下:
zkServers:定zk服务器列表,由英文状态逗号分开的host:port字符串组成
sessionTimeout:设置会话超时时间,单位毫秒
connectionTimeout:设置连接创建超时时间,单位毫秒。在此时间内无法创建与 zk 的连接,则直接放弃连接,并抛出异常
zkSerializer:为会话指定序列化器。zk 节点内容仅支持字节数组(byte[])类型, 且 zk 不负责序列化。在创建 zkClient 时需要指定所要使用的序列 化器,例如 Hessian 或 Kryo。默认使用 Java 自带的序列化方式进 行对象的序列化。当为会话指定了序列化器后,客户端在进行读 写操作时就会自动进行序列化与反序列化。
connection:IZkConnection 接口对象,是对 zk 原生 API 的最直接包装,是和 zk 最直接的交互层,包含了增删改查等一系列方法。该接口最常用 的实现类是 zkClient 默认的实现类 ZkConnection,其可以完成绝大部分的业务需求。
operationRetryTimeout:设置重试超时时间,单位为毫秒
2、 创建节点(create开头的方法)
全量参数解释如下:
path:要创建的节点完整路径
data:节点的初始数据内容,可以传入 Object 类型及 null。zk 原生 API 中只允许向节点传入 byte[]数据作为数据内容,但 zkClient 中具有自定义序列化器,所以可以传入各种类型对象。
mode:节点类型,CreateMode 枚举常量,常用的有四种类型。PERSISTENT:持久型;PERSISTENT_SEQUENTIAL:持久顺序型;EPHEMERAL:临时型;EPHEMERAL_SEQUENTIAL:临时顺序型
acl:节点的 ACL 策略
callback:回调接口
context:执行回调时可以使用的上下文对象
createParents 是否级递归创建节点。zk 原生 API 中要创建的节点路径必须存在, 即要创建子节点,父节点必须存在。但 zkClient 解决了这个问题, 可以做递归节点创建。没有父节点,可以先自动创建了父节点, 然后再在其下创建子节点。
3、删除节点(delete方法)

全量参数解释如下:
path:要删除节点的完整路径
version:要删除节点中包含的数据版本
4、更新数据(write方法)

全量参数解释如下:
path:要更新节点的完整路径
data:更新的值
expectedVersion:数据更新后要采用的数据版本号
5、检查节点是否存在(exists方法)

全量参数解释如下:
path:节点路径
watch:要判断查看的节点及其子节点是否有watcher监听
6、获取节点内容(readData)

全量参数解释如下:
path:节点路径
watch:要判断查看的节点及其子节点是否有watcher监听
returnNullIfPathNotExists:这是个 boolean 值。默认情况下若指定的节点不存在,则会抛出 KeeperException$NoNodeException 异常。设置该值 为 true,若指定节点不存在,则直接返回 null 而不再抛出异常。
stat:当前节点的状态,但是执行后会被最新获取到的stat值给替换掉。
7、获取子节点列表(getChildren)

全量参数解释如下:
path:节点路径
watch:要判断查看的节点及其子节点是否有watcher监听
8、watcher注册(subscribe系列)
ZkClient 采用 Listener 来实现 Watcher 监听。客户端可以通过注册相关监听器来实现对 zk 服务端事件的订阅。
可以通过 subscribeXxx()方法实现 watcher 注册,即相关事件订阅;通过 unsubscribeXxx() 方法取消相关事件的订阅。
 .
.
全量参数解释如下:
path:节点路径
IZkChildListener:子节点数量变化监听器
IZkDataListener:数据内容变化监听器
IZkStateListener:客户端与 zk 的会话连接状态变化监听器,可以监听新会话的创建、 会话创建出错、连接状态改变。连接状态是系统定义好的枚举类 型 Event.KeeperState 的常量。
(二)代码演示
1、引入依赖
<!--zkClient 依赖-->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
2、场景演示
// 指定 zk 集群 private static final String CLUSTER = "192.168.124.11:2181"; // 指定节点名称 private static final String PATH = "/mylog"; @Test void contextLoads() { // 创建 zkClient ZkClient zkClient = new ZkClient(CLUSTER); // 为 zkClient 指定序列化器 zkClient.setZkSerializer(new SerializableSerializer()); // ---------------- 创建节点 ----------- // 指定创建持久节点 CreateMode mode = CreateMode.PERSISTENT; // 指定节点数据内容 String data = "first log"; // 创建节点 String nodeName = zkClient.create(PATH, data, mode); System.out.println("新创建的节点名称为:" + nodeName); // ---------------- 获取数据内容 ----------- Object readData = zkClient.readData(PATH); System.out.println("节点的数据内容为:" + readData); // ---------------- 注册 watcher ----------- zkClient.subscribeDataChanges(PATH, new IZkDataListener() { @Override public void handleDataChange(String dataPath, Object data) throws Exception { System.out.print("节点" + dataPath); System.out.println("的数据已经更新为了" + data); } @Override public void handleDataDeleted(String dataPath) throws Exception { System.out.println(dataPath + "的数据内容被删除"); } }); // ---------------- 更新数据内容 ----------- zkClient.writeData(PATH, "second log"); String updatedData = zkClient.readData(PATH); System.out.println("更新过的数据内容为:" + updatedData); // ---------------- 删除节点 ----------- zkClient.delete(PATH); // ---------------- 判断节点存在性 ----------- boolean isExists = zkClient.exists(PATH); System.out.println(PATH + "节点仍存在吗?" + isExists); }
四、Curator客户端
Curator 是 Netflix 公司开源的一套 zk 客户端框架,与 ZkClient 一样,其也封装了 zk 原生 API。其目前已经成为 Apache 的顶级项目。同时,Curator 还提供了一套易用性、可读性更 强的 Fluent 风格的客户端 API 框架。
(一)客户端介绍
1、创建会话
(1)普通api创建

参入解释如下:
connectString:指定zk服务器列表,由英文状态逗号分开的host:port字符串组成
sessionTimeoutMs:设置会话超时时间,单位毫秒,默认 60 秒
connectionTimeoutMs:设置连接超时时间,单位毫秒,默认 15 秒
connectionTimeoutMs retryPolicy:重试策略,内置有四种策略,分别由以下四个类的实例指定: ExponentialBackoffRetry、RetryNTimes、RetryOneTime、 RetryUntilElapsed
(2)fluent风格创建
CuratorFramework client = CuratorFrameworkFactory .builder() .connectString("192.168.124.11:2181") .sessionTimeoutMs(15000) .connectionTimeoutMs(13000) .retryPolicy(retryPolicy) .namespace("logs") .build();
2、创建节点
创建一个节点,初始内容为空:client.create().forPath(path);说明:默认创建的是持久节点,数据内容为空。
创建一个节点,附带初始内容:client.create().forPath(path, “mydata”.getBytes());说明:Curator 在指定数据内容时,只能使用 byte[]作为方法参数。
创建一个临时节点,初始内容为空:client.create().withMode(CreateMode.EPHEMERAL).forPath(path);说明:CreateMode 为枚举类型。
创建一个临时节点,并自动递归创建父节点:client.create().createingParentsIfNeeded().withMode(CreateMode.EPHEMERAL) .forPath(path);说明:若指定的节点多级父节点均不存在,则会自动创建。
3、删除节点
删除一个节点:语句:client.delete().forPath(path);说明:只能将叶子节点删除,其父节点不会被删除。
删除一个节点,并递归删除其所有子节点:client.delete().deletingChildrenIfNeeded().forPath(path); 说明:该方法在使用时需谨慎。
4、 更新数据 setData()
设置一个节点的数据内容:client.setData().forPath(path, newData);说明:该方法具有返回值,返回值为 Stat 状态对象。
5、检测节点是否存在 checkExits()
设置一个节点的数据内容:Stat stat = client.checkExists().forPath(path);说明:该方法具有返回值,返回值为 Stat 状态对象。若 stat 为 null,说明该节点不存在,否则说明节点是存在的。
6、获取节点数据内容 getData()
读取一个节点的数据内容:byte[] data = client.getDate().forPath(path); 说明:其返回值为 byte[]数组。
7、获取子节点列表 getChildren()
读取一个节点的所有子节点列表:List<String> childrenNames = client.getChildren().forPath(path); 说明:其返回值为 byte[]数组。
8、watcher 注册 usingWatcher()
curator 中绑定 watcher 的操作有三个:checkExists()、getData()、getChildren()。这三个方法的共性是,它们都是用于获取的。这三个操作用于 watcher 注册的方法是相同的,都是 usingWatcher()方法。
这两个方法中的参数 CuratorWatcher 与 Watcher 都为接口。这两个接口中均包含一个 process()方法,它们的区别是,CuratorWatcher 中的 process()方法能够抛出异常,这样的话, 该异常就可以被记录到日志中。
//监听节点的存在性变化 Stat stat = client.checkExists().usingWatcher((CuratorWatcher) event -> { System.out.println("节点存在性发生变化"); }).forPath(path); //监听节点的内容变化 byte[] data = client.getData().usingWatcher((CuratorWatcher) event -> { System.out.println("节点数据内容发生变化"); }).forPath(path); //监听节点子节点列表变化 List<String> sons = client.getChildren().usingWatcher((CuratorWatcher) event -> { System.out.println("节点的子节点列表发生变化"); }).forPath(path);
(二)代码示例
1、引入依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
2、代码演示
public void curatorTest() throws Exception{ String nodePath = "/lclcurator"; // ---------------- 创建会话 ----------- // 创建重试策略对象:第 1 秒重试 1 次,最多重试 3 次 ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3); // 创建客户端 CuratorFramework client = CuratorFrameworkFactory .builder() .connectString("192.168.124.11:2181") .sessionTimeoutMs(15000) .connectionTimeoutMs(13000) .retryPolicy(retryPolicy) .namespace("logs") .build(); // 开启客户端 client.start(); // 指定要创建和操作的节点,注意,其是相对于/logs 节点的 String nodePath = "/host"; // ---------------- 创建节点 ----------- String nodeName = client.create().forPath(nodePath, "myhost".getBytes()); System.out.println("新创建的节点名称为:" + nodeName); // ---------------- 获取数据内容并注册 watcher ----------- byte[] data = client.getData().usingWatcher((CuratorWatcher) event -> { System.out.println(event.getPath() + "数据内容发生变化"); }).forPath(nodePath); System.out.println("节点的数据内容为:" + new String(data)); // ---------------- 更新数据内容 ----------- client.setData().forPath(nodePath, "newhost".getBytes()); // 获取更新过的数据内容 byte[] newData = client.getData().forPath(nodePath); System.out.println("更新过的数据内容为:" + new String(newData)); // ---------------- 删除节点 ----------- client.delete().forPath(nodePath); // ---------------- 判断节点存在性 ----------- Stat stat = client.checkExists().forPath(nodePath); boolean isExists = true; if(stat == null) { isExists = false; } System.out.println(nodePath + "节点仍存在吗?" + isExists); }
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号