
JVM与JIT
一、JVM介绍
(一)JVM简述
Java代码编译生成class文件,然后在JVM上运行;但是并不是只有Java一种语言可以编译成为class文件。

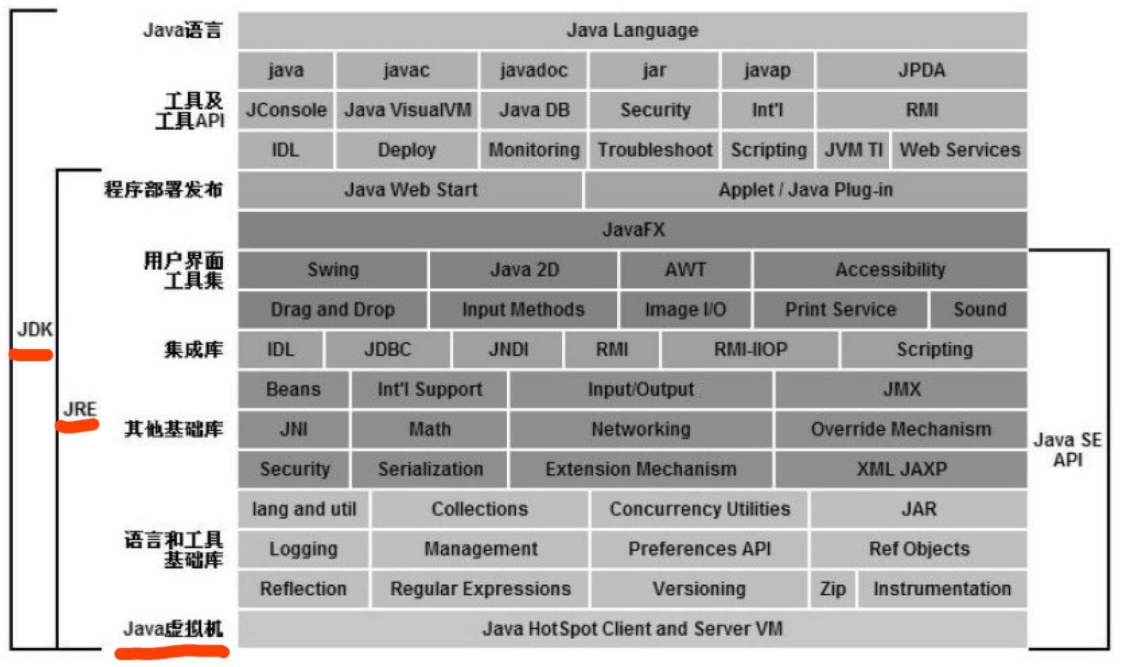
1、JVM、JRE、JDK:
JVM:Java虚拟机,提供了class文件的运行支持
JRE:Java运行环境,提供了java应用程序运行所必须的软件环境,含有JVM和丰富的类库
JDK:Java开发工具包,包含编写Java程序锁必须的编译、运行等开发工具和JRE(用于编译程序的javac命令、用于启动JVM运行Java程序的Java命令、用于生成文档的Javadoc命令、用于打包的jar命令等)
三者的关系是JDK包含JRE,JRE包含JVM
2、JVM JIT运行方式
JVM有两种运行方式,Server模式和Client模式,可以通过-server或-client设置JVM的运行参数
Server模式和Client模式的区别:
(1)Server VM模式的初始堆空间会大一点,默认使用的是并行垃圾回收器,启动慢、运行快
(2)Client VM相对会保守一些,其初始堆空间会小一点,其使用串行的垃圾回收器,目的就是为了让JVM快速启动,但是运行速度会比Server模式慢
如果在不指定参数的情况下,JVM在启动时会根据硬件及操作系统自动选择模式。
如果是32位操作系统:
Windows系统:使用Client模式启动
其他操作系统:机器配置超过2核+2G时,默认使用Server模式,斗则使用Client模式
如果是64位操作系统:只有Server模式,没有Client模式。
以下是使用64位Windows操作系统演示
D:\>java -client -showversion testApplication java version "1.8.0_281" Java(TM) SE Runtime Environment (build 1.8.0_281-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode) D:\>java -server -showversion testApplication java version "1.8.0_281" Java(TM) SE Runtime Environment (build 1.8.0_281-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode)
(二)JVM架构
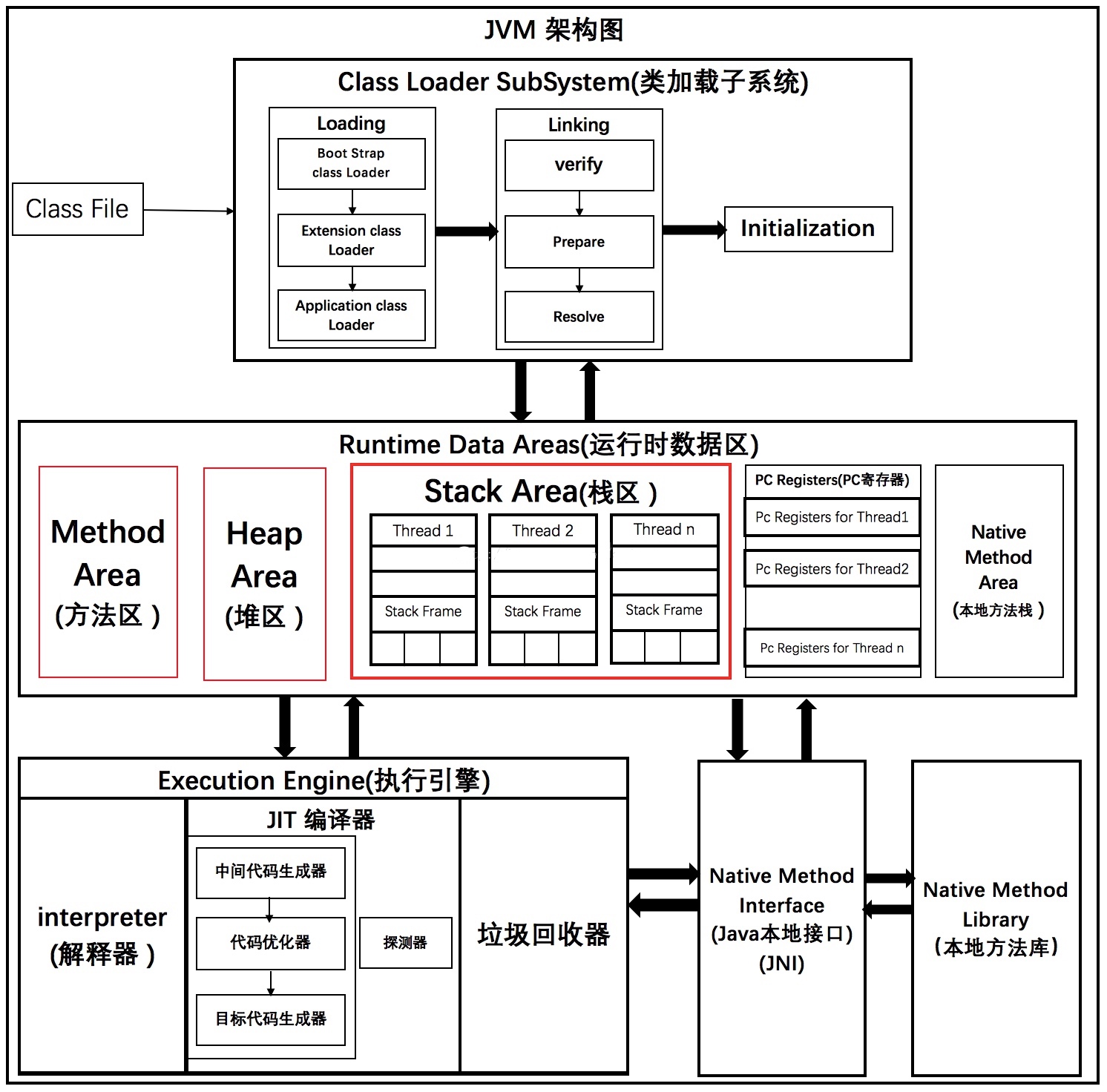
JVM由类加载器、运行时数据区、执行引擎、本地接口、本地库组成。
类加载器:在JVM启动时或者类运行时将需要的class文件加载到JVM中
运行时数据区(内存区):存储运行时的各种数据;将内存划分为若干个区以模拟实际机器上的存储、记录、调度等功能,如实际机器上的各种功能寄存器或者PC指针的记录器等。
执行引擎:负责执行class文件中包含的字节码指令,类似于CPU
本地接口 & 本地库:调用使用C或C++实现的接口
(三)JVM执行流程
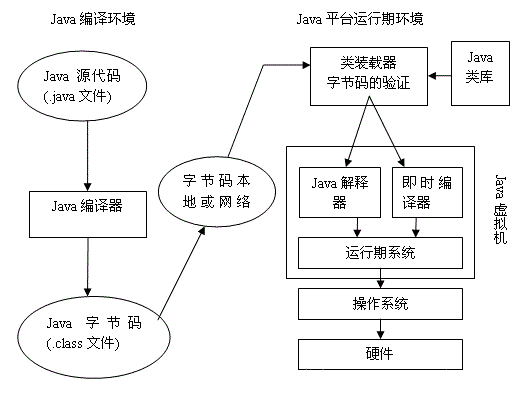
1、Java编译器将java文件编译成虚拟机可运行的class字节码文件
2、类加载器的字节码验证,验证通过后将其加载到JVM虚拟机中
3、JVM虚拟机运行class文件,并行逻辑处理并与操作系统交互
这里同时存在解释器和即时编译器,这里解释一下编译执行、解释执行、即时编译执行
解释执行:将class文件一行一行翻译成机器码进行,并交由操作系统执行。优点是可以跨平台(这正是Java的优点),缺点是解析需要时间,执行效率低。
编译执行:将class文件全部编译成机器码文件,然后交由操作系统执行,此时操作系统可以直接执行。但是机器码文件不保存。优点是执行速度快、效率超高、占用内存小,缺点是不能跨平台。
即时编译执行:将class文件编译成机器码文件,并存入内存,以便后续使用。
(四)热点代码
上面JVM虚拟机运行时,同时存在使用解释器进行解释执行和使用即时编译器边编译边执行;其是通过判断代码是否是热点代码来进行不同的处理的,如果是热点代码,则使用即时编译器边编译边执行,如果非热点代码,则使用解释器进行处理
程序中的代码只有是热点代码时,才会被编译为本地代码。热点代码有两类:被多次调用的代码和被多次执行的循环体。
目前主要的热点探测方式主要有两种:
1、基于采样的热点探测
采用这种探测方式的虚拟机会周期性的检查各个线程的栈顶,如果发现某些方法经常出现在栈顶,那这个方法就是热点方法。这种探测方法的好处是简单有效,可以很方便的获取方法的调用关系(将调用堆栈展开即可);缺点是不够精确,很容易受到线程阻塞或者其他外界因素的影响
2、基于计数器的
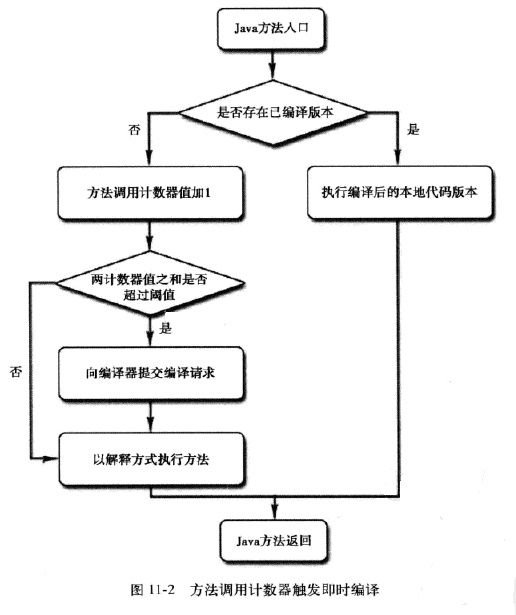
采用这种探测方式的虚拟机会为每个方法甚至代码块建立一个计数器,方法每次被调用,计数器就会加一,如果调用次数达到了阈值,就认为该方法为热点方法。这种探测方法的优点是足够准确;缺点是实现比较复杂,且拿不到方法的调用关系。
在Hotspot虚拟机中采用的是基于计数器的热点探测。其为方法提供了两个计数器,方法调用计数器可回边计数器,方法调用计数器是用来统计方法调用次数,回边计数器是用来统计循环体被循环的次数。当计数器的技术结果达到阈值,则会出发JIT即时编译。
在Client模式下,热点代码计数阈值默认为1500次,Server模式下为10000次。但是也可以通过参数来进行设置:-XX:CompileThreshold=3000,但是JVM中存在热度衰减,时间段内调用方法的次数减小,计数器就减小。
二、JIT使用及优化
(一)JIT编译器简述
在现在流行的JVM产品中,比如HotSpot,都是既有解释器又有编译器,其特点在上面已经说过,解释器的优点是启动快,内存占用少,缺点是长时间运行慢;编译器的优点是长时间运行时,运行速度快,缺点是启动慢,占用内存比解释器大。因此解释器和编译器的作用场景:
(1)在混合模式下,当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,编译器开始逐渐发挥作用,把越来越多的代码编译后放到本地,从而获取更高的执行效率。
(2)当程序运行环境中内存资源限制比较大时(比如嵌入式开发),可以使用解释器执行,从而节省内存空间。如果内存资源比较充足的情况,可以使用编译器来提升程序运行效率(以空间换时间)。
在HotSpot虚拟机中,有C1(Client Complier)、C2(Server Complier)两个即时编译器,分别用在客户端模式和服务端模式下。至于采用的是哪一种,就看JVM是以哪种模式启动的。
两者的区别是:用C1编译器可以获取更高的编译速度,用C2编译器可以获得更好的编译质量,因为C1编译器主要关注点在局部优化,而放弃耗时较长的全局优化手段;而C2编译器是专门针对服务端的编译器,并为服务端的性能配置特别调整过,是一个充分优化过的高级编译器。
(二)JIT编译器优化
JIT即时编译器会通过公共子表达式消除,方法内敛、方法逃逸分析来优化编译后的代码。
1、公共子表达式消除
如果一个表达式前面已经计算过,后面也有相同的表达式,那么该表达式就是公共子表达式。公共子表达式分为局部公共子表达式(仅限于程序的基本块内)和全局公共子表达式(优化范围涵盖了多个基本块)。
举个栗子:int d = (c*b)*12+a+(a+b*c) 编译成解机器码指令如下:
iload_2 // b imul // 计算b*c bipush 12 // 推入12 imul // 计算(c*b)*12 iload_1 // a iadd // 计算(c*b)*12+a iload_1 // a iload_2 // b iload_3 // c imul // 计算b*c iadd // 计算a+b*c iadd // 计算(c*b)*12+a+(a+b*c) istore 4
由于代码中c*b 和 b*c 是一样的结果,就可以将 b*c 看作公共子表达式,就会优化成 int d = E*12+a+(a+E)
同时JIT还可以继续使用“代数简化”进行优化,再将其优化为:int d = E*13+2a
表达式改变后,机器码就会少很多,就达到了节省时间的目的。
2、方法内敛
在使用JIT即时编译时,将方法调用替换为直接使用方法中的内容,这就是方法内敛,他减少了方法调用过程中压栈和入栈的开销,同时可以为之后的一些优化手段提供条件。
举个栗子:下面的代码可以在使用方法内敛优化前后的对比
private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4); } private int add2(int x1, int x2) { return x1 + x2; }
private int add4(int x1, int x2, int x3, int x4) { return x1 + x2 + x3 + x4; }
3、方法逃逸分析
逃逸分析是动态分析对象作用域的分析算法。当一个对象在方法中被定义后,它可以被外部方法所引用,例如作为调用参数传入到其他方法中,就叫做方法逃逸。也就是说方法外是否可以用到这个对象。
逃逸分析包括:全局变量赋值逃逸、方法返回值逃逸、实例引用发生逃逸、线程逃逸(赋值给类变量或可以在其他线程中访问的实例变量)
各种逃逸样例代码如下所示:
@Slf4j public class MethodEscape { //全局变量 public static Object object; //全局变量赋值逃逸 public void globalVariableEscape(){ object = new Object(); } //方法返回值逃逸 public Object getObject(){ return new Object(); } //实例引用发生逃逸 public void instancePassEscape(){ this.speak(this); } private void speak(MethodEscape methodEscape) { log.info("======"); } }
那么如何可以避免方法逃逸呢,例如下面的代码
public StringBuffer geneStringBuffer(String s1, String s2){ StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb; }
其实可以直接返回String,而不是返回在方法中创建的StringBuffer对象,就可以避免方法逃逸。
public String geneString(String s1, String s2){ StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb.toString(); }
开启方法逃逸分析:
上面说了逃逸分析的方法,那么作用呢?其作用就是可以根据分析出来是否存在方法逃逸的结果,来做同步省略、将堆分配转化为栈分配、分离对象或标量替换。
(1)同步省略 & 同步锁消除:
如果一个对象只能被一个线程访问到,那么对该对象的操作可以不考虑同步。
public class EscapeAnalysisTest { public static void main(String[] args) { long a = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { getString("TestLockEliminate ", "Suffix"); } System.out.println("============" + (System.currentTimeMillis() - a)); try { System.out.println("============" + (System.currentTimeMillis() - a)); } catch (Exception e) { System.out.println(e); } } public static String getString(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb.toString(); } }
如果在运行的时候使用逃逸分析,同时使用了同步锁消除,执行时长为60毫秒。
C:\Users\licl81>java -XX:+DoEscapeAnalysis -XX:+EliminateLocks EscapeAnalysisTest ============60 ============61
但是不使用同步锁消除,执行时长为87毫秒
C:\Users\licl81>java -XX:+DoEscapeAnalysis -XX:-EliminateLocks EscapeAnalysisTest ============87 ============87
这里有个常识,sb.append(s1)是会加锁的
@Override public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }
(2)将堆分配转化为栈分配
如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,那么首选则是栈分配,而不是堆分配。
例如下面的代码:
public class EscapeAnalysisTest { public static void main(String[] args) { long a = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { alloc(); } System.out.println("============" + (System.currentTimeMillis() - a)); try { Thread.sleep(20000); System.out.println("============" + (System.currentTimeMillis() - a)); } catch (Exception e) { System.out.println(e); } } private static void alloc() { UserDemo user = new UserDemo(); } static class UserDemo { } }
在不开启逃逸分析运行代码时
java -Xmx2G -Xms2G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError EscapeAnalysisTest
使用jmap查看堆中对象分配情况
C:\Users\licl81>jps 22704 Jps 28376 45032 Launcher 284 EscapeAnalysisTest C:\Users\licl81>jmap -histo 284 num #instances #bytes class name ---------------------------------------------- 1: 1000000 16000000 EscapeAnalysisTest$UserDemo 2: 428 15357144 [I 3: 3311 588224 [C 4: 2322 55728 java.lang.String 5: 481 55144 java.lang.Class 6: 107 40800 [B 7: 792 31680 java.util.TreeMap$Entry 8: 533 31384 [Ljava.lang.Object; 9: 213 9384 [Ljava.lang.String;
可以看到堆中分配了100万个 EscapeAnalysisTest$UserDemo对象。
如果开启逃逸分析:
java -Xmx2G -Xms2G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError EscapeAnalysisTest
然后再用jmap查看
C:\Users\licl81>jps 34544 EscapeAnalysisTest 29860 Jps 28376 45032 Launcher C:\Users\licl81>jmap -histo 34544 num #instances #bytes class name ---------------------------------------------- 1: 427 18675832 [I 2: 120837 1933392 EscapeAnalysisTest$UserDemo 3: 3311 588224 [C 4: 2322 55728 java.lang.String 5: 481 55144 java.lang.Class
可以发下只有12万的数据被分配在堆上。
可以看到上述的对比,在未开启方法逃逸分析时,虽然UserDemo对象虽然没有方法逃逸,但是仍然在堆上分配了一百万个UserDemo对象。开启方法逃逸分析后,则只在堆上创建了12万个UserDemo对象。
那么,所有的对象和数组都会被分配到堆上,这句话是不完全正确的,要看是否开启了方法逃逸分析。
(3)分离对象或标量替换
有的对象可能不需要连续的内存结构存在也可以被访问到,那么对象的部分内容可以不存储在内存中,而可以存储在CPU寄存器上。
在JIT阶段,如果经过逃逸分析,发现一个对象不会被外界访问,那么经过JIT优化,就会把这个对象拆解成若干个其中包含若干个成员变量来替换。
以下面的代码为例:
public class A{ public int a=1; public int b=2 } public class B { //方法getAB使用类A里面的a,b private void getAB() { A x = new A(); x.a; x.b; } }
由于对象A不会被其他对象访问,那么就会被标量替换为
public class B { private void getAB(){ a = 1; b = 2; } }
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号