
Kafka--JAVA代码样例
一、原生API
(一)生产者
生产者的发送可以分为异步发送、异步回调发送和同步发送。除了三种发送方式外,还可以进行批量发送,也可以在发送时对发送者进行拦截进行特殊处理。
1、异步发送
异步发送就是生产者将消息发送到分区器后,就不再管后续的流程(分区器是否发送到broker成功)
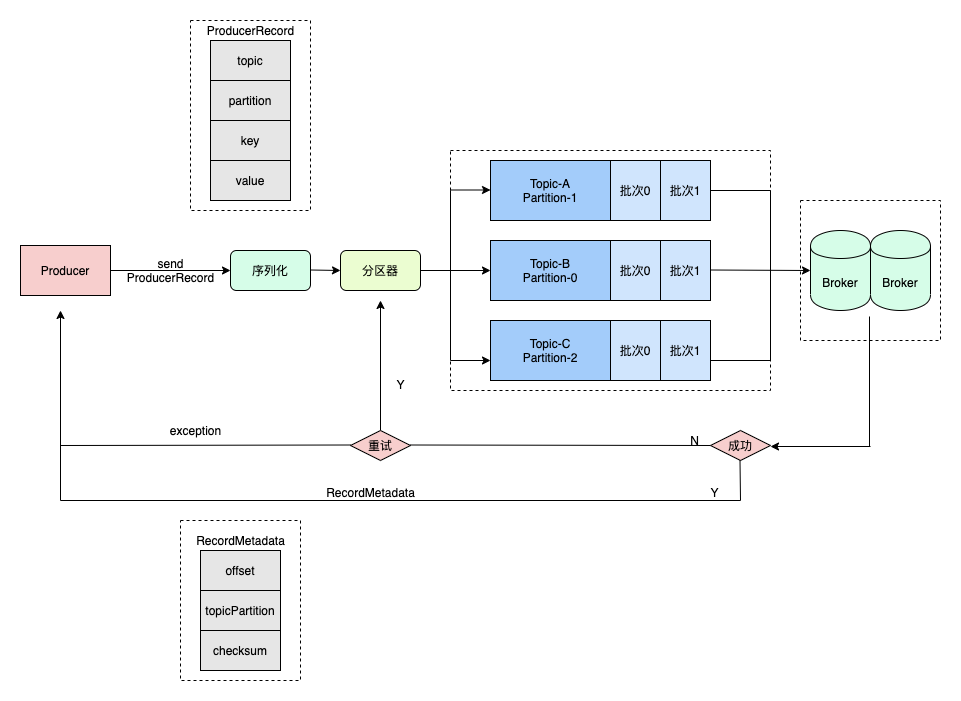
代码样例:
private static final long EXPIRE_INTERVAL = 10 * 1000; // 第一个泛型:当前生产者所生产消息的key // 第二个泛型:当前生产者所生产的消息本身 private KafkaProducer<Integer, String> producer; public OneProducer() { Properties properties = new Properties(); // 指定kafka集群 properties.put("bootstrap.servers", "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"); // 指定key与value的序列化器 properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("acks", "all");// 记录完整提交,最慢的但是最大可能的持久化 // properties.put("retries", 3);// 请求失败重试的次数 properties.put(ProducerConfig.RETRIES_CONFIG, 3); // properties.put("retry.backoff.ms", 100);// 两次重试之间的时间间隔 默认为100ms properties.put("batch.size", 16384);// batch的大小 producer将试图批处理消息记录,以减少请求次数。这将改善client与server之间的性能。默认是16384Bytes,即16kB,也就是一个batch满了16kB就发送出去 //如果batch太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里。 properties.put("linger.ms", 1);// 默认情况即使缓冲区有剩余的空间,也会立即发送请求,设置一段时间用来等待从而将缓冲区填的更多,单位为毫秒,producer发送数据会延迟1ms,可以减少发送到kafka服务器的请求数据 properties.put("buffer.memory", 33554432);// 提供给生产者缓冲内存总量,设置发送消息的缓冲区,默认值是33554432,就是32MB. // 如果发送消息出去的速度小于写入消息进去的速度,就会导致缓冲区写满,此时生产消息就会阻塞住,所以说这里就应该多做一些压测,尽可能保证说这块缓冲区不会被写满导致生产行为被阻塞住 properties.put("partitioner.class","com.lcl.galaxy.kafka.nativeapi.producer.MyPartitioner"); /** * 请求超时 * * ==max.request.size== * * 这个参数用来控制发送出去的消息的大小,默认是1048576字节,也就1mb * * 这个一般太小了,很多消息可能都会超过1mb的大小,所以需要自己优化调整,把他设置更大一些(企业一般设置成10M) * * ==request.timeout.ms== * * 这个就是说发送一个请求出去之后,他有一个超时的时间限制,默认是30秒 * * 如果30秒都收不到响应,那么就会认为异常,会抛出一个TimeoutException来让我们进行处理 * *重试乱序 * max.in.flight.requests.per.connection * * * 每个网络连接已经发送但还没有收到服务端响应的请求个数最大值 * 消息重试是可能导致消息的乱序的,因为可能排在你后面的消息都发送出去了,你现在收到回调失败了才在重试,此时消息就会乱序, * 所以可以使用“max.in.flight.requests.per.connection”参数设置为1,这样可以保证producer必须把一个请求发送的数据发送成功了再发送后面的请求。避免数据出现乱序 */ this.producer = new KafkaProducer<Integer, String>(properties); // ProducerRecord<Integer, String> record3 = new ProducerRecord<>("cities", "tianjin"); } public void sendMsg() throws ExecutionException, InterruptedException { // 创建消息记录(包含主题、消息本身) (String topic, V value) // ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin"); // 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value) // ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin"); // 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value) ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 0, 1, "hangzhou"); producer.send(record); }
2、异步回调发送
异步回调发送与异步发送的区别就很明显了,当发布完成后,会接受后续结果(分区器到broker的结果)的回调。
代码样例:
public void sendMsg() { // 创建消息记录(包含主题、消息本身) (String topic, V value) // ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin"); // 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value) // ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin"); // 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value) ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, 1, "tianjin"); producer.send(record, (metadata, ex) -> { System.out.println("ok"); System.out.println("topic = " + metadata.topic()); System.out.println("partition = " + metadata.partition()); System.out.println("offset = " + metadata.offset()); }); // producer.send(record, new Callback() { // @Override // public void onCompletion(RecordMetadata metadata, Exception exception) { // System.out.println("ok"); // System.out.println("topic = " + metadata.topic()); // System.out.println("partition = " + metadata.partition()); // System.out.println("offset = " + metadata.offset()); // } // }); }
3、同步发送
同步发送就是要等到分区器与broker的处理结果才会返回发送结果。
public void sendMsg() throws ExecutionException, InterruptedException { for(int i=0;i<10;i++){ ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "beijing-"+i); /** * 同步发送或异步阻塞发送 * */ Future<RecordMetadata> send = producer.send(record); RecordMetadata result = send.get(); //阻塞 System.out.println("partion:"+result.partition()+",offset:"+result.offset()); } producer.close(); }
4、批量发送
Kafka使⽤异步批量的⽅式发送消息。当Producer⽣产⼀条消息时,并不会⽴刻发送到Broker,⽽是先放⼊到消息缓冲区,等到缓冲区满或者消息个数达到限制后,再批量发送到Broker。
Producer端需要注意以下参数:
buffer.memory参数:表示消息缓存区的⼤⼩,单位是字节。
batch.size参数:batch的阈值。当kafka采⽤异步⽅式发送消息时,默认是按照batch模式发送。其中同⼀主题同⼀分区的消息会默认合并到⼀个batch内,当达到阈值后就会发送。
linger.ms参数:表示消息的最⼤的延时时间,默认是0,表示不做停留直接发送。
private KafkaProducer<Integer, String> producer; public SomeProducerBatch() { Properties properties = new Properties(); // 指定kafka集群 properties.put("bootstrap.servers", "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"); // 指定key与value的序列化器 properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定生产者每1024条消息向broker发送一次 properties.put("batch.size", 1024); // 指定生产者每50ms向broker发送一次 properties.put("linger.ms", 50); this.producer = new KafkaProducer<Integer, String>(properties); } public void sendMsg() { for(int i=0; i<10; i++) { String str = "beijing-"+i; ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 0,str); int k = i; producer.send(record, (metadata, ex) -> { System.out.println("i = " + k); System.out.println("topic = " + metadata.topic()); System.out.println("partition = " + metadata.partition()); System.out.println("offset = " + metadata.offset()); }); } }
5、生产者拦截器
⽣产者拦截器既可以⽤来在消息发送前做以下准备⼯作,⽐如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可⽤⽤来在发送回调逻辑前做⼀些定制化的需求。
(1)创建一个拦截器,拦截生产者的发送、关闭等场景,例如在发送时修改发送的topic等信息
public class ProducerInterceptorPrefix implements ProducerInterceptor<String,String> { private volatile long sendSuccess = 0; private volatile long sendFailure = 0; /** * KafkaProducer在将消息序列化和计算分区之前会调用生产者拦截器的onSend()方法来对消息进行 * 相应的定制化操作。一般来说最好不要修改ProducerRecord的topic、key和partition等消息。 * 如果要修改,需确保对其有准确性的判断,否则会预想的效果出现偏差。 * @param record * @return */ @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { String modefiedValue = "prefix1-" + record.value(); return new ProducerRecord<>(record.topic(), record.partition(),record.timestamp(),record.key(), modefiedValue,record.headers()); } /** * Kafka会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者onAcknowledgement方法, * 优先于用户设定的Callback之前执行。这个方法运行在Producer的I/O线程中,所以这个方法中实现的代码逻辑越简单越好 * 否则会影响消息的发送速度。 * @param metadata * @param exception */ @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { if(exception==null){ sendSuccess++; }else { sendFailure++; } } /** * close()方法主要用于关闭拦截器时执行一些资源的清理工作。 * 在这3个方法中抛出的异常都会被记录到日志中,但不会再向上传递 */ @Override public void close() { double successRatio = (double) sendSuccess /(sendFailure + sendSuccess); System.out.println("[INFO] 发送成功率="+String.format("%f",successRatio * 100)+"%"); } @Override public void configure(Map<String, ?> configs) { } }
(2)设置消息发送的拦截器,并发送消息(红色注释的代码)
private KafkaProducer<Integer, String> producer; public FiveProducer() { Properties properties = new Properties(); // 指定kafka集群 properties.put("bootstrap.servers", "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"); // 指定key与value的序列化器 properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("acks", "all");// 记录完整提交,最慢的但是最大可能的持久化 // properties.put("retries", 3);// 请求失败重试的次数 properties.put(ProducerConfig.RETRIES_CONFIG, 3); // properties.put("retry.backoff.ms", 100);// 两次重试之间的时间间隔 默认为100ms properties.put("batch.size", 16384);// batch的大小 producer将试图批处理消息记录,以减少请求次数。这将改善client与server之间的性能。默认是16384Bytes,即16kB,也就是一个batch满了16kB就发送出去 //如果batch太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里。 properties.put("linger.ms", 1);// 默认情况即使缓冲区有剩余的空间,也会立即发送请求,设置一段时间用来等待从而将缓冲区填的更多,单位为毫秒,producer发送数据会延迟1ms,可以减少发送到kafka服务器的请求数据 properties.put("buffer.memory", 33554432);// 提供给生产者缓冲内存总量,设置发送消息的缓冲区,默认值是33554432,就是32MB. // 如果发送消息出去的速度小于写入消息进去的速度,就会导致缓冲区写满,此时生产消息就会阻塞住,所以说这里就应该多做一些压测,尽可能保证说这块缓冲区不会被写满导致生产行为被阻塞住 properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptorPrefix.class.getName()); this.producer = new KafkaProducer<Integer, String>(properties); } public void sendMsg() throws ExecutionException, InterruptedException { ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "shanghai"); producer.send(record); }
(二)消费者
消费者进行消费也可以分为自动提交()、同步手动提交、异步手动提交、同异步手动提交三种模式,除了这三种模式外,消费者也可以使用拦截器进行消费拦截。
1、自动提交
⾃动提交 可能会出现消息重复消费的情况,使用时只需要设置enable.auto.commit为true即可。
private KafkaConsumer<Integer, String> consumer; public SomeConsumer() { // 两个参数: // 1)指定当前消费者名称 // 2)指定消费过程是否会被中断 Properties properties = new Properties(); properties.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaConsumerTest"); String brokers = "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"; // 指定kafka集群 properties.put("bootstrap.servers", brokers); // 指定消费者组ID properties.put("group.id", "cityGroup1"); // 开启自动提交,默认为true properties.put("enable.auto.commit", "true"); // 设置一次poll()从broker读取多少条消息 properties.put("max.poll.records", "500"); // 指定自动提交的超时时限,默认5s properties.put("auto.commit.interval.ms", "1000"); // 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker // 认为消费者已经挂掉。默认为10s properties.put("session.timeout.ms", "30000"); // 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3 properties.put("heartbeat.interval.ms", "10000"); // 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为: // earliest:指定offset为第一条offset // latest: 指定offset为最后一条offset properties.put("auto.offset.reset", "earliest"); // 指定key与value的反序列化器 properties.put("key.deserializer","org.apache.kafka.common.serialization.IntegerDeserializer"); properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); this.consumer = new KafkaConsumer<Integer, String>(properties); } public void doWork() { // 订阅消费主题 // consumer.subscribe(Collections.singletonList("cities")); consumer.subscribe(Arrays.asList("cities", "test")); // 从broker获取消息。参数表示,若buffer中没有消息,消费者等待消费的时间。 // 0,表示没有消息什么也不返回 // >0,表示当时间到后仍没有消息,则返回空 while (true) { ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(100)); for(ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); } } }
2、同步手动提交
同步提交⽅式是,消费者向 broker 提交 offset 后等待 broker 成功响应。若没有收到响应,则会重新提交,直到获取到响应。⽽在这个等待过程中,消费者是阻塞的。其严重影响了消费者的吞吐量。
构造器与前面的自动提交一样,只需要设置enable.auto.commit为false即可(不设置也可以,默认为false)。然后在消费消息时,手动提交。 手动提交的代码样例如下所示:
public void doWork() { // 订阅消费主题 consumer.subscribe(Collections.singletonList("cities")); // 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。 // 0,表示没有消息什么也不返回 // >0,表示当时间到后仍没有消息,则返回空 while(true){ ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(1000)); for(ConsumerRecord record : records) { System.out.println("topic2 = " + record.topic()); System.out.println("partition2 = " + record.partition()); System.out.println("key2 = " + record.key()); System.out.println("value2 = " + record.value()); // 如果业务执行成功,手动同步提交。反之,不执行提交,达到失败的场景,可以进行重试的效果 consumer.commitSync(); } } }
3、异步手动提交
⼿动同步提交⽅式需要等待 broker 的成功响应,效率太低,影响消费者的吞吐量。异步提交⽅式是,消费者向 broker 提交 offset 后不⽤等待成功响应,所以其增加了消费者的吞吐量。
构造器与同步手动提交一致,只是消费时不一样,消费代码如下所示:
public void doWork() { while(true){ // 订阅消费主题 consumer.subscribe(Collections.singletonList("cities")); // 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。 // 0,表示没有消息什么也不返回 // >0,表示当时间到后仍没有消息,则返回空 ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(1000)); for(ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); } consumer.commitAsync(); // 手动异步提交 // consumer.commitAsync(); consumer.commitAsync((offsets, ex) -> { if(ex != null) { System.out.print("提交失败,offsets = " + offsets); System.out.println(", exception = " + ex); } }); } }
4、同异步手动提交
同异步提交,即同步提交与异步提交组合使⽤。⼀般情况下,若偶尔出现提交失败,其也不会影响消费者的消费。因为后续提交最终会将这次提交失败的 offset 给提交了。但异步提交会产⽣重复消费,为了防⽌重复消费,可以将同步提交与异常提交联合使⽤。
public void doWork() { // 订阅消费主题 consumer.subscribe(Collections.singletonList("cities")); // 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。 // 0,表示没有消息什么也不返回 // >0,表示当时间到后仍没有消息,则返回空 while(true){ ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(1000)); for(ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); } // 手动异步提交 consumer.commitAsync((offsets, ex) -> { if(ex != null) { System.out.print("提交失败,offsets = " + offsets); System.out.println(", exception = " + ex); // 同步提交 consumer.commitSync(); } }); } }
5、消费者拦截器
消费者拦截器需要⾃定义实现org.apache.kafka.clients.consumer.ConsumerInterceptor接⼝。此接⼝包含3个⽅法:
KafkaConsumer会在poll()⽅法返回之前调⽤拦截器的onConsumer()⽅法来对消息进⾏相应的定制化操作,⽐如修改返回的消息内容、按照某种规则过滤消息(可能会减少poll()⽅法返回的消息个数)。如果onConsumer()⽅法中抛出异常,那么被捕获并记录到⽇志中,但是异常不会再向上传递。
KafkaConsumer会在提交完消费位移之后调⽤拦截器的onCommit()⽅法,可以使⽤这个⽅法来记录跟踪所提交的位移信息,⽐如消费者使⽤commitSync的⽆参数⽅法是,我们不知道提交的消费位移的具体细节,⽽使⽤拦截器的conCommit()⽅法可以做到这⼀点。
(1)创建拦截器
public class ConsumerInterceptorTTL implements ConsumerInterceptor<String,String> { private static final long EXPIRE_INTERVAL = 10 * 1000; @Override public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) { long now = System.currentTimeMillis(); Map<TopicPartition, List<ConsumerRecord<String,String>>> newRecords = new HashMap<>(); for(TopicPartition tp:records.partitions()){ List<ConsumerRecord<String,String>> tpRecords = records.records(tp); List<ConsumerRecord<String,String>> newTpRecords = new ArrayList<>(); for (ConsumerRecord<String,String> record:tpRecords){ if(now - record.timestamp()<EXPIRE_INTERVAL){ newTpRecords.add(record); } } if(!newTpRecords.isEmpty()){ newRecords.put(tp,newTpRecords); } } return new ConsumerRecords<>(newRecords); } @Override public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) { /* offsets.forEach((tp,offset)-> System.out.println(tp+":"+offset.offset())); */ } @Override public void close() {} @Override public void configure(Map<String, ?> configs) {} }
(2)使用拦截器(红色标注的代码)
private KafkaConsumer<Integer, String> consumer; public SomeConsumer() { // 两个参数: // 1)指定当前消费者名称 // 2)指定消费过程是否会被中断 Properties properties = new Properties(); properties.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaConsumerTest"); String brokers = "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"; // 指定kafka集群 properties.put("bootstrap.servers", brokers); // 指定消费者组ID properties.put("group.id", "cityGroup1"); // 开启自动提交,默认为true properties.put("enable.auto.commit", "true"); // 设置一次poll()从broker读取多少条消息 properties.put("max.poll.records", "500"); // 指定自动提交的超时时限,默认5s properties.put("auto.commit.interval.ms", "1000"); // 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker // 认为消费者已经挂掉。默认为10s properties.put("session.timeout.ms", "30000"); // 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3 properties.put("heartbeat.interval.ms", "10000"); // 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为: // earliest:指定offset为第一条offset // latest: 指定offset为最后一条offset properties.put("auto.offset.reset", "earliest"); // 指定key与value的反序列化器 properties.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer"); properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, ConsumerInterceptorTTL.class.getName()); this.consumer = new KafkaConsumer<Integer, String>(properties); } public void doWork() { // 订阅消费主题 // consumer.subscribe(Collections.singletonList("cities")); List<String> topics = new ArrayList<>(); topics.add("cities"); topics.add("test"); consumer.subscribe(topics); /** * 一共发了3条消息:first-expire-data、normal-data、last-expire-data。 * 第一条、第三条被修改成超时了,那么此时消费者通过poll()方法只能拉取normal-data这一条消息,另外两条被过滤了 */ while (true){ ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(1000)); for(ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); } } }
(三)多线程消费
private final static String TOPIC_NAME = "cities"; public static void main(String[] args) throws InterruptedException { String brokers = "192.168.124.15:9092,192.168.124.15:9093,192.168.124.15:9094"; String groupId = "test"; int workerNum = 5; CunsumerExecutor consumers = new CunsumerExecutor(brokers, groupId, TOPIC_NAME); consumers.execute(workerNum); Thread.sleep(1000000); consumers.shutdown(); } // Consumer处理 public static class CunsumerExecutor{ private final KafkaConsumer<String, String> consumer; private ExecutorService executors; public CunsumerExecutor(String brokerList, String groupId, String topic) { Properties props = new Properties(); props.put("bootstrap.servers", brokerList); props.put("group.id", groupId); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); } public void execute(int workerNum) { executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy()); while (true) { ConsumerRecords<String, String> records = consumer.poll(200); for (final ConsumerRecord record : records) { executors.submit(new ConsumerRecordWorker(record)); } } } public void shutdown() { if (consumer != null) { consumer.close(); } if (executors != null) { executors.shutdown(); } try { if (!executors.awaitTermination(10, TimeUnit.SECONDS)) { System.out.println("Timeout.... Ignore for this case"); } } catch (InterruptedException ignored) { System.out.println("Other thread interrupted this shutdown, ignore for this case."); Thread.currentThread().interrupt(); } } } // 记录处理 public static class ConsumerRecordWorker implements Runnable { private ConsumerRecord<String, String> record; public ConsumerRecordWorker(ConsumerRecord record) { this.record = record; } @Override public void run() { // 假如说数据入库操作 System.out.println("Thread - "+ Thread.currentThread().getName()); System.err.printf("patition = %d , offset = %d, key = %s, value = %s%n", record.partition(), record.offset(), record.key(), record.value()); } }
二、Spring Boot Kafka
使用SpringBoot与原生的API主要调整三点,分别是:producer和consumer等配置项直接放入配置文件、发送消息使用KafkaTemplate、消费者使用KafkaListener注解即可。
1、配置项
kafka: topic: cities spring: kafka: bootstrap-servers: 192.168.206.131:9092,192.168.206.132:9092,192.168.206.133:9092 producer: key-serializer: org.apache.kafka.common.serialization.IntegerSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer batch-size: 16384 consumer: group-id: mygroup1 enable-auto-commit: false key-deserializer: org.apache.kafka.common.serialization.IntegerDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer max-poll-records: 10
2、发送消息
@RestController @RequestMapping("/boot") @Slf4j public class BootProducerApi { @Autowired private KafkaTemplate kafkaTemplate; @Value("${kafka.topic}") private String topic; @GetMapping("/send") public void sendMsg() throws Exception { String cityName = "LY"; for(int i=0; i<50; i++) { ProducerRecord<Integer,String> record = new ProducerRecord<>(topic,cityName + i*1000); ListenableFuture<SendResult> future = kafkaTemplate.send(record); RecordMetadata recordMetadata = future.get().getRecordMetadata(); log.info("producer=======【{}】=======【{}】", i+1, recordMetadata.offset()); log.info("producer=======【{}】=======【{}】", i+1, recordMetadata.partition()); log.info("producer=======【{}】=======【{}】", i+1, recordMetadata.timestamp()); log.info("producer=======【{}】=======【{}】", i+1, recordMetadata.topic()); } } }
3、消费者
@Component @Slf4j public class BootConsumer { @KafkaListener(topics = "${kafka.topic}") public void onMsg(String msg){ log.info("consumer============msg=【{}】",msg); } }
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号