
mysql索引优化
数据量预估达到多少是建立索引比较好(10w+)
这个看你的应用查询数据量的大小,查询值越多,数据库压力越大,还要看你负载均衡和建立索引,看你的并发量,即同一瞬间操作数据库的次数
建立索引注意的地方:
1,某个字段的值大量出现在where并且值没有太多重复的或者字段的值太少(像enum这种就不需要索引 ,int等类型的表男女性别关系的大量重复也不需要)
2,小型的表也不需要建立索引;对于小型的表,建立索引可能会影响性能
3,一张表中不要出现太多的索引
4,避免选择大型数据类型的列作为索引 如text数据类型的字段
5,在SQL语句中经常进行GROUP BY、ORDER BY的字段上建立索引
6,查询较多的表才建立索引,经常增删改的表不要建立索引
6,用于联接的列(主健/外健)上建立索引{导致死锁的头号原因是外键未加索引(第二号原因是表上的位图索引遭到并发更新)}
7、建议将需要建立索引的字段加上not null(因为 对含有null的字段添加索引会使索引的计算更加复杂,且还需要额外多一个字节)
查看索引的使用情况
show status like 'Handler_read%'; show global status like 'Handler_read%'; (flush 不会重置 global状态)
SHOW SESSION STATUS LIKE "%handler_read%"; 和(show status like 'Handler_read%';)一样?
例子:
FLUSH STATUS;
SELECT …;
SHOW SESSION STATUS LIKE ‘Handler_read%’;
EXPLAIN SELECT …;
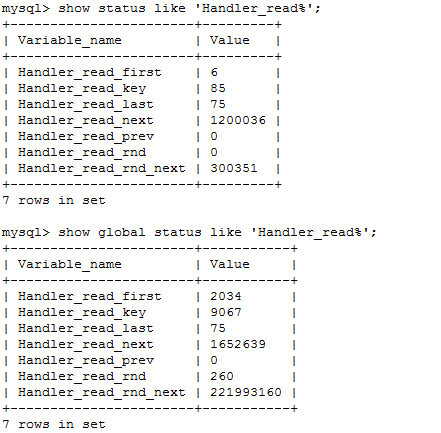
Handler_read_first: 表明SQL是在做一个全索引扫描,注意是全部,而不是部分;例如,SELECT col1 FROM foo,假定col1有索引(这个值越低越好)。所以说如果存在WHERE语句,这个选项是不会变的。如果这个选项的数值很大,既是好事 也是坏事。说它好是因为毕竟查询是在索引里完成的,而不是数据文件里,说它坏是因为大数据量时,简便是索引文件,做一次完整的扫描也是很费时的 Handler_read_key: 此选项数值如果很高,那么恭喜你,你的系统高效的使用了索引,一切运转良好(越大约好) Handler_read_next: 此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数 Handler_read_prev: 此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,一般就是ORDER BY … DESC Handler_read_rnd : 简单的说,就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序。这个值较高,意味着运行效率低,应该建立索引来补救。 Handler_read_rnd_next: 此选项表明在进行数据文件扫描时,从数据文件里取数据的次数,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。(越小越好)
重复数据较多的列(键值较少的列)不适合建立索引
对于非常小的的表,大部分情况下全表扫描更好
中到大型表,索引非常有效
特大型表,建立和使用索引的代价将随之增长,可以使用分区技术来解决
1、最适合创建索引的列通常时出现在where子句中;对于查询占主要的应用来说,不加索引的话会进行全表扫描,但性别这种可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引
2、索引不同列的值不同的越多索引效果越好
3、数据越多效果越好
4、不要过多使用索引 每个额外的索引都需要额外的磁盘空间。降低读写的性能
5、创建索引的列不要让字段的默认值为NULL。
对字符串进行索引,应该制定一个前缀长度,可以节省大量的索引空间
对字符串进行索引,应该指定一个前缀长度,请问怎么指定?
ADD INDEX `table_title` (title(4));//title为字段
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上(如整型的字段),对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否
极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响
索引遵循原则:
1、组合索引遵循前缀原则
key(a,b,c)
生效的语句:
where a=1 and b=2 and c=3
where a=1 and b=2
where a=1
不生效的语句:
where b=2 and c=3
where a=1 and b=3
where b=2
where b=3
2、like查询时 %在前是不生效的 如 where name like %lisi% 我们可以使用全文索引(MyISAM)InnodDB在5.6页支持全文索引了
3、column is null 可以使用索引(判断列是否为null)
B-tree索引 is null不会生效,相反is not null会生效
而BitMap索引在 is null和 is not null 的情况下都可以生效
4、如果mysql估计使用索引比全表扫描更慢,会放弃使用索引
如: where id>1 and id < 100 索引的原理是先在索引里找2在什么位置,找到2的位置在去定位数据行 然后在看3在索引的什么位置在去定位 这样依次到99 mysql认为只有98条直接全部扫描更快,所以会放弃索引
5、如果or前的条件中的列有索引,后面的没有,索引不会被用到
6、列类型是字符串,查询时一定要给值加引号否则索引失效
索引对性能的影响:
大大减少服务器的扫描的数据量
帮助服务器避免排序和临时表
将随机I/O变顺序I/O
大大提高查询速度。 降低写的速度。占用磁盘
1.避免使用select *
2.count(1)或count(列) 代替 count(*)3. 创建表时尽量时 char 代替 varchar4. 表的字段顺序固定长度的字段优先5. 组合索引代替多个单列索引(经常使用多个条件查询时)6. 使用连接(JOIN)来代替子查询(Sub-Queries)7. 不要有超过5个以上的表连接(JOIN)8. 优先执行那些能够大量减少结果的连接。9. 连表时注意条件类型需一致10.索引散列值不适合建索引,例:性别不适合1、索引列的字段类型与查询的不同 如 vachar类型的数字没有添加引号,或者int类型的查询时加了引号 2、使用or 时 or两端的字段至少有一个没有索引(所以or两端的字段必须都要索引哦) 3、多列索引的查询时(组合索引没有遵循前缀原则) 必须使用第一个开头(如索引为name,age 查询where age=28则失效; where name=‘tom’ and age=28 或者name=‘tom’则有效) 4、like 以 %开头 5、如果mysql估计使用全表扫描要比使用索引快,则不使用索引 6、查询的数量是大表的大部分,应该是30%以上。 如表里有1000万条记录,一条SQL查的结果有600万,肯定不会走索引了 6、索引列上用了函数的时候,例如where to_char(id) = ... 7、强制全表扫描的时候 6)其他索引失效的时候 使用+ - * / ! 等运算符号 使用 <> 、not in 、not exist、!=
当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况 8、索引列存在null
B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走
联合索引 is not null 只要在建立的索引列(不分先后)都会走, in null时 必须要和建立索引第一列一起使用,当建立索引第一位置条件是is null 时,其他建立索引的列可以是is null(但必须在所有列 都满足is null的时候),或者=一个值; 当建立索引的第一位置是=一个值时,其他索引列可以是任何情况(包括is null =一个值),以上两种情况索引都会走。其他情况不会走

 浙公网安备 33010602011771号
浙公网安备 33010602011771号