
42-案例篇:如何优化NAT性能(下)
案例准备
-
服务器准备
buntu 18.04 机器配置:2CPU,4GB内存 预先安装docker、tcpdump、curl、ab、SystemTap等工具 # Ubuntu $ apt-get install -y docker.io tcpdump curl apache2-utils # CentOS $ curl -fsSL https://get.docker.com | sh $ yum install -y tcpdump curl httpd-toolsSystemTap是Linux的一种动态追踪框架,
它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核的行为# Ubuntu $ apt-get install -y systemtap-runtime systemtap # Configure ddebs source $ echo "deb http://ddebs.ubuntu.com $(lsb_release -cs) main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-updates main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-proposed main restricted universe multiverse" | \ sudo tee -a /etc/apt/sources.list.d/ddebs.list # Install dbgsym $ apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F2EDC64DC5AEE1F6B9C621F0C8CAB6595FDFF622 $ apt-get update $ apt install ubuntu-dbgsym-keyring $ stap-prep $ apt-get install linux-image-`uname -r`-dbgsym # CentOS $ yum install systemtap kernel-devel yum-utils kernel $ stab-prep本次案例还是最常见的Nginx,并且会用ab作为它的客户端,进行压力测试
案例中总共用到两台虚拟机
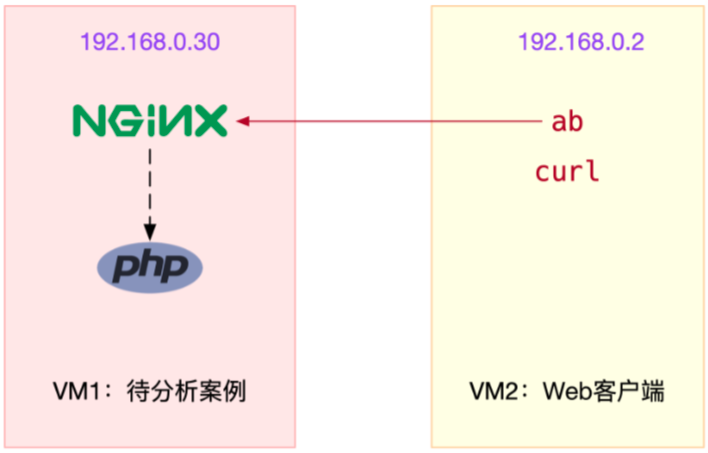
注意,curl和ab只需要在客户端VM(即VM2)中安装
-
终端一,执行下面的命令,启动Nginx,注意选项--network=host
表示容器使用Host网络模式,即不使用NAT$ docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80 -
终端二,执行curl命令,确认Nginx正常启动
$ curl http://192.168.0.30/ ... <p><em>Thank you for using nginx.</em></p> </body> </html> -
终端二,执行ab命令,对Nginx进行压力测试
不过在测试前要注意,Linux默认允许打开的文件描述数比较小,这个值只有1024# open files $ ulimit -n 1024 # 执行ab前先把这个选项调大,比如调成65536 # 临时增大当前会话的最大文件描述符数 $ ulimit -n 65536 # 执行ab命令,进行压力测试 # -c表示并发请求数为5000 # -n表示总的请求数为10万 # -r表示套接字接收错误时仍然继续执行 # -s表示设置每个请求的超时时间为2s $ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/ ... Requests per second: 6576.21 [#/sec] (mean) Time per request: 760.317 [ms] (mean) Time per request: 0.152 [ms] (mean, across all concurrent requests) Transfer rate: 5390.19 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 177 714.3 9 7338 Processing: 0 27 39.8 19 961 Waiting: 0 23 39.5 16 951 Total: 1 204 716.3 28 7349 ... ## 记住这几个数值,这将是接下来案例的基准指标 # 1. 每秒请求数(Requests per second)为6576 # 2. 每个请求的平均延迟(Time per request)为760ms # 3. 建立连接的平均延迟(Connect)为177ms -
终端一,停止这个未使用NAT的Nginx应用
$ docker rm -f nginx-hostnet -
终端一,启动今天的案例应用
案例应用监听8080端口,并且使用了DNAT,来实现Host的8080端口,到容器的8080端口的映射关系$ docker run --name nginx --privileged -p 8080:8080 -itd feisky/nginx:nat -
终端一,执行iptables命令,确认DNAT规则已经创建
$ iptables -nL -t nat Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL ... Chain DOCKER (2 references) target prot opt source destination RETURN all -- 0.0.0.0/0 0.0.0.0/0 DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:8080 ## # 在PREROUTING链中,目的为本地的请求,会转到DOCKER链 # 而在DOCKER链中,目的端口为8080的tcp请求,会被DNAT到172.17.0.2的8080端口 # 其中172.17.0.2就是Nginx容器的IP地址 -
终端二,执行curl命令,确认Nginx已经正常启动
$ curl http://192.168.0.30:8080/ ... <p><em>Thank you for using nginx.</em></p> </body> </html> ## # 执行ab命令,把请求的端口号换成8080,进行压测 # -c表示并发请求数为5000 # -n表示总的请求数为10万 # -r表示套接字接收错误时仍然继续执行 # -s表示设置每个请求的超时时间为2s $ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... apr_pollset_poll: The timeout specified has expired (70007) Total of 5602 requests completed ## # 果然刚才正常运行的ab,现在失败了,还报了连接超时的错误 # 运行ab时的-s参数,设置了每个请求的超时时间为2s,而从输出可以看到,这次只完成了5602个请求 ## # 既然是为了得到ab的测试结果,不妨把超时时间延长一下试试,比如延长到30s # 延迟增大意味着要等更长时间,为了快点得到结果,可以同时把总测试次数也减少到10000 $ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/ ... Requests per second: 76.47 [#/sec] (mean) Time per request: 65380.868 [ms] (mean) Time per request: 13.076 [ms] (mean, across all concurrent requests) Transfer rate: 44.79 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 1300 5578.0 1 65184 Processing: 0 37916 59283.2 1 130682 Waiting: 0 2 8.7 1 414 Total: 1 39216 58711.6 1021 130682 ... ## # 再重新看看ab的输出,这次的结果显示 # 1. 每秒请求数(Requests per second)为76 # 2. 每个请求的延迟(Time per request)为65s # 3. 建立连接的延迟(Connect)为1300ms ## # 显然,每个指标都比前面差了很多 # 那么,碰到这种问题时应该怎么办呢? # 可以根据前面的讲解,先自己分析一下再继续学习下面的内容 ## # 在上一节使用tcpdump抓包的方法,找出了延迟增大的根源 # 那么今天的案例仍然可以用类似的方法寻找线索 # 不过现在换个思路,因为已经事先知道了问题的根源就是NAT -
回忆一下Netfilter中,网络包的流向以及NAT的原理,发现要保证NAT正常工作,就至少需要两个步骤
- 第一利用Netfilter中的钩子函数(Hook),修改源地址或者目的地址
- 第二利用连接跟踪模块conntrack ,关联同一个连接的请求和响应
是不是这两个地方出现了问题呢?用前面提到的动态追踪工具SystemTap来试试
由于今天案例是在压测场景下,并发请求数大大降低,并且我知道NAT是罪魁祸首
所以有理由怀疑,内核中发生了丢包现象
-
终端一,创建一个dropwatch.stp 的脚本文件,并写入下面的内容
#! /usr/bin/env stap ############################################################ # Dropwatch.stp # Author: Neil Horman <nhorman@redhat.com> # An example script to mimic the behavior of the dropwatch utility # http://fedorahosted.org/dropwatch ############################################################ # Array to hold the list of drop points we find global locations # Note when we turn the monitor on and off probe begin { printf("Monitoring for dropped packets\n") } probe end { printf("Stopping dropped packet monitor\n") } # increment a drop counter for every location we drop at probe kernel.trace("kfree_skb") { locations[$location] <<< 1 } # Every 5 seconds report our drop locations probe timer.sec(5) { printf("\n") foreach (l in locations-) { printf("%d packets dropped at %s\n", @count(locations[l]), symname(l)) } delete locations }这个脚本跟踪内核函数kfree_skb()的调用,并统计丢包的位置
文件保存好后,执行stap命令,就可以运行丢包跟踪脚本
这里的stap,是SystemTap的命令行工具$ stap --all-modules dropwatch.stp Monitoring for dropped packets ## # 当看到probe begin输出的“Monitoring for dropped packets”时 # 表明SystemTap已经将脚本编译为内核模块,并启动运行了 -
终端二,再次执行ab命令
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/ -
终端一,观察stap命令的输出
10031 packets dropped at nf_hook_slow 676 packets dropped at tcp_v4_rcv 7284 packets dropped at nf_hook_slow 268 packets dropped at tcp_v4_rcv ## # 发现大量丢包都发生在nf_hook_slow位置 # 看到这个名字应该能想到,这是在Netfilter Hook的钩子函数中,出现丢包问题了 # 但是不是NAT还不能确定 # 接下来还得再跟踪nf_hook_slow的执行过程,这一步可以通过perf来完成 -
终端二,再次执行ab命令
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/ -
终端一,执行perf record和perf report命令
# 记录一会(比如 30s)后按Ctrl+C结束 perf record -a -g -- sleep 30 # 输出报告 perf report -g graph,0在perf report界面中,输入查找命令 / 然后,在弹出的对话框中,输入nf_hook_slow
最后再展开调用栈,就可以得到下面这个调用图
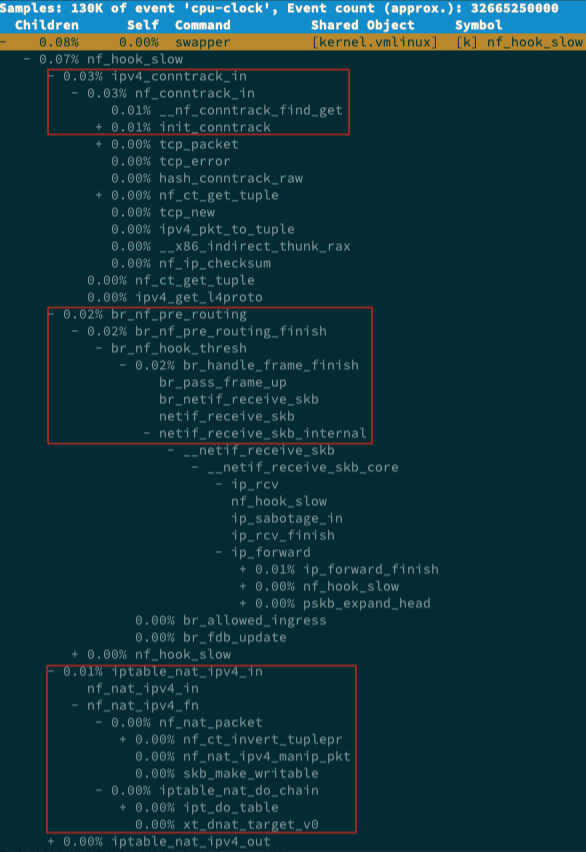
从这个图可以看到nf_hook_slow调用最多的有三个地方
分别是ipv4_conntrack_in、br_nf_pre_routing以及iptable_nat_ipv4_in
换言之nf_hook_slow主要在执行三个动作- 第一接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象(Bucket)
- 第二在Linux网桥中转发包,这是因为案例Nginx是一个Docker容器,而容器的网络通过网桥来实现
- 第三接收网络包时,执行DNAT,即把8080端口收到的包转发给容器
到这里其实就找到了性能下降的三个来源
这三个来源,都是Linux的内核机制,所以接下来的优化,自然也是要从内核入手根据以前各个资源模块的内容知道Linux内核为用户提供了大量的可配置选项
这些选项可以通过proc文件系统或者sys文件系统,来查看和修改
除此之外,还可以用sysctl这个命令行工具,来查看和修改内核配置
-
比如今天的主题是DNAT,而DNAT的基础是conntrack
所以可以先看看内核提供了哪些conntrack的配置选项
终端一,继续执行下面的命令$ sysctl -a | grep conntrack net.netfilter.nf_conntrack_count = 180 net.netfilter.nf_conntrack_max = 1000 net.netfilter.nf_conntrack_buckets = 65536 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 ...可以看到,这里最重要的三个指标
- net.netfilter.nf_conntrack_count,表示当前连接跟踪数
- net.netfilter.nf_conntrack_max,表示最大连接跟踪数
- net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小
所以从这个输出看出,当前连接跟踪数是180,最大连接跟踪数是1000,连接跟踪表的大小,则是65536
回想一下前面的ab命令,并发请求数是5000,而请求数是100000
显然,跟踪表设置成,只记录1000个连接,是远远不够的实际上内核在工作异常时,会把异常信息记录到日志中
比如前面的ab测试内核已经在日志中报出了“nf_conntrack: table full”的错误
执行 dmesg 命令就可以看到$ dmesg | tail [104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet [104243.800401] net_ratelimit: 3939 callbacks suppressed [104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet [104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet其中net_ratelimit表示有大量的日志被压缩掉了,这是内核预防日志攻击的一种措施
而当看到“nf_conntrack: table full”的错误时,就表明nf_conntrack_max太小了那是不是直接把连接跟踪表调大就可以了呢?
调节前得明白,连接跟踪表,实际上是内存中的一个哈希表
如果连接跟踪数过大,也会耗费大量内存其实上面看到的nf_conntrack_buckets,就是哈希表的大小
哈希表中的每一项,都是一个链表,而链表长度,就等于nf_conntrack_max除以nf_conntrack_buckets比如可以估算一下,上述配置的连接跟踪表占用的内存大小
# 连接跟踪对象大小为376,链表项大小为16 nf_conntrack_max* 连接跟踪对象大小 +nf_conntrack_buckets* 链表项大小 = 1000*376+65536*16 B = 1.4 MB接下来将nf_conntrack_max改大一些,比如改成131072(即nf_conntrack_buckets的2倍)
$ sysctl -w net.netfilter.nf_conntrack_max=131072 $ sysctl -w net.netfilter.nf_conntrack_buckets=65536 -
终端二,重新执行ab命令,注意这次把超时时间也改回原来的2s
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... Requests per second: 6315.99 [#/sec] (mean) Time per request: 791.641 [ms] (mean) Time per request: 0.158 [ms] (mean, across all concurrent requests) Transfer rate: 4985.15 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 355 793.7 29 7352 Processing: 8 311 855.9 51 14481 Waiting: 0 292 851.5 36 14481 Total: 15 666 1216.3 148 14645果然现在可以看到
- 每秒请求数(Requests per second)为6315(不用NAT时为6576)
- 每个请求的延迟(Time per request)为791ms(不用NAT时为760ms)
- 建立连接的延迟(Connect)为355ms(不用NAT时为177ms)
这个结果已经比刚才的测试好了很多,也很接近最初不用NAT时的基准结果了
不过连接跟踪表里,到底都包含了哪些东西?这里的东西,又是怎么刷新的呢?
实际上可以用conntrack命令行工具,来查看连接跟踪表的内容# -L表示列表 # -o表示以扩展格式显示 $ conntrack -L -o extended | head ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1 ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1从这里可以发现,连接跟踪表里的对象
包括了协议、连接状态、源IP、源端口、目的IP、目的端口、跟踪状态等
由于这个格式是固定的,所以可以用awk、sort等工具,对其进行统计分析
-
终端二,启动ab命令后,再回到终端一中,执行下面的命令
# 统计总的连接跟踪数 $ conntrack -L -o extended | wc -l 14289 # 统计TCP协议各个状态的连接跟踪数 $ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}' SYN_RECV 4 CLOSE_WAIT 9 ESTABLISHED 2877 FIN_WAIT 3 SYN_SENT 2113 TIME_WAIT 9283 # 统计各个源IP的连接跟踪数 $ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10 14116 192.168.0.2 172 192.168.0.96这里统计了总连接跟踪数TCP协议各个状态的连接跟踪数,以及各个源IP的连接跟踪数
可以看到大部分TCP的连接跟踪,都处于TIME_WAIT状态
并且它们大都来自于192.168.0.2这个IP地址(也就是运行ab命令的VM2)这些处于TIME_WAIT的连接跟踪记录,会在超时后清理,而默认的超时时间是120s,执行下面的命令来查看
$ sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120所以如果连接数非常大,确实也应该考虑,适当减小超时时间
除了上面这些常见配置conntrack还包含了其他很多配置选项
可以根据实际需要参考nf_conntrack的文档来配置
小结
由于NAT基于Linux内核的连接跟踪机制来实现
所以,在分析NAT性能问题时,可以先从conntrack角度来分析
比如用systemtap、perf等,分析内核中conntrack的行文
然后,通过调整netfilter内核选项的参数,来进行优化
其实Linux这种通过连接跟踪机制实现的NAT,也常被称为有状态的NAT,而维护状态,也带来了很高的性能成本
除了调整内核行为外在不需要状态跟踪的场景下(比如只需要按预定的IP和端口进行映射,而不需要动态映射)
也可以使用无状态的NAT (比如用tc或基于DPDK开发),来进一步提升性能

