
40-案例篇:网络请求延迟变大了,我该怎么办?
除 DDoS会带来网络延迟增大外,也有其他原因导致的网络延迟, 比如
- 网络传输慢,导致延迟
- Linux内核协议栈报文处理慢,导致延迟
- 应用程序数据处理慢,导致延迟等等
网络延迟
提到网络延迟时,可能轻松想起它的含义---网络数据传输所用的时间
不过要注意,这个时间可能是单向的,指从源地址发送到目的地址的单程时间
也可能是双向的,即从源地址发送到目的地址,然后又从目的地址发回响应,这个往返全程所用的时间
通常更常用的是双向的往返通信延迟,比如ping测试的结果,就是往返延时RTT(Round-Trip Time)
除了网络延迟外
另一个常用的指标是应用程序延迟,它是指,从应用程序接收到请求, 再到发回响应,全程所用的时间
通常,应用程序延迟也指的是往返延迟,是网络数据传输时间加上数据处理时间的和
在Linux网络基础篇中,可以用ping来测试网络延迟
ping基于ICMP协议,它通过计算ICMP回显响应报文与ICMP回显请求报文的时间差,来获得往返延时
这个过程并不需要特殊认证,常被很多网络攻击利用,比如端口扫描工具nmap、组包工具hping3等等
所以为了避免这些问题,很多网络服务会把ICMP禁止掉
这也就导致我们无法用ping ,来测试网络服务的可用性和往返延时
这时可以用traceroute或hping3的TCP和UDP模式,来获取网络延迟
比如以baidu.com为例,可以执行下面的hping3命令,测试当前机器到百度搜索服务器的网络延迟
# -c表示发送3次请求
# -S表示设置TCP SYN
# -p表示端口号为80
root@alnk:~# hping3 -c 3 -S -p 80 baidu.com
HPING baidu.com (eth0 220.181.38.251): S set, 40 headers + 0 data bytes
len=46 ip=220.181.38.251 ttl=48 id=60840 sport=80 flags=SA seq=0 win=8192 rtt=47.9 ms
len=46 ip=220.181.38.251 ttl=49 id=62209 sport=80 flags=SA seq=1 win=8192 rtt=47.8 ms
len=46 ip=220.181.38.251 ttl=49 id=27368 sport=80 flags=SA seq=2 win=8192 rtt=47.8 ms
--- baidu.com hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 47.8/47.8/47.9 ms
##
从hping3的结果中可以看到,往返延迟RTT为47ms
当然用traceroute,也可以得到类似结果
# --tcp 表示使用TCP协议
# -p 表示端口号
# -n 表示不对结果中的IP地址执行反向域名解析
root@alnk:~# traceroute --tcp -p 80 -n baidu.com
traceroute to baidu.com (220.181.38.148), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 * * *
4 * * *
5 * * *
6 * * *
7 * * *
8 * * *
9 * * *
10 * * *
11 * * *
12 183.60.190.109 5.303 ms * *
13 * * *
14 * * *
15 * * *
16 * * *
17 * * *
18 * * *
19 * * *
20 * * *
21 10.166.96.36 46.231 ms 220.181.38.148 42.693 ms *
##
traceroute会在路由的每一跳发送三个包,并在收到响应后,输出往返延时
如果无响应或者响应超时(默认5s),就会输出一个星号
网络延迟升高时的分析思路案例
-
案例准备
Ubuntu 18.04 机器配置:2CPU,4GB内存 预先安装docker、hping3、tcpdump、curl、wrk、Wireshark 等工具
-
在终端一中,执行下面的命令,运行官方Nginx,它会在80端口监听
root@alnk:~# docker run --network=host --name=good -itd nginx -
继续在终端一中,执行下面的命令,运行案例应用,它会监听8080端口
root@alnk:~# docker run --name nginx --network=host -itd feisky/nginx:latency -
在终端二中执行curl命令,验证两个容器已经正常启动
# 80正常 [root@local_deploy_192-168-1-5 ~]# curl http://124.71.83.217 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> # 8080正常 [root@local_deploy_192-168-1-5 ~]# curl http://124.71.83.217:8080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> -
在终端二,执行下面的命令,分别测试案例机器80端口和8080端口的延迟
# 测试80端口延迟 [root@local_deploy_192-168-1-5 ~]# hping3 -c 3 -S -p 80 124.71.83.217 HPING 124.71.83.217 (eth0 124.71.83.217): S set, 40 headers + 0 data bytes len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=80 flags=SA seq=0 win=64240 rtt=9.8 ms len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=80 flags=SA seq=1 win=64240 rtt=8.5 ms len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=80 flags=SA seq=2 win=64240 rtt=7.4 ms --- 124.71.83.217 hping statistic --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 7.4/8.6/9.8 ms # 测试8080端口延迟 [root@local_deploy_192-168-1-5 ~]# hping3 -c 3 -S -p 8080 124.71.83.217 HPING 124.71.83.217 (eth0 124.71.83.217): S set, 40 headers + 0 data bytes len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=8080 flags=SA seq=0 win=64240 rtt=8.5 ms len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=8080 flags=SA seq=1 win=64240 rtt=7.7 ms len=46 ip=124.71.83.217 ttl=48 DF id=0 sport=8080 flags=SA seq=2 win=64240 rtt=7.6 ms --- 124.71.83.217 hping statistic --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 7.6/7.9/8.5 ms ## # 从这个输出你可以看到,两个端口的延迟差不多,都是8ms # 不过,这只是单个请求的情况。换成并发请求的话,又会怎么样呢? -
在终端二中,执行下面的新命令,分别测试案例机器并发100时80端口和8080端口的性能
# 测试80端口性能 [root@local_deploy_192-168-1-5 ~]# wrk --latency -c 100 -t 2 --timeout 2 http://124.71.83.217/ Running 10s test @ http://124.71.83.217/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 193.99ms 346.67ms 1.86s 87.16% Req/Sec 331.23 1.05k 6.59k 94.97% Latency Distribution 50% 8.35ms 75% 279.98ms 90% 654.18ms 99% 1.61s 6564 requests in 10.01s, 5.34MB read Socket errors: connect 0, read 0, write 0, timeout 83 Requests/sec: 655.87 Transfer/sec: 546.72KB # 测试8080端口性能 [root@local_deploy_192-168-1-5 ~]# wrk --latency -c 100 -t 2 --timeout 2 http://124.71.83.217:8080/ Running 10s test @ http://124.71.83.217:8080/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 311.29ms 398.66ms 1.94s 83.58% Req/Sec 179.02 147.02 1.00k 93.50% Latency Distribution 50% 57.17ms 75% 463.84ms 90% 827.38ms 99% 1.69s 3569 requests in 10.01s, 2.91MB read Socket errors: connect 0, read 0, write 0, timeout 31 Requests/sec: 356.63 Transfer/sec: 297.52KB ## # 从上面两个输出可以看到,官方Nginx(监听在80端口)的平均延迟是193.99ms| # 而案例Nginx的平均延迟(监听在8080端口)则是311.29ms ## 结合上面hping3的输出很容易发现,案例Nginx在并发请求下的延迟增大了很多,这是怎么回事呢? -
使用tcpdump抓取收发的网络包,分析网络的收发过程有没有问题
在终端一中,执行下面的tcpdump命令,抓取8080端口上收发的网络 包,并保存到nginx.pcap文件root@alnk:~# tcpdump -nn tcp port 8080 -w nginx.pcap -
终端二中,重新执行wrk命令
[root@local_deploy_192-168-1-5 ~]# wrk --latency -c 100 -t 2 --timeout 2 http://124.71.83.217:8080/ -
当wrk命令结束后,再次切换回终端一,并按下Ctrl+C结束tcpdump命令
然后,再把抓取到的nginx.pcap ,复制到装有Wireshark的机器中,并用Wireshark打开它
由于网络包的数量比较多,可以先过滤一下
比如,在选择一个包后,可以单击右键并选择 “Follow” -> “TCP Stream”,如下图所示
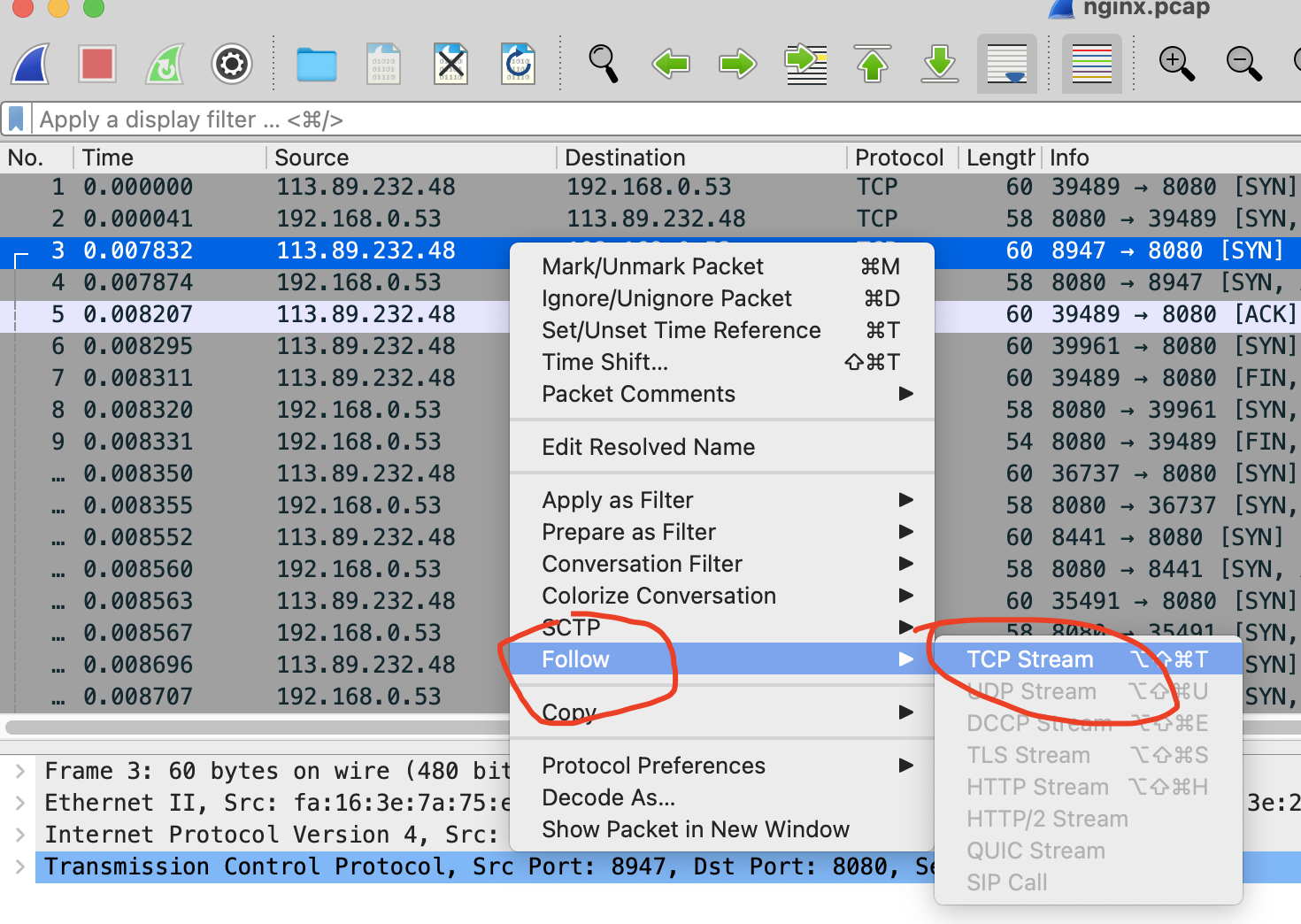
然后,关闭弹出来的对话框,回到Wireshark主窗口,
这时候会发现Wireshark已经自动帮你设置了一个过滤表达式 tcp.stream eq 24
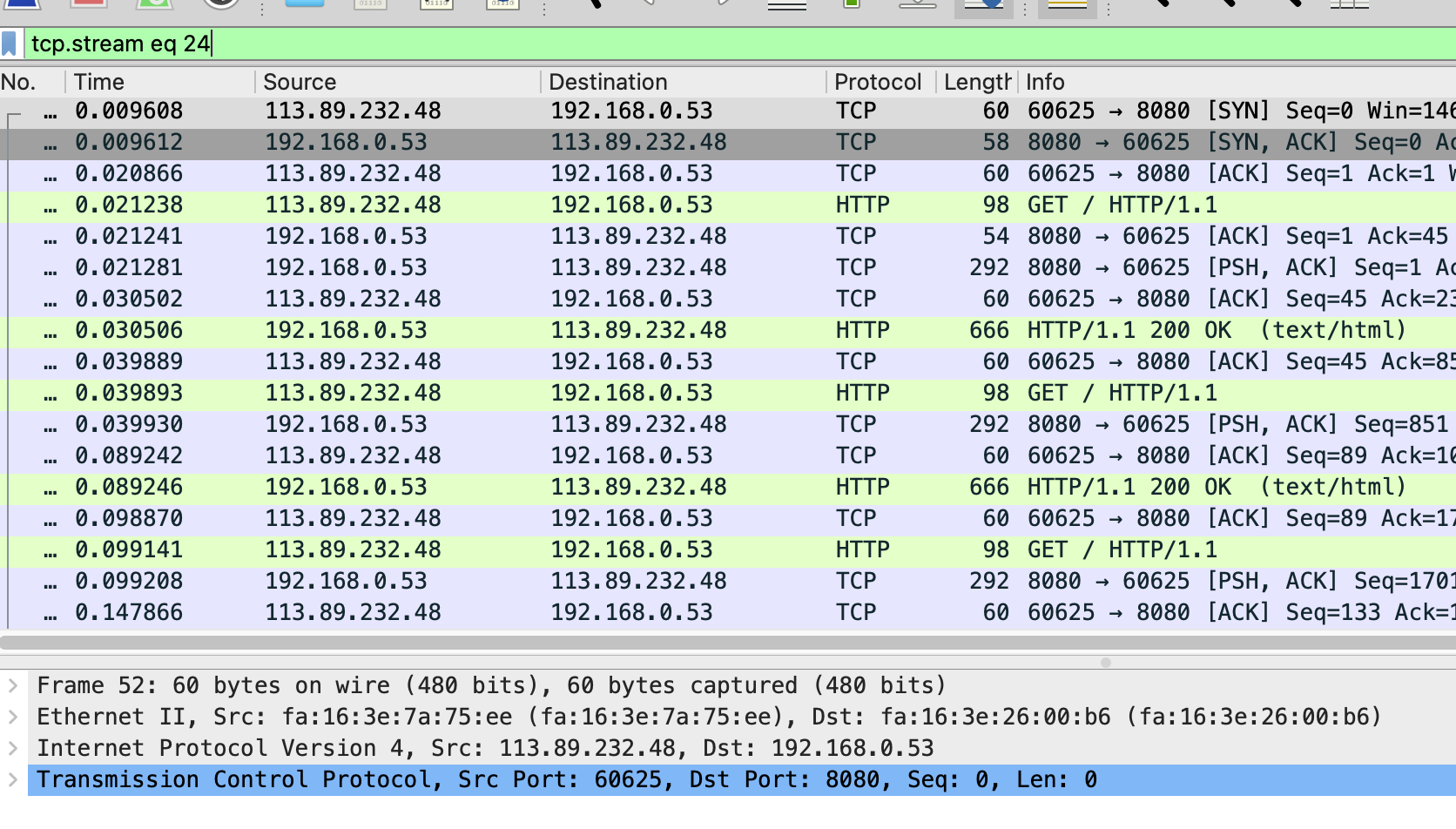
从这里可以看到这个TCP连接从三次握手开始的每个请求和响应情况,当然这可能还不够直观
可以继续点击菜单栏里的Statics -> Flow Graph
选中 “Limit to display filter” 并设置Flow type 为 “TCP Flows”
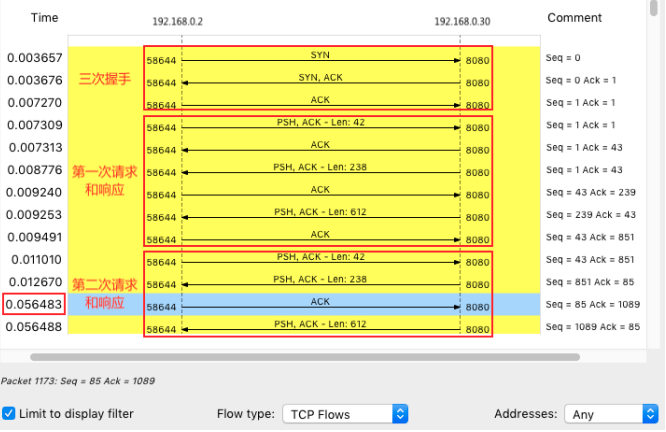
注意这个图的左边是客户端,而右边是Nginx服务器
通过这个图就可以看出,前面三次握手,以及第一次HTTP请求和响应还是挺快的
但第二次HTTP请求就比较慢了,特别是客户端在收到服务器第一个分组后,40ms后才发出了ACK响应
看到40ms这个值有没有想起什么东西呢?实际上,这是TCP延迟确认(Delayed ACK)的最小超时时间这是针对 TCP ACK 的一种优化机制,也就是说,不用每次请求都发送一个ACK
而是先等一会儿(比如40ms),看看有没有“顺风车”
如果这段时间内,正好有其他包需要发送,那就捎带着ACK一起发送过去
当然,如果一直等不到其他包,那就超时后单独发送ACK
因为案例中40ms发生在客户端,有理由怀疑,是客户端开启了延迟确认机制
而这儿的客户端,实际上就是前面运行的wrk查询TCP文档(执行 man tcp)发现,只有TCP套接字专门设置了TCP_QUICKACK ,才会开启快速确认模式
否则,默认情况下,采用的就是延迟确认机制为了验证猜想,确认wrk的行为,可以用strace ,来观察wrk为套接字设置了哪些TCP选项
-
终端二中,执行下面的命令
[root@local_deploy_192-168-1-5 ~]# strace -f wrk --latency -c 100 -t 2 --timeout 2 http://124.71.83.217:8080/ [pid 32138] setsockopt(5, SOL_TCP, TCP_NODELAY, [1], 4) = 0这样可以看到,wrk只设置了TCP_NODELAY选项,而没有设置TCP_QUICKACK
这说明wrk采用的正是延迟确认,也就解释了上面这个40ms的问题不过别忘了,这只是客户端的行为,按理来说Nginx服务器不应该受到这个行为的影响
那是不是分析网络包时漏掉了什么线索呢?回到Wireshark重新观察一 下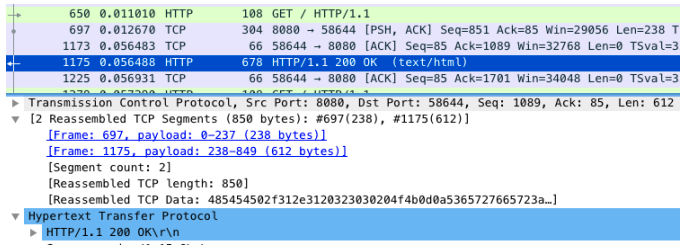
仔细观察 Wireshark 的界面,其中, 1173号包,就是刚才说到的延迟ACK包
下一行的1175 ,则是Nginx发送的第二个分组包
它跟697号包组合起来,构成一个完整的HTTP响应(ACK号都是85)第二个分组没跟前一个分组697号一起发送,而是等到客户端对第一个分组的ACK后1173号才发送
这看起来跟延迟确认有点像,只不过,这儿不再是ACK,而是发送数据看到这里想起了一个东西—— Nagle 算法(纳格算法)
进一步分析案例前, 先简单介绍一下这个算法Nagle算法,是TCP协议中用于减少小包发送数量的一种优化算法,目的是为了提高实际带宽的利用率
举个例子,当有效负载只有1字节时,再加上TCP头部和IP头部分别占用的20字节,整个网络包就是41字节
这样实际带宽的利用率只有 2.4%(1/41)
往大了说,如果整个网络带宽都被这种小包占满,那整个网络的有效利用率就太低了
Nagle算法正是为了解决这个问题
它通过合并TCP小包,提高网络带宽的利用率
Nagle算法规定,一个TCP连接上,最多只能有一个未被确认的未完成分组
在收到这个分组的ACK前,不发送其他分组
这些小分组会被组合起来,并在收到ACK后,用同一个分组发送出去显然Nagle算法本身的想法还是挺好的,但是知道Linux默认的延迟确认机制后
应该就不这么想了,因为它们一起使用时,网络延迟会明显。如下图所示
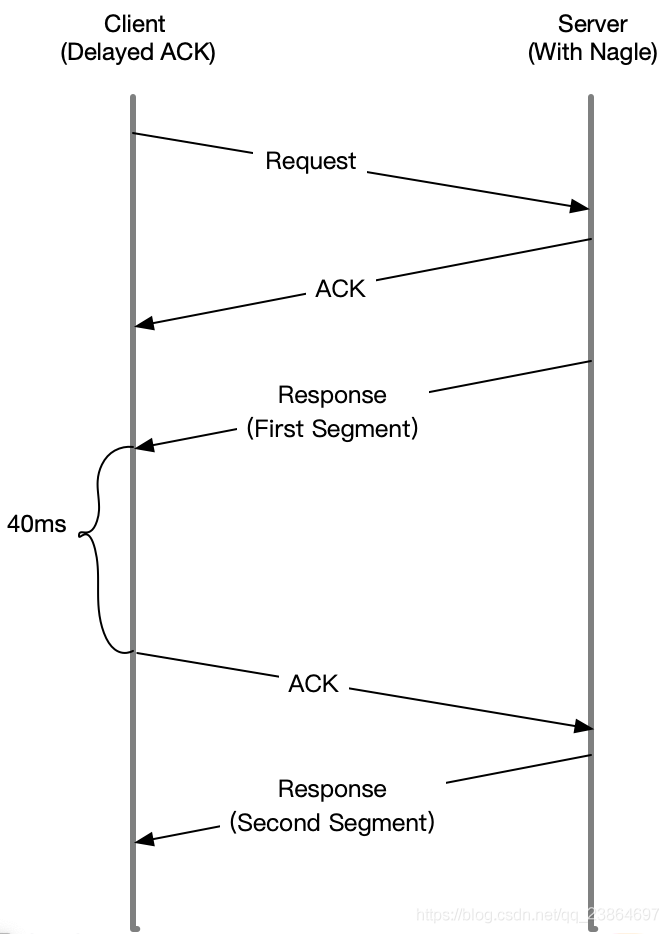
当Sever发送了第一个分组后,由于Client开启了延迟确认,就需要等待40ms后才会回复ACK
同时由于Server端开启了Nagle,而这时还没收到第一个分组的ACK,Server也会 在这里一直等着
直到40ms超时后,Client才会回复ACK,然后Server才会继续发送第二个分组既然可能是Nagle的问题,那该怎么知道,案例Nginx有没有开启Nagle呢?
查询tcp的文档就会知道,只有设置了TCP_NODELAY后,Nagle算法才会禁用
所以只需要查看Nginx的tcp_nodelay选项就可以了
-
终端一中,执行下面的命令,查看案例Nginx的配置
root@alnk:~# docker exec nginx cat /etc/nginx/nginx.conf | grep tcp_nodelay tcp_nodelay off; ## # 果然看到案例Nginx的tcp_nodelay是关闭的,将其设置为on ,应该就可以解决了 ## # 改完后问题是否就解决了呢?自然需要验证一下 # 修改后的应用已经打包到了Docker镜像中,在终端一中执行下面的命令,就可以启动它 # 删除案例应用 root@alnk:~# docker rm -f nginx # 启动优化后的应用 root@alnk:~# docker run --name nginx --network=host -itd feisky/nginx:nodelay -
终端二,重新执行wrk测试延迟
root@alnk:~# wrk --latency -c 100 -t 2 --timeout 2 http://124.71.83.217:8080/ Running 10s test @ http://192.168.0.30:8080/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 9.58ms 14.98ms 350.08ms 97.91% Req/Sec 6.22k 282.13 6.93k 68.50% Latency Distribution 50% 7.78ms 75% 8.20ms 90% 9.02ms 99% 73.14ms 123990 requests in 10.01s, 100.50MB read Requests/sec: 12384.04 Transfer/sec: 10.04MB ## # 果然现在延迟已经缩短成了9ms,跟测试的官方Nginx镜像是一样的 # Nginx默认就是开启tcp_nodelay的 -
终端一,停止案例
root@alnk:~# docker rm -f nginx good
小结
今天学习了网络延迟增大后的分析方法
网络延迟是最核心的网络性能指标
由于网络传输、网络包处理等各种因素的影响,网络延迟不可避免
但过大的网络延迟,会直接影响用户的体验
所以在发现网络延迟增大后,可以用traceroute、hping3、tcpdump、Wireshark、 strace等多种工具
来定位网络中的潜在问题
- 使用hping3以及wrk等工具,确认单次请求和并发请求情况的网络延迟是否正常
- 使用traceroute,确认路由是否正确,并查看路由中每一跳网关的延迟
- 使用tcpdump和Wireshark,确认网络包的收发是否正常
- 使用strace等,观察应用程序对网络套接字的调用情况是否正常
这样就可以依次从路由、网络包的收发、再到应用程序等,逐层排查,直到定位问题根源

