
13-答疑篇:LinuxCPU性能优化答疑
问题1:性能工具版本太低,导致指标不全
[02-基础篇:到底应该怎么理解“平均负载”]
pidstat命令没有%wait列
>>>:
使用CentOS的普遍碰到的问题
pidstat输出里有一个%wait指标,代表进程等待CPU的时间百分比
这是systat 11.5.5版本才引入的新指标,旧版本没有这一项
而CentOS软件库里的sysstat版本刚好比这个低,所以没有这项指标
问题2:使用stress命令,无法模拟iowait高的场景
[02-基础篇:到底应该怎么理解“平均负载”]
使用stress无法模拟iowait升高,但是却看到了sys升高
>>>:
这是因为案例中的stress -i参数,它表示通过系统调用sync()来模拟I/O的问题,但这种方法实际上并不可靠
因为sync()的本意是刷新内存缓冲区的数据到磁盘中,以确保同步
如果缓冲区内本来就没多少数据,那读写到磁盘中的数据也就不多,也就没法产生I/O压力
这一点,在使用SSD磁盘的环境中尤为明显,很可能你的iowait总是0
却单纯因为大量的系统调用,导致了系统CPU使用率sys升高
推荐使用stress-ng来代替stress
可以运行下面的命令,来模拟 iowait 的问题
# -i 的含义还是调用 sync,而 —hdd 则表示读写临时文件
stress-ng -i 1 --hdd 1 --timeout 600
问题3:无法模拟出RES中断的问题
[04-基础篇:经常说的CPU上下文切换是什么意思?(下)]
这个问题是说,即使运行了大量的线程,也无法模拟出重调度中断RES升高的问题
>>>:
重调度中断是调度器用来分散任务到不同CPU的机制,也就是可以唤醒空闲状态的CPU
来调度新任务运行,而这通常借助处理器间中断(Inter-Processor Interrupts,IPI)来实现
所以,这个中断在单核(只有一个逻辑CPU)的机器上当然就没有意义了,因为压根儿就不会发生重调度的情况
上下文切换的问题依然存在,cs(context switch)从几百增加到十几万
同时sysbench线程的自愿上下文切换和非自愿上下文切换也都会大幅上升
特别是非自愿上下文切换,会上升到十几万
根据非自愿上下文的含义,我们都知道,这是过多的线程在争抢CPU
其实这个结论也可以从另一个角度获得
比如,可以在pidstat的选项中,加入-u和-t参数,输出线程的CPU使用情况,会看到下面的界面:
# pidstat -u -t 1
14:24:03 UID TGID TID %usr %system %guest %wait %CPU CPU Com
14:24:04 0 - 2472 0.99 8.91 0.00 77.23 9.90 0 |__stress
14:24:04 0 - 2473 0.99 8.91 0.00 68.32 9.90 0 |__stress
14:24:04 0 - 2474 0.99 7.92 0.00 75.25 8.91 0 |__stress
14:24:04 0 - 2475 2.97 6.93 0.00 70.30 9.90 0 |__stress
14:24:04 0 - 2476 2.97 6.93 0.00 68.32 9.90 0 |__stress
#
从这个pidstat的输出界面,发现每个stress线程的%wait高达70%,而CPU使用率只有不到10%
stress线程大部分时间都消耗在了等待CPU上,这也表明,确实是过多的线程在争抢CPU
###
pidstat中的%wait跟top中的iowait%(缩写为 wa)对比,其实这是没有意义的
因为它们是完全不相关的两个指标
pidstat中,%wait表示进程等待CPU的时间百分比
top中 ,iowait%则表示等待I/O的CPU时间百分比
等待CPU的进程已经在CPU的就绪队列中,处于运行状态
而等待I/O的进程则处于不可中断状态
问题4:无法模拟出I/O性能瓶颈,以及I/O压力过大的问题
[07-案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(上)]
在I/O瓶颈案例中,除了模拟不成功的,还有更多的是案例I/O压力过大
导致自己的机器出各种问题,甚至连系统都没响应了?
>>>:
之所以这样,其实还是因为每个人的机器配置不同,既包括了CPU和内存配置的不同,更是因为磁盘的巨大差异
比如,机械磁盘(HDD)、低端固态磁盘(SSD)与高端固态磁盘相比,性能差异可能达到数倍到数十倍
可以在案例中增加一个参数指定块设备
-d 设置要读取的磁盘,默认前缀为 /dev/sd 或者 /dev/xvd 的磁盘
-s 设置每次读取的数据量大小,单位为字节,默认为 67108864(也就是 64MB)
-c 设置每个子进程读取的次数,默认为 20 次,也就是说,读取 20*64MB 数据后,子进程退出
举例
#github地址
https://github.com/feiskyer/linux-perf-examples/tree/master/high-iowait-process
#docker命令
docker run --privileged --name=app -itd feisky/app:iowait /app -d /dev/sdb -s 67108864 -c 20
#查看日志
docker logs app
Reading data from disk /dev/sdb with buffer size 67108864 and count 20
问题5:性能工具(如vmstat)输出中,第一行数据跟其他行差别巨大
[04-基础篇:经常说的CPU上下文切换是什么意思?(下)]
在执行vmstat时,第一行数据跟其他行相比较,数值相差特别大
>>>:
查命令手册
运行man vmstat命令,可以在手册中发现下面这句话
The first report produced gives averages since the last reboot. Additional reports give
pling period of length delay. The process and memory reports are instantaneous in eithe
#第一行数据是系统启动以来的平均值,其他行才是你在运行vmstat命令时,设置的间隔时间的平均值
#另外,进程和内存的报告内容都是即时数值
问题6:使用perf工具时,看到的是16进制地址而不是函数名
[05-基础篇:某个应用的CPU使用率居然达到100%,我该怎么办?]
在CentOS系统中,使用perf工具看不到函数名,只能看到一些16进制格式的函数地址
>>> :
其实,只要观察一下perf界面最下面的那一行,就会发现一个警告信息
Failed to open /opt/bitnami/php/lib/php/extensions/opcache.so
这说明,perf找不到待分析进程依赖的库,实际上这个案例中有很多依赖库都找不到
perf工具本身只在最后一行显示警告信息,所以只能看到这一条警告
其实也是在分析Docker容器应用时,经常碰到的一个问题,因为容器应用依赖的库都在镜像里面
# 解决办法
在容器外面把分析纪录保存下来,再去容器里查看结果,这样,库和符号的路径也就都对了
现在宿主机运行perf record -g -p < pid>,执行一会儿(比如15秒)后,按Ctrl+C停止
然后,把生成的perf.data文件,拷贝到容器里面来分析
docker cp perf.data phpfpm:/tmp
docker exec -i -t phpfpm bash
接下来,在容器的bash中继续运行下面的命令,安装perf并使用perf report查看报告
cd /tmp/
apt-get update && apt-get install -y linux-tools linux-perf procps
perf_4.9 report
#注意
首先是perf工具的版本问题
在最后一步中,我们运行的工具是容器内部安装的版本perf_4.9,而不是普通的perf命令
因为,perf命令实际上是一个软连接,会跟内核的版本进行匹配
但镜像里安装的perf版本跟虚拟机的内核版本有可能并不一致
问题7:为什么perf的报告中,很多符号都不显示调用栈
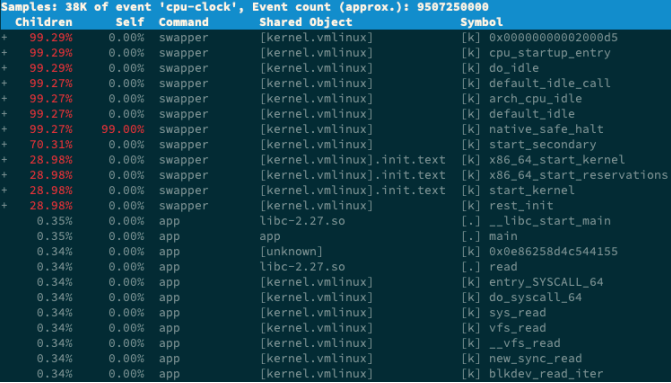
[08-案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(下)]
perf report是一个可视化展示perf.data的工具
这个界面可以清楚看到,perf report的输出中,只有swapper显示了调用栈
其他所有符号都不能查看堆栈情况,包括案例中的app应用
>>>:
执行man perf-report命令,找到-g参数的说明:
-g选项等同于--call-graph
它的参数是后面那些被逗号隔开的选项
意思分别是输出类型、最小阈值、输出限制、排序方法、排序关键词、分支以及值的类型
这里默认的参数是graph,0.5,caller,function,percent
通过手册中对threshold的说明,当一个事件发生比例高于这个阈值时,它的调用栈才会显示出来
threshold的默认值为0.5%,也就是说,事件比例超过0.5%时,调用栈才能被显示
再观察案例应用app的事件比例,只有0.34%,低于0.5%,所以看不到app的调用栈就很正常了
这种情况下,需要给perf report设置一个小于0.34%的阈值,就可以看到的调用图了。比如执行下面的命令:
perf report -g graph,0.3
问题8:怎么理解perf report报告
[08-案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(下)]
为啥不一上来就用perf工具解决,还要执行那么多其他工具呢?
在问题7的perf report界面中,swapper高达99%的比例
直觉来说,应该直接观察它才对,为什么没那么做呢?
>>>:
swapper跟SWAP没有任何关系,它只在系统初始化时创建init进程
之后,它就成了一个最低优先级的空闲任务
也就是说,当CPU没有其他任务运行时,就会执行swapper
所以,可以称它为“空闲任务”
在perf report的界面中,展开它的调用栈,会看到,swapper时钟事件都耗费在了do_idle 上,也就是在执行空闲任务
所以,分析案例时,直接忽略了前面这个99%的符号,转而分析后面只有0.3%的app
其实从这里也能理解,为什么一开始不先用perf分析
因为在多任务系统中,次数多的事件,不一定就是性能瓶颈
所以,只观察到一个大数值,并不能说明什么问题
具体有没有瓶颈,还需要你观测多个方面的多个指标,来交叉验证
关于Children和Self的含义
Self是最后一列的符号(可以理解为函数)本身所占比例
Children是这个符号调用的其他符号(可以理解为子函数,包括直接和间接调用)占用的比例之和
很多性能工具确实会对系统性能有一定影响
就拿perf来说,它需要在内核中跟踪内核栈的各种事件,那么不可避免就会带来一定的性能损失
这一点,虽然对大部分应用来说,没有太大影响,但对特定的某些应用(比如那些对时钟周期特别敏感的应用)
可能就是灾难了
使用性能工具时,确实应该考虑工具本身对系统性能的影响
perf 这种动态追踪工具,会给系统带来一定的性能损失
vmstat、pidstat这些直接读取proc文件系统来获取指标的工具,不会带来性能损失
转载请注明出处哟~
https://www.cnblogs.com/lichengguo

