
11-套路篇:如何迅速分析出系统CPU的瓶颈在哪里?
CPU性能指标
cpu常用性能指标
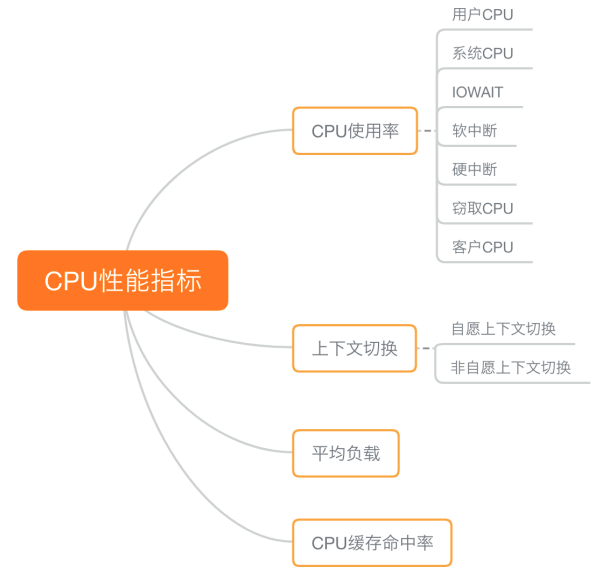
CPU使用率
用户CPU使用率
用户CPU使用率,包括用户态CPU使用率(user)和低优先级用户态CPU使用率(nice)
表示CPU在用户态运行的时间百分比
用户CPU使用率高,通常说明有应用程序比较繁忙
系统CPU使用率
系统CPU使用率,表示CPU在内核态运行的时间百分比(不包括中断)
系统CPU使用率高,说明内核比较繁忙
等待I/O的CPU使用率
等待I/O的CPU使用率,通常也称为iowait
表示等待I/O的时间百分比
iowait高,通常说明系统与硬件设备的I/O交互时间比较长
软中断和硬中断的CPU使用率
软中断和硬中断的CPU使用率
分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比
它们的使用率高,通常说明系统发生了大量的中断
窃取CPU使用率和客户CPU使用率
在虚拟化环境中会用到的窃取CPU使用率(steal)和客户CPU使用率(guest)
分别表示被其他虚拟机占用的CPU时间百分比
和运行客户虚拟机的CPU时间百分比
平均负载
平均负载(Load Average),也就是系统的平均活跃进程数
它反应了系统的整体负载情况,主要包括三个数值,分别指过去1分钟、过去5分钟和过去15分钟的平均负载
理想情况下,平均负载等于逻辑CPU个数,这表示每个CPU都恰好被充分利用
如果平均负载大于逻辑CPU个数,就表示负载比较重了
进程上下文切换
无法获取资源而导致的自愿上下文切换
被系统强制调度导致的非自愿上下文切换
上下文切换,本身是保证Linux正常运行的一项核心功能
但过多的上下文切换,会将原本运行进程的CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上
缩短进程真正运行的时间,成为性能瓶颈
CPU缓存命中率
由于CPU发展的速度远快于内存的发展
CPU的处理速度就比内存的访问速度快得多
这样,CPU在访问内存的时候,免不了要等待内存的响应
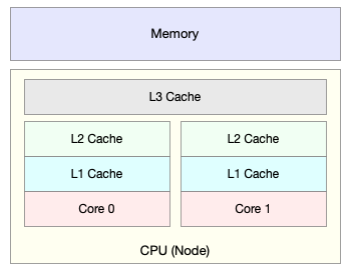
为了协调这两者巨大的性能差距,CPU缓存(通常是多级缓存)就出现了
CPU缓存的速度介于CPU和内存之间,缓存里存的是热点的内存数据
根据不断增长的热点数据
这些缓存按照大小不同分为L1、L2、L3等三级缓存,
其中L1和L2常用在单核中, L3则用在多核中
从L1到L3,三级缓存的大小依次增大
相应的,性能依次降低(当然比内存还是好得多)
而它们的命中率,衡量的是CPU缓存的复用情况,命中率越高,则表示性能越好
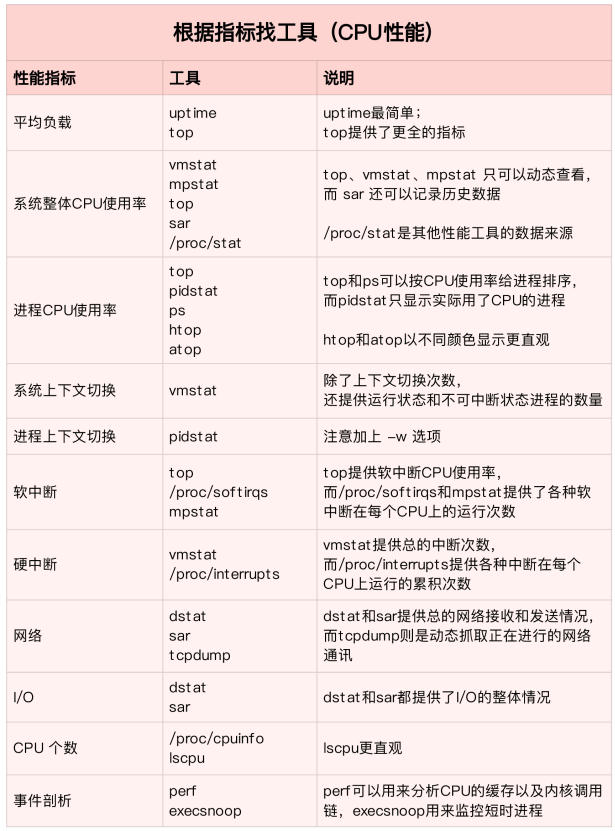
性能分析工具
从CPU的性能指标出发
【从CPU的性能指标出发。也就是说,当要查看某个性能指标时,要清楚知道哪些工具可以做到】
根据不同的性能指标,对提供指标的性能工具进行分类和理解
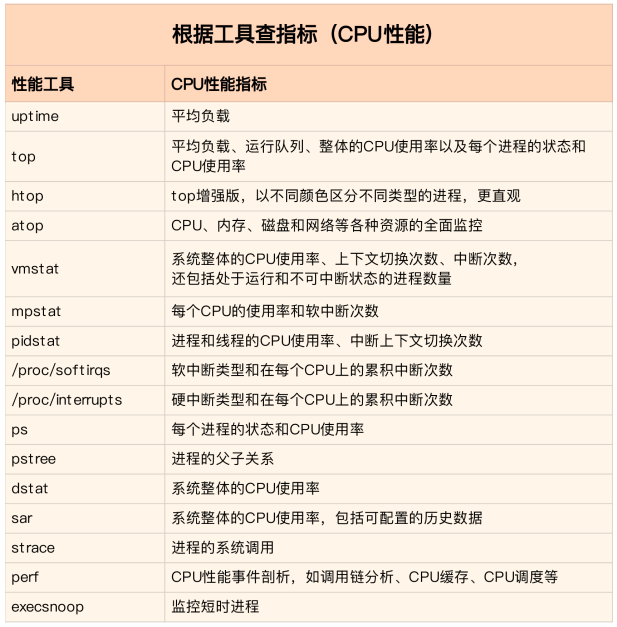
从工具出发
【从工具出发。也就是已经安装了某个工具后,要知道这个工具能提供哪些指标】
这在实际环境特别是生产环境中也是非常重要的
因为很多情况下,并没有权限安装新的工具包,只能最大化地利用好系统中已经安装好的工具
这就需要对它们有足够的了解
如何迅速分析CPU的性能瓶颈
在实际生产环境中,通常希望尽可能快地定位系统的瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题
那有什么方法可以又快又准找出系统瓶颈呢?
虽然CPU的性能指标比较多,但既然都是描述系统的CPU性能,它们就不是完全孤立的,很多指标间都有一定的关联
想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理
举个例子,用户CPU使用率高,应该去排查进程的用户态而不是内核态
因为用户CPU使用率反映的就是用户态的CPU使用情况,而内核态的CPU使用情况只会反映到系统CPU使用率上
为了缩小排查范围,通常会先运行几个支持指标较多的工具,如top、vmstat和pidstat
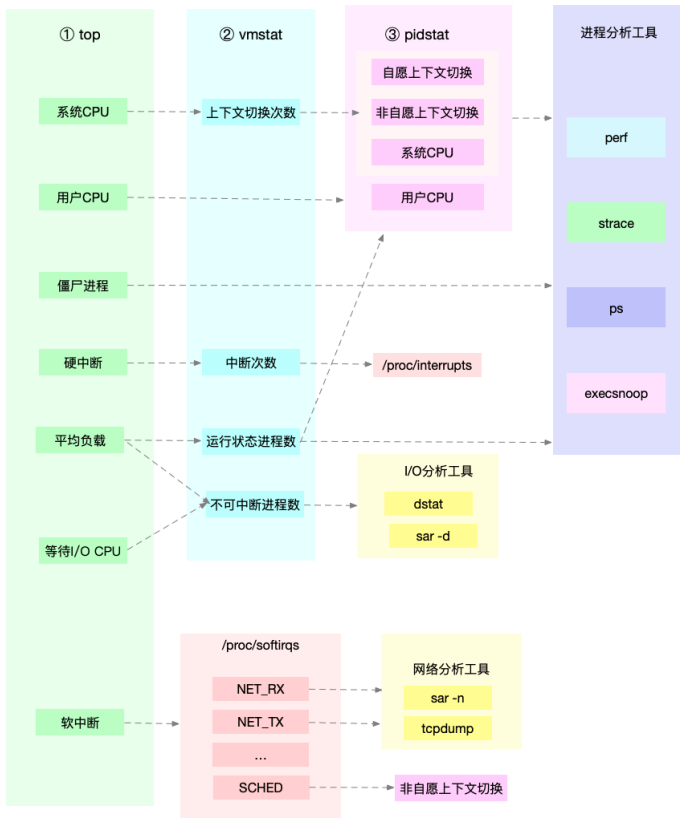
通过这张图可以发现,这三个命令,几乎包含了所有重要的CPU性能指标
1.从top的输出可以得到各种CPU使用率以及僵尸进程和平均负载等信息
2.从vmstat的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数
3.从pidstat的输出可以得到进程的用户CPU使用率、系统CPU使用率、以及自愿上下文切换和非自愿上下文切换情况
例子1
pidstat输出的进程用户CPU使用率升高,会导致top输出的用户CPU使用率升高
所以,当发现top输出的用户CPU使用率有问题时,可以跟pidstat的输出做对比,观察是否是某个进程导致的问题
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为
比如使用strace分析系统调用情况,以及使用perf分析调用链中各级函数的执行情况
例子2
top输出的平均负载升高,可以跟vmstat输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高
如果是不可中断进程数增多了,就需要做I/O的分析,用dstat或sar等工具,进一步分析I/O的情况
如果是运行状态进程数增多了,就需要回到top和pidstat,找出这些处于运行状态的到底是什么进程
然后再用进程分析工具,做进一步分析
例子3
当发现top输出的软中断CPU使用率升高时,可以查看/proc/softirqs文件中各种类型软中断的变化情况
确定到底是哪种软中断出的问题
比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具sar和tcpdump来分析
转载请注明出处哟~
https://www.cnblogs.com/lichengguo
