
06-案例篇:系统的CPU使用率很高,但为啥却找不到高CPU的应用?
引子
上一节讲了CPU使用率是什么,并通过一个案例使用top、vmstat、pidstat等工具
排查高CPU使用率的进程,然后再使用perf top工具定位应用内部函数的问题
似乎感觉高CPU使用率的问题,还是挺容易排查的,那是不是所有CPU使用率高的问题,都可以这么分析呢?
答案是否定的,系统的CPU使用率,不仅包括进程用户态和内核态的运行
还包括中断处理、等待I/O以及内核线程等
所以,当发现系统的CPU使用率很高的时候,不一定能找到相对应的高CPU使用率的进程
案例分析
实验环境
#服务端(192.168.1.6)
配置:2CPU,4G内存,centos7.6_64
预先安装docker、sysstat、perf、ab 等工具(yum install perf httpd-tools sysstat -y)
#客户端(192.168.1.5)
配置:1CPU,2G内存,centos7.6_64
预先安装ab工具(yum install httpd-tools -y)
1.在服务端,第一个终端启动nginx和php应用
[root@local_sa_192-168-1-6 ~]# docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
[root@local_sa_192-168-1-6 ~]# docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp
#查看docker应用是否启动
[root@local_sa_192-168-1-6 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
25b4ee281264 feisky/php-fpm:sp "php-fpm -F --pid /o…" 16 hours ago Up 16 hours
....
2.在客户端,使用curl访问,出现it works证明环境搭建成功
[root@local_deploy_192-168-1-5 ~]# curl http://192.168.1.6:10000/
It works!
3.在客户端,测试一下nginx的性能
# 并发100个请求测试Nginx性能,总共测试1000个请求
[root@local_deploy_192-168-1-5 ~]# ab -c 100 -n 1000 http://192.168.1.6:10000/
......
Requests per second: 147.84 [#/sec] (mean)
Time per request: 676.413 [ms] (mean)
......
# 从ab的输出结果可以看到Nginx能承受的每秒平均请求数,只有147多一点,感觉它的性能有点差
# 那么,到底是哪里出了问题呢?我们再用top和pidstat来观察一下
4.在客户端,将测试的并发请求数改成 5,同时把请求时长设置为10分钟,以便分析
[root@local_deploy_192-168-1-5 ~]# ab -c 5 -t 600 http://192.168.1.6:10000/
5.在服务端,第一个终端运行top命令,观察cpu的使用情况
[root@local_sa_192-168-1-6 ~]# top
......
%Cpu(s): 75.2 us, 20.6 sy, 0.0 ni, 3.0 id, 0.0 wa, 0.0 hi, 1.2 si, 0.0 st
......
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
16841 101 20 0 33092 2180 756 S 4.0 0.1 0:52.43 nginx
25355 bin 20 0 336684 9540 1880 S 3.0 0.2 0:02.05 php-fpm
25360 bin 20 0 336684 9544 1880 S 3.0 0.2 0:02.02 php-fpm
25367 bin 20 0 336684 9532 1868 R 3.0 0.2 0:01.99 php-fpm
25380 bin 20 0 336684 9536 1868 S 3.0 0.2 0:01.99 php-fpm
25372 bin 20 0 336684 9548 1880 R 2.7 0.2 0:01.97 php-fpm
16792 root 20 0 713312 14736 4036 S 1.3 0.4 0:23.24 containerd-shim
3143 root 20 0 1311848 77552 30452 S 1.0 2.0 1:23.38 dockerd
#观察top输出的进程列表可以发现,CPU使用率最高的进程也只不过才4.0%,看起来并不高
#再看系统CPU使用率(%Cpu)这一行,系统的整体CPU使用率是比较高的:用户CPU使用率us已经到了75%,系统CPU为20%,而空闲CPU(id)则只有3%
#明明用户CPU使用率都75%了,可是找不到高CPU使用率的进程
#看来top是不管用了,使用pidstat工具可以查看进程CPU使用情况
6.在服务端,第二个终端运行pidstat命令
# 间隔1秒输出一组数据(按Ctrl+C结束)
[root@local_sa_192-168-1-6 ~]# pidstat 1
Linux 3.10.0-1160.31.1.el7.x86_64 (local_sa_192-168-1-6) 2021年11月11日 _x86_64_ (2 CPU)
10时35分33秒 UID PID %usr %system %guest %wait %CPU CPU Command
10时35分34秒 0 3143 0.00 0.99 0.00 0.00 0.99 1 dockerd
10时35分34秒 0 16792 0.00 1.98 0.00 0.00 1.98 0 containerd-shim
10时35分34秒 101 16841 0.00 2.97 0.00 17.82 2.97 0 nginx
10时35分34秒 1 25355 0.99 2.97 0.00 7.92 3.96 1 php-fpm
10时35分34秒 1 25360 0.00 2.97 0.00 7.92 2.97 1 php-fpm
10时35分34秒 1 25367 0.99 2.97 0.00 11.88 3.96 0 php-fpm
10时35分34秒 1 25372 0.00 2.97 0.00 6.93 2.97 1 php-fpm
10时35分34秒 1 25380 0.99 1.98 0.00 5.94 2.97 0 php-fpm
10时35分34秒 0 31616 0.00 0.99 0.00 0.00 0.99 1 pidstat
平均时间: UID PID %usr %system %guest %wait %CPU CPU Command
平均时间: 0 303 0.00 0.33 0.00 0.00 0.33 - kworker/1:1H
平均时间: 0 3143 0.33 0.66 0.00 0.00 0.99 - dockerd
平均时间: 0 16792 0.33 0.99 0.00 0.00 1.32 - containerd-shim
平均时间: 101 16841 0.66 3.31 0.00 18.21 3.97 - nginx
平均时间: 0 16893 0.33 0.00 0.00 0.00 0.33 - containerd-shim
平均时间: 1 25355 0.66 2.32 0.00 8.94 2.98 - php-fpm
平均时间: 1 25360 0.00 2.65 0.00 7.95 2.65 - php-fpm
平均时间: 1 25367 0.33 2.32 0.00 9.27 2.65 - php-fpm
平均时间: 1 25372 0.00 2.65 0.00 7.62 2.65 - php-fpm
平均时间: 1 25380 0.33 2.32 0.00 7.62 2.65 - php-fpm
平均时间: 0 31616 0.33 0.99 0.00 0.00 1.32 - pidstat
#发现,所有进程的CPU使用率也都不高,最高的Nginx也只有5%,即使所有进程的CPU使用率都加起来,离80%还差得远
#会出现这种情况,很可能是因为前面的分析漏了一些关键信息
#返回去分析top的输出,看看能不能有新发现
7.在服务端,第一个终端运行top命令
[root@local_sa_192-168-1-6 ~]# top
top - 10:39:26 up 2 days, 18:45, 2 users, load average: 1.07, 2.36, 1.70
Tasks: 196 total, 6 running, 189 sleeping, 0 stopped, 0 zombie
%Cpu(s): 75.8 us, 20.3 sy, 0.0 ni, 2.9 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 3880292 total, 860952 free, 584392 used, 2434948 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2907388 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
16841 101 20 0 33092 2180 756 S 4.0 0.1 1:02.98 nginx
14974 bin 20 0 336684 9536 1876 S 3.0 0.2 0:00.20 php-fpm
14987 bin 20 0 336684 9536 1872 S 3.0 0.2 0:00.19 php-fpm
14979 bin 20 0 336684 9536 1872 S 2.7 0.2 0:00.19 php-fpm
14996 bin 20 0 336684 9536 1868 S 2.7 0.2 0:00.19 php-fpm
14998 bin 20 0 336684 9536 1868 R 2.7 0.2 0:00.19 php-fpm
#Tasks这一行看起来有点奇怪,就绪队列中居然有6 Running状态的进程(6 running)
ab测试的参数,并发请求数是5。
再看进程列表里,php-fpm的数量也是5,再加上Nginx,好像同时有6个进程也并不奇怪
但真的是这样吗?
再仔细看进程列表,这次主要看Running(R)状态的进程
发现,Nginx和所有的php-fpm都处于Sleep(S)状态
# 对top命令进行排序,选择进程状态排序。
#1. shift + f
#2.然后选择这一行 S = Process Status 按s键设置确认,然后按q键退回到主界面
#3.在主界面就会以进程状态排序,按R倒序
[root@local_sa_192-168-1-6 ~]# top
op - 10:45:29 up 2 days, 18:51, 2 users, load average: 3.48, 4.38, 2.93
Tasks: 201 total, 6 running, 195 sleeping, 0 stopped, 0 zombie
%Cpu(s): 75.9 us, 19.5 sy, 0.0 ni, 3.5 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 3880292 total, 798932 free, 583840 used, 2497520 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2882684 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7364 bin 20 0 8172 1120 104 R 0.0 0.0 0:00.00 stress
7365 bin 20 0 8168 860 104 R 0.0 0.0 0:00.00 stress
7368 bin 20 0 8172 600 104 R 0.0 0.0 0:00.00 stress
7371 bin 20 0 8172 860 104 R 0.0 0.0 0:00.00 stress
7373 bin 20 0 7272 100 0 R 0.0 0.0 0:00.00 stress
# 可以发现,真正处于Running(R)状态的,是几个stress进程。
# 这几个stress进程就比较奇怪了
# 使用pidstat来分析这几个进程
[root@local_sa_192-168-1-6 ~]# pidstat -p 7364
Linux 3.10.0-1160.31.1.el7.x86_64 (local_sa_192-168-1-6) 2021年11月11日 _x86_64_ (2 CPU)
10时47分55秒 UID PID %usr %system %guest %wait %CPU CPU Command
#居然没有任何输出。
#难道是pidstat命令出问题了吗?
#在怀疑性能工具出问题前,最好还是先用其他工具交叉确认一下
#ps应该是最简单易用的
#在终端里运行下面的命令,看看7364进程的状态
[root@local_sa_192-168-1-6 ~]# ps aux|grep 7364
root 12794 0.0 0.0 112724 956 pts/1 R+ 10:49 0:00 grep --color=auto 7364
#还是没有输出。
#现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出。
#既然进程都没了,那性能问题应该也跟着没了吧
8.在服务端,第一个终端再次观察top命令
[root@local_sa_192-168-1-6 ~]# top
top - 10:50:11 up 2 days, 18:55, 2 users, load average: 6.54, 5.58, 3.82
Tasks: 196 total, 5 running, 191 sleeping, 0 stopped, 0 zombie
%Cpu(s): 75.8 us, 20.0 sy, 0.0 ni, 3.2 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 3880292 total, 763724 free, 582748 used, 2533820 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2879892 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 R 0.3 0.0 0:14.45 rcu_sched
9306 bin 20 0 7272 100 0 R 0.0 0.0 0:00.00 stress
9307 bin 20 0 8168 96 0 R 0.0 0.0 0:00.00 stress
9310 bin 20 0 7272 96 0 R 0.0 0.0 0:00.00 stress
# 用户CPU使用率还是高达75.8%
# 细看一下top的输出,发现stress进程的PID一直在改变
# 进程的PID在变,这说明什么呢?要么是这些进程在不停地重启,要么就是全新的进程
# 1.第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了
# 2.第二个原因,这些进程都是短时进程,也就是在其他应用内部通过exec调用的外面命令。
# 这些命令一般都只运行很短的时间就会结束,很难用top这种间隔时间比较长的工具发现
要怎么查找一个进程的父进程呢?
pstree
9.在服务端,第二个终端使用pstree命令
# 多运行几次
[root@local_sa_192-168-1-6 ~]# pstree |grep stress
|-containerd-shim-+-php-fpm-+-3*[php-fpm---sh---stress---stress]
[root@local_sa_192-168-1-6 ~]# pstree |grep stress
| | `-2*[php-fpm---sh---stress---stress]
[root@local_sa_192-168-1-6 ~]# pstree |grep stress
|-containerd-shim-+-php-fpm-+-3*[php-fpm---sh---stress---stress]
[root@local_sa_192-168-1-6 ~]# pstree |grep stress
|-containerd-shim-+-php-fpm-+-2*[php-fpm---sh---stress---stress]
#stress是被php-fpm调用的子进程,并且进程数量不止一个(这里是 3 个)
# 找到父进程后,我们能进入app的内部分析了
10.在服务端,第二个终端
# 拷贝源码到本地
[root@local_sa_192-168-1-6 ~]# docker cp phpfpm:/app .
# grep 查找看看是不是有代码在调用stress命令
[root@local_sa_192-168-1-6 ~]# grep stress -r app
app/index.php:// fake I/O with stress (via write()/unlink()).
app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
# 再来看看 app/index.php 的源代码
[root@local_sa_192-168-1-6 ~]# cat app/index.php
<?php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
?>
# 源码里对每个请求都会调用一个stress命令,模拟I/O压力
# 从注释上看,stress会通过write()和unlink()对I/O进程进行压测
# 看来,这应该就是系统CPU使用率升高的根源了
# stress模拟的是I/O压力,而之前在top的输出中看到的,却一直是用户CPU和系统CPU升高,并没见到iowait升高
# 这又是怎么回事呢?
# 从代码中可以看到,给请求加入verbose=1参数后,就可以查看stress的输出
[root@local_sa_192-168-1-6 ~]# curl http://192.168.1.6:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [21931] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [21934] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [21931] (394) <-- worker 21934 returned error 1
[3] => stress: WARN: [21931] (396) now reaping child worker processes
[4] => stress: FAIL: [21931] (400) kill error: No such process
[5] => stress: FAIL: [21931] (451) failed run completed in 0s
)
# 看错误消息mkstemp failed: Permission denied
# 以及failed run completed in 0s
# 原来stress命令并没有成功,它因为权限问题失败退出了
# 看来,我们发现了一个PHP调用外部stress命令的bug没有权限创建临时文件
# 从这里我们可以猜测,正是由于权限错误,大量的stress进程在启动时初始化失败,进而导致用户CPU使用率的升高
# 分析出问题来源,下一步是不是就要开始优化了呢?
# 当然不是!既然只是猜测,那就需要再确认一下,这个猜测到底对不对,是不是真的有大量的stress进程
# 该用什么工具或指标呢?
# perf
11.在服务端,第三个终端
# perf它可以用来分析CPU性能事件,用在这里就很合适
# 运行perf record -g命令 ,并等待一会儿(比如 15 秒)后按 Ctrl+C 退出
# 然后再运行perf report查看报告
### 注意,centos7中由于使用了容器环境,需要把报告拷贝到容器中去分析
# 在宿主机上生成perf.data数据
[root@local_sa_192-168-1-6 ~]# perf recode -g
perf: 'recode' is not a perf-command. See 'perf --help'.
[root@local_sa_192-168-1-6 ~]# perf record -g
^C[ perf record: Woken up 30 times to write data ]
[ perf record: Captured and wrote 8.558 MB perf.data (62670 samples) ]
# 拷贝数据到容器中
[root@local_sa_192-168-1-6 ~]# docker cp perf.data phpfpm:/tmp
[root@local_sa_192-168-1-6 ~]# docker exec -i -t phpfpm bash
root@2e2f18f5ba75:/app# cd /tmp/
root@2e2f18f5ba75:/tmp# apt-get update && apt-get install -y linux-perf linux-tools procps
root@2e2f18f5ba75:/tmp# chown root.root perf.data
root@2e2f18f5ba75:/tmp# perf_4.9 report
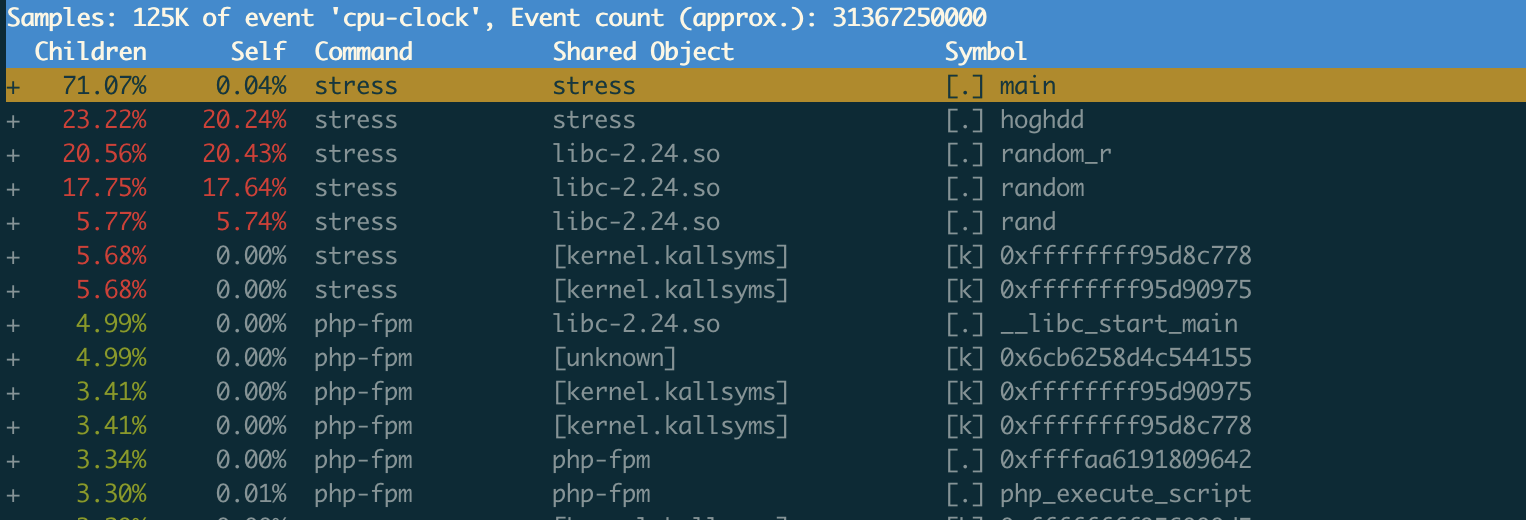
stress占了所有CPU时钟事件的71%,看来它的确就是CPU使用率升高的元凶了
随后的优化就很简单了,只要修复权限问题,并减少或删除stress的调用,就可以减轻系统的CPU压力
当然,实际生产环境中的问题一般都要比这个案例复杂
在找到触发瓶颈的命令行后,却可能发现,这个外部命令的调用过程是应用核心逻辑的一部分,并不能轻易减少或者删除
这时,就得继续排查,为什么被调用的命令,会导致CPU使用率升高或I/O升高等问题
execsnoop工具
在这个案例中,使用了top、pidstat、pstree等工具分析了系统CPU使用率高的问题
并发现CPU升高是短时进程stress导致的,但是整个分析过程还是比较复杂的
对于这类问题,有没有更好的方法监控呢?
execsnoop就是一个专为短时进程设计的工具
它通过ftrace实时监控进程的exec()行为,并输出短时进程的基本信息
包括进程PID、父进程 PID、命令行参数以及执行的结果
execsnoop所用的ftrace是一种常用的动态追踪技术,一般用于分析Linux内核的运行时行为
execsnoop安装(其实就是一个shell脚本)
下载链接:https://alnk-blog-pictures.oss-cn-shenzhen.aliyuncs.com/blog-pictures/execsnoop
脚本直接放到 /usr/bin/ 目录下即可
# 按Ctrl+C结束
[root@local_sa_192-168-1-6 ~]# execsnoop
Tracing exec()s. Ctrl-C to end.
Instrumenting sys_execve
PID PPID ARGS
13665 13642 gawk -v o=1 -v opt_name=0 -v name= -v opt_duration=0 [...]
13666 13663 cat -v trace_pipe
13667 5460 sh-13667 [000] d... 242729.963605: execsnoop_sys_execve: (SyS_execve+0x0/0x30)
13668 13667 /usr/local/bin/stress -t 1 -d 1
13670 5464 sh-13670 [000] d... 242729.966825: execsnoop_sys_execve: (SyS_execve+0x0/0x30)
13671 5472 sh-13671 [000] d... 242729.967127: execsnoop_sys_execve: (SyS_execve+0x0/0x30)
13672 13671 /usr/local/bin/stress -t 1 -d 1
13673 13670 /usr/local/bin/stress -t 1 -d 1
......
发现大量stress进程
小结
碰到常规问题无法解释的CPU使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况
1.应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过top等工具也不容易发现
2.应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的CPU
对于这类进程,我们可以用pstree或者execsnoop找到它们的父进程,再从父进程所在的应用入手,排查问题的根源
转载请注明出处哟~
https://www.cnblogs.com/lichengguo
