【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密。这个可能是我做技术研究的思路有关,我开始学习某一套技术总是想着这套技术到底能干什么,只有当我真正理解了这套技术解决了什么问题时候,我后续的学习就能逐步的加快,而学习hdfs时候我就发现,要理解hadoop框架的意义,hdfs和mapreduce是密不可分,所以当我写分布式文件系统时候,总是感觉自己的理解肤浅,今天我开始写mapreduce了,今天写文章时候比上周要进步多,不过到底能不能写好本文了,只有试试再说了。
Mapreduce初析
Mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
我们要学习的就是这个计算模型的运行规则。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
Mapreduce的基础实例
讲解mapreduce运行原理前,首先我们看看mapreduce里的hello world实例WordCount,这个实例在任何一个版本的hadoop安装程序里都会有,大家很容易找到,这里我还是贴出代码,便于我后面的讲解,代码如下:
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package org.apache.hadoop.examples;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }} |
如何运行它,这里不做累述了,大伙可以百度下,网上这方面的资料很多。这里的实例代码是使用新的api,大家可能在很多书籍里看到讲解mapreduce的WordCount实例都是老版本的api,这里我不给出老版本的api,因为老版本的api不太建议使用了,大家做开发最好使用新版本的api,新版本api和旧版本api有区别在哪里:
- 新的api放在:org.apache.hadoop.mapreduce,旧版api放在:org.apache.hadoop.mapred
- 新版api使用虚类,而旧版的使用的是接口,虚类更加利于扩展,这个是一个经验,大家可以好好学习下hadoop的这个经验。
其他还有很多区别,都是说明新版本api的优势,因为我提倡使用新版api,这里就不讲这些,因为没必要再用旧版本,因此这种比较也没啥意义了。
下面我对代码做简单的讲解,大家看到要写一个mapreduce程序,我们的实现一个map函数和reduce函数。我们看看map的方法:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
这里有三个参数,前面两个Object key, Text value就是输入的key和value,第三个参数Context context这是可以记录输入的key和value,例如:context.write(word, one);此外context还会记录map运算的状态。
对于reduce函数的方法:
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
reduce函数的输入也是一个key/value的形式,不过它的value是一个迭代器的形式Iterable<IntWritable> values,也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。
至于计算的逻辑就是程序员自己去实现了。
下面就是main函数的调用了,这个我要详细讲述下,首先是:
Configuration conf = new Configuration();
运行mapreduce程序前都要初始化Configuration,该类主要是读取mapreduce系统配置信息,这些信息包括hdfs还有mapreduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息,有些童鞋不理解为啥要这么做,这个是没有深入思考mapreduce计算框架造成,我们程序员开发mapreduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,其它的工作都是交给mapreduce框架自己操作的,但是至少我们要告诉它怎么操作啊,比如hdfs在哪里啊,mapreduce的jobstracker在哪里啊,而这些信息就在conf包下的配置文件里。
接下来的代码是:
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
If的语句好理解,就是运行WordCount程序时候一定是两个参数,如果不是就会报错退出。至于第一句里的GenericOptionsParser类,它是用来解释常用hadoop命令,并根据需要为Configuration对象设置相应的值,其实平时开发里我们不太常用它,而是让类实现Tool接口,然后再main函数里使用ToolRunner运行程序,而ToolRunner内部会调用GenericOptionsParser。
接下来的代码是:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不累述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,这里多了个第四行,这个是装载Combiner类,这个我后面讲mapreduce运行机制时候会讲述,其实本例去掉第四行也没有关系,但是使用了第四行理论上运行效率会更好。
接下来的代码:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
这个是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
最后的代码是:
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
第一行就是构建输入的数据文件,第二行是构建输出的数据文件,最后一行如果job运行成功了,我们的程序就会正常退出。FileInputFormat和FileOutputFormat是很有学问的,我会在下面的mapreduce运行机制里讲解到它们。
好了,mapreduce里的hello word程序讲解完毕,我这个讲解是从新办api进行,这套讲解在网络上还是比较少的,应该很具有代表性的。
Mapreduce运行机制
下面我要讲讲mapreduce的运行机制了,前不久我为公司出了一套hadoop面试题,里面就问道了mapreduce运行机制,出题时候我发现这个问题我自己似乎也将不太清楚,因此最近几天恶补了下,希望在本文里能说清楚这个问题。
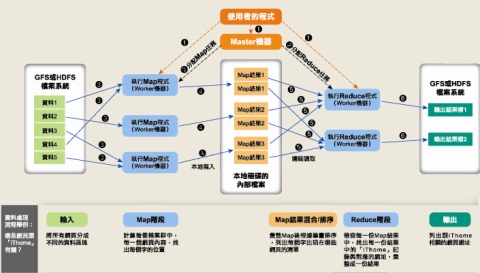
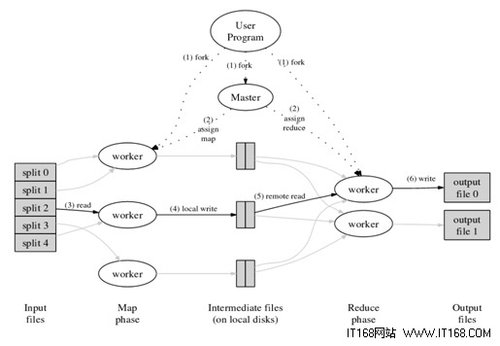
下面我贴出几张图,这些图都是我在百度图片里找到的比较好的图片:
图片一:
图片二:
图片三:
图片四:
图片五:
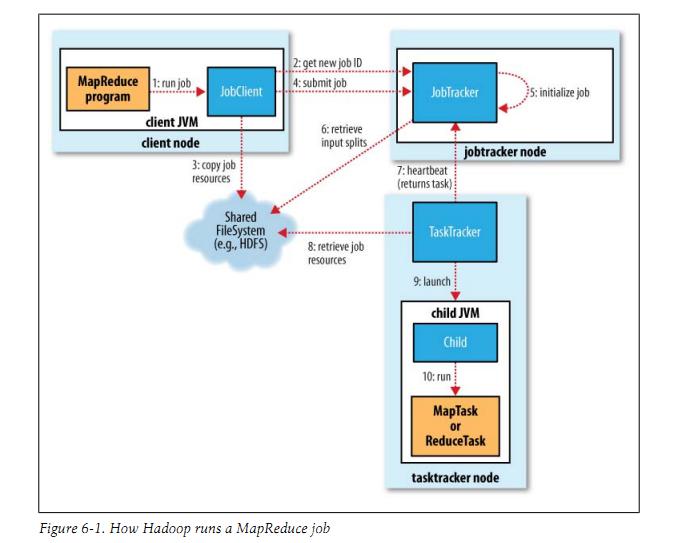
图片六:
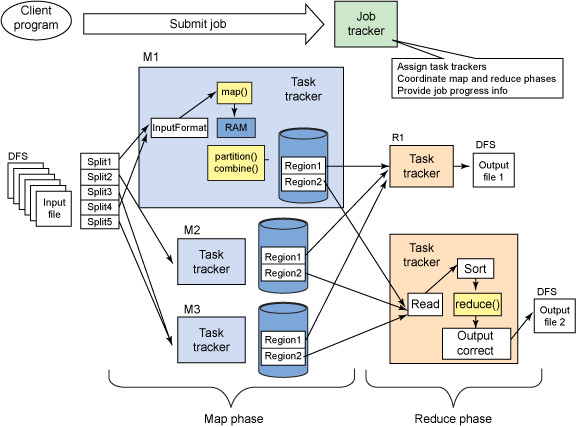
我现在学习技术很喜欢看图,每次有了新理解就会去看看图,每次都会有新的发现。
谈mapreduce运行机制,可以从很多不同的角度来描述,比如说从mapreduce运行流程来讲解,也可以从计算模型的逻辑流程来进行讲解,也许有些深入理解了mapreduce运行机制还会从更好的角度来描述,但是将mapreduce运行机制有些东西是避免不了的,就是一个个参入的实例对象,一个就是计算模型的逻辑定义阶段,我这里讲解不从什么流程出发,就从这些一个个牵涉的对象,不管是物理实体还是逻辑实体。
首先讲讲物理实体,参入mapreduce作业执行涉及4个独立的实体:
- 客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
- JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
- TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障,我会在后面的mapreduce的相关问题里讲到这个问题的)
- Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
那么mapreduce到底是如何运行的呢?
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值,接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。
下面我从逻辑实体的角度讲解mapreduce运行机制,这些按照时间顺序包括:输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。
- 输入分片(input split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
- map阶段:就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;
- combiner阶段:combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
- shuffle阶段:将map的输出作为reduce的输入的过程就是shuffle了,这个是mapreduce优化的重点地方。这里我不讲怎么优化shuffle阶段,讲讲shuffle阶段的原理,因为大部分的书籍里都没讲清楚shuffle阶段。Shuffle一开始就是map阶段做输出操作,一般mapreduce计算的都是海量数据,map输出时候不可能把所有文件都放到内存操作,因此map写入磁盘的过程十分的复杂,更何况map输出时候要对结果进行排序,内存开销是很大的,map在做输出时候会在内存里开启一个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80(这个大小和阀值都是可以在配置文件里进行配置的),同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作,前面我讲到写入磁盘前会有个排序操作,这个是在写入磁盘操作时候进行,不是在写入内存时候进行的,如果我们定义了combiner函数,那么排序前还会执行combiner操作。每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。这个过程里还会有一个Partitioner操作,对于这个操作很多人都很迷糊,其实Partitioner操作和map阶段的输入分片(Input split)很像,一个Partitioner对应一个reduce作业,如果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片,这个程序员可以编程控制,主要是根据实际key和value的值,根据实际业务类型或者为了更好的reduce负载均衡要求进行,这是提高reduce效率的一个关键所在。到了reduce阶段就是合并map输出文件了,Partitioner会找到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制线程,这些线程默认个数是5个,程序员也可以在配置文件更改复制线程的个数,这个复制过程和map写入磁盘过程类似,也有阀值和内存大小,阀值一样可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算了。
- reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
Mapreduce的相关问题
这里我要谈谈我学习mapreduce思考的一些问题,都是我自己想出解释的问题,但是某些问题到底对不对,就要广大童鞋帮我确认了。
- jobtracker的单点故障:jobtracker和hdfs的namenode一样也存在单点故障,单点故障一直是hadoop被人诟病的大问题,为什么hadoop的做的文件系统和mapreduce计算框架都是高容错的,但是最重要的管理节点的故障机制却如此不好,我认为主要是namenode和jobtracker在实际运行中都是在内存操作,而做到内存的容错就比较复杂了,只有当内存数据被持久化后容错才好做,namenode和jobtracker都可以备份自己持久化的文件,但是这个持久化都会有延迟,因此真的出故障,任然不能整体恢复,另外hadoop框架里包含zookeeper框架,zookeeper可以结合jobtracker,用几台机器同时部署jobtracker,保证一台出故障,有一台马上能补充上,不过这种方式也没法恢复正在跑的mapreduce任务。
- 做mapreduce计算时候,输出一般是一个文件夹,而且该文件夹是不能存在,我在出面试题时候提到了这个问题,而且这个检查做的很早,当我们提交job时候就会进行,mapreduce之所以这么设计是保证数据可靠性,如果输出目录存在reduce就搞不清楚你到底是要追加还是覆盖,不管是追加和覆盖操作都会有可能导致最终结果出问题,mapreduce是做海量数据计算,一个生产计算的成本很高,例如一个job完全执行完可能要几个小时,因此一切影响错误的情况mapreduce是零容忍的。
- Mapreduce还有一个InputFormat和OutputFormat,我们在编写map函数时候发现map方法的参数是之间操作行数据,没有牵涉到InputFormat,这些事情在我们new Path时候mapreduce计算框架帮我们做好了,而OutputFormat也是reduce帮我们做好了,我们使用什么样的输入文件,就要调用什么样的InputFormat,InputFormat是和我们输入的文件类型相关的,mapreduce里常用的InputFormat有FileInputFormat普通文本文件,SequenceFileInputFormat是指hadoop的序列化文件,另外还有KeyValueTextInputFormat。OutputFormat就是我们想最终存储到hdfs系统上的文件格式了,这个根据你需要定义了,hadoop有支持很多文件格式,这里不一一列举,想知道百度下就看到了。
好了,文章写完了,呵呵,这篇我自己感觉写的不错,是目前hadoop系列文章里写的最好的,我后面会再接再厉的。加油!!!
====================================
自己动手实践 WordCount
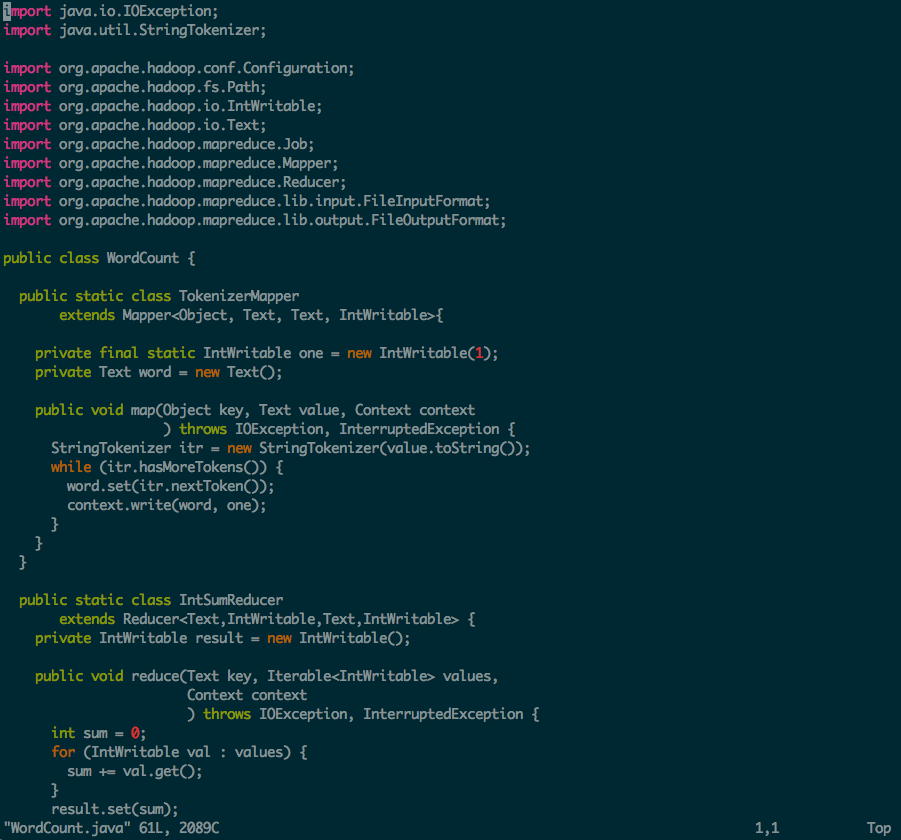
1. 在Hadoop机器上面新建WordCount.java文件
Source Code
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Usage
Assuming environment variables are set as follows:
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar

2. 对WordCount.java 文件进行编译
Compile WordCount.java and create a jar:
$ bin/hadoop com.sun.tools.javac.Main WordCount.java $ jar cf wc.jar WordCount*.class
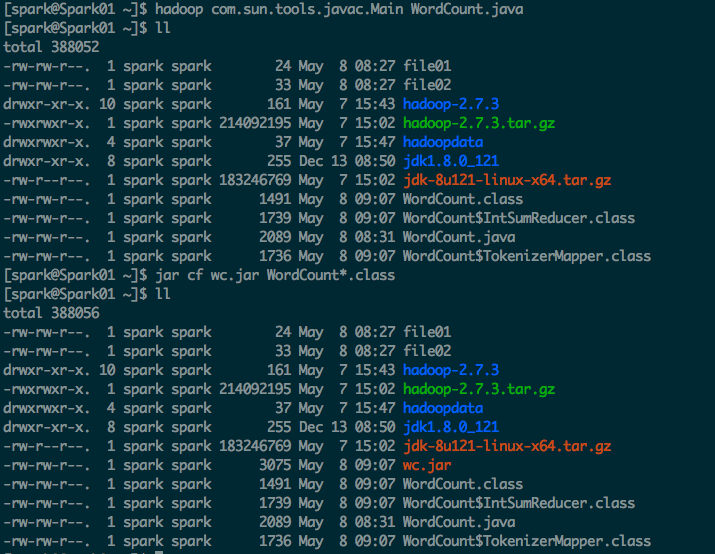
Assuming that:
- /user/joe/wordcount/input - input directory in HDFS
- /user/joe/wordcount/output - output directory in HDFS
Sample text-files as input:
$ bin/hadoop fs -ls /user/joe/wordcount/input/ /user/joe/wordcount/input/file01 /user/joe/wordcount/input/file02 $ bin/hadoop fs -cat /user/joe/wordcount/input/file01 Hello World Bye World $ bin/hadoop fs -cat /user/joe/wordcount/input/file02 Hello Hadoop Goodbye Hadoop
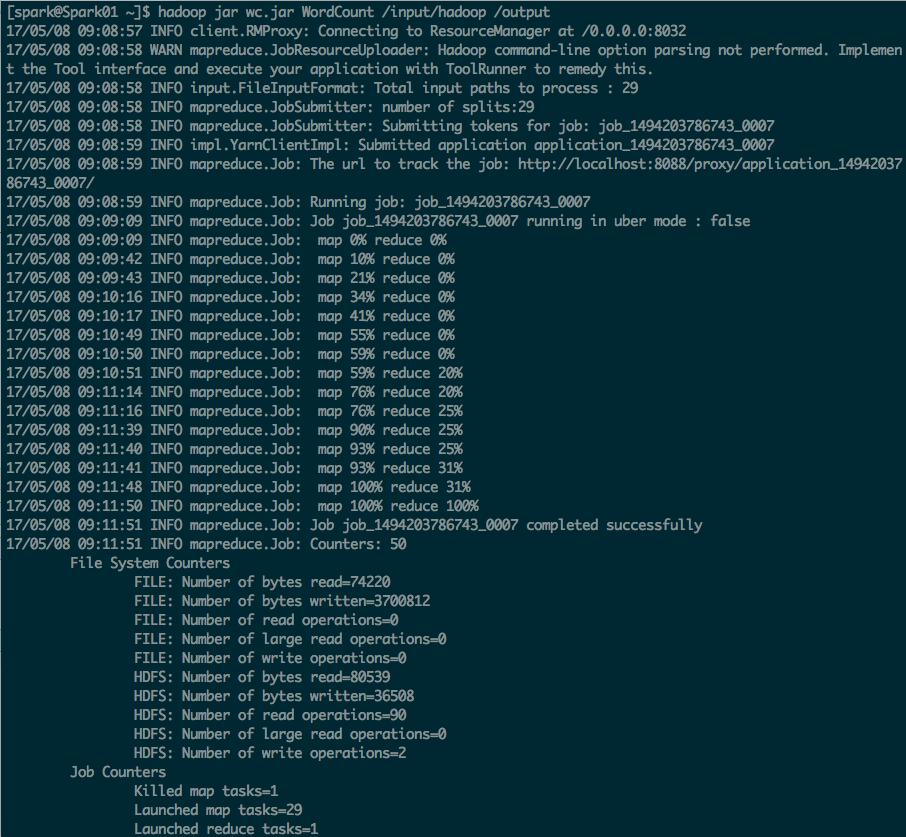
3. 运行WordCount 程序
Run the application:
$ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
Output:
$ bin/hadoop fs -cat /user/joe/wordcount/output/part-r-00000` Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2`
hadoop jar wc.jar WordCount /input/hadoop /output
查看输出文件
[spark@Spark01 ~]$ hadoop fs -cat /output/part-r-00000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号