
SQL Server 根据一个表数据修改另外一个表数据
今天在写代码的时候发现一个有趣的问题,同时也暴露了之前写的代码有问题,还好之前没有出现重复的情况,及时发现了这个问题,及时改了回来,不然就GG了
下面先上代码,再给大家解说一下


CREATE TABLE #t1 (id INT,value int) CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value) VALUES( 1, 1 ), ( 2, 2 ), ( 3, 3 ), ( 4, 4 ) INSERT #t2(id,value) VALUES( 1, 1 ), ( 1, 2 ), ( 1, 3 ) SELECT * FROM #t1 SELECT * FROM #t2 --; --WITH t1 AS( --SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN #t2 t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1 DROP TABLE #t2
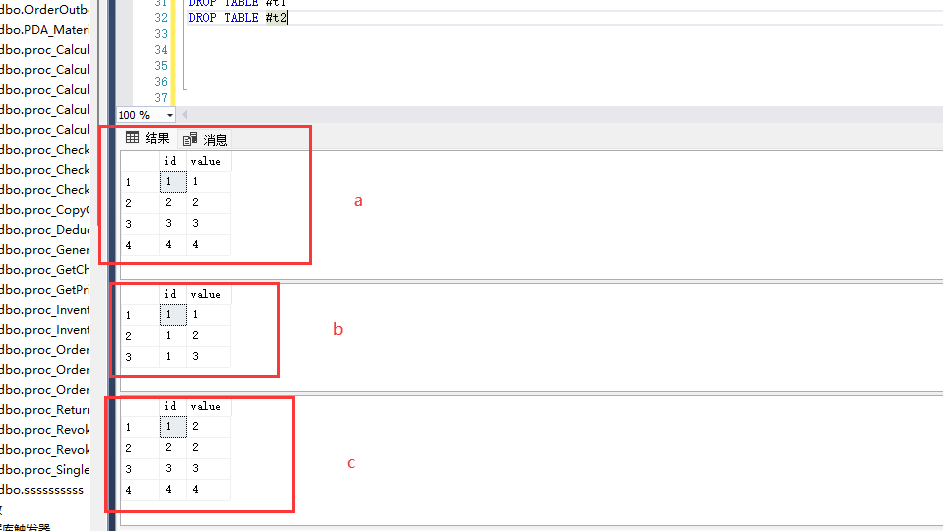
其实当你看代码就知道,我想根据b表修改a表,按我们的思维,a表id=1的有一条记录,b表id=1的有三条,
这样级联修改以后应该c结果中id=1的值应该是7才对,但是只有2,说明是a表里面的1加了b表里面的value=1 的第一条记录,我在SQL交流群里面问了一下
有人说a表只有一条记录,b表有三条记录,只匹配了第一条,然后我就试了一下,在a表中造了三条记录
CREATE TABLE #t1 (id INT,value int) CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value) VALUES( 1, 1 ), ( 1, 2 ), ( 1, 3 ), ( 4, 4 ) INSERT #t2(id,value) VALUES( 1, 1 ), ( 1, 2 ), ( 1, 3 ) SELECT * FROM #t1 SELECT * FROM #t2 --; --WITH t1 AS( --SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN #t2 t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1 DROP TABLE #t2
然后出现一件很神奇的事
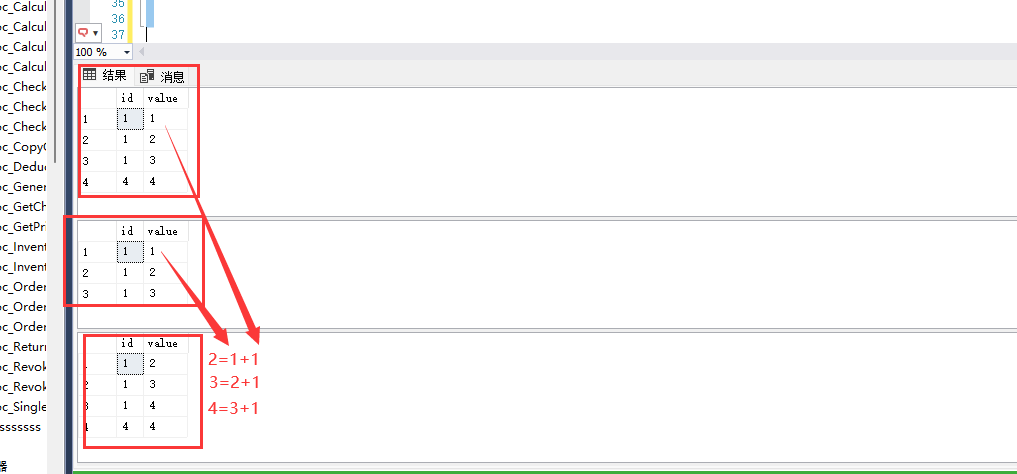
可以看见,即使a表有三条,匹配的b表依旧只有是第一条
所以及时看见这个坑,阿西吧,又是踩坑的一天,还好检查代码发现了问题
经过修正后的代码,有三种解决方案,第一子查询汇总修改,第二用 CTE(CTE表示公用表表达式,是一个临时命名结果集,始终返回结果集)语法解决,第三种使用循环,
具体使用看实际情况,因为我的级联修改是在循环外,所以就用前两种,我一般使用CTE 语法修改,这个语法用法还是很普遍很爽的,但是使用有限制,脱离主体只能使用一次,
如果你要用多次,建议使用临时表或者表变量(个人推荐表变量,具体使用还是要看情况,差异还是挺大的,有时间我为大家写一篇这三种的异同的随便)
不哔哔,直接上代码
CREATE TABLE #t1 (id INT,value int) CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value) VALUES( 1, 1 ), ( 2, 2 ), ( 3, 3 ), ( 4, 4 ) INSERT #t2(id,value) VALUES( 1, 1 ), ( 1, 2 ), ( 1, 3 ) SELECT * FROM #t1 SELECT * FROM #t2 --; --WITH t1 AS( --SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN (SELECT id,SUM(value) value FROM #t2 WHERE #t2.id=id GROUP BY id)t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1 DROP TABLE #t2
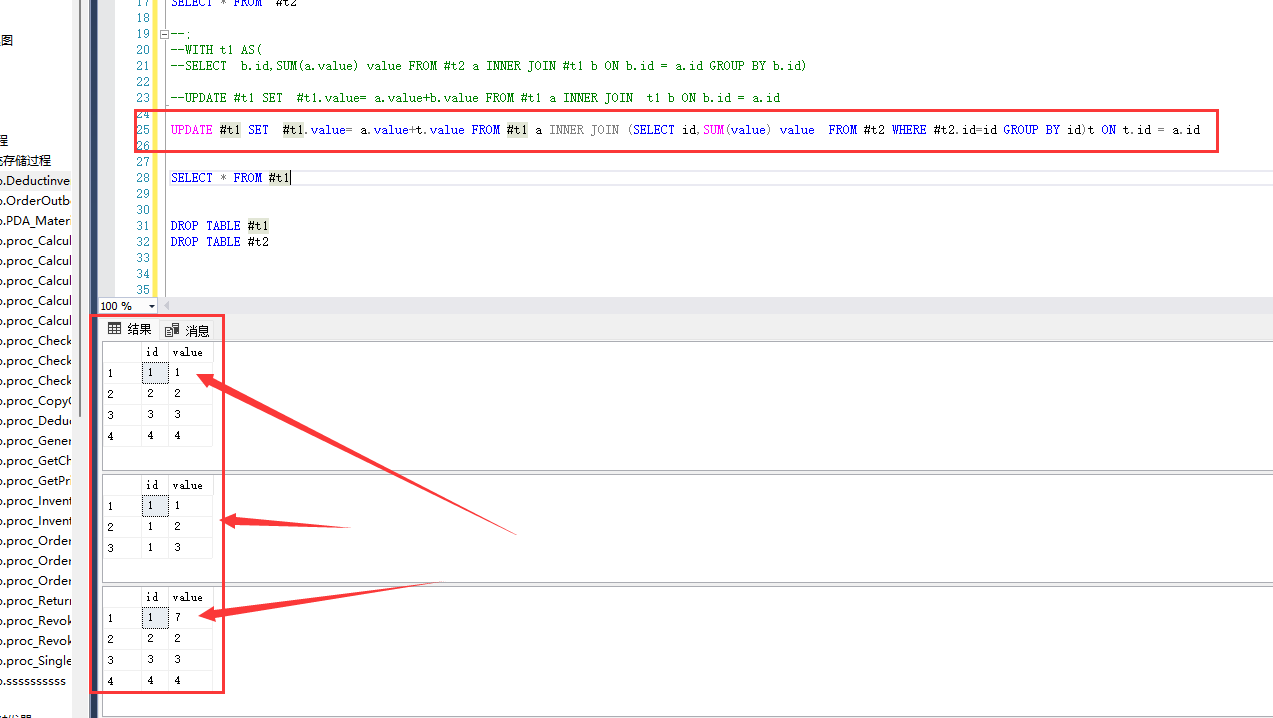
这就舒服了,终于实现了我要的效果,这是使用子查询的
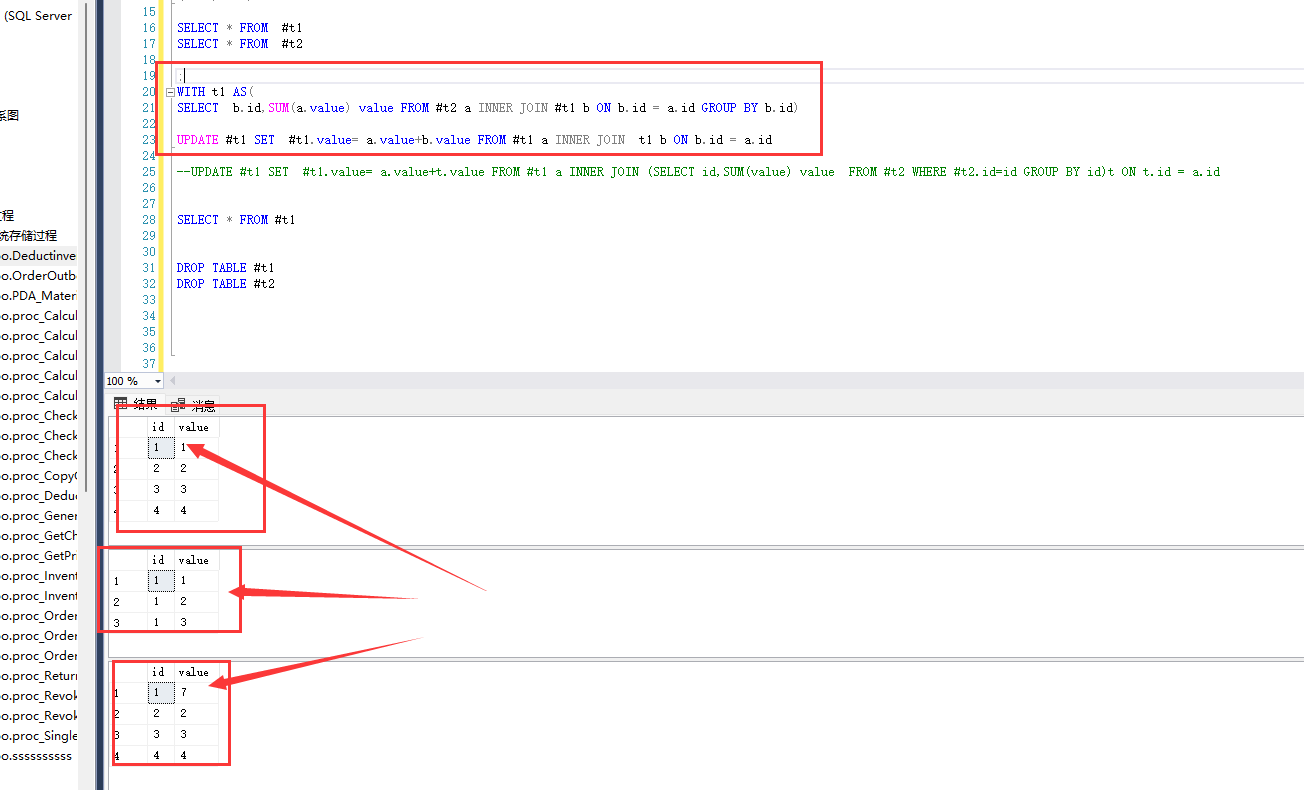
这就比较爽了,至于循环就自己下去试一下,可以用游标,也可以用while循环
游标直接修改就行了,用while循环,要先给参考表一个行号,可以用 ROW_NUMBER() 实现
具体看自己,今天分享结束了,想想就后怕,这么大个坑,出问题就GG了,今天分享出来,也希望给大家一个参考
本文来自博客园,作者:酒笙匿清栀,转载请注明原文链接:https://www.cnblogs.com/libo962464/p/16813698.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号