Sql Server系列:事务完整性
1、事务的基本概念
事务是一系列的任务组成的逻辑工作单元,这个逻辑工作单元中的所有任务必须作为一个整体要么全部完成要么全部失败。
在SQL Server中,不管是否显式地使用begin transaction标记了事务的开始,每个DDL操作都是一个事务。
要把多条命令封装在一个事务中,只需要使用两个标记来圈定整个事务的范围:一个标记于事务开始处,而另一个则位于事务完成处,也就是把事务对数据的修改提交到磁盘的地方。如果封装在事务内部的代码检测到错误发生,可以回滚或撤销整个事务。
◊ begin transaction
◊ commit transaction
◊ rollback transaction
BEGIN TRANSACTION INSERT INTO Product(ProductNo,ProductName) VALUES ('1001','ProductA') IF @@error <> 0 BEGIN ROLLBACK TRANSACTION RAISERROR('error',16,1) RETURN END INSERT INTO Product(ProductNo,ProductName) VALUES ('1002','ProductB') IF @@error <> 0 BEGIN ROLLBACK TRANSACTION RAISERROR('error',16,1) RETURN END COMMIT TRANSACTION
1.1、事务完整性
事务完整性使用ACID特性来衡量事务的质量。违反事务完整性的问题有3类:脏读(dirty read)、不可重复读(nonrepeatable read)、幻影行(phantom rows)。要解决这3个问题,需要在事务之间使用不同的完整性或者隔离性级别。
1>、ACID属性
一个数据库产品的质量是通过它所提供的事务处理机制对ACID特性的支持程度来衡量的。ACID是4个相互独立的特性的首字母缩写:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持续性(durability)。
◊ 原子性
事务必须是原子的,这也就是说,在事务结束的时候,事务中的操作要么全部完成,要么全部失败。如果事务中的某些操作被写到磁盘,而另外一些则没有,就违反了原子性。
◊ 一致性
事务必须保证数据库的一致性,在事务执行前数据库应当处于一致状态,而事务结束的时候,数据库又会回到一致性状态。从ACID特性的目的来看,一致性意味着数据库中的每一行和每个值必须与其所描述的现实保持一致,而且满足所有约束的要求。如果将订单行写到磁盘上,却没有写入相应的订单明细,则Order与OrderDetail表之间的一致性就被破坏了。
◊ 隔离性
每个事务都必须与其他事务所产生的结果隔离开来。不管是否有其他的事务正在执行,事务都必须使用它开始运行的那一刻的数据集合执行下去。隔离性是两个事务之间的屏障。检验隔离性的方法之一是看数据库是否具有这样的能力,即:在相同的初始数据集合上多次重复执行一组特地的事务集合,而每次都能得到相同的结果。隔离性在多用户数据库中更为重要。
◊ 持续性
事务的持续性指不管系统是否发生了故障,事务处理的结果都是永久的。一旦事务被提交后,它就一直处于已提交状态。
2>、事务缺陷
事务之间缺乏足够的隔离性会表现在以下3个方面:脏读、不可重复读和幻影行。这些事务缺陷是影响事务完整性的隐患。
◊ 脏读(Dirty Reads)
事务最明显的缺陷是在事务提交之前,它对数据所做的修改就为其他事务所见。如果一个事务读取了另外一个事务尚未提交的更新,就叫做脏读。
BEGIN TRANSACTION UPDATE Product SET ProductName='Transaction Dirty Read' WHERE ProductID=1 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT ProductName FROM Product WHERE ProductID=1 COMMIT TRANSACTION
执行结果如下:
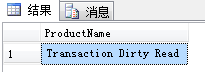
第一个事务尚未完成对数据的修改,而第二个事务却能够读到修改结果,这就违反了事务完整性。
◊ 不可重复读(Non-Repeatable Reads)
不可重复读类似于脏读,只不过它发生在事务看看到其他事务已经提交的数据更新的情况下。真正的隔离性指一个事务不会影响到另外一个事务。如果隔离性是完全的,那么一个事务不应该能看到本事务以外的数据更新。在一个事务内进行同样的读操作,每次都应该得到相同的结果。如果在两次读操作中得到了不同的结果,就意味着出现了不可重复读型事务缺陷。
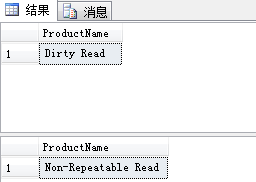
SET TRANSACTION ISOLATION LEVEL READ COMMITTED BEGIN TRANSACTION --UPDATE Product SET ProductName='Dirty Read' WHERE ProductID=1 SELECT ProductName FROM Product WHERE ProductID=1 BEGIN TRANSACTION UPDATE Product SET ProductName='Non-Repeatable Read' WHERE ProductID=1 COMMIT TRANSACTION SELECT ProductName FROM Product WHERE ProductID=1
执行结果如下:
◊ 幻影行(Phantom Rows)
危害最小的事务完整性缺陷是幻影行。和不可重复读有些相似,幻影行指的是一个事务的更新结果影响到另外一个事务的情况,但与不可重复读不同的是它不仅会影响到另外一个事务所取的结果集中的数据值,而且还能使select语句返回另外一些不同的记录行。
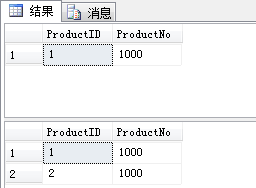
BEGIN TRANSACTION SELECT ProductID,ProductNo FROM Product WHERE ProductNo='1000' BEGIN TRANSACTION UPDATE Product SET ProductNo='1000' WHERE ProductID=2 COMMIT TRANSACTION SELECT ProductID,ProductNo FROM Product WHERE ProductNo='1000'
执行结果如下:
在上述所有这些事务缺陷中,脏读危害最大,不可重复读次之,幻影行危害最小。
3>、隔离性级别
数据库产品是通过在事务之间建立隔离还处理这3个事务缺陷的。隔离性级别是事务之间隔离带的高度,可以根据具体需求加以调节以控制允许出现的事务缺陷。
ANSI SQL-92定义了4个隔离级别:
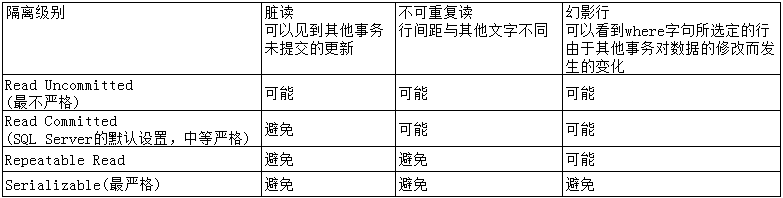
SQL Server使用锁来实现隔离性级别。鉴于锁影响到性能,用户必须在隔离级别和性能之间进行权衡。SQL Server的默认隔离级别是Read Committed,这对于大多数OLTP项目都是适用的。
◊ 级别1——Read Uncommitted
最不严格的隔离级别是Read Uncommitted,它不能防止任何一种事务缺陷,因为它根本没有在事务间提供隔离。把SQL Server的隔离级别设为Read Uncommitted,等同于把SQL Server的锁设置为NOLOCK。这种设置适合报表或只读的应用程序,因为此时SQL Server只为防止数据崩溃提供足够的锁,而不会为行竞争提供足够的锁,这对数据经常被更新的系统是不合适的。
◊ 级别2——Read Committed
Read Committed防止了最严重的事务缺陷,而又不会是系统陷入过度锁争用的泥潭。基于这个原因,SQL Server将她作为默认的隔离级别,对于绝大多数的OLTP项目来说,它都是一个理想的选择。
◊ 级别3——Repeatable Read
Repeatable Read可以防止脏读和不可重复读,它增加了事务的隔离级别,而因此带来的锁争用的压力没有Serializable隔离级别那样的严重。
◊ 级别4——Serializable
这是最严格的隔离级别,它防止了全部的事务缺陷,并且通过了在上面的隔离定义中所提到的串行事务测试。这种模式适用于对于绝对的事务完整性的要求比性能更为重要的情况。银行、账务系统、高度竞争性的销售数据库(例如股票市场)通常会使用Serializable隔离级别。
使用Serializable隔离级别相当于把锁设为HOLDLOCK,这将会使事务在整个执行期间都保持锁,甚至包含共享锁。这种设置虽然提供了完全的事务隔离性,却会造成恶劣的锁争用,并使性能降低。
2、SQL Server的锁机制
SQL Server用锁来实现事务之间的隔离,这样可以防止一个事务所操作的数据受到另外一个事务影响。每个所都具有以下3个特性:
◊ 粒度(Granularity)——锁的大小
◊ 模式(Mode)——锁的类型
◊ 持续期(Duration)——锁的隔离模式
2.1、锁的粒度

SQL Server的锁管理器试图在锁大小和数量之间寻求平衡以争取教好的性能。矛盾的焦点在并发(较小的锁可以允许更多的事务同时存取数据)和性能(锁越少速度越快)。为了达到平衡,锁管理器会动态地从一组锁切换到另外一组锁。
1>、25个行锁有可能升级为一个页锁。
2>、如果在同一个扩展区的其他4个以上的页面上分布着25个以上被锁定的行,上述页锁和这25个行级锁就可能升级为一个扩展盘区锁,因为该扩展盘区上有50%以上的页面都受到了锁定的影响。
3>、如果有足够的扩展盘区被锁住,所有这些锁就可能升级为一个表锁。
动态调整的锁策略为SQL Server的开发人员带来了显著的益处:
◊ 无需任何编程,就可以自动地在性能和并发之间取得最佳平衡;
◊ 随着数据库的增长,锁管理器会相应地使用与之匹配的锁粒度,从而保持数据库具有良好的性能;
◊ 动态锁定简化了管理工作。
2.2、锁模式
除了锁粒度也就是锁大小的属性之外,锁还具有锁模式属性,它确定了锁定的用途。SQL Server具有丰富的锁模式。
1>、锁争用
在SQL Server中,锁的相互作用与兼容性对事务完整性和性能都有很重要的影响。一些锁模式会排斥另一些锁模式。锁的兼容性如下:
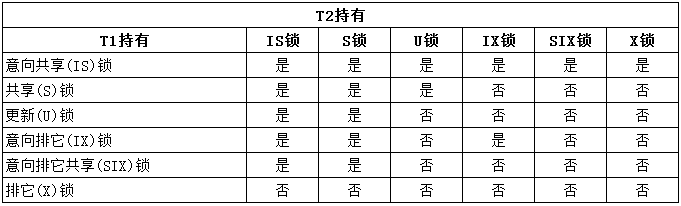
2>、共享锁(S)
到目前为止,最常用也是最为滥用的锁就是共享锁,它是一个简单的“读锁”。事务得到了共享锁就好比是在宣称“我正在查看这个数据”。通常多个事务可以同时查看同一组数据,当然最终还要取决于隔离模式。
3>、排它锁(X)
使用排它锁意味着事务正在写数据。对于同一数据,在同一时间只能有一个事务持有排它锁,其他事务在排它锁持续期间不能查看该数据。
4>、更新锁(U)
更新锁并不是事务执行更新时所使用的锁,更新锁意味着事务即将要使用排它锁,它当前正在扫描数据,以确定使用排它锁锁定的那些行。可以将更新锁当作即将转化为排它锁的共享锁。
为了避免死锁,在同一个时刻只运行使用一个事务持有更新锁。
5>、意向锁
意向锁是一种用于警示的锁,它警告其他事务即将要发生一些事情。意向锁的主要目的是提高性能。
2.3、查看锁
sp_lock

 浙公网安备 33010602011771号
浙公网安备 33010602011771号