
Hadoop系列教程<一>---Hadoop是什么呢?
Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量。Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。但是Hadoop的使用范围远小于SQL或Python之类的脚本语言,所以不要盲目使用Hadoop。不过作为一名钻研Java的物联网工程师,我觉得值得去学习了解,而且想和大数据打交道还没有那个没听过Hadoop的。
Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。 Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。 Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
Hadoop的架构
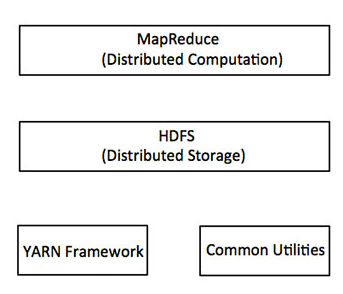
在其核心,Hadoop主要有两个层次,即(如下图所示):
- 加工/计算层(MapReduce),以及
- 存储层(Hadoop分布式文件系统)。
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
HDFS的关键元素:
Block:将一个文件进行分块,通常是64M。
NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在Hadoop2.*开始支持activity-standy模式----如果主NameNode失效,启动备用主机运行NameNode。
DataNode:分布在廉价的计算机上,用于存储Block块文件。

MapReduce
MapReduce是一种并行编程模型,用于编写普通硬件的设计,谷歌对大量数据的高效处理(多TB数据集)的分布式应用在大型集群(数千个节点)以及可靠的容错方式。 MapReduce程序可在Apache的开源框架Hadoop上运行。
通俗说MapReduce是一套从海量·源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。其基本原理:将大的数据分析分成小块逐个分析,最后再将提取出来的数据
汇总分析,最终获得我们想要的内容。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
Hadoop分布式文件系统
Hadoop分布式文件系统(HDFS)是基于谷歌文件系统(GFS),并提供了一个设计在普通硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。来自其他分布式文件系统的差别是显著。它高度容错并设计成部署在低成本的硬件。提供了高吞吐量的应用数据访问,并且适用于具有大数据集的应用程序。
除了上面提到的两个核心组件,Hadoop的框架还包括以下两个模块:
-
Hadoop通用:这是Java库和其他Hadoop组件所需的实用工具。
-
Hadoop YARN :这是作业调度和集群资源管理的框架。
Hadoop如何工作?
建立重配置,处理大规模处理服务器这是相当昂贵的,但是作为替代,可以联系许多普通电脑采用单CPU在一起,作为一个单一功能的分布式系统,实际上,集群机可以平行读取数据集,并提供一个高得多的吞吐量。此外,这样便宜不到一个高端服务器价格。因此使用Hadoop跨越集群和低成本的机器上运行是一个不错不选择。
Hadoop运行整个计算机集群代码。这个过程包括以下核心任务由 Hadoop 执行:
- 数据最初分为目录和文件。文件分为128M和64M(128M最好)统一大小块。
- 然后这些文件被分布在不同的群集节点,以便进一步处理。
- HDFS,本地文件系统的顶端﹑监管处理。
- 块复制处理硬件故障。
- 检查代码已成功执行。
- 执行发生映射之间,减少阶段的排序。
- 发送排序的数据到某一计算机。
- 为每个作业编写的调试日志。
Hadoop的优势
-
Hadoop框架允许用户快速地编写和测试的分布式系统。有效并在整个机器和反过来自动分配数据和工作,利用CPU内核的基本平行度。
-
Hadoop不依赖于硬件,以提供容错和高可用性(FTHA),而Hadoop库本身已被设计在应用层可以检测和处理故障。
-
服务器可以添加或从集群动态删除,Hadoop可继续不中断地运行。
-
Hadoop的的另一大优势在于,除了是开源的,因为它是基于Java并兼容所有的平台。
转载请注明出处!
http://www.cnblogs.com/libingbin/
感谢您的阅读。如果文章对您有用,那么请轻轻点个赞,以资鼓励。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号