
sql输出表中重复数据
数据:
1 1 2 3
2 2 2 3
3 1 2 3
4 2 2 3
5 2 1 3
6 1 1 3
7 3 2 1
表格查询:
SELECT * FROM `t1`;
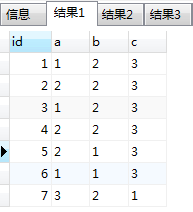
可以看到,如果界定为 a、b、c 都相同即为重复数据,那么sql的目的就是取出这样的数据。
。。。
按a分组,取数量:
SELECT a,COUNT(1) FROM `t1` GROUP BY a HAVING COUNT(1)>0;

看看出 a是1的有3条记录...
。。。
SELECT id,a,b,c,COUNT(1) AS cnt from t1 GROUP BY a,b,c HAVING cnt>1;
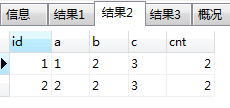
可以看出 abc都相同的有两类,每类有两条,一个是 abc都为123,另一个是abc都为223
这样就取出重复的数据,但是也只能取出重复的数据是 abc为123,和 abc为223,并不能一次取出重复的所有Id,如果要取出所有重复id还要继续查询 ,也就是遍历上面的结果,每次都是根据 abc的值查询就可以查询出所有重复的记录的id了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号