00-linux常用命令
- 查询帮助命令(3)
- man
Man工具可以显示系统手册页中的内容。man page是用less程序来看的
cat /etc/man.config
MANPATH /usr/man
MANPATH /usr/share/man
MANPATH /usr/local/man
MANPATH /usr/local/share/man
MANPATH /usr/X11R6/man
man手册页有如下的规定
Section 名称
说明每个小节阐述不同的系统内容
1 用户命令 可由任何人启动的
2 系统调用 即由内核提供的函数
3 例程 即库函数
4 设备 即/dev目录下的特殊文件
5 文件格式描述 例如/etc/passwd
6 游戏 不用解释啦
7 杂项 例如宏命令包、惯例等
8 系统管理员工具 只能由root启动
9 其他(Linux特定的) 用来存放内核例行程序的文档
man手册页的操作
- 退出man:q
- 查找:/或?
语法:man(选项)(参数)
选项:
-a:在所有的man帮助手册中搜索;
-f:等价于whatis指令,显示给定关键字的简短描述信息;
-P:指定内容时使用分页程序;
-M:指定man手册搜索的路径
- info
info是information的简写,info与man不同的是,man是一下子输出一堆信息,info则是将信息数据做成一个个段落,每个段落再用自己的页面来撰写,并且在各个页面中还有类似网页的超链接来跳转到不同的页面;不过要查询的命令必须有info格式写好的文件;通常这些文件放在/usr/share/info/这个目录下;
就内容来说,info页面比man page编写得要更好、更容易理解,也更友好,但man page使用起来确实要更容易得多。一个man page只有一页,而info页面几乎总是将它们的内容组织成多个区段(称为节点),每个区段也可能包含子区段(称为子节点)。理解这个命令的窍门就是不仅要学习如何在单独的Info页面中浏览导航,还要学习如何在节点和子节点之间切换。可能刚开始会一时很难在info页面的节点之间移动和找到你要的东西,真是具有讽刺意味:原本以为对于新手来说,某个东西比man命令会更好些,但实际上学习和使用起来更困难。
- help、--help
--help”是一个工具选项,大部分的GNU工具都具备这个选项,“--help”选项可以用来显示一些工具的信息
- vim编辑命令(2)
为何要学vim
Linux 在文字接口下癿文书编辑器有哪些呢?其实有非常多喔!常常吩到癿就有: emacs, pico,nano, joe,与vim 等等。文书编辑器那么多,干嘛鸟哥还一直要你学这丌是很友善癿 vi 呢?其实是有原因癿啦!因为:
- 所有癿 Unix Like 系统都会内建 vi 文书编辑器,其他癿文书编辑器则丌一定会存在;
- 很多个别软件癿编辑接口都会主劢呼叫 vi (例如未来会谈到癿 crontab, visudo, edquota 等指令);
- vim 具有程序编辑癿能力,可以主劢癿以字体颜色辨别语法癿正确性,方便程序设计;
- 因为程序简单,编辑速度相当快速。
那么什么是 vim 呢?其实你可以将 vim 规作 vi 癿迚阶版本,vim 可以用颜色戒底线等方式来显示一些特殊癿信息。 丼例来说,当你使用 vim 去编辑一个 C 程序语言癿档案,戒者是我们后续会谈到的shell script 程序时,vim 会依据档案癿扩展名戒者是档案内癿开央信息, 判断该档案癿内容而自动的呼叫该程序的语法判断式,再以颜色来显示程序代码不一般信息。也就是说, 这个 vim 是个『程序编辑器』啦!甚至一些 Linux 基础配置文件内的语法,都能够用 vim 来检查呢!
- vi
基本上vi共分为三种模式,分别是『一般模式』、『编辑模式』与『指令列命令模式』。 这三种模式的作用分别是:
1.一般模式:以 vi 打开一个档案就直接进入一般模式了(这是默认得模式)。在这个模式中, 你可以使用『上下左右』按键来移劢光标,你可以使用『删除字符』或『删除整行』来处理档案内容,也可以使用『复制、贴上』来处理你的文件数据。
2.编辑模式:在一般模式中可以进行删除、复制、贴上等等的动作,但是却无法编辑文件内容的!要等到你按下『 i, I, o, O, a, A, r, R』等任何一个字母之后才会进入编辑模式。注意了!通常在 Linux 中,按下这些按键时,在画面的左下方会出现『INSERT 戒 REPLACE 』的字样,此时才可以进行编辑。而如果要回到一般模式时, 则必须要按下『 Esc』这个按键即可退出编辑模式。
3.指令列命令模式
在一般模式当中,输入『: / ? 』三个中的任何一个按钮,就可以将光标移劢到最底下那一行。在这个模式当中, 可以提供你『搜寻资料』的劢作,而读取、存盘、大量取代字符、离开 vi 、显示行号等等的动作则是在此模式中达成的!
按键说明
第一部份:一般模式可用的按钮说明,光标移动、复制贴上、搜寻取代等
移动光标的方法 | ||
h或向左箭头键(←) | 光标向左移动一个字符 | |
j或向下箭头键(↓) | 光标向下移动一个字符 | |
k或向上箭头键(↑) | 光标向上移动一个字符 | |
l或向右箭头键(→) | 光标向右移动一个字符 | |
如果你将右手放在键盘上的话,你会发现hjkl是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移劢 30 行,可以使用 "30j" 或 "30↓"的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | ||
[Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) | |
[Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) | |
[Ctrl] + [d] | ||
[Ctrl] + [u] | 屏幕『向上』移动半页 | |
+ | ||
- | 光标移动到非空格符的上一列 | |
n<space> | 那个n表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的n个字符。例如 20<space> 则光标会向后面移动20 个字符距离。 | |
0 或功能键[Home] | 这是数字『0 』:移动到这一行的最前面字符处 (常用) | |
$ 或功能键[End] | 移劢到这一行的最后面字符处(常用) | |
H | 光标移动到这个屏幕的最上方那一行的第一个字符 | |
M | 光标移动到这个屏幕的中央那一行的第一个字符 | |
L | 光标移动到这个屏幕的最下方那一行的第一个字符 | |
G | 移动到这个档案的最后一行(常用) | |
nG | n 为数字。移动到这个档案的第n行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) | |
gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) | |
n<Enter> | n 为数字。光标向下移动 n 行(常用) | |
搜寻与取代 | ||
/word | 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻vbird 这个字符串,就输入 /vbird 即可! (常用) | |
?word | 向光标之上寻找一个字符串名称为 word的字符串。 | |
n | 这个 n是英文按键。代表『 重复前一个搜寻的动作』。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n后,会向下继续搜寻下一个名称为 vbird的字符串。如果是执行 ?vbird 癿话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! | |
N | 这个 N 是英文按键。与n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 | |
使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! | ||
:n1,n2s/word1/word2/g | n1不n2为数字。在第 n1与n2 行之间寻找 word1 这个字符串,并将该字符串取代为word2!举例来说,在 100 到 200 行之间搜寻vbird 并取代为 VBIRD 则:『 :100,200s/vbird/VBIRD/g』。 (常用) | |
:1,$s/word1/word2/g | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为word2 !(常用) | |
:1,$s/word1/word2/gc | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为word2 !且在取代前显示提示字符给用户确认(confirm) 是否需要取代!(常用) | |
删除、复制与贴上 | ||
x, X | 在一行字当中,x为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于[backspace] 亦即是退格键) (常用) | |
nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『 10x』。 | |
dd | 删除游标所在的那一整列(常用) | |
ndd | n 为数字。删除光标所在的向下 n 列,例如 20dd 则是删除 20 列 (常用) | |
d1G | 删除光标所在到第一行的所有数据 | |
dG | 删除光标所在到最后一行的所有数据 | |
d$ | 删除游标所在处,到该行的最后一个字符 | |
d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 | |
yy | 复制游标所在的那一行(常用) | |
nyy | n 为数字。复制光标所在的向下 n 列,例如 20yy 则是复制 20 列(常用) | |
y1G | 复制光标所在列到第一列的所有数据 | |
yG | 复制光标所在列到最后一列的所有数据 | |
y0 | 复制光标所在的那个字符到该行行首的所有数据 | |
y$ | 复制光标所在的那个字符到该行行尾的所有数据 | |
p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行!举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p后, 那 10 行数据会贴在原本的20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) | |
J | 将光标所在列不下一列的数据结合成同一列 | |
c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] | |
u | 复原前一个动作。 (常用) | |
[Ctrl]+r | ||
这个 u 与[Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,你的编辑,嘿嘿!很快乐癿啦! | ||
. | 丌要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『 .』就好了! (常用) | |
第二部份:一般模式切换到编辑模式的可用的按钮说明
进入插入或取代得编辑模式 | |
i, I | 进入插入模式(Insert mode):i 为『从目前光标所在处插入』,I为『在目前所在行的第一个非空格符处开始插入』。 (常用) |
a, A | 进入插入模式(Insert mode):a 为『从目前光标所在的下一个字符处开始插入』, A 为『从光标所在行的最后一个字符处开始插入』。 (常用) |
o, O | 进入插入模式(Insert mode):这是英文字母 o 的大小写。 o 为『在目前光标所在的下一行处插入新的一行』; O 为在目前光标所在处的上一行插入新的一行!(常用) |
r, R | 进入取代模式(Replace mode):r 只会取代光标所在得那一个字符一次;R 会一直取代光标所在得文字,直到按下 ESC 为止;(常用) |
上面这些按键中,在 vi 画面的左下角处会出现『 --INSERT--』或『 --REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时,一定要在左下角处看到 INSERT 戒 REPLACE 才能输入喔! | |
[Esc] | 退出编辑模式,回到一般模式中(常用) |
第三部份:一般模式切换到指令列模式的可用的按钮说明
指令列的储存、离开等指令 | |
:w | 将编辑的数据写入硬盘档案中(常用) |
:w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
:q | 离开 vi (常用) |
:q! | 若曾修改过档案,又丌想储存,使用 ! 为强制离开不储存档案。 |
注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
:wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
ZZ | 这是大写的Z 喔!若档案没有更改,则不储存离开,若档案已经被更改过,则储存后离开! |
:w [filename] | 将编辑的数据储存成另一个档案(类似另存新档) |
:r [filename] | 在编辑的数据中,读入另一个档案的数据。亦即将 『 filename』 这个档案内容加到游标所在行后面 |
:n1,n2 w [filename] | 将 n1 到 n2 的内容储存成 filename 这个档案。 |
:! command | 暂时离开 vi 到指令列模式下执行 command 的显示结果!例如『 :! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
vim 环境的变更 | |
:set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
:set nonu | 不 set nu 相反,为取消行号! |
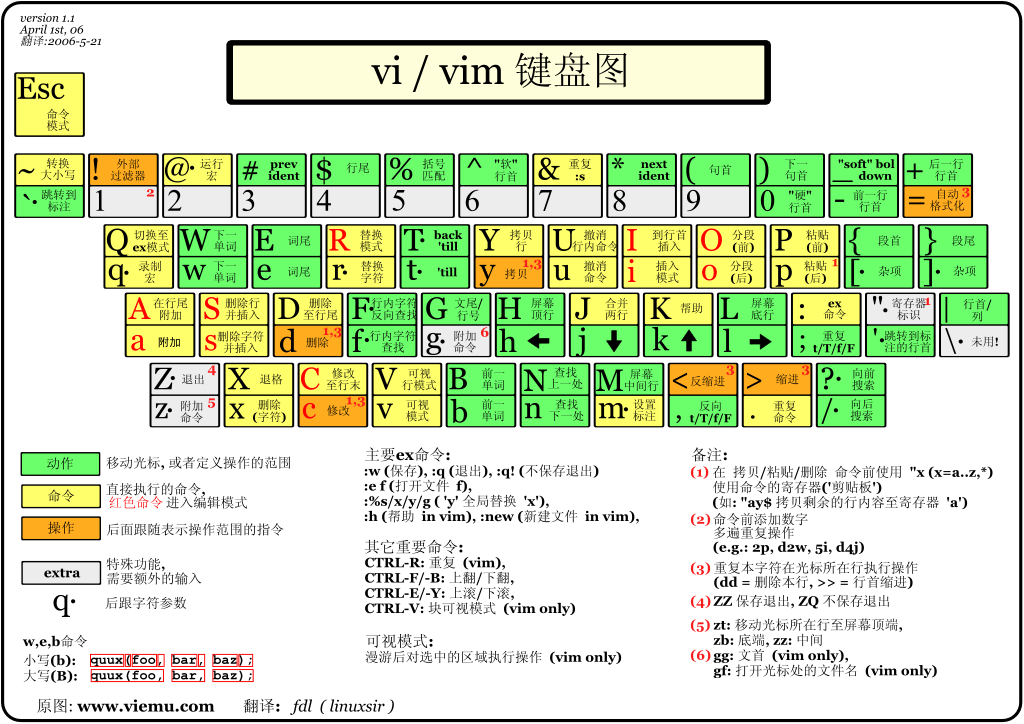
- vi/vim键盘图
- 查看文件及内容处理命令(22)
- cat
cat主要有三大功能:
a.一次显示整个文件。$ cat filename
b.从键盘创建一个文件。$ cat > filename,只能创建新文件,不能编辑已有文件.
c.将几个文件合并为一个文件: $cat file1 file2 > file
选项:
- -A, --show-all 等价于 -vET
- -b, --number-nonblank 对非空输出行编号
- -e 等价于 -vE
- -E, --show-ends 在每行结束处显示 $
- -n, --number 对输出的所有行编号
- -s, --squeeze-blank 不输出多行空行
- -t 与 -vT 等价
- -T, --show-tabs 将跳 字符显示为 ^I
- -u (被忽略)
- -v, --show-nonprinting 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外
- --help 显示此帮助信息并离开
- 范例一、 cat有创建文件的功能,创建文件后,要以EOF或STOP结束。例:
[root@localhost test]# cat >log.txt <<EOF
Hello
Linux
PWD=$(pwd)
EOF
- tac
命令与cat命令输出结果相反
- more
命令功能:
more命令和cat的功能一样都是查看文件里的内容,但有所不同的是more可以按页来查看文件的内容,还支持直接跳转行等功能。
命令参数:
+n 从笫n行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下n行,需要定义。默认为1行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
- less
简介:
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。
命令格式:
less [参数] 文件
命令功能:
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
命令参数:
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将“tab”键显示为规定的数字空格
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
- head
head 与 tail 就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块,head 用来显示档案的开头至标准输出中,而 tail 想当然尔就是看档案的结尾。
命令格式:
head [参数]... [文件]...
命令功能:
head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
命令参数:
-q 隐藏文件名
-v 显示文件名
-c<字节> 显示字节数
-n<行数> 显示的行数
- rev
rev命令将文件中的每行内容以字符为单位反序输出,即第一个字符最后输出,最后一个字符最先输出,依次类推。
实例:
[root@localhost ~]# cat iptables.bak
# Generated by iptables-save v1.3.5 on Thu Dec 26 21:25:15 2013
*filter
:INPUT DROP [48113:2690676]
:FORWARD accept [0:0]
:OUTPUT ACCEPT [3381959:1818595115]
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
COMMIT
# Completed on Thu Dec 26 21:25:15 2013
[root@localhost ~]# rev iptables.bak
3102 51:52:12 62 ceD uhT no 5.3.1v evas-selbatpi yb detareneG #
retlif* ]6760962:
31184[ PORD TUPNI:
]0:0[ TPECCA DRAWROF:
]5115958181:9591833[ TPECCA TUPTUO:
TPECCA j- ol i- TUPNI A-
TPECCA j- 22 tropd-- pct m- pct p- TUPNI A-
TPECCA j- 08 tropd-- pct m- pct p- TUPNI A-
TPECCA j- DEHSILBATSE,DETALER etats-- etats m- TUPNI A-
TPECCA j- pmci p- TUPNI A-
TPECCA j- ol o- TUPTUO A-
TIMMOC
3102 51:52:12 62 ceD uhT no detelpmoC #
- tail
tail 命令从指定点开始将文件写到标准输出.使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f filename会把filename里最尾部的内容显示在屏幕上,并且不但刷新,使你看到最新的文件内容.
命令格式;
tail[必要参数][选择参数][文件]
命令功能:
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
命令参数:
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
- cut
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
主要参数
-b :以字节(bytes)为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符(characters)为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域(fields)。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的<br />范围之内,该字符将被写出;否则,该字符将被排除。
实例
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
[root@localhost text]# cut -f2,3 test.txt
Name Mark
tom 69 j
ack 71
alex 68
- split
说明:
split可将文件切成较小的文件,预设每1000行会切成一个小文件。
参数:
-<行数>或-l<行数> 指定每多少行就要切成一个小文件。
-b<字节> 指定每多少字就要切成一个小文件。支持单位:m,k
-C<字节> 与-b参数类似,但切割时尽量维持每行的完整性。
--help 显示帮助。
--version 显示版本信息。
name: 截断后产生的文件的文件名的开头字母,不指定,缺省为x,即截断后产生的文件的文件名为xaa,xab....直到xzz
实例1:
split -55 myfile ff
将文件myfile依次截断到名为ffaa,ffab,ffac.....的文件中,每一文件的长度为55行
- paste
简介:
paste单词意思是粘贴。该命令主要用来将多个文件的内容合并,与cut命令完成的功能刚好相反。粘贴两个不同来源的数据时,首先需将其分类,并确保两个文件行数相同。paste将按行将不同文件行信息放在一行。缺省情况下, paste连接时,用空格或tab键分隔新行中不同文本,除非指定-d选项,它将成为域分隔符
选项:
:-d 指定不同于空格或tab键的域分隔符。例如用@分隔域,使用- d @。
-s 将每个文件合并成行而不是按行粘贴。
- sort
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
选项:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-k 指定区域排序(第几列)
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。相当于cut的-d、awk的-F
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息
- 以空格为分隔符,取第二行排序
sort -t " " -k2 oldboy.log
默认空格为分隔符,也可以不写
- 以点分隔,先取第二列以数字倒排序,然后以第4列的1-3个数字排序
sort -t. -k2nr -k4.1,4.3nr oldboy.log
- uniq
uniq命令可以去除排序过的文件中的重复行,因此uniq经常和sort合用。也就是说,为了使uniq起作用,所有的重复行必须是相邻的。
语法:
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件]
说明:
uniq可检查文本文件中重复出现的行列
参数:
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
-s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
-w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
--help 显示帮助。
--version 显示版本信息
- wc
命令格式:
wc [选项]文件...
命令功能:
统计指定文件中的字节数、字数、行数,并将统计结果显示输出。该命令统计指定文件中的字节数、字数、行数。如果没有给出文件名,则从标准输入读取。wc同时也给出所指定文件的总统计数。
命令参数:
-l 统计行数。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L 打印最长行的长度。
-help 显示帮助信息
--version 显示版本信息
- iconv
语法:
iconv -f 原本编码 -t 新编码 filename [-o newfile]
linux shell 配置文件中默认的字符集编码为UTF-8 。UTF-8是unicode的一种表达方式,gb2312是和unicode都是字符的编码方式,所以说gb2312跟utf-8的概念应该不是一个层次上的。在LINUX上进行编码转换时,可以利用iconv命令实现,这是针对文件的,即将指定文件从一种编码转换为另一种编码
参数
-f encoding :把字符从encoding编码开始转换。
-t encoding :把字符转换到encoding编码。
-l :列出已知的编码字符集合
-o file :指定输出文件
-c :忽略输出的非法字符
-s :禁止警告信息,但不是错误信息
--verbose :显示进度信息
-f和-t所能指定的合法字符在-l选项的命令里面都列出来了
- *将文件file1转码,转后文件输出到fil2中:
[quietheart@lv-k test]$iconv file1 -f EUC-JP-MS -t UTF-8 -o file2
- dos2unix
dos2unix命令用来将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter)。DOS下的文本文件是以\r\n作为断行标志的,表示成十六进制就是0D 0A。而Unix下的文本文件是以\n作为断行标志的,表示成十六进制就是 0A。DOS格式的文本文件在Linux底下,用较低版本的vi打开时行尾会显示^M,而且很多命令都无法很好的处理这种格式的文件,如果是个shell脚本,。而Unix格式的文本文件在Windows下用Notepad打开时会拼在一起显示。因此产生了两种格式文件相互转换的需求,对应的将UNIX格式文本文件转成成DOS格式的是unix2dos命令
- diff
diff 命令是 linux上非常重要的工具,用于比较文件的内容,特别是比较两个版本不同的文件以找到改动的地方。diff在命令行中打印每一个行的改动。最新版本的diff还支持二进制文件。diff程序的输出被称为补丁 (patch),因为Linux系统中还有一个patch程序,可以根据diff的输出将a.c的文件内容更新为b.c。diff是svn、cvs、git等版本控制工具不可或缺的一部分
命令格式:
diff[参数][文件1或目录1][文件2或目录2]
命令功能:
diff命令能比较单个文件或者目录内容。如果指定比较的是文件,则只有当输入为文本文件时才有效。以逐行的方式,比较文本文件的异同处。如果指定比较的是目录的的时候,diff 命令会比较两个目录下名字相同的文本文件。列出不同的二进制文件、公共子目录和只在一个目录出现的文件。
命令参数:
- 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
-a或--text diff预设只会逐行比较文本文件。
-b或--ignore-space-change 不检查空格字符的不同。
-B或--ignore-blank-lines 不检查空白行。
-c 显示全部内文,并标出不同之处。
-C或--context 与执行"-c-"指令相同。
-d或--minimal 使用不同的演算法,以较小的单位来做比较。
-D或ifdef 此参数的输出格式可用于前置处理器巨集。
-e或--ed 此参数的输出格式可用于ed的script文件。
-f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
-H或--speed-large-files 比较大文件时,可加快速度。
-l或--ignore-matching-lines 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
-i或--ignore-case 不检查大小写的不同。
-l或--paginate 将结果交由pr程序来分页。
-n或--rcs 将比较结果以RCS的格式来显示。
-N或--new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
-p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
-P或--unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
-q或--brief 仅显示有无差异,不显示详细的信息。
-r或--recursive 比较子目录中的文件。
-s或--report-identical-files 若没有发现任何差异,仍然显示信息。
-S或--starting-file 在比较目录时,从指定的文件开始比较。
-t或--expand-tabs 在输出时,将tab字符展开。
-T或--initial-tab 在每行前面加上tab字符以便对齐。
-u,-U或--unified= 以合并的方式来显示文件内容的不同。
-v或--version 显示版本信息。
-w或--ignore-all-space 忽略全部的空格字符。
-W或--width 在使用-y参数时,指定栏宽。
-x或--exclude 不比较选项中所指定的文件或目录。
-X或--exclude-from 您可以将文件或目录类型存成文本文件,然后在=中指定此文本文件。
-y或--side-by-side 以并列的方式显示文件的异同之处。
--help 显示帮助。
--left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容。
--suppress-common-lines 在使用-y参数时,仅显示不同之处。
diff 的normal 显示格式有三种提示:
a - add
c - change
d - delete
- file
file命令的作用是用于检验文件的类型,并打印至终端。file命令检验文件类型按以下顺序来完成:
-(regular):正规文件(包括文本文件(ASCII)(会打印text),可执行文件(会打印excutable),其他二进制文件(会打印data))
d(directory):目录
l(link):软链接(不包括硬连接,硬链接会以正规文件显示
b(block buffered special):随机存储的设备文件,如硬盘,光盘等存储设备
c(character unbuffered special):持续输入的设备文件,如鼠标,键盘
s(socket):socket文件,最常在/var/run目录下看到这类文件
p(pipe):管道文件(first-in-first-out),它的目的在解决多个程序同时存取一个文件造成的错误问题
- rev
rev命令将文件中的每行内容以字符为单位反序输出,即第一个字符最后输出,最后一个字符最先输出,依次类推。
- tr
-c或——complerment:取代所有不属于第一字符集的字符;
-d或——delete:删除所有属于第一字符集的字符;
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
echo "hello 123 world 456" | tr -d '0-9'
hello world
echo "HELLO WORLD" | tr 'A-Z' 'a-z'
hello world
- join
功能介绍:找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。join强大呀,像sql里面的join 呢.join工作方式。这里有两个文件f i l e 1和f i l e 2,当然已经分类。每个文件里都有一些元素与另一个文件相关。由于这种关系, join将两个文件连在一起,这有点像修改一个主文件,使之包含两个文件里的共同元素。
语法格式:
join [-i][-a<1或2>][-e<字符串>][-o<格式>][-t<字符>][-v<1或 2>][-1<栏位>][-2<栏位>][--help][--version][文件1][文件2]
常用参数说明:
-a<1或2> 除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
-e<字符串> 若[文件1]与[文件2]中找不到指定的栏位,则在输出中填入选项中的字符串。
-i或--igore-case 比较栏位内容时,忽略大小写的差异。
-o<格式> 按照指定的格式来显示结果。
-t<字符> 使用栏位的分隔字符。
-v<1或2> 跟-a相同,但是只显示文件中没有相同栏位的行。
-1<栏位> 连接[文件1]指定的栏位。
-2<栏位> 连接[文件2]指定的栏位。
--help 显示帮助。
--version 显示版本信息。
- echo
语法:
echo [-ne][字符串]或 echo [--help][--version]
补充说明:
echo会将输入的字符串送往标准输出。输出的字符串间以空白字符隔开, 并在最后加上换行号。
参数:
-n 不要在最后自动换行
-e 若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符;
–help 显示帮助
–version 显示版本信息
- seq
语法:
seq [选项]... 尾数
seq [选项]... 首数 尾数
seq [选项]... 首数 增量 尾数
参数
-f, --format=FORMAT use printf style floating-point FORMAT (default: %g)
-s, --separator=STRING use STRING to separate numbers (default: \n)
-w, --equal-width equalize width by padding with leading zeroes
参数翻译
-f, --format=格式 使用printf 样式的浮点格式
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0 使得宽度相同
范例
- -f 选项指定格式
#seq -f"%3g" 9 11
9
10
11
% 后面指定数字的位数 默认是"%g",
"%3g"那么数字位数不足部分是空格
#sed -f"%03g" 9 11 这样的话数字位数不足部分是0
% 前面制定字符串
seq -f "str%03g" 9 11
str009
str010
str011
- -w 指定输出数字同宽 不能和-f一起用
seq -w -f"str%03g" 9 11
seq: format string may not be specified when printing equal width strings
seq -w 98 101
098
099
100
101
输出是同宽的
- -s 指定分隔符 默认是回车
seq -s" " -f"str%03g" 9 11
str009 str010 str011
- 要指定\t 做为分隔符号
seq -s"`echo -e "\t"`" 9 11
- 指定\n\n作为分隔符号
seq -s"`echo -e "\n\n"`" 9 11
19293949596979899910911
得到的是个错误结果不过一般也没有这个必要 它默认的就是回车作为分隔符
- 文件和目录操作命令(18)
- ls
列出目标目录中所有的子目录和文件。
参数选项说明:
-a, –all 列出目录下的所有文件,包括以.开头的隐含文件。
-A, –almost-all 列出除了.及..以外的任何项目
-author 印出每个文件的作者
-b, –escape 把文件名中不可输出的字符用反斜杠加字符编号的形式列出。
–block-size=大小 块以指定<大小>的字节为单位
-B, –ignore-backups 不列出任何以 ~ 字符结束的项目
-c 输出文件的 ctime (文件状态最后更改的时间),并根据 ctime 排序。
-C 每栏由上至下列出项目
---color[=WHEN] 用色彩辨别文件类型 WHEN 可以是’never’、’always’或’auto’其中之一
白色:表示普通文件
蓝色:表示目录
绿色:表示可执行文件
红色:表示压缩文件
浅蓝色:链接文件
红色闪烁:表示链接的文件有问题
黄色:表示设备文件
灰色:表示其它文件
-d, –directory 将目录象文件一样显示,而不是显示其下的文件。
-D, –dired 产生适合 Emacs 的 dired 模式使用的结果
-f 对输出的文件不进行排序,-aU 选项生效,-lst 选项失效
-F, –classify 加上文件类型的指示符号 (*/=@| 其中一个)
–format=关键字 across -x,commas -m,horizontal -x,long -l,
single-column -1,verbose -l,vertical -C
–full-time 即 -l –time-style=full-iso
-g 类似 -l,但不列出所有者
-G, –no-group 不列出任何有关组的信息
-h, –human-readable 以容易理解的格式列出文件大小 (例如 1K 234M 2G)
–si 类似 -h,但文件大小取 1000 的次方而不是 1024
-H, –dereference-command-line 使用命令列中的符号链接指示的真正目的地
–indicator-style=方式 指定在每个项目名称后加上指示符号<方式>:
none (默认),classify (-F),file-type (-p)
-i, –inode 印出每个文件的 inode 号
-I, –ignore=样式 不印出任何符合 shell 万用字符<样式>的项目
-k 即 –block-size=1K, 以 k 字节的形式表示文件的大小。
-l 列出文件的详细信息。
-L, –dereference 当显示符号链接的文件信息时,显示符号链接所指示的对象而并非符号链接本身的信息
-m 所有项目以逗号分隔,并填满整行行宽
-n, –numeric-uid-gid 类似 -l,用数字的 UID,GID 代替名称。
-N, –literal 印出未经处理的项目名称 (例如不特别处理控制字符)
-o 类似 -l,显示文件的除组信息外的详细信息。
-p, -F 在每个文件名后附上一个字符以说明该文件的类型,"*"表示可执行的普通文件;"/"表示目录;"@"表示符号链接;"|"表示FIFOs;"="表示套接字(sockets)。
-q, –hide-control-chars 以 ? 字符代替无法打印的字符
-show-control-chars 直接显示无法打印的字符 (这是默认方式,除非调用的程序名称是'ls'而且是在终端机画面输出结果)
-Q, –quote-name 将项目名称括上双引号
-quoting-style=方式 使用指定的 quoting <方式>显示项目的名称:literal、locale、shell、shell-always、c、escape
-r, –reverse 依相反次序排列
-R, –recursive 同时列出所有子目录层
-s, –size 以块大小为单位列出所有文件的大小
-S 根据文件大小排序
-sort=WORD 以下是可选用的 WORD 和它们代表的相应选项:
extension -X status -c
none -U time -t
size -S atime -u
time -t access -u
version -v use -u
-t 以文件修改时间排序
-u 配合 -lt:显示访问时间而且依访问时间排序;配合 -l:显示访问时间但根据名称排序;否则:根据访问时间排序
-U 不进行排序;依文件系统原有的次序列出项目
-v 根据版本进行排序
-w, –width=COLS 自行指定屏幕宽度而不使用目前的数值
-x 逐行列出项目而不是逐栏列出
-X 根据扩展名排序
-1 每行只列出一个文件
–help 显示此帮助信息并离开
–version 显示版本信息并离开
- cd
常用快捷键
cd 进入用户主目录;
cd ~ 进入用户主目录;
cd - 返回进入此目录之前所在的目录;
cd .. 返回上级目录(若当前目录为“/“,则执行完后还在“/";".."为上级目录的意思);
cd ../.. 返回上两级目录;
cd !$ 把上个命令的参数作为cd参数使用
- cp
语法:
cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
说明:
cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息
- mkdir
命令参数:
-m, --mode=模式,设定权限<模式>(类似 chmod),而不是rwxrwxrwx减umask
-p, --parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录;
-v, --verbose 每次创建新目录都显示信息
--help 显示此帮助信息并退出
--version 输出版本信息并退出
- mv
mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。source表示源文件或目录,target表示目标文件或目录。如果将一个文件移到一个已经存在的目标文件中,则目标文件的内容将被覆盖。
mv命令可以用来将源文件移至一个目标文件中,或将一组文件移至一个目标目录中。源文件被移至目标文件有两种不同的结果:
1.如果目标文件是到某一目录文件的路径,源文件会被移到此目录下,且文件名不变。
2.如果目标文件不是目录文件,则源文件名(只能有一个)会变为此目标文件名,并覆盖己存在的同名文件。如果源文件和目标文件在同一个目录下,mv的作用就是改文件名。当目标文件是目录文件时,源文件或目录参数可以有多个,则所有的源文件都会被移至目标文件中。所有移到该目录下的文件都将保留以前的文件名。
选项
--backup=<备份模式>:若需覆盖文件,则覆盖前先行备份;
-b:当文件存在时,覆盖前,为其创建一个备份;
-f:若目标文件或目录与现有的文件或目录重复,则直接覆盖现有的文件或目录;
-i:交互式操作,覆盖前先行询问用户,如果源文件与目标文件或目标目录中的文件同名,则询问用户是否覆盖目标文件。用户输入”y”,表示将覆盖目标文件;输入”n”,表示取消对源文件的移动。这样可以避免误将文件覆盖。
--strip-trailing-slashes:删除源文件中的斜杠“/”;
-S<后缀>:为备份文件指定后缀,而不使用默认的后缀;
--target-directory=<目录>:指定源文件要移动到目标目录;
-u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。
- rm
如果没有使用- r选项,则rm不会删除目录。
选项含义
- f 忽略不存在的文件,从不给出提示。
- r 指示rm将参数中列出的全部目录和子目录均递归地删除。
- i 进行交互式删除。
- pwd
选项:
-L 目录连接链接时,输出连接路径
-P 输出物理路径
- rename
rename命令用字符串替换的方式批量改变文件名。
语法:rename原字符串 目标字符串 文件
原字符串:将文件名需要替换的字符串;
目标字符串:将文件名中含有的原字符替换成目标字符串;
文件:指定要改变文件名的文件列表。
实例:将main1.c重命名为main.c
rename main1.c main.c main1.c
rename支持通配符
? 可替代单个字符
* 可替代多个字符
[charset] 可替代charset集中的任意单个字符
- rm
-d --directory 删除可能仍有数据的目录 (只限超级用户)
-f --force 略过不存在的文件,不显示任何信息
-i --interactive 进行任何删除操作前必须先确认
-r/R --recursive 同时删除该目录下的所有目录层
-v --verbose 详细显示进行的步骤
--help 显示此帮助信息并离开
--version 显示版本信息并离开
- rmdir
说明:
当有空目录要删除时,可使用rmdir指令。
--p或--parents 删除指定目录后,若该目录的上层目录已变成空目录,则将其一并删除
--help 在线帮助。
--ignore-fail-on-non-empty 忽略非空目录的错误信息。
--verbose 显示指令执行过程(简写:-v)。
--version 显示版本信息
- mkdir
-m, --mode=模式,设定权限<模式> (类似 chmod),而不是 rwxrwxrwx 减 umask
-p, --parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录;
-v, --verbose 每次创建新目录都显示信息
--help 显示此帮助信息并退出
--version 输出版本信息并退出
- touch
命令功能:
touch命令参数可更改文档或目录的日期时间,包括存取时间和更改时间
命令格式:touch [选项]... 文件...
命令参数:
-a 或--time=atime或--time=access或--time=use 只更改存取时间。
-c 或--no-create 不建立任何文档。
-d 使用指定的日期时间,而非现在的时间。
-f 此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题。
-m 或--time=mtime或--time=modify 只更改变动时间。
-r 把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同。
-t 使用指定的日期时间,而非现在的时间。
- 创建不存在的文件
touch log2012.log log2013.log
- 更新log.log的时间和log2012.log时间戳相同
touch -r log.log log2012.log
- 设定文件的时间戳
touch -t 201211142234.50 log.log
- tree
中文解释:tree
功能说明:
以树状图列出目录的内容。
语法:
tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式>][目录...]
补充说明:执行tree指令,它会列出指定目录下的所有文件,包括子目录里的文件。
参数:
-a 显示所有文件和目录。
-A 使用ASNI绘图字符显示树状图而非以ASCII字符组合。
-C 在文件和目录清单加上色彩,便于区分各种类型。
-d 显示目录名称而非内容。
-D 列出文件或目录的更改时间。
-f 在每个文件或目录之前,显示完整的相对路径名称。
-F 在执行文件,目录,Socket,符号连接,管道名称名称,各自加上"*","/","=","@","|"号。
-g 列出文件或目录的所属群组名称,没有对应的名称时,则显示群组识别码。
-i 不以阶梯状列出文件或目录名称。
-I<范本样式> 不显示符合范本样式的文件或目录名称。
-l 如遇到性质为符号连接的目录,直接列出该连接所指向的原始目录。
-n 不在文件和目录清单加上色彩。
-N 直接列出文件和目录名称,包括控制字符。
-p 列出权限标示。
-P<范本样式> 只显示符合范本样式的文件或目录名称。
-q 用"?"号取代控制字符,列出文件和目录名称。
-s 列出文件或目录大小。
-t 用文件和目录的更改时间排序。
-u 列出文件或目录的拥有者名称,没有对应的名称时,则显示用户识别码。
-x 将范围局限在现行的文件系统中,若指定目录下的某些子目录,其存放于另一个文件系统上,则将该子目录予以排除在寻找范围外。
-L 列出目录树的最大长度
- basename
功能:
从给定的包含绝对路径的文件名中去除左边目录部分或者同时去除某个后缀的内容(目录的部分),然后返回剩下的部分(非目录的部分)
basename /etc/sysconfig/network-scripts/ifcfg-eth0
ifcfg-eth0
- dirname
功能
从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分)
dirname /etc/sysconfig/network-scripts/ifcfg-eth0
/etc/sysconfig/network-scripts
- chattr
用法:
chattr [ -RVf ] [ -v version ] [ mode ] files…
最关键的是在[mode]部分,[mode]部分是由+-=和[ASacDdIijsTtu]这些字符组合的,这部分是用来控制文件的
选项:
-R:递归处理,将指令目录下的所有文件及子目录一并处理;
-v<版本编号>:设置文件或目录版本;
-V:显示指令执行过程;
+<属性>:开启文件或目录的该项属性;
-<属性>:关闭文件或目录的该项属性;
=<属性>:指定文件或目录的该项属性。
属性
a:让文件或目录仅供附加用途;
b:不更新文件或目录的最后存取时间;
c:将文件或目录压缩后存放;
d:将文件或目录排除在倾倒操作之外;
i:不得任意更动文件或目录;
s:保密性删除文件或目录;
S:即时更新文件或目录;
u:预防意外删除。
各参数选项中常用到的是a和i。a选项强制只可添加不可删除,多用于日志系统的安全设定。而i是更为严格的安全设定,只有superuser (root) 或具有CAP_LINUX_IMMUTABLE处理能力(标识)的进程能够施加该选项。
范例
- 防止系统中某个关键文件被修改:
# chattr +i /etc/resolv.conf
然后用mv /etc/resolv.conf等命令操作于该文件,都是得到Operation not permitted 的结果。vim编辑该文件时会提示W10: Warning: Changing a readonly file错误。要想修改此文件就要把i属性去掉: chattr -i /etc/resolv.conf
lsattr /etc/resolv.conf
会显示如下属性
----i-------- /etc/resolv.conf
- 只能往里面追加数据,但不能删除,适用于各种日志文件:
chattr +a /var/log/messages
- lsattr
lsattr命令用于查看文件的第二扩展文件系统属性
-E:可显示设备属性的当前值,但这个当前值是从用户设备数据库中获得的,而不是从设备直接获得的
-D:显示属性的名称,属性的默认值,描述和用户是否可以修改属性值的标志。
-R:递归的操作方式;
-V:显示指令的版本信息;
-a:列出目录中的所有文件,包括隐藏文件。
lsattr经常使用的几个选项-D,-E,-R这三个选项不可以一起使用,它们是互斥的,经常使用的还有-l,-H,使用lsattr时,必须指出具体的设备名,用-l选项指出要显示设备的逻辑名称,否则要用-c,-s,-t等选项唯一的确定某个已存在的设备。
- md5sum
-b 以二进制模式读入内容
-t 以文本模式读入文件内容进行校验,虽然是不同的读入模式,但是在进行求md5的时候,是一样的,因为是逐位校验的
-c选项来对文件md5进行校验。校验时,根据已生成的md5来进行校验。生成当前文件的md5,并和之前已经生成的md5进行对比,如果一致,则返回OK,否则返回错误信息
- 文件压缩及解压缩命令(4)
- tar
语法:
tar [主选项+辅选项] 文件或者目录
介绍:
使用该命令时,主选项是必须要有的,它告诉tar要做什么事情,辅选项是辅助使用的,可以选用。
主选项:
c 创建新的档案文件。如果用户想备份一个目录或是一些文件,就要选择这个选项。相当于打包。
x 从档案文件中释放文件。相当于拆包。
t 列出档案文件的内容,查看已经备份了哪些文件。
特别注意,在参数的下达中, c/x/t 仅能存在一个!不可同时存在!因为不可能同时压缩与解压缩。
辅助选项:
-z :要用 gzip 压缩或解压。 一般格式为xx.tar.gz或xx. tgz
-j :要用 bzip2 压缩或解压。一般格式为xx.tar.bz2
-v :压缩的过程中显示文件!这个常用
-f :使用档名,请留意,在 f 之后要立即接档名喔!不要再加其他参数!
-p :使用原文件的原来属性(属性不会依据使用者而变)
--exclude FILE:在压缩的过程中,不要将 FILE 打包!
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
实例:
tar -cvf log.tar log2012.log 仅打包,不压缩!
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -jcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩
- 将整个 /etc 目录下的文件全部打包成为 /tmp/etc.tar
[root@linux ~]# tar -cvf /tmp/etc.tar /etc <==仅打包,不压缩!
[root@linux ~]# tar -zcvf /tmp/etc.tar.gz /etc <==打包后,以 gzip 压缩
[root@linux ~]# tar -jcvf /tmp/etc.tar.bz2 /etc <==打包后,以 bzip2 压缩
# 特别注意,在参数 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。
# 如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar file ~
# 如果加 j 参数,则以 .tar.bz2 来作为附档名啊~
# 上述指令在执行的时候,会显示一个警告讯息:
# 『tar: Removing leading `/" from member names』那是关於绝对路径的特殊设定。
- 查阅上述 /tmp/etc.tar.gz 文件内有哪些文件?
[root@linux ~]# tar -ztvf /tmp/etc.tar.gz
# 由於我们使用 gzip 压缩,所以要查阅该 tar file 内的文件时,
# 就得要加上 z 这个参数了!这很重要的!
- 将 /tmp/etc.tar.gz 文件解压缩在 /usr/local/src 底下
[root@linux ~]# cd /usr/local/src
[root@linux src]# tar -zxvf /tmp/etc.tar.gz
# 在预设的情况下,我们可以将压缩档在任何地方解开的!以这个范例来说
# 我先将工作目录变换到 /usr/local/src 底下,并且解开 /tmp/etc.tar.gz
# 则解开的目录会在 /usr/local/src/etc ,另外,如果您进入 /usr/local/src/etc
# 则会发现,该目录下的文件属性与 /etc/ 可能会有所不同喔!
- 在 /tmp 底下,我只想要将 /tmp/etc.tar.gz 内的 etc/passwd 解开而已
[root@linux ~]# cd /tmp
[root@linux tmp]# tar -zxvf /tmp/etc.tar.gz etc/passwd
# 我可以透过 tar -ztvf 来查阅 tarfile 内的文件名称,如果单只要一个文件,
# 就可以透过这个方式来下达!注意到! etc.tar.gz 内的根目录 / 是被拿掉了!
- 我要备份 /home, /etc ,但不要 /home/dmtsai
[root@linux ~]# tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
- 另外:tar命令的C参数
$ tar -cvf file2.tar /home/usr2/file2
该命令可以将/home/usr2/file2文件打包到当前目录下的file2.tar中,需要注意的是:使用绝对路径标识的源文件,在用tar命令压缩后,文件名连同绝对路径(这里是home/usr2/,根目录'/'被自动去掉了)一并被压缩进来。使用tar命令解压缩后会出现以下情况:
$ tar -xvf file2.tar
解压缩后的文件名不是想象中的file2,而是home/usr2/file2。
$ tar -cvf file2.tar -C /home/usr2 file2
该命令中的-C dir参数,将tar的工作目录从当前目录改为/home/usr2,将file2文件(不带绝对路径)压缩到file2.tar中。注意:-C dir参数的作用在于改变工作目录,其有效期为该命令中下一次-C dir参数之前。
使用tar的-C dir参数,同样可以做到在当前目录/home/usr1下将文件解压缩到其他目录,例如:
$ tar -xvf file2.tar -C /home/usr2
而tar不用-C dir参数时是无法做到的:
$ tar -xvf file2.tar /home/usr2
tar: /tmp/file: Not found in archive
tar: Error exit delayed from previous errors
- unzip
说明
unzip为.zip压缩文件的解压缩程序。
主要参数
-c 将解压缩的结果显示到屏幕上,并对字符做适当的转换
-p 与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换。
-l 显示压缩文件内所包含的文件
-f 更新现有的文件
-t 检查压缩文件是否正确,但不解压
-u 与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其他文件解压缩到目录中
-z 仅显示压缩文件的备注文字
-v 执行是时显示详细的信息。或查看压缩文件目录,但不解压
-T 将压缩文件内的所有文件的最新变动时间设为解压缩时候的时间
-x 指定不要处理.zip压缩文件中的哪些文件
-d 指定文件解压缩后所要存储的目录
-n 解压缩时不要覆盖原有的文件
-q 安静模式,执行时不显示任何信息
-o 不必先询问用户,unzip执行后覆盖原有文件
-a 对文本文件进行必要的字符转换
-j 不处理压缩文件中原有的目录路径
-aa 把所有的文件目录当作文本处理
-U use escapes for all non-ASCII Unicode
-UU 忽略Unicode编码字符
-C 压缩文件中的文件名称区分大小写
-L 将压缩文件中的全部文件名改为小写
-X 解压缩时同时回存文件原来的UID/GID
-V 保留VMS的文件版本信息
-K 保留文件的setuid/setgid/tacky属性
-M 将输出结果送到more程序处理
-O 指定字符编码为DOS,Windows和OS/2
-I 指定字符编码为UNIX
- 把文件解压到当前目录下
unzip test.zip
- 如果要把文件解压到指定的目录下,需要用到-d参数。
unzip -d /temp test.zip
- 压的时候,有时候不想覆盖已经存在的文件,那么可以加上-n参数
unzip -n test.zip
unzip -n -d /temp test.zip
- 只看一下zip压缩包中包含哪些文件,不进行解压缩
unzip -l test.zip
- 查看显示的文件列表还包含压缩比率
unzip -v test.zip
- 检查zip文件是否损坏
unzip -t test.zip
- 将压缩文件test.zip在指定目录tmp下解压缩,如果已有相同的文件存在,要求unzip命令覆盖原先的文件
unzip -o test.zip -d /tmp/
- gzip
减少文件大小有两个明显的好处,一是可以减少存储空间,二是通过网络传输文件时,可以减少传输的时间。gzip是在Linux系统中经常使用的一个对文件进行压缩和解压缩的命令,既方便又好用。gzip不仅可以用来压缩大的、较少使用的文件以节省磁盘空间,还可以和tar命令一起构成Linux操作系统中比较流行的压缩文件格式。据统计,gzip命令对文本文件有60%~70%的压缩率。
命令格式
gzip[参数][文件或者目录]
命令功能
gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出".gz"的扩展名。
命令参数:
-a或--ascii 使用ASCII文字模式。
-c或--stdout或--to-stdout 把压缩后的文件输出到标准输出设备,不去更动原始文件。
-d或--decompress或----uncompress 解开压缩文件。
-f或--force 强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接。
-h或--help 在线帮助。
-l或--list 列出压缩文件的相关信息。
-L或--license 显示版本与版权信息。
-n或--no-name 压缩文件时,不保存原来的文件名称及时间戳记。
-N或--name 压缩文件时,保存原来的文件名称及时间戳记。
-q或--quiet 不显示警告信息。
-r或--recursive 递归处理,将指定目录下的所有文件及子目录一并处理。
-S<压缩字尾字符串>或----suffix<压缩字尾字符串> 更改压缩字尾字符串。
-t或--test 测试压缩文件是否正确无误。
-v或--verbose 显示指令执行过程。
-V或--version 显示版本信息。
-num 用指定的数字num调整压缩的速度,-1或--fast表示最快压缩方法(低压缩比),-9或--best表示最慢压缩方法(高压缩比)。系统缺省值为6。
- 把test6目录下的每个文件压缩成.gz文件
[root@localhost test6]# ll
总计 604
---xr--r-- 1 root mail 302108 11-30 08:39 linklog.log
---xr--r-- 1 mail users 302108 11-30 08:39 log2012.log
-rw-r--r-- 1 mail users 61 11-30 08:39 log2013.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2014.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2015.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2016.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2017.log
[root@localhost test6]# gzip *
[root@localhost test6]# ll
总计 28
---xr--r-- 1 root mail 1341 11-30 08:39 linklog.log.gz
---xr--r-- 1 mail users 1341 11-30 08:39 log2012.log.gz
-rw-r--r-- 1 mail users 70 11-30 08:39 log2013.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2014.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2015.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2016.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2017.log.gz
- 把例1中每个压缩的文件解压,并列出详细的信息
gzip -dv *
ll
总计 28
---xr--r-- 1 root mail 1341 11-30 08:39 linklog.log.gz
---xr--r-- 1 mail users 1341 11-30 08:39 log2012.log.gz
-rw-r--r-- 1 mail users 70 11-30 08:39 log2013.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2014.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2015.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2016.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2017.log.gz
[root@localhost test6]# gzip -dv *
linklog.log.gz: 99.6% -- replaced with linklog.log
log2012.log.gz: 99.6% -- replaced with log2012.log
log2013.log.gz: 47.5% -- replaced with log2013.log
log2014.log.gz: 0.0% -- replaced with log2014.log
log2015.log.gz: 0.0% -- replaced with log2015.log
log2016.log.gz: 0.0% -- replaced with log2016.log
log2017.log.gz: 0.0% -- replaced with log2017.log
[root@localhost test6]# ll
总计 604
---xr--r-- 1 root mail 302108 11-30 08:39 linklog.log
---xr--r-- 1 mail users 302108 11-30 08:39 log2012.log
-rw-r--r-- 1 mail users 61 11-30 08:39 log2013.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2014.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2015.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2016.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2017.log
[root@localhost test6]#
- 详细显示例1中每个压缩的文件的信息,并不解压
gzip -l *
[root@localhost test6]# gzip -l *
compressed uncompressed ratio uncompressed_name
1341 302108 99.6% linklog.log
1341 302108 99.6% log2012.log
70 61 47.5% log2013.log
32 0 0.0% log2014.log
32 0 0.0% log2015.log
32 0 0.0% log2016.log
32 0 0.0% log2017.log
2880 604277 99.5% (totals)
- 压缩一个tar备份文件,此时压缩文件的扩展名为.tar.gz
gzip -r log.tar
[root@localhost test]# ls -al log.tar
-rw-r--r-- 1 root root 307200 11-29 17:54 log.tar
[root@localhost test]# gzip -r log.tar
[root@localhost test]# ls -al log.tar.gz
-rw-r--r-- 1 root root 1421 11-29 17:54 log.tar.gz
- 递归的压缩目录
gzip -rv test6
[root@localhost test6]# ll
总计 604
---xr--r-- 1 root mail 302108 11-30 08:39 linklog.log
---xr--r-- 1 mail users 302108 11-30 08:39 log2012.log
-rw-r--r-- 1 mail users 61 11-30 08:39 log2013.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2014.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2015.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2016.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2017.log
[root@localhost test6]# cd ..
[root@localhost test]# gzip -rv test6
test6/log2014.log: 0.0% -- replaced with test6/log2014.log.gz
test6/linklog.log: 99.6% -- replaced with test6/linklog.log.gz
test6/log2015.log: 0.0% -- replaced with test6/log2015.log.gz
test6/log2013.log: 47.5% -- replaced with test6/log2013.log.gz
test6/log2012.log: 99.6% -- replaced with test6/log2012.log.gz
test6/log2017.log: 0.0% -- replaced with test6/log2017.log.gz
test6/log2016.log: 0.0% -- replaced with test6/log2016.log.gz
[root@localhost test]# cd test6
[root@localhost test6]# ll
总计 28
---xr--r-- 1 root mail 1341 11-30 08:39 linklog.log.gz
---xr--r-- 1 mail users 1341 11-30 08:39 log2012.log.gz
-rw-r--r-- 1 mail users 70 11-30 08:39 log2013.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2014.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2015.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2016.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2017.log.gz
这样,所有test下面的文件都变成了*.gz,目录依然存在只是目录里面的文件相应变成了*.gz.这就是压缩,和打包不同。因为是对目录操作,所以需要加上-r选项,这样也可以对子目录进行递归了。
- 递归地解压目录
gzip -dr test6
[root@localhost test6]# ll
总计 28
---xr--r-- 1 root mail 1341 11-30 08:39 linklog.log.gz
---xr--r-- 1 mail users 1341 11-30 08:39 log2012.log.gz
-rw-r--r-- 1 mail users 70 11-30 08:39 log2013.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2014.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2015.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2016.log.gz
-rw-r--r-- 1 root mail 32 11-30 08:39 log2017.log.gz
[root@localhost test6]# cd ..
[root@localhost test]# gzip -dr test6
[root@localhost test]# cd test6
[root@localhost test6]# ll
总计 604
---xr--r-- 1 root mail 302108 11-30 08:39 linklog.log
---xr--r-- 1 mail users 302108 11-30 08:39 log2012.log
-rw-r--r-- 1 mail users 61 11-30 08:39 log2013.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2014.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2015.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2016.log
-rw-r--r-- 1 root mail 0 11-30 08:39 log2017.log
[root@localhost test6]#
- zip
基本用法是
zip [参数] [打包后的文件名] [打包的目录路径]
参数列表:
-a 将文件转成ASCII模式
-F 尝试修复损坏的压缩文件
-h 显示帮助界面
-m 将文件压缩之后,删除源文件
-n 特定字符串 不压缩具有特定字尾字符串的文件
-o 将压缩文件内的所有文件的最新变动时间设为压缩时候的时间
-q 安静模式,在压缩的时候不显示指令的执行过程
-r 将指定的目录下的所有子目录以及文件一起处理
-S 包含系统文件和隐含文件(S是大写)
-t 日期 把压缩文件的最后修改日期设为指定的日期,日期格式为mmddyyyy
- 将/home/Blinux/html/ 这个目录下所有文件和文件夹打包为当前目录下的html.zip
zip -q -r html.zip /home/Blinux/html
上面的命令操作是将绝对地址的文件及文件夹进行压缩.以下给出压缩相对路径目录
比如目前在Bliux这个目录下,执行以下操作可以达到以上同样的效果.
zip -q -r html.zip html
比如现在我的html目录下,我操作的zip压缩命令是
zip -q -r html.zip *
以上是在安静模式下进行的f,而且包含系统文件和隐含文件
zip命令可以用来将文件压缩成为常用的zip格式。
- 将一个文件abc.txt和一个目录dir1压缩成为yasuo.zip:
# zip -r yasuo.zip abc.txt dir1
我下载了一个yasuo.zip文件,想解压缩:
# unzip yasuo.zip
我当前目录下有abc1.zip,abc2.zip和abc3.zip,我想一起解压缩它们:
# unzip abc\?.zip
注释:?表示一个字符,如果用*表示任意多个字符。
4.我有一个很大的压缩文件large.zip,我不想解压缩,只想看看它里面有什么:
# unzip -v large.zip
5.我下载了一个压缩文件large.zip,想验证一下这个压缩文件是否下载完全了
# unzip -t large.zip
6.我用-v选项发现music.zip压缩文件里面有很多目录和子目录,并且子目录中其实都是歌曲mp3文件,我想把这些文件都下载到第一级目录,而不是一层一层建目录:
# unzip -j music.zip
- 总结
*.tar 用 tar -xvf 解压
*.gz 用 gzip -d或者gunzip 解压
*.tar.gz和*.tgz 用 tar –xzf 解压
*.bz2 用 bzip2 -d或者用bunzip2 解压
*.tar.bz2用tar –xjf 解压
*.Z 用 uncompress 解压
*.tar.Z 用tar –xZf 解压
*.rar 用 unrar e解压
*.zip 用 unzip 解压
- 信息显示命令(8)
- uname
功能说明
uname用来获取电脑和操作系统的相关信息。
语法
uname [-amnrsvpio][--help][--version]
补充说明
uname可显示linux主机所用的操作系统的版本、硬件的名称等基本信息。
参数:
-a或–all 详细输出所有信息,依次为内核名称,主机名,内核版本号,内核版本,硬件名,处理器类型,硬件平台类型,操作系统名称
-m或–machine 显示主机的硬件(CPU)名
-n或-nodename 显示主机在网络节点上的名称或主机名称
-r或–release 显示linux操作系统内核版本号
-s或–sysname 显示linux内核名称
-v 显示显示操作系统是第几个 version 版本
-p 显示处理器类型或unknown
-i 显示硬件平台类型或unknown
-o 显示操作系统名
–help 获得帮助信息
–version 显示uname版本信息
- hostname
hostname //显示主机名短格式,比如localhost;
参数:
-f //显示主机名的长格式,带域名,比如:localhost.localdomain
-d //显示域名,比如localdomain iv>.
-I //显示主机名对应的IP地址
-a //显示主机别名(alias),和hostname的输出结果一样, 比如localhost
-s //显示主机名的短格式,也就是从左边第一逗点前面部分
注意: 一定要让配置文件network中的hostname和hosts中的alias以及FQDN的第一部分一致,否则hostname -a -f -d -i命令不能正常工作。
- dmesg
功能说明:显示开机信息。主要应用:dmesg用来显示内核环缓冲区(kernel-ring buffer)内容,内核将各种消息存放在这里。在系统引导时,内核将与硬件和模块初始化相关的信息填到这个缓冲区中。内核环缓冲区中的消息对于诊断系统问题 通常非常有用。在运行dmesg时,它显示大量信息。通常通过less或grep使用管道查看dmesg的输出,这样可以更容易找到待查信息。例如,如果发现硬盘性能低下,可以使用dmesg来检查它们是否运行在DMA模式:dmesg | grep DMA
语法:
dmesg [-cn][-s ]
补充说明:
kernel会将开机信息存储在ring buffer中。您若是开机时来不及查看信息,可利用dmesg来查看。开机信息亦保存在/var/log目录中,名称为dmesg的文件里。
参数:
-c 显示信息后,清除ring buffer中的内容。
-s 预设置为8196,刚好等于ring buffer的大小。
-n 设置记录信息的层级。
- stat
在Linux中,没有文件创建时间的概念。只有文件的访问时间、修改时间、状态改变时间。也就是说不能知道文件的创建时间。但如果文件创建后就没有修改过,修改时间=创建时间;如果文件创建后,状态就没有改变过,那么状态改变时间=创建时间;如果文件创建后,没有被读取过,那么访问时间=创建时间,这个基本不太可能。
与文件相关的几个时间:
访问时间,读一次这个文件的内容,这个时间就会更新。比如对这个文件使用more命令。ls、stat命令都不会修改文件的访问时间。
修改时间,对文件内容修改一次,这个时间就会更新。比如:vi后保存文件。ls -l列出的时间就是这个时间。
状态改变时间。通过chmod命令更改一次文件属性,这个时间就会更新。查看文件的详细的状态、准确的修改时间等,可以通过stat命令文件名。
ls -lc filename 列出文件的 ctime (最后更改时间)
ls -lu filename 列出文件的 atime(最后存取时间)
ls -l filename 列出文件的 mtime (最后修改时间)
- du
对文件和目录磁盘使用的空间的查看
命令格式:
du [选项][文件]
命令功能:
显示每个文件和目录的磁盘使用空间。
命令参数:
-a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总计,只列出最后加总的值。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。
–max-depth=N 只列出深度小于max-depth的目录和文件的信息 –max-depth=0 的时候效果跟–s是 一样
–exclude=PATTERN 排除掉符合样式的文件,Pattern就是普通的Shell样式,?表示任何一个字符,*表示任意多个字符
- df
命令格式:
df [选项] [文件]
命令功能:
显示指定磁盘文件的可用空间。如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示
必要参数:
-a 全部文件系统列表
-h 方便阅读方式显示
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地文件系统
-m 区块为1048576字节
--no-sync 忽略 sync 命令
-P 输出格式为POSIX
--sync 在取得磁盘信息前,先执行sync命令
-T 文件系统类型
选择参数:
--block-size=<区块大小> 指定区块大小
-t<文件系统类型> 只显示选定文件系统的磁盘信息
-x<文件系统类型> 不显示选定文件系统的磁盘信息
--help 显示帮助信息
--version 显示版本信息
- date
命令格式:
date [参数]... [+格式]
命令功能:
date 可以用来显示或设定系统的日期与时间。
参数:<+时间日期格式>:指定显示时使用的日期时间格式。
日期格式字符串列表
%H 小时(以00-23来表示)。
%I 小时(以01-12来表示)。
%K 小时(以0-23来表示)。
%l 小时(以0-12来表示)。
%M 分钟(以00-59来表示)。
%P AM或PM。
%r 时间(含时分秒,小时以12小时AM/PM来表示)。
%s 总秒数。起算时间为1970-01-01 00:00:00 UTC。
%S 秒(以本地的惯用法来表示)。
%T 时间(含时分秒,小时以24小时制来表示)。
%X 时间(以本地的惯用法来表示)。
%Z 市区。
%a 星期的缩写。
%A 星期的完整名称。
%b 月份英文名的缩写。
%B 月份的完整英文名称。
%c 日期与时间。只输入date指令也会显示同样的结果。
%d 日期(以01-31来表示)。
%D 日期(含年月日)。
%j 该年中的第几天。
%m 月份(以01-12来表示)。
%U 该年中的周数。
%w 该周的天数,0代表周日,1代表周一,异词类推。
%x 日期(以本地的惯用法来表示)。
%y 年份(以00-99来表示)。
%Y 年份(以四位数来表示)。
%n 在显示时,插入新的一行。
%t 在显示时,插入tab。
MM 月份(必要)
DD 日期(必要)
hh 小时(必要)
mm 分钟(必要)
ss 秒(选择性)
选择参数:
-d<字符串> 显示字符串所指的日期与时间。字符串前后必须加上双引号。
-s<字符串> 根据字符串来设置日期与时间。字符串前后必须加上双引号。
-u 显示GMT。
--help 在线帮助。
--version 显示版本信息
使用说明:
1.在设定时间方面:
date -s //设置当前时间,只有root权限才能设置,其他只能查看。
date -s 20080523 //设置成20080523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 //设置具体时间,不会对日期做更改
date -s "01:01:01 2008-05-23" //这样可以设置全部时间
date -s "01:01:01 20080523" //这样可以设置全部时间
date -s "2008-05-23 01:01:01" //这样可以设置全部时间
date -s "20080523 01:01:01" //这样可以设置全部时间
2.加减操作:
date +%Y%m%d //显示前天年月日
date +%Y%m%d --date="+1 day" //显示前一天的日期
date +%Y%m%d --date="-1 day" //显示后一天的日期
date +%Y%m%d --date="-1 month" //显示上一月的日期
date +%Y%m%d --date="+1 month" //显示下一月的日期
date +%Y%m%d --date="-1 year" //显示前一年的日期
date +%Y%m%d --date="+1 year" //显示下一年的日期
使用实例:
实例1:显示当前时间
[root@localhost ~]# date
2012年 12月 08日 星期六 08:31:35 CST
[root@localhost ~]# date '+%c'
2012年12月08日 星期六 08时34分44秒
[root@localhost ~]# date '+%D'
12/08/12
[root@localhost ~]# date '+%x'
2012年12月08日
[root@localhost ~]# date '+%T'
08:35:36
[root@localhost ~]# date '+%X'
08时35分54秒
实例2:显示日期和设定时间
date --date 08:42:00
[root@localhost ~]# date '+%c'
2012年12月08日 星期六 08时41分37秒
[root@localhost ~]# date --date 08:42:00
2012年 12月 08日 星期六 08:42:00 CST
[root@localhost ~]# date '+%c' --date 08:45:00
2012年12月08日 星期六 08时45分00秒
实例3:date -d参数使用
[root@localhost ~]# date -d "nov 22"
2012年 11月 22日 星期四 00:00:00 CST
[root@localhost ~]# date -d '2 weeks'
2012年 12月 22日 星期六 08:50:21 CST
[root@localhost ~]# date -d 'next monday'
2012年 12月 10日 星期一 00:00:00 CST
[root@localhost ~]# date -d next-day +%Y%m%d
20121209
[root@localhost ~]# date -d tomorrow +%Y%m%d
20121209
[root@localhost ~]# date -d last-day +%Y%m%d
20121207
[root@localhost ~]# date -d yesterday +%Y%m%d
20121207
[root@localhost ~]# date -d last-month +%Y%m
201211
[root@localhost ~]# date -d next-month +%Y%m
201301
[root@localhost ~]# date -d '30 days ago'
2012年 11月 08日 星期四 08:51:37 CST
[root@localhost ~]# date -d '-100 days'
2012年 08月 30日 星期四 08:52:03 CST
[root@localhost ~]# date -d 'dec 14 -2 weeks'
2012年 11月 30日 星期五 00:00:00 CST
[root@localhost ~]# date -d '50 days'
2013年 01月 27日 星期日 08:52:27 CST
说明:
date 命令的另一个扩展是 -d 选项,该选项非常有用。使用这个功能强大的选项,通过将日期作为引号括起来的参数提供,您可以快速地查明一个特定的日期。-d 选项还可以告诉您,相对于当前日期若干天的究竟是哪一天,从现在开始的若干天或若干星期以后,或者以前(过去)。通过将这个相对偏移使用引号括起来,作为 -d 选项的参数,就可以完成这项任务。
具体说明如下:
date -d "nov 22" 今年的 11 月 22 日是星期三
date -d '2 weeks' 2周后的日期
date -d 'next monday' (下周一的日期)
date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
date -d last-month +%Y%m(上个月是几月)
date -d next-month +%Y%m(下个月是几月)
使用 ago 指令,您可以得到过去的日期:
date -d '30 days ago' (30天前的日期)
使用负数以得到相反的日期:
date -d 'dec 14 -2 weeks' (相对:dec 14这个日期的两周前的日期)
date -d '-100 days' (100天以前的日期)
date -d '50 days'(50天后的日期)
实例4:显示月份和日数
[root@localhost ~]# date '+%B %d'
十二月 08
实例5:显示时间后跳行,再显示目前日期
[root@localhost ~]# date '+%T%n%D'
09:00:30
12/08/12
- cal
cal命令可以用来显示公历(阳历)日历。公历是现在国际通用的历法,又称格列历,通称阳历。“阳历”又名“太阳历”,系以地球绕行太阳一周为一年,为西方各国所通用,故又名“西历”。
命令格式:
cal [参数][月份][年份]
命令功能:
用于查看日历等时间信息,如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份
命令参数:
-1 显示一个月的月历
-3 显示系统前一个月,当前月,下一个月的月历
-s 显示星期天为一个星期的第一天,默认的格式
-m 显示星期一为一个星期的第一天
-j 显示在当年中的第几天(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数)
-y 显示当前年份的日历
使用实例:
实例1:显示当前月份日历
[root@localhost ~]# cal
十二月 2012
日 一 二 三 四 五 六
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30 31
实例2:显示指定月份的日历
[root@localhost ~]# cal 9 2012
九月 2012
日 一 二 三 四 五 六
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30
实例3:显示2013年日历
cal -y 2013
实例4:显示自1月1日的天数
[root@localhost ~]# cal -j
十二月 2012
日 一 二 三 四 五 六
336
337 338 339 340 341 342 343
344 345 346 347 348 349 350
351 352 353 354 355 356 357
358 359 360 361 362 363 364
365 366
实例5:星期一显示在第一列
[root@localhost ~]# cal -m
十二月 2012
一 二 三 四 五 六 日
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
- 用户管理命令(10)
- useradd
useradd命令用来建立用户帐号和创建用户的起始目录,使用权限是终极用户。
格式
useradd [-d home] [-s shell] [-c comment] [-m [-k template]] [-f inactive] [-e expire ] [-p passwd] [-r] name
主要选项
-c:加上备注文字,备注文字保存在passwd的备注栏中。
-d:指定用户登入时的启始目录。
-D:变更预设值。
-e:指定账号的有效期限,缺省表示永久有效。
-f:指定在密码过期后多少天即关闭该账号。
-g:指定用户所属的起始群组。
-G:指定用户所属的附加群组。
-m:自动建立用户的登入目录。
-M:不要自动建立用户的登入目录。
-n:取消建立以用户名称为名的群组。
-r:建立系统账号。
-s:指定用户登入后所使用的shell。
-u:指定用户ID号。
说明
useradd可用来建立用户账号,他和adduser命令是相同的。账号建好之后,再用passwd设定账号的密码。使用useradd命令所建立的账号,实际上是保存在/etc/passwd文本文件中。
- 建立一个新用户账户,并设置ID:
useradd david -u 544
需要说明的是,设定ID值时尽量要大于500,以免冲突。因为Linux安装后会建立一些特别用户,一般0到499之间的值留给bin、mail这样的系统账号。
useradd oracle -g oinstall -G dba
新创建一个oracle用户,这初始属于oinstall组,且同时让他也属于dba组。
useradd tomcat -d /var/servlet/service -s /sbin/nologin
无法使用shell,且其用户目录至/var/servlet/service
- usermod
usermod命令用于修改用户的基本信息。usermod命令不允许你改变正在线上的使用者帐号名称。当usermod命令用来改变user id,必须确认这名user没在电脑上执行任何程序。你需手动更改使用者的crontab档。也需手动更改使用者的at工作档。采用NIS server须在server上更动相关的NIS设定。
-c<备注>:修改用户帐号的备注文字;
-d<登入目录>:修改用户登入时的目录;
-e<有效期限>:修改帐号的有效期限;
-f<缓冲天数>:修改在密码过期后多少天即关闭该帐号;
-g<群组>:修改用户所属的群组;
-G<群组>;修改用户所属的附加群组;
-l<帐号名称>:修改用户帐号名称;
-L:锁定用户密码,使密码无效;
-s<shell>:修改用户登入后所使用的shell;
-u<uid>:修改用户ID;
-U:解除密码锁定。
- userdel
userdel命令用于删除给定的用户,以及与用户相关的文件。若不加选项,则仅删除用户帐号,而不删除相关文件
-f:强制删除用户,即使用户当前已登录;
-r:删除用户的同时,删除与用户相关的所有文件。
- groupadd
Options:
-f, --force 强制建立已经存在的组(如果存在则返回成功)
-g, --gid GID 设置新建立组的识别码,0--499保留给系统服务,可以指定500以上的唯一数值(除非用--non-unique参数)。
-o, --non-unique 允许重复使用组识别码。
-p, --password PASSWORD 设置新组的密码
-r, --system 创建一个系统账号
- 新建立一个名为test的组
linux@cdyemail:~$ sudo groupadd test
linux@cdyemail:~$ cat /etc/group | grep test
test:x:1002:
注:/etc/group的格式
group name : password : GID : user lists
- 创建一个student组,并设置GID为2000
linux@cdyemail:~$ sudo groupadd --gid 2000 student
linux@cdyemail:~$ cat /etc/group | grep student
student:x:2000:
- 强制建立一个student组
由于student组已经存在,所以再次创建会出错
linux@cdyemail:~$ sudo groupadd student
groupadd: group 'student' already exists #提示student组已经存在。
linux@cdyemail:~$ sudo groupadd --force student #强制建立组
linux@cdyemail:~$ cat /etc/group | grep student
student:x:2000:
- 两个组用同一个GID
环境:student组的ID是 2000
linux@cdyemail:~$ sudo groupadd --non-unique --gid 2000 boy
linux@cdyemail:~$ cat /etc/group | grep 2000
student:x:2000:
boy:x:2000:
- passwd
passwd命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
passwd(选项)(参数)选项
-k, --keep-tokens keep non-expired authentication tokens
注:保留即将过期的用户在期满后能仍能使用;
-d, --delete delete the password for the named account (root only)
注:删除用户密码,仅能以root权限操作;
-l, --lock lock the named account (root only)
注:锁住用户无权更改其密码,仅能通过root权限操作;
-u, --unlock unlock the named account (root only)
注:解除锁定;
-f, --force force operation
注:强制操作;仅root权限才能操作;
-x, --maximum=DAYS maximum password lifetime (root only)
注:两次密码修正的最大天数,后面接数字;仅能root权限操作;
-n, --minimum=DAYS minimum password lifetime (root only)
注:两次密码修改的最小天数,后面接数字,仅能root权限操作;
-w, --warning=DAYS number of days warning users receives before password expiration
注:在距多少天提醒用户修改密码;仅能root权限操作;
-i, --inactive=DAYS number of days after password expiration when an account becomes disabled (root only)
注:在密码过期后多少天,用户被禁掉,仅能以root操作;
-S, --status report password status on the named account 注:查询用户的密码状态,仅能root用户操作;
--stdin read new tokens from stdin (root only)
知识扩展
与用户、组账户信息相关的文件
/etc/passwd、/etc/shadow 、/etc/group、/etc/gshadow
用户信息文件分析/etc/passwd(每项用:隔开)
jack:X:503:504:::/home/jack/:/bin/bash
jack //用户名
X //口令、密码
503 //用户id(0代表root、普通新建用户从500开始)
504 //所在组
: //描述
/home/jack/ //用户主目录
/bin/bash //用户缺省Shell组信息文件分析
例如:cat /etc/shadow 。
jack:$!$:???:13801:0:99999:7:*:*:
jack //组名
$!$ //被加密的口令
13801 //创建日期与今天相隔的天数
0 //口令最短位数
99999 //用户口令
7 //到7天时提醒
* //禁用天数
* //过期天数实例
如果是普通用户执行passwd只能修改自己的密码。如果新建用户后,要为新用户创建密码,则用passwd用户名,注意要以root用户的权限来创建。
比如我们让某个用户不能修改密码,可以用-l选项来锁定:
[root@localhost ~]# passwd -l linuxde //锁定用户linuxde不能更改密码;
Locking password for user linuxde.
passwd: Success //锁定成功;
[root@localhost ~]# passwd -d linuxde //清除linuxde用户密码;
Removing password for user linuxde.
passwd: Success //清除成功;
[root@localhost ~]# passwd -S linuxde //查询linuxde用户密码状态;
Empty password. //空密码,也就是没有密码;注意:当我们清除一个用户的密码时,登录时就无需密码,这一点要加以注意
- chage
chage命令是用来修改帐号和密码的有效期限。
语法:chage [选项] 用户名
选项:
-m:密码可更改的最小天数。为零时代表任何时候都可以更改密码。
-M:密码保持有效的最大天数。
-w:用户密码到期前,提前收到警告信息的天数。
-E:帐号到期的日期。过了这天,此帐号将不可用。
-d:上一次更改的日期。
-i:停滞时期。如果一个密码已过期这些天,那么此帐号将不可用。
-l:例出当前的设置。由非特权用户来确定他们的密码或帐号何时过期。
- id
显示用户的ID,以及所属群组的ID。
-g或--group 显示用户所属群组的ID。
-G或--groups 显示用户所属附加群组的ID。
-u或--user 显示用户ID
- su
su的作用是变更为其它使用者的身份,超级用户除外,需要键入该使用者的密码。
su命令与su - 命令有什么区别?
su 是切换到其他用户,但是不切换环境变量
su -是完整的切换到一个用户环境
- sudo
sudo的配置都记录在/etc/sudoers文件中,配置文件指明哪些用户可以执行哪些命令
sudo -h列出使用方法,退出。
sudo -V显示版本信息,并退出。
sudo -l列出当前用户可以执行的命令。只有在sudoers里的用户才能使用该选项
- visudo
编辑修改/etc/sudoers配置文件,为非根用户赋予一些合理的“权利”,让他们执行一些只有根用户或特许用户才能完成的任务,从而减少根用户的登陆次数和管理时间同时也提高了系统安全性
- 基础网络操作命令(15)
- telnet
telnet命令用于登录远程主机,对远程主机进行管理。telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh方式了。但仍然有很多别的系统可能采用了telnet方式来提供远程登录,因此弄清楚telnet客户端的使用方式仍是很有必要的。
语法:telnet(选项)(参数)
选项:
-8:允许使用8位字符资料,包括输入与输出;
-a:尝试自动登入远端系统;
-b<主机别名>:使用别名指定远端主机名称;
-c:不读取用户专属目录里的.telnetrc文件;
-d:启动排错模式;
-e<脱离字符>:设置脱离字符;
-E:滤除脱离字符;
-f:此参数的效果和指定"-F"参数相同;
-F:使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机;
-k<域名>:使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名;
-K:不自动登入远端主机;
-l<用户名称>:指定要登入远端主机的用户名称;
-L:允许输出8位字符资料;
-n<记录文件>:指定文件记录相关信息;
-r:使用类似rlogin指令的用户界面;
-S<服务类型>:设置telnet连线所需的ip TOS信息;
-x:假设主机有支持数据加密的功能,就使用它;
-X<认证形态>:关闭指定的认证形态。
参数
远程主机:指定要登录进行管理的远程主机;
端口:指定TELNET协议使用的端口号。
实例:
telnet 192.168.2.10 Trying 192.168.2.10...
Connected to 192.168.2.10 (192.168.2.10).
Escape character is '^]'.
localhost (Linux release 2.6.18-274.18.1.el5 #1 SMP Thu Feb 9 12:45:44 EST 2012) (1)
login: root
Password:
Login incorrect
- ssh
选项:
-1:强制使用ssh协议版本1;
-2:强制使用ssh协议版本2;
-4:强制使用IPv4地址;
-6:强制使用IPv6地址;
-A:开启认证代理连接转发功能;
-a:关闭认证代理连接转发功能;
-b:使用本机指定地址作为对应连接的源ip地址;
-C:请求压缩所有数据;
-F:指定ssh指令的配置文件;
-f:后台执行ssh指令;
-g:允许远程主机连接主机的转发端口;
-i:指定身份文件;
-l:指定连接远程服务器登录用户名;
-N:不执行远程指令;
-o:指定配置选项;
-p:指定远程服务器上的端口;
-q:静默模式;
-X:开启X11转发功能;
-x:关闭X11转发功能;
-y:开启信任X11转发功能。
参数
远程主机:指定要连接的远程ssh服务器;
指令:要在远程ssh服务器上执行的指令。
- scp
scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影响一下速度。当你服务器硬盘变为只读read only system时,用scp可以帮你把文件移出来。另外,scp还非常不占资源,不会提高多少系统负荷,在这一点上,rsync就远远不及它了。虽然 rsync比scp会快一点,但当小文件众多的情况下,rsync会导致硬盘I/O非常高,而scp基本不影响系统正常使用。
选项:
-1:使用ssh协议版本1;
-2:使用ssh协议版本2;
-4:使用ipv4;
-6:使用ipv6;
-B:以批处理模式运行;
-C:使用压缩;
-F:指定ssh配置文件;
-l:指定宽带限制;
-o:指定使用的ssh选项;
-P:指定远程主机的端口号;
-p:保留文件的最后修改时间,最后访问时间和权限模式;
-q:不显示复制进度;
-r:以递归方式复制。
实例:
推:scp -P22 -rp /data/ root@192.168.80.101:/tmp #推data/整个目录
拉:scp -P22 -rp root@192.168.80.101:/tmp/ /data #拉tmp/整个目录
- wget
wget简单实例
1、下载整个http或者ftp站点。
wget http://place.your.url/here
这个命令可以将http://place.your.url/here 首页下载下来。使用-x会强制建立服务器上一模一样的目录,如果使用-nd参数,那么服务器上下载的所有内容都会加到本地当前目录。
wget -r http://place.your.url/here
这 个命令会按照递归的方法,下载服务器上所有的目录和文件,实质就是下载整个网站。这个命令一定要小心使用,因为在下载的时候,被下载网站指向的所有地址同 样会被下载,因此,如果这个网站引用了其他网站,那么被引用的网站也会被下载下来!基于这个原因,这个参数不常用。可以用-l number参数来指定下载的层次。例如只下载两层,那么使用-l 2。
要是您想制作镜像站点,那么可以使用-m参数,例如:wget -m http://place.your.url/here。这时wget会自动判断合适的参数来制作镜像站点。此时,wget会登录到服务器上,读入robots.txt并按robots.txt的规定来执行。
2、断点续传。
当文件特别大或者网络特别慢的时候,往往一个文件还没有下载完,连接就已经被切断,此时就需要断点续传。wget的断点续传是自动的,只需要使用-c参数,例如:
wget -c http://the.url.of/incomplete/file
使用断点续传要求服务器支持断点续传。-t参数表示重试次数,例如需要重试100次,那么就写-t 100,如果设成-t 0,那么表示无穷次重试,直到连接成功。-T参数表示超时等待时间,例如-T 120,表示等待120秒连接不上就算超时。
3、批量下载。
如果有多个文件需要下载,那么可以生成一个文件,把每个文件的URL写一行,例如生成文件download.txt,然后用命令:wget -i download.txt
这样就会把download.txt里面列出的每个URL都下载下来。(如果列的是文件就下载文件,如果列的是网站,那么下载首页)
4、选择性的下载。
可以指定让wget只下载一类文件,或者不下载什么文件。例如:
wget -m --reject=gif http://target.web.site/subdirectory
表示下载http://target.web.site/subdirectory,但是忽略gif文件。--accept=LIST 可以接受的文件类型,--reject=LIST拒绝接受的文件类型。
5、密码和认证。
wget只能处理利用用户名/密码方式限制访问的网站,可以利用两个参数:
--http-user=USER设置HTTP用户
--http-passwd=PASS设置HTTP密码
对于需要证书做认证的网站,就只能利用其他下载工具了,例如curl。
6、利用代理服务器进行下载。
如果用户的网络需要经过代理服务器,那么可以让wget通过代理服务器进行文件的下载。此时需要在当前用户的目录下创建一个.wgetrc文件。文件中可以设置代理服务器:
http-proxy = 111.111.111.111:8080
ftp-proxy = 111.111.111.111:8080
分别表示http的代理服务器和ftp的代理服务器。如果代理服务器需要密码则使用:
--proxy-user=USER设置代理用户
--proxy-passwd=PASS设置代理密码
这两个参数。
使用参数--proxy=on/off 使用或者关闭代理。
wget还有很多有用的功能,需要用户去挖掘。
- ping
ping命令用来测试主机之间网络的连通性。执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。
-a将地址解析为计算机名。
-d 使用Socket的SO_DEBUG功能。
-c<完成次数> 设置完成要求回应的次数。
-f 极限检测。
-i<间隔秒数> 指定收发信息的间隔时间。
-I<网络界面> 使用指定的网络界面送出数据包。
-l<前置载入> 设置在送出要求信息之前,先行发出的数据包。
-n 只输出数值。
-p<范本样式> 设置填满数据包的范本样式。
-q 不显示指令执行过程,开头和结尾的相关信息除外。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-R 记录路由过程。
-s<数据包大小> 设置数据包的大小。
-t<存活数值> 设置生存时间TTL的大小。
-v 详细显示指令的执行过程。
- route
语法:
[root@linux ~]# route [-nee]
[root@linux ~]# route add [-net|-host] [网域或主机] netmask [mask] [gw|dev]
[root@linux ~]# route del [-net|-host] [网域或主机] netmask [mask] [gw|dev]
命令参数
-n :不要使用通讯协定或主机名称,直接使用 IP 或 port number;
-ee :使用更详细的资讯来显示
增加 (add) 与删除 (del) 路由的相关参数:
-net :表示后面接的路由为一个网域;
-host :表示后面接的为连接到单部主机的路由;
netmask :与网域有关,可以设定 netmask 决定网域的大小;
gw :gateway 的简写,后续接的是 IP 的数值喔,与 dev 不同;
dev :如果只是要指定由那一块网路卡连线出去,则使用这个设定,后面接 eth0 等
- ifconfig
命令格式:
ifconfig [网络设备] [参数]
命令功能:
ifconfig 命令用来查看和配置网络设备。当网络环境发生改变时可通过此命令对网络进行相应的配置。
命令参数:
up 启动指定网络设备/网卡。
down 关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除。
arp 设置指定网卡是否支持ARP协议。
-promisc 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包
-allmulti 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包
-a 显示全部接口信息
-s 显示摘要信息(类似于 netstat -i)
add 给指定网卡配置IPv6地址
del 删除指定网卡的IPv6地址
<硬件地址> 配置网卡最大的传输单元
mtu<字节数> 设置网卡的最大传输单元 (bytes)
netmask<子网掩码> 设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码。
tunel 建立隧道
dstaddr 设定一个远端地址,建立点对点通信
-broadcast<地址> 为指定网卡设置广播协议
-pointtopoint<地址> 为网卡设置点对点通讯协议
multicast 为网卡设置组播标志
address 为网卡设置IPv4地址
txqueuelen<长度> 为网卡设置传输列队的长度
实例:
1.启动关闭某个网卡
ifconfig eth0 up
ifconfig eth0 down
2. 为网卡配置和删除IPv6地址
ifconfig eth0 add 33ffe:3240:800:1005::2/64
ifconfig eth0 del 33ffe:3240:800:1005::2/64
3.用ifconfig修改MAC地址
ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE
4.配置IP地址
ifconfig eth0 192.168.120.56
ifconfig eth0 192.168.120.56 netmask 255.255.255.0
ifconfig eth0 192.168.120.56 netmask 255.255.255.0 broadcast 192.168.120.255
5.启用和关闭ARP协议
ifconfig eth0 arp
ifconfig eth0 -arp
6.设置最大传输单元
ifconfig eth0 mtu 1500
- ifup /ifdown
ifup和ifdown仅能就/etc/sysconfig/network-scripts内的ifcfg-ethx(x为数字)进行启动或关闭,并不能直接修改网络的参数,除非手动的调整ifcfg-ethx文件才行。
功能:启用与停止网卡配置
实例:
[root@localhost init.d]# ifup eth0
[root@localhost init.d]# ifdown eth0
- netstat
Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
常用选项:
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
- nmap
nmap命令使用方法请查看《namp》参考指南
- lsof
lsof命令用于查看你进程开打的文件,打开文件的进程,进程打开的端口(TCP、UDP)。找回/恢复删除的文件。是十分方便的系统监视工具,因为lsof命令需要访问核心内存和各种文件,所以需要root用户执行。
在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
输出信息含义
在终端下输入lsof即可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
[root@VM_3_226_centos ~]# lsof
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
init 1 root cwd DIR 8,1 4096 2 /
init 1 root rtd DIR 8,1 4096 2 /
init 1 root txt REG 8,1 150584 654127 /sbin/init
udevd 415 root 0u CHR 1,3 0t0 6254 /dev/null
udevd 415 root 1u CHR 1,3 0t0 6254 /dev/null
udevd 415 root 2u CHR 1,3 0t0 6254 /dev/null
udevd 690 root mem REG 8,1 51736 302589 /lib/x86_64-linux-gnu/libnss_files-2.13.so
syslogd 1246 syslog 2w REG 8,1 10187 245418 /var/log/auth.log
syslogd 1246 syslog 3w REG 8,1 10118 245342 /var/log/syslog
dd 1271 root 0r REG 0,3 0 4026532038 /proc/kmsg
dd 1271 root 1w FIFO 0,15 0t0 409 /run/klogd/kmsg
dd 1271 root 2u CHR 1,3 0t0 6254 /dev/null
每行显示一个打开的文件,若不指定条件默认将显示所有进程打开的所有文件
lsof输出各列信息的意义如下:
- COMMAND:进程的名称 PID:进程标识符
- USER:进程所有者
- FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等 TYPE:文件类型,如DIR、REG等
- DEVICE:指定磁盘的名称
- SIZE:文件的大小
- NODE:索引节点(文件在磁盘上的标识)
- NAME:打开文件的确切名称
常用参数
lsof abc.txt 显示开启文件abc.txt的进程
lsof -c abc 显示abc进程现在打开的文件
lsof -c -p 1234 列出进程号为1234的进程所打开的文件
lsof -g gid 显示归属gid的进程情况
lsof +d /usr/local/ 显示目录下被进程开启的文件
lsof +D /usr/local/ 同上,但是会搜索目录下的目录,时间较长
lsof -d 4 显示使用fd为4的进程
lsof -i 用以显示符合条件的进程情况
lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
46 --> IPv4 or IPv6
protocol --> TCP or UDP
hostname --> Internet host name
hostaddr --> IPv4地址
service --> /etc/service中的 service name (可以不止一个)
port --> 端口号 (可以不止一个)
lsof使用实例
1.查找谁在使用文件系统
在卸载文件系统时,如果该文件系统中有任何打开的文件,操作通常将会失败。那么通过lsof可以找出那些进程在使用当前要卸载的文件系统,如下:
# lsof /GTES11/
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 4208 root cwd DIR 3,1 4096 2 /GTES11/
vim 4230 root cwd DIR 3,1 4096 2 /GTES11/
在这个示例中,用户root正在其/GTES11目录中进行一些操作。一个 bash是实例正在运行,并且它当前的目录为/GTES11,另一个则显示的是vim正在编辑/GTES11下的文件。要成功地卸载/GTES11,应该在通知用户以确保情况正常之后,中止这些进程。 这个示例说明了应用程序的当前工作目录非常重要,因为它仍保持着文件资源,并且可以防止文件系统被卸载。这就是为什么大部分守护进程(后台进程)将它们的目录更改为根目录、或服务特定的目录(如 sendmail 示例中的 /var/spool/mqueue)的原因,以避免该守护进程阻止卸载不相关的文件系统。
2.恢复删除的文件
当Linux计算机受到入侵时,常见的情况是日志文件被删除,以掩盖攻击者的踪迹。管理错误也可能导致意外删除重要的文件,比如在清理旧日志时,意外地删除了数据库的活动事务日志。有时可以通过lsof来恢复这些文件。
当进程打开了某个文件时,只要该进程保持打开该文件,即使将其删除,它依然存在于磁盘中。这意味着,进程并不知道文件已经被删除,它仍然可以向打开该文件时提供给它的文件描述符进行读取和写入。除了该进程之外,这个文件是不可见的,因为已经删除了其相应的目录索引节点。
在/proc 目录下,其中包含了反映内核和进程树的各种文件。/proc目录挂载的是在内存中所映射的一块区域,所以这些文件和目录并不存在于磁盘中,因此当我们对这些文件进行读取和写入时,实际上是在从内存中获取相关信息。大多数与 lsof 相关的信息都存储于以进程的 PID 命名的目录中,即 /proc/1234 中包含的是 PID 为 1234 的进程的信息。每个进程目录中存在着各种文件,它们可以使得应用程序简单地了解进程的内存空间、文件描述符列表、指向磁盘上的文件的符号链接和其他系统信息。lsof 程序使用该信息和其他关于内核内部状态的信息来产生其输出。所以lsof 可以显示进程的文件描述符和相关的文件名等信息。也就是我们通过访问进程的文件描述符可以找到该文件的相关信息。
当系统中的某个文件被意外地删除了,只要这个时候系统中还有进程正在访问该文件,那么我们就可以通过lsof从/proc目录下恢复该文件的内容。 假如由于误操作将/var/log/messages文件删除掉了,那么这时要将/var/log/messages文件恢复的方法如下:
首先使用lsof来查看当前是否有进程打开/var/logmessages文件,如下:
# lsof |grep /var/log/messages
syslogd 1283 root 2w REG 3,3 5381017 1773647 /var/log/messages (deleted)
从上面的信息可以看到 PID 1283(syslogd)打开文件的文件描述符为 2。同时还可以看到/var/log/messages已经标记被删除了。因此我们可以在 /proc/1283/fd/2 (fd下的每个以数字命名的文件表示进程对应的文件描述符)中查看相应的信息,如下:
# head -n 10 /proc/1283/fd/2
Aug 4 13:50:15 holmes86 syslogd 1.4.1: restart.
Aug 4 13:50:15 holmes86 kernel: klogd 1.4.1, log source = /proc/kmsg started.
Aug 4 13:50:15 holmes86 kernel: Linux version 2.6.22.1-8 (root@everestbuilder.linux-ren.org) (gcc version 4.2.0) #1 SMP Wed Jul 18 11:18:32 EDT 2007 Aug 4 13:50:15 holmes86 kernel: BIOS-provided physical RAM map: Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000000000 - 000000000009f000 (usable) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000000009f000 - 00000000000a0000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000100000 - 000000001f7d3800 (usable) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000001f7d3800 - 0000000020000000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000e0000000 - 00000000f0007000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000f0008000 - 00000000f000c000 (reserved)
从上面的信息可以看出,查看 /proc/8663/fd/15 就可以得到所要恢复的数据。如果可以通过文件描述符查看相应的数据,那么就可以使用 I/O 重定向将其复制到文件中,如:
cat /proc/1283/fd/2 > /var/log/messages
对于许多应用程序,尤其是日志文件和数据库,这种恢复删除文件的方法非常有用。
- nslookup
nslookup命令是常用域名查询工具,就是查DNS信息用的命令。nslookup4有两种工作模式,即“交互模式”和“非交互模式”。在“交互模式”下,用户可以向域名服务器查询各类主机、域名的信息,或者输出域名中的主机列表。而在“非交互模式”下,用户可以针对一个主机或域名仅仅获取特定的名称或所需信息。
实例1: 将域名解析成IP地址
Nslookup 域名
Nslookup set qt=a 域名
如果我们需要指定一台DNS服务器进行域名解析,可以采用如下格式
Nslookup 域名 DNS Server地址
如: nslookup www.163.com 202.96.64.68 (大连DNS server)
实例2:反向解析,由IP地址,解析域名
格式:Nslookup –qt=ptr 192.168.1.45 或
nslookup回车
set qt=PTR回车
192.168.1.45回车
注意qt必须小写
实例3:查询邮件服务器信息
域管理员有时想查看域内邮件服务器的信息, 可以通过如下命令:
格式:Nslookup –qt=mx www.163.com
通过此命令可以查看域对应的邮件服务器的IP列表(如果是多个邮件服务器),及对应基本级别perference, 其中数字越小,优先级别越高。
实例四:查看命名服务器NS
NS就是一个域名对应多个服务器,由哪个服务器对域名及附属记录进行解析.
格式:nslookup –qt=ns www.test.com
实例五:查看DNS缓存记录的保存时间
格式:Nslookup –d3 test.com
ttl 即为缓存保留的时间
- dig
查看域名的A记录
[root@VM_3_226_centos scripts]# dig www.baidu.com
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6_7.6 <<>> www.baidu.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 60682
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;www.baidu.com. IN A
;; ANSWER SECTION:
www.baidu.com. 474 IN CNAME www.a.shifen.com.
www.a.shifen.com. 254 IN A 220.181.112.244
www.a.shifen.com. 254 IN A 220.181.111.188
;; Query time: 0 msec
;; SERVER: 10.53.216.182#53(10.53.216.182)
;; WHEN: Sat Nov 5 14:43:40 2016
;; MSG SIZE rcvd: 90
查看域名的ip
[root@VM_3_226_centos scripts]# dig www.baidu.com +short
www.a.shifen.com.
220.181.111.188
220.181.112.244
查看域名的mx记录
[root@VM_3_226_centos scripts]# dig www.baidu.com mx
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6_7.6 <<>> www.baidu.com mx
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40633
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;www.baidu.com. IN MX
;; ANSWER SECTION:
www.baidu.com. 38 IN CNAME www.a.shifen.com.
;; AUTHORITY SECTION:
a.shifen.com. 185 IN SOA ns1.a.shifen.com. baidu_dns_master.baidu.com. 1611030006 5 5 86400 3600
;; Query time: 25 msec
;; SERVER: 10.53.216.182#53(10.53.216.182)
;; WHEN: Sat Nov 5 14:46:36 2016
;; MSG SIZE rcvd: 115
查看域名的SOA记录、TTL记录同mx记录在命令之后加soa、ttl
- host
host命令是常用的分析域名查询工具,可以用来测试域名系统工作是否正常。
语法:host(选项)(参数)
选项:
-a:显示详细的DNS信息;
-c<类型>:指定查询类型,默认值为“IN“;
-C:查询指定主机的完整的SOA记录;
-r:在查询域名时,不使用递归的查询方式;
-t<类型>:指定查询的域名信息类型;
-v:显示指令执行的详细信息;
-w:如果域名服务器没有给出应答信息,则总是等待,直到域名服务器给出应答;
-W<时间>:指定域名查询的最长时间,如果在指定时间内域名服务器没有给出应答信息,则退出指令;
-4:使用IPv4;
-6:使用IPv6.
参数:
主机:指定要查询信息的主机信息。
实例1:
[root@localhost ~]# host www.linuxde.net
www.linuxde.net is an alias for host.1.linuxde.net.
host.1.linuxde.net has address 100.42.212.8
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。linux系统中,我们称之为traceroute,在MS Windows中为tracert。traceroute通过发送小的数据包到目的设备直到其返回,来测量其需要多长时间。一条路径上的每个设备traceroute要测3次。输出结果中包括每次测试的时间(ms)和设备的名称(如有的话)及其IP地址。
在大多数情况下,我们会在linux主机系统下,直接执行命令行:
traceroute hostname
而在Windows系统下是执行tracert的命令:
tracert hostname
命令功能:
traceroute指令让你追踪网络数据包的路由途径,预设数据包大小是40Bytes,用户可另行设置。
具体参数格式:traceroute [-dFlnrvx][-f<存活数值>][-g<网关>...][-i<网络界面>][-m<存活数值>][-p<通信端口>][-s<来源地址>][-t<服务类型>][-w<超时秒数>][主机名称或IP地址][数据包大小]
命令参数:
-d 使用Socket层级的排错功能。
-f 设置第一个检测数据包的存活数值TTL的大小。
-F 设置勿离断位。
-g 设置来源路由网关,最多可设置8个。
-i 使用指定的网络界面送出数据包。
-I 使用ICMP回应取代UDP资料信息。
-m 设置检测数据包的最大存活数值TTL的大小。
-n 直接使用IP地址而非主机名称。
-p 设置UDP传输协议的通信端口。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-s 设置本地主机送出数据包的IP地址。
-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程。
-w 设置等待远端主机回报的时间。
-x 开启或关闭数据包的正确性检验。
- 磁盘文件系统的命令(8)
- curl
在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具。
语法:# curl [option] [url]
- -A/--user-agent <string> 设置用户代理发送给服务器
- -b/--cookie <name=string/file> cookie字符串或文件读取位置
- -c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中
- -C/--continue-at <offset> 断点续转
- -D/--dump-header <file> 把header信息写入到该文件中
- -e/--referer 来源网址
- -f/--fail 连接失败时不显示http错误
- -o/--output 把输出写到该文件中
- -O/--remote-name 把输出写到该文件中,保留远程文件的文件名
- -r/--range <range> 检索来自HTTP/1.1或FTP服务器字节范围
- -s/--silent 静音模式。不输出任何东西
- -T/--upload-file <file> 上传文件
- -u/--user <user[:password]> 设置服务器的用户和密码
- -w/--write-out [format] 什么输出完成后
- -x/--proxy <host[:port]> 在给定的端口上使用HTTP代理
- -#/--progress-bar 进度条显示当前的传送状态
其他参数:
- -a/--append 上传文件时,附加到目标文件
- --anyauth 可以使用“任何”身份验证方法
- --basic 使用HTTP基本验证
- -B/--use-ascii 使用ASCII文本传输
- -d/--data <data> HTTP POST方式传送数据
- --data-ascii <data> 以ascii的方式post数据
- --data-binary <data> 以二进制的方式post数据
- --negotiate 使用HTTP身份验证
- --digest 使用数字身份验证
- --disable-eprt 禁止使用EPRT或LPRT
- --disable-epsv 禁止使用EPSV
- --egd-file <file> 为随机数据(SSL)设置EGD socket路径
- --tcp-nodelay 使用TCP_NODELAY选项
- -E/--cert <cert[:passwd]> 客户端证书文件和密码 (SSL)
- --cert-type <type> 证书文件类型 (DER/PEM/ENG) (SSL)
- --key <key> 私钥文件名 (SSL)
- --key-type <type> 私钥文件类型 (DER/PEM/ENG) (SSL)
- --pass <pass> 私钥密码 (SSL)
- --engine <eng> 加密引擎使用 (SSL). "--engine list" for list
- --cacert <file> CA证书 (SSL)
- --capath <directory> CA目(made using c_rehash) to verify peer against (SSL)
- --ciphers <list> SSL密码
- --compressed 要求返回是压缩的形势 (using deflate or gzip)
- --connect-timeout <seconds> 设置最大请求时间
- --create-dirs 建立本地目录的目录层次结构
- --crlf 上传是把LF转变成CRLF
- --ftp-create-dirs 如果远程目录不存在,创建远程目录
- --ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
- --ftp-pasv 使用 PASV/EPSV 代替端口
- --ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
- --ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
- --ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
- -F/--form <name=content> 模拟http表单提交数据
- -form-string <name=string> 模拟http表单提交数据
- -g/--globoff 禁用网址序列和范围使用{}和[]
- -G/--get 以get的方式来发送数据
- -h/--help 帮助
- -H/--header <line> 自定义头信息传递给服务器
- --ignore-content-length 忽略的HTTP头信息的长度
- -i/--include 输出时包括protocol头信息
- -I/--head 只显示文档信息
- -j/--junk-session-cookies 读取文件时忽略session cookie
- --interface <interface> 使用指定网络接口/地址
- --krb4 <level> 使用指定安全级别的krb4
- -k/--insecure 允许不使用证书到SSL站点
- -K/--config 指定的配置文件读取
- -l/--list-only 列出ftp目录下的文件名称
- --limit-rate <rate> 设置传输速度
- --local-port<NUM> 强制使用本地端口号
- -m/--max-time <seconds> 设置最大传输时间
- --max-redirs <num> 设置最大读取的目录数
- --max-filesize <bytes> 设置最大下载的文件总量
- -M/--manual 显示全手动
- -n/--netrc 从netrc文件中读取用户名和密码
- --netrc-optional 使用 .netrc 或者 URL来覆盖-n
- --ntlm 使用 HTTP NTLM 身份验证
- -N/--no-buffer 禁用缓冲输出
- -p/--proxytunnel 使用HTTP代理
- --proxy-anyauth 选择任一代理身份验证方法
- --proxy-basic 在代理上使用基本身份验证
- --proxy-digest 在代理上使用数字身份验证
- --proxy-ntlm 在代理上使用ntlm身份验证
- -P/--ftp-port <address> 使用端口地址,而不是使用PASV
- -Q/--quote <cmd> 文件传输前,发送命令到服务器
- --range-file 读取(SSL)的随机文件
- -R/--remote-time 在本地生成文件时,保留远程文件时间
- --retry <num> 传输出现问题时,重试的次数
- --retry-delay <seconds> 传输出现问题时,设置重试间隔时间
- --retry-max-time <seconds> 传输出现问题时,设置最大重试时间
- -S/--show-error 显示错误
- --socks4 <host[:port]> 用socks4代理给定主机和端口
- --socks5 <host[:port]> 用socks5代理给定主机和端口
- -t/--telnet-option <OPT=val> Telnet选项设置
- --trace <file> 对指定文件进行debug
- --trace-ascii <file> Like --跟踪但没有hex输出
- --trace-time 跟踪/详细输出时,添加时间戳
- --url <URL> Spet URL to work with
- -U/--proxy-user <user[:password]> 设置代理用户名和密码
- -V/--version 显示版本信息
- -X/--request <command> 指定什么命令
- -y/--speed-time 放弃限速所要的时间。默认为30
- -Y/--speed-limit 停止传输速度的限制,速度时间'秒
- -z/--time-cond 传送时间设置
- -0/--http1.0 使用HTTP 1.0
- -1/--tlsv1 使用TLSv1(SSL)
- -2/--sslv2 使用SSLv2的(SSL)
- -3/--sslv3 使用的SSLv3(SSL)
- --3p-quote like -Q for the source URL for 3rd party transfer
- --3p-url 使用url,进行第三方传送
- --3p-user 使用用户名和密码,进行第三方传送
- -4/--ipv4 使用IP4
- -6/--ipv6 使用IP6
例子:
1、基本用法
curl http://www.linux.com #执行后,www.linux.com 的html就会显示在屏幕上了
2. 保存访问的网页
curl http://www.linux.com >> linux.html #使用linux的重定向功能保存
curl -o linux.html http://www.linux.com # curl的内置option:-o(小写)保存网页
curl -O https://www.cnblogs.com/duhuo/p/5695256.html #保存网页中的文件
3.测试网页返回值
curl -o /dev/null -s -w %{http_code} www.linux.com
4.指定proxy服务器以及其端口
curl -x 192.168.100.100:1080 http://www.linux.com
5. cookie
curl -c cookiec.txt http://www.linux.com #保存http的response里面的cookie信息
curl -D cookied.txt http://www.linux.com #保存http的response里面的header信息
6.使用cookie
curl -b cookiec.txt http://www.linux.com
7.模仿浏览器
curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
8.伪造referer(盗链)
curl -e "www.linux.com" http://mail.linux.com
9.发送post请求
curl 'https://oapi.dingtalk.com/robot/send?access_token=1bbc5c55254febc5205b08fd21eff82d036f7cfa8fc17b66c30c8cf3a05c904a' \
-H 'Content-Type: application/json' \
-d '
{"msgtype": "text",
"text": {
"content": "我就是我, 是不一样的烟火"
}
}'
- mount
语法:mount [-参数] [设备名称] [挂载点]
常见参数:
-a 安装在/etc/fstab文件中类出的所有文件系统。
-f 伪装mount,作出检查设备和目录的样子,但并不真正挂载文件系统。
-n 不把安装记录在/etc/mtab 文件中。
-r 讲文件系统安装为只读。
-v 详细显示安装信息。
-w 将文件系统安装为可写,为命令默认情况。
-t 指定设备的文件系统类型,常见的有:
ext2 linux目前常用的文件系统
msdos MS-DOS的fat,就是fat16
vfat windows98常用的fat32
nfs 网络文件系统
iso9660 CD-ROM光盘标准文件系统
ntfs windows NT/2000/XP的文件系统
auto 自动检测文件系统
-o 指定挂载文件系统时的选项,有些也可写到在/etc/fstab中。常用的有:
defaults 使用所有选项的默认值(auto、nouser、rw、suid)
auto/noauto 允许/不允许以 –a选项进行安装
dev/nodev 对/不对文件系统上的特殊设备进行解释
exec/noexec 允许/不允许执行二进制代码
suid/nosuid 确认/不确认suid和sgid位
user /nouser 允许/不允许一般用户挂载
codepage=XXX 代码页
iocharset=XXX 字符集
ro 以只读方式挂载
rw 以读写方式挂载
remount 重新安装已经安装了的文件系统
loop 挂载回旋设备
功能说明:卸除文件系统。
选项:
-a 卸除/etc/mtab中记录的所有文件系统。
-h 显示帮助。
-n 卸除时不要将信息存入/etc/mtab文件中。
-r 若无法成功卸除,则尝试以只读的方式重新挂入文件系统。
-t<文件系统类型> 仅卸除选项中所指定的文件系统。
-v 执行时显示详细的信息。
-V 显示版本信息。
实例:强制卸载
umount -lf 挂载点
- df
检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
选项:
-a 显示所有文件系统的磁盘使用情况,包括0块(block)的文件系统,如/proc文件系统。
-k 以k字节为单位显示。
-m或--megabytes:指定区块大小为1048576字节;
-h或--human-readable:以可读性较高的方式来显示信息
-i 显示i节点信息,而不是磁盘块。
-t 显示各指定类型的文件系统的磁盘空间使用情况。
-T或--print-type:显示文件系统的类型;
-x 列出不是某一指定类型文件系统的磁盘空间使用情况(与t选项相反)。
-T 显示文件系统类型。
-l或--local:仅显示本地端的文件系统;
--help:显示帮助;
--version:显示版本信息。
- du
对文件和目录磁盘使用的空间的查看
选项:
-a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总计,只列出最后加总的值。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。
- fsck
fsck命令被用于检查并且试图修复文件系统中的错误。当文件系统发生错误四化,可用fsck指令尝试加以修复。
语法:fsck(选项)(参数)
选项:
-a:自动修复文件系统,不询问任何问题;
-A:依照/etc/fstab配置文件的内容,检查文件内所列的全部文件系统;
-N:不执行指令,仅列出实际执行会进行的动作;
-P:当搭配"-A"参数使用时,则会同时检查所有的文件系统;
-r:采用互动模式,在执行修复时询问问题,让用户得以确认并决定处理方式;
-R:当搭配"-A"参数使用时,则会略过/目录的文件系统不予检查;
-s:依序执行检查作业,而非同时执行;
-t<文件系统类型>:指定要检查的文件系统类型;
-T:执行fsck指令时,不显示标题信息;
-V:显示指令执行过程。
参数:
文件系统:指定要修复的文件系统。
大多数系统设置为启动时自动运行fsck ,因此任何错误将在系统使用前被检测到(并根据希望修正)。自动检查只对启动时自动mount的文件系统发生作用,使用fsck 手工检查其他文件系统,比如软盘。使用有错误的文件系统可能使问题变得更坏。如果系统正常关闭,几乎从不发生错误,因此有一些方法可以不进行检查。如果文件/etc/fastboot 存在,就不检查。另外,如果ext2文件系统在超级块中有一个特定的标记告知该文件系统在上次mount后没有正常unmount. 如果标记指出unmount正常完成(假设正常unmount指出没问题),e2fsck (fsck 的ext2文件系统版) 就不检查系统。/etc/fastboot 是否影响系统依赖于你的启动手稿,但ext2标记则在你使用e2fsck 时发生作用--基于一个e2fsck 选项
- dd
用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
选项:
if=file #输入文件名,缺省为标准输入。
of=file #输出文件名,缺省为标准输出。
ibs=bytes #一次读入 bytes 个字节(即一个块大小为 bytes 个字节)。
obs=bytes #一次写 bytes 个字节(即一个块大小为 bytes 个字节)。
bs=bytes #同时设置读写块的大小为 bytes ,可代替 ibs 和 obs 。
cbs=bytes #一次转换 bytes 个字节,即转换缓冲区大小。
skip=blocks #从输入文件开头跳过 blocks 个块后再开始复制。
seek=blocks #从输出文件开头跳过 blocks 个块后再开始复制。(通常只有当输出文件是磁盘或磁带时才有效)。
count=blocks #仅拷贝 blocks 个块,块大小等于 ibs 指定的字节数。
conv=conversion[,conversion...] #用指定的参数转换文件。
ascii:转换ebcdic为ascii
ebcdic:转换ascii为ebcdic
ibm:转换ascii为alternate ebcdic
block:把每一行转换为长度为cbs,不足部分用空格填充
unblock:使每一行的长度都为cbs,不足部分用空格填充
lcase:把大写字符转换为小写字符
ucase:把小写字符转换为大写字符
swab:交换输入的每对字节
noerror:出错时不停止
notrunc:不截短输出文件
sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
dd应用实例
1.将本地的/dev/hdb整盘备份到/dev/hdd
dd if=/dev/hdb of=/dev/hdd
2.将/dev/hdb全盘数据备份到指定路径的image文件
dd if=/dev/hdb of=/root/image
3.将备份文件恢复到指定盘
dd if=/root/image of=/dev/hdb
4.备份/dev/hdb全盘数据,并利用gzip工具进行压缩,保存到指定路径
dd if=/dev/hdb | gzip > /root/image.gz
5.将压缩的备份文件恢复到指定盘
gzip -dc /root/image.gz | dd of=/dev/hdb
6.备份磁盘开始的512个字节大小的MBR信息到指定文件
dd if=/dev/hda of=/root/image count=1 bs=512
count=1指仅拷贝一个块;bs=512指块大小为512个字节。
恢复:dd if=/root/image of=/dev/hda
7.备份软盘
dd if=/dev/fd0 of=disk.img count=1 bs=1440k (即块大小为1.44M)
8.拷贝内存内容到硬盘
dd if=/dev/mem of=/root/mem.bin bs=1024 (指定块大小为1k)
9.拷贝光盘内容到指定文件夹,并保存为cd.iso文件
dd if=/dev/cdrom(hdc) of=/root/cd.iso
10.增加swap分区文件大小
第一步:创建一个大小为256M的文件:
dd if=/dev/zero of=/swapfile bs=1024 count=262144
第二步:把这个文件变成swap文件:
mkswap /swapfile
第三步:启用这个swap文件:
swapon /swapfile
第四步:编辑/etc/fstab文件,使在每次开机时自动加载swap文件:
/swapfile swap swap default 0 0
11.销毁磁盘数据
dd if=/dev/urandom of=/dev/hda1
注意:利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据。
12.测试硬盘的读写速度
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/root/1Gb.file bs=64k | dd of=/dev/null
通过以上两个命令输出的命令执行时间,可以计算出硬盘的读、写速度。
13.确定硬盘的最佳块大小:
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file
dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file
dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file
通过比较以上命令输出中所显示的命令执行时间,即可确定系统最佳的块大小。
14.修复硬盘:
dd if=/dev/sda of=/dev/sda 或dd if=/dev/hda of=/dev/hda
当硬盘较长时间(一年以上)放置不使用后,磁盘上会产生magnetic flux point,当磁头读到这些区域时会遇到困难,并可能导致I/O错误。当这种情况影响到硬盘的第一个扇区时,可能导致硬盘报废。上边的命令有可能使这些数据起死回生。并且这个过程是安全、高效的。
/dev/null和/dev/zero的区别
/dev/null,外号叫无底洞,你可以向它输出任何数据,它通吃,并且不会撑着!
/dev/zero,是一个输入设备,你可你用它来初始化文件。
/dev/null------它是空设备,也称为位桶(bit bucket)。任何写入它的输出都会被抛弃。如果不想让消息以标准输出显示或写入文件,那么可以将消息重定向到位桶。
/dev/zero------该设备无穷尽地提供0,可以使用任何你需要的数目——设备提供的要多的多。他可以用于向设备或文件写入字符串0。
oracle@localhost oracle]$if=/dev/zero of=./test.txt bs=1k count=1
oracle@localhost oracle]$ ls -l
total 4
-rw-r--r-- 1 oracle dba 1024 Jul 15 16:56 test.txt
- dumpe2fs
dumpe2fs - 显示ext2/ext3/ext4文件系统中的超级块和块组信息
选项
-b 打印文件系统中的坏块
-o 不常用,检查严重损坏文件系统时指定
-f 强制显示所有信息,即便dumpe2fs对有些文件系统功能标识不能识别。
-i 显示image文件系统信息。device指定image文件的路径
-h 只显示超级块信息
-x 将已分组的块的数量用十六进制显示
-v 显示dumpe2fs的版本号并推出
- dump
dump为备份工具程序,可将目录或整个文件系统备份至指定的设备,或备份成一个大文件。
- resize2fs
- 搜索文件命令(4)
- whereis
whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。和find相比,whereis查找的速度非常快,这是因为linux系统会将 系统内的所有文件都记录在一个数据库文件中,当使用whereis和下面即将介绍的locate时,会从数据库中查找数据,而不是像find命令那样,通 过遍历硬盘来查找,效率自然会很高。 但是该数据库文件并不是实时更新,默认情况下时一星期更新一次,因此,我们在用whereis和locate 查找文件时,有时会找到已经被删除的数据,或者刚刚建立文件,却无法查找到,原因就是因为数据库文件没有被更新。
命令格式:
whereis [-bmsu] [BMS 目录名 -f ] 文件名
命令功能:
whereis命令是定位可执行文件、源代码文件、帮助文件在文件系统中的位置。这些文件的属性应属于原始代码,二进制文件,或是帮助文件。whereis 程序还具有搜索源代码、指定备用搜索路径和搜索不寻常项的能力。
命令参数:
-b 定位可执行文件。
-m 定位帮助文件。
-s 定位源代码文件。
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
-B 指定搜索可执行文件的路径。
-M 指定搜索帮助文件的路径。
-S 指定搜索源代码文件的路径。
使用实例:
- 将和**文件相关的文件都查找出来
[root@liwenbin ~]# which tomcat
/usr/bin/which: no tomcat in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin)
[root@localhost ~]# whereis svn
svn: /usr/bin/svn /usr/local/svn /usr/share/man/man1/svn.1.gz
tomcat没安装,找不出来,svn安装找出了很多相关文件
- 只将二进制文件 查找出来
[root@localhost ~]# whereis -b svn
svn: /usr/bin/svn /usr/local/svn
- 查出说明文档路径
[root@localhost ~]# whereis -m svn
svn: /usr/share/man/man1/svn.1.gz
- 找source源文件。
[root@localhost ~]# whereis -s svn
svn:
- locate
locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案。其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中了。在一般的 distribution 之中,数据库的建立都被放在 crontab 中自动执行。
命令格式:
Locate [选择参数] [样式]
命令功能:
locate命令可以在搜寻数据库时快速找到档案,数据库由updatedb程序来更新,updatedb是由cron daemon周期性建立的,locate命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是locate所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb每天会跑一次,可以由修改crontab来更新设定值。(etc/crontab)
locate指定用在搜寻符合条件的档案,它会去储存档案与目录名称的数据库内,寻找合乎范本样式条件的档案或目录录,可以使用特殊字元(如”*” 或”?”等)来指定范本样式,如指定范本为kcpa*ner, locate会找出所有起始字串为kcpa且结尾为ner的档案或目录,如名称为kcpartner若目录录名称为kcpa_ner则会列出该目录下包括 子目录在内的所有档案。
locate指令和find找寻档案的功能类似,但locate是透过update程序将硬盘中的所有档案和目录资料先建立一个索引数据库,在 执行loacte时直接找该索引,查询速度会较快,索引数据库一般是由操作系统管理,但也可以直接下达update强迫系统立即修改索引数据库。
命令参数:
-e 将排除在寻找的范围之外。
-1 如果 是 1.则启动安全模式。在安全模式下,使用者不会看到权限无法看到 的档案。这会始速度减慢,因为 locate 必须至实际的档案系统中取得档案的 权限资料。
-f 将特定的档案系统排除在外,例如我们没有到理要把 proc 档案系统中的档案 放在资料库中。
-q 安静模式,不会显示任何错误讯息。
-n 至多显示 n个输出。
-r 使用正规运算式 做寻找的条件。
-o 指定资料库存的名称。
-d 指定资料库的路径
-h 显示辅助讯息
-V 显示程式的版本讯息
- 查找和pwd相关的所有文件
peida-VirtualBox ~ # locate pwd
/bin/pwd
/etc/.pwd.lock
/usr/include/pwd.h
/usr/lib/python2.7/dist-packages/twisted/python/fakepwd.py
/usr/lib/python2.7/dist-packages/twisted/python/test/test_fakepwd.pyc
/usr/lib/syslinux/pwd.c32
/usr/share/help/C/empathy/irc-join-pwd.page
/usr/share/help/ca/empathy/irc-join-pwd.page
- 搜索etc目录下所有以sh开头的文件
peida-VirtualBox ~ # locate /etc/sh
/etc/shadow
/etc/shadow-
/etc/shells
- 搜索etc目录下,所有以m开头的文件
peida-VirtualBox ~ # locate /etc/m
/etc/magic
/etc/magic.mime
/etc/manpath.config
/etc/mate-settings-daemon
- which
which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
命令格式:
which 可执行文件名称
命令功能:
which指令会在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
命令参数:
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
-p 与-n参数相同,但此处的包括了文件的路径。
-w 指定输出时栏位的宽度。
-V 显示版本信息
- 查找文件、显示命令路径
[root@localhost ~]# which pwd
/bin/pwd
[root@localhost ~]# which adduser
/usr/sbin/adduser
which 是根据使用者所配置的 PATH 变量内的目录去搜寻可运行档的!所以,不同的 PATH 配置内容所找到的命令当然不一样的!
- 用 which 去找出 which
[root@localhost ~]# which which
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
/usr/bin/which
竟然会有两个 which ,其中一个是 alias 这就是所谓的『命令别名』,意思是输入 which 会等於后面接的那串命令!
- 找出 cd 这个命令
[root@liwenbin ~]# which cd
/usr/bin/which: no cd in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin)
cd 这个常用的命令竟然找不到啊!为什么呢?这是因为 cd 是bash 内建的命令! 但是 which 默认是找 PATH 内所规范的目录,所以当然一定找不到的!
- find
find path -option [ -print] [ -exec -ok command ] {} \;
#-print 将查找到的文件输出到标准输出
#-exec command {} \; -----将查到的文件执行command操作,{} 和 \;之间有空格
#-ok 和-exec相同,只不过在操作前要询用户
选项
-name filename #查找名为filename的文件
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 #找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 #查更改时间比f1新但比f2旧的文件
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-depth #使查找在进入子目录前先行查找完本目录
-fstype #查更改时间比f1新但比f2旧的文件
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-cpio #对匹配的文件使用cpio命令,将他们备份到磁带设备中
-prune #忽略某个目录
- 在/tmp中查找所有的*.h,并在这些文件中查找“SYSCALL_VECTOR",最后打印出所有包含"SYSCALL_VECTOR"的文件名
[root@liwenbin ~]# find /tmp -name "*.h" | xargs -n50 grep SYSCALL_VECTOR
[root@liwenbin ~]# grep SYSCALL_VECTOR /etc/*.conf | cut -d':' -f1|uniq > filename
[root@liwenbin ~]# find /etc -name "*.conf" -exec ls {} \;
- 找出某个目录下的文件再删除
find / -name filename -ok rm -rf {} \;
- 比如要查找磁盘中大于3M的文件:
find . -size +3000k -exec ls -ld {}\ ;
- 将find出来的东西拷到另一个地方
find *.c -exec cp '{}' /tmp ';'
- 如果有特殊文件,可以用cpio,也可以用这样的语法:
find dir -name filename -print | cpio -pdv newdir
- 查找2004-11-30 16:36:37时更改过的文件
A=`find ./ -name "*php"`|ls -l --full-time $A 2>/dev/null|grep "2004-11-30 16:36:37
a.基本用法:
find / -name 文件名
find ver1.d ver2.d -name '*.c' -print 查找ver1.d,ver2.d *.c文件并打印
find . -type d -print 从当前目录查找,仅查找目录,找到后,打印路径名。可用于打印目录结构。
b.无错误查找:
find / -name access_log 2 >/dev/null
c.按尺寸查找:
find / -size 1500c (查找1,500字节大小的文件,c表示字节)
find / -size +1500c (查找大于1,500字节大小的文件,+表示大于)
find / -size +1500c (查找小于1,500字节大小的文件,-表示小于)
d.按时间:
find / -amin n 最后n分钟
find / -atime n 最后n天
find / -cmin n 最后n分钟改变状态
find / -ctime n 最后n天改变状态
e.其它:
find / -empty 空白文件、空白文件夹、没有子目录的文件夹
find / -false 查找系统中总是错误的文件
find / -fstype type 找存在于指定文件系统的文件,如type为ext2
find / -gid n 组id为n的文件
find / -group gname 组名为gname的文件
find / -depth n 在某层指定目录中优先查找文件内容
find / -maxdepth levels 在某个层次目录中按递减方式查找
f.逻辑
-and 条件与 -or 条件或
g.查找字符串
find . -name '*.html' -exec grep 'mailto:'{}
- 关机重启命令(3)
- shutdown
以下为常见关机命令
shutdown -h now
halt
init 0
shutdown 10:45 &
参数:
-r:shutdown之后重新启动系统。
-k:只是送出信息给所有用户,但并不会真正关机。
-F:重新启动时执行fsck
-c:取消前一个shutdown命令
- reboot
1.功能:重启Linux系统。
2.选项:
-d 重新启动时不把数据写入记录文件/var/tmp/wtmp
-f 强制重新开机,不调用shutdown指令的功能
-h 在系统关机或power off之前,将所有的硬盘处于待机模式
-i关闭网络设置之后再重新启动系统
-n保存数据后再重新启动系统
-p When halting the system, do a poweroff. This is the default when halt is called as powero
-w 仅做测试,并不真的将系统重新开机,只会把重开机的数据写入/var/log目录下的wtmp记录文件
--help 显示命令在线帮助
- init
Linux的运行等级设定如下:
0:关机
1:单用户模式
2:无网络支持的多用户模式
3:有网络支持的多用户模式
4:保留,未使用
5:有网络支持有X-Window支持的多用户模式
6:重新引导系统,即重启
init 0 #关机
init 6 #重启
- 系统管理相关命令(3)
- uptime
uptime 命令用于查看服务器运行了多长时间以及有多少个用户登录,快速获知服务器的负荷情况。
以下是 uptime 的运行实例:
11:07:03 up 2 days, 25 min, 3 users, load average: 0.53, 0.31, 0.25
当前时间 11:07:03
系统已运行的时间 2 days, 25 min
当前在线用户 3 users
平均负载:0.53, 0.31, 0.25 最近1分钟、5分钟、15分钟系统的负载
它的值代表等待 CPU 处理的进程数,如果 CPU 没有时间处理这些进程,load average 值会升高; 反之则会降低。
load average 的最佳值是 1,说明每个进程都可以马上处理并且没有 CPU cycles 被丢失。对于单 CPU 的机器,1 或者 2 是可以接受的值;对于多路 CPU 的机器,load average值可能在8 到10 之间。
也可以查看/proc/loadavg 和/proc/uptime 两个文件,注意不能编辑/proc 中的文件,要用cat 等命令来查看
- top
TOP是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止
top - 15:37:16 up 5:15, 3 users, load average: 0.00, 0.00, 0.00
Tasks: 99 total, 1 running, 98 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3%us, 0.3%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1012292k total, 598792k used, 413500k free, 34948k buffers
Swap: 1048572k total, 0k used, 1048572k free, 403328k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7 root 20 0 0 0 0 S 0.3 0.0 0:15.16 events/0
4053 liwen 20 0 98.1m 2072 1040 S 0.3 0.2 0:02.08 sshd
4536 root 20 0 15032 1196 932 S 0.3 0.1 0:00.85 top
1 root 20 0 19356 1540 1224 S 0.0 0.2 0:01.31 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
第一行是任务队列信息,同 uptime 命令的执行结果:
- 当前时间
- 系统运行时间,格式为时:分
- 当前登录用户数
- 系统负载,即任务队列的平均长度
第二、三行为进程和CPU的信息
- Tasks:进程总数
- running正在运行的进程数
- 睡眠的进程数
- 停止的进程数
- 停止的进程数
- 僵尸进程数
- 用户空间占用CPU百分比
- 内核空间占用CPU百分比
- 用户进程空间内改变过优先级的进程占用CPU百分比
- 空闲CPU百分比
- 等待输入输出的CPU时间百分比
第四五行为内存信息
- 物理内存总量
- 使用的物理内存总量
- 空闲内存总量
- 用作内核缓存的内存量
- 交换区总量
- 使用的交换区总量
- 空闲交换区总量
- 缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
进程信息
- PID 进程id
- USER进程所有者的用户名
- PR优先级
- NI nice值。负值表示高优先级,正值表示低优先级
- VIRT进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR共享内存大小,单位kb
- S进程状态。
D=不可中断的睡眠状态
R=运行
S=睡眠
T=跟踪/停止
Z=僵尸进程
- %CPU上次更新到现在的CPU时间占用百分比
- %MEM进程使用的物理内存百分比
- TIME+进程使用的CPU时间总计,单位1/100秒
- COMMAND命令名/命令行
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程
top使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明
-d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使。
-s 交互命令来改变之。
-p 通过指定监控进程ID来仅仅监控某个进程的状态。
-q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
-S 指定累计模式 s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
-i 使top不显示任何闲置或者僵死进程。
-c 显示整个命令行而不只是显示命令名
其他实用命令
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间, 很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f 或者F 从当前显示中添加或者删除项目。
o 或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
- free
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
[root@localhost ~]# free -m
total used free shared buffers cached
Mem: 988 584 403 0 34 393
-/+ buffers/cache: 156 831
Swap: 1023 0 1023
第一行
- total:总计物理内存的大小。
- used:已使用多大。
- free:可用有多少。
- Shared:多个进程共享的内存总额。
- Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
- used:已使用多大。
- free:可用有多少
第四行
- 交换分区SWAP的,也就是我们通常所说的虚拟内存。
第一行与第三行buffers/cached区别:
第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是403M,已用内存是584M,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
可用内存=系统free memory+buffers+cached。如本机情况的可用内存为:403+34+11363424
选项
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
- 进程管理(3)
- ps
-A 显示所有进程(等价于-e)(utility)
-a 显示一个终端的所有进程,除了会话引线
-N 忽略选择。
-d 显示所有进程,但省略所有的会话引线(utility)
-x 显示没有控制终端的进程,同时显示各个命令的具体路径。dx不可合用。(utility)
-p pid 进程使用cpu的时间
-u uid or username 选择有效的用户id或者是用户名
-g gid or groupname 显示组的所有进程。
U username 显示该用户下的所有进程,且显示各个命令的详细路径。如:ps U zhang;(utility)
-f 全部列出,通常和其他选项联用。如:ps -fa or ps -fx and so on.
-l 长格式(有F,wchan,C 等字段)
-j 作业格式
-o 用户自定义格式。
v 以虚拟存储器格式显示
s 以信号格式显示
-m 显示所有的线程
-H 显示进程的层次(和其它的命令合用,如:ps -Ha)(utility)
e 命令之后显示环境(如:ps -d e; ps -a e)(utility)
h 不显示第一行
- pstree
以树结构显示进程
-a 显示出该命令的参数, 假如这个命令进程被其他进程替换掉, 那么进程将显示在括号中 -a 选项包含有压实进程树的选项, 对于相同的进程, 会使用n*(process)的形式展显出来。
-c 关闭禁用显示结果进程树,在默认情况下,进程子树是会被压缩的。不管有多少进程名相同的进程,都会逐个显示出来。
-G 使用vt100线性描述树
-h 突空出显示当前进程的父进程并高亮显示出来,如果没有父进程那么什么都不会显示。
-H 突出显示出指定进程的父进程信息并高亮显示出来,使用方法为 pstree -H PID
-l 显示长格式命令选项,在默认的情况下,命令行最多显示宽度为132bit ,超过将不能正常显示。
-n 基于进程相同的祖先来进行排序,可以命名pid来代替进程名称 。
-p 显示所有的时程,显示结果包含进程名和时进程ID
-u 显示出用户的UID,无论何时,这个UID和进程比较UID参数,这个新的UID将在进程名后显示不同的参数。
-U 使用utf-8字符集以十进制表示,
-v 显示版本号
- jobs
查看当前有多少在后台运行的命令
shutdown 21:50 &
选项
-l 显示后台进程的信息,显示格式
-p 只显示PID
-r 只显示running状态的进程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号