网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息

#!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html' r=requests.get(url) if r.status_code==200: print('网络请求成功') demo=r.text soup=BeautifulSoup(demo,'html.parser') print(soup.prettify())
BeautifulSoup类的基本属性

#!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html' r=requests.get(url) if r.status_code==200: print('网络请求成功') demo=r.text soup=BeautifulSoup(demo,'html.parser') tag_title=soup.title print(tag_title) tag_a_attrs=soup.a.attrs print(soup.p.string)
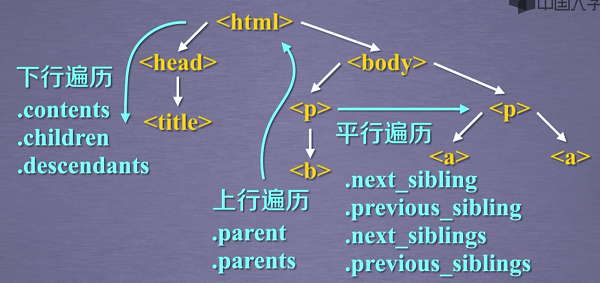
标签树的下行遍历
#!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html' r=requests.get(url) if r.status_code==200: print('网络请求成功') demo=r.text soup=BeautifulSoup(demo,'html.parser') print(soup.prettify()) print('我是分割线'.center(80,'-')) #遍历子节点 for child in soup.body.children: print(child) #遍历子孙节点 for descendant in soup.body.descendants: print(descendant)
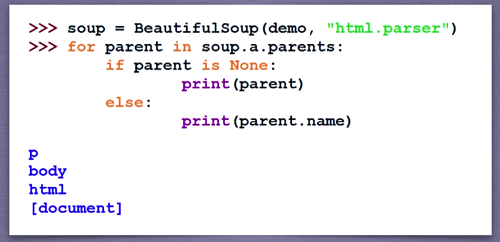
标签树的上行遍历

遍历title标签的上一级标签
print(soup.title.parent)
#a标签的下一标签 print(soup.a.next_sibling)
遍历a标签的所有前序节点以及后续节点
#遍历a标签的前序节点 for sibling in soup.a.next_siblings: print(sibling) #遍历a标签的前序节点 for sibling in soup.a.previous_siblings: print(sibling)
soup标签的上一级标签为空,所以要进行判断