
26.pacemaker集群(drbd、nginx、mariadb)
一、概念
pacemaker :群集资源管理器
corosync: 消息/基础架构。 位于高可用集群结构中的底层,为各个节点(node)之间提供心跳信息传递。
pcs : pacemaker corosync server
stonith:stonith 是“shoot the other node in the head ” 的首字母简写,他是heartbeat 软件包的一个组件,它允许使用一个远程或“智能的”链接到健康服务器的电源设备自动重启失效电源
stonith 设备可以关闭电源并相应软件命令,运行heartbeat的服务器可以通过串口线或网线向stonith设备发送命令,他控制高可用服务器对其他服务器的电力供应
主服务器可以复位备用服务器的电源
备用服务器也可以复位主服务的电源
fencing:集群通常需要使用fencing agent。是在一个节点不稳定或者无答复时将其关闭,使得他不会损坏集群的其他资源,其主要用途是消除脑裂
RA :resource agent是管理一个集群资源的可执行程序,没有固定其实现的编程语言,但大部分RA 都是使用shell 脚本实现。pacemaker 使用RA来和收管理资源进行交互,它即支持它自身实现的70多个RA,也支持第三方RA。要实现一个RA, 需要遵循OCF 规范pacemaker 支持三种类型的RA:
LSB resource agents
OCF resource agents
legacy heartbeat resource agents
RA 支持的主要操作包括:
start 、 stop 、monitor、validate-all、meta-data…
#pcs resource agents 命令查看相关的agent
集群配置:群集名称,资源依赖,次序约束等。
网络:业务、存储、带外管理、心跳分开。
服务器:HCL(硬件兼容)、带外管理、冗余电源。
二.集群节点的准备工作
2.1.安装软件
yum -y install pacemaker corosync pcs psmisc policycoreutils-python fence-agents-all
cd /etc/yum.repos.d
wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/network:ha-clustering:Stable.repo
yum install crmsh -y
2.2.主机名及解析
主机名解析、双机ssh key互信
在两台主机上都需修改
修改/etc/hosts文件
10.146.3.102 vtlh-m-pacemaker01 node01 10.146.3.115 vtlh-m-pacemaker02 node02
双机ssh key互信
ssh-keygen -t rsa -b 1024 ssh-copy-id -i .ssh/id_rsa.pub node02
2.3.NTP同步
timedatectl set-timezone yum install chrony vim /etc/chrony.conf server 10.134.128.21 iburst systemctl status chronyd.service systemctl restart chronyd.service systemctl enable chronyd.service chronyc sources -v
三、范例:
3.1.集群创建
3.1.1.配置PCS守护进程及hacluster账户密码
##1.配置pcs守护程序 systemctl status pcsd systemctl enable pcsd systemctl start pcsd
#设置hacluster账户密码 ##2.安装集群软件包时,会创建一个账户hacluster,它的密码是禁用的,此账号用于集群间通信时的身份验证,必须在每个节点设置其密码并启用此账户。 echo '123'|passwd --stdin hacluster
3.1.2.集群配置文件
集群及pacemaker配置文件
corosync.conf和cib.xml,默认不存在
corosync.conf 文件提供corosync 使用的集群参数
cib.xml 存储集群配置及所有资源的信息,pcsd 守护程序负责整个节点上同步CIB的内容
可以手工创建、修改、但建议通过pcs 工具进行管理和维护
pcs cluster auth node01 node02 ##只需要node01上执行即可
pcs cluster auth node01 node02 -u hacluster -p 123 --debug
/var/log/pcsd/pcsd.log ##相关日志
出现以下错误,需要取消代理配置
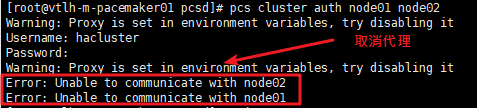
3.1.3.配置和同步集群节点
pcs cluster setup --name web node01 node02
pcs status ##查看集群状态
systemctl status pacemaker ##查看pcemaker是否启动。
systemctl start pacemaker
systemctl enable pacemaker
pcs cluster enable --all ##集群开机自启
corosync-cfg-tool -s
corosync-cmapctl |grep members ##查盾接入成员
pcs status corosync
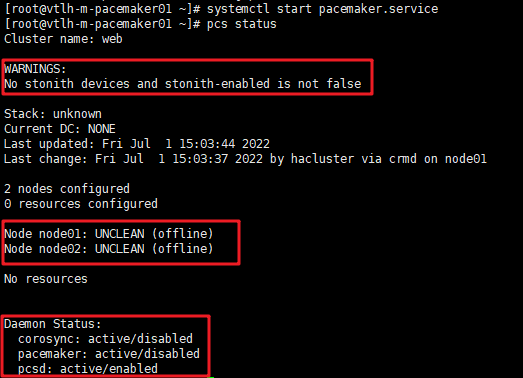
"No stonith devices and stonith-enabled is not false",因为尚未配置stonith,所以先将stonith-enabled属性更改为false
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore ##两节点不需要仲裁,关闭仲裁。
pcs resource defaults migration-threshold=1 ##故障时资源迁移
在node1恢复后,为防止node2资源迁回node01(迁来迁去对还是会对业务有一定影响)
pcs resource defaults resource-stickiness=100
pcs resource defaults
再次查看集群状态pcs status
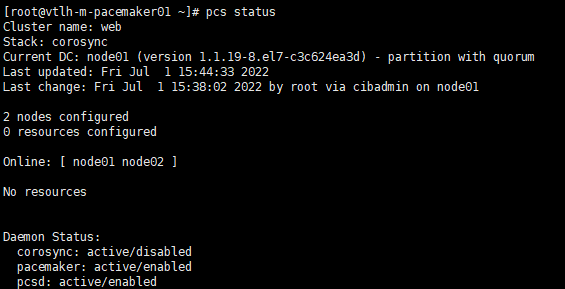
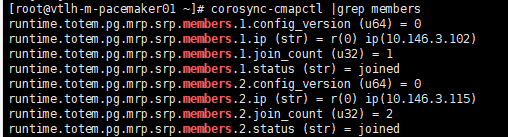
在node01恢复后,为防止node02资源迁回node01
# pcs resource defaults resource-stickiness=100 # pcs resource defaults ##资源超时时间 # pcs resource op defaults timeout=90s # pcs resource op defaults
图形管理界面
3.2.集群资源配置
以下均在node01上操作即可,不需要两个node上都操作。
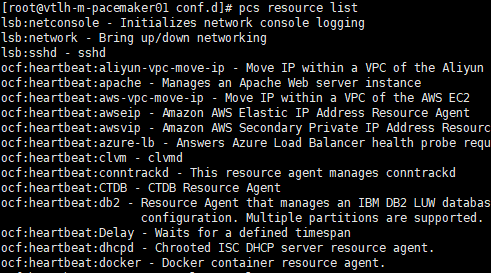
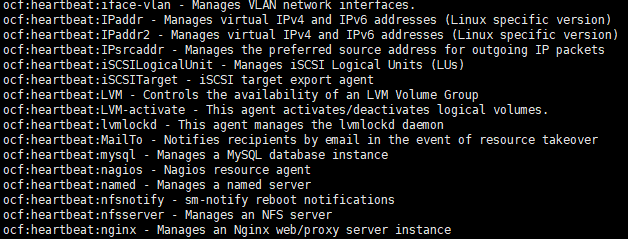
pcs resource list ##查看支持的资源清单
pcs resource standards ##列出资源类型
pcs resource agent ##查看资源使用方法
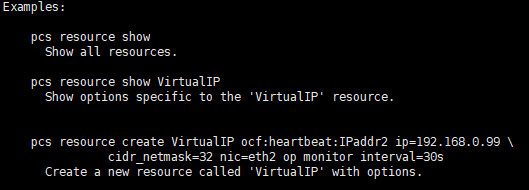
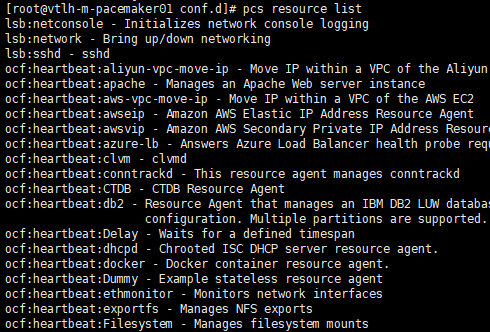
3.2.1.创建vip
pcs resource create nginx-vip ocf:heartbeat:IPaddr2 ip=10.146.3.134 cidr_netmask=22 op monitor interval=30s pcs resource show ##查看资源 crm_mon ##控制台查看资源
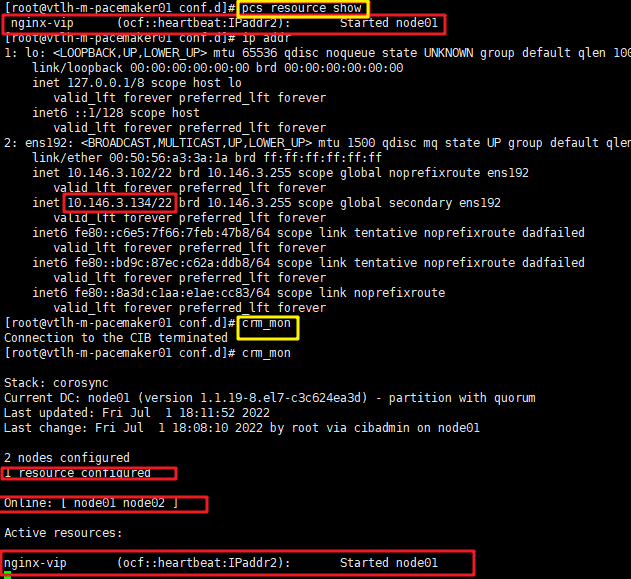
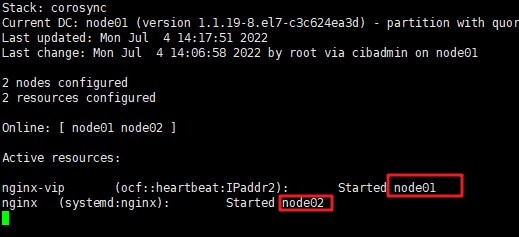
查看集群状态
pcs status
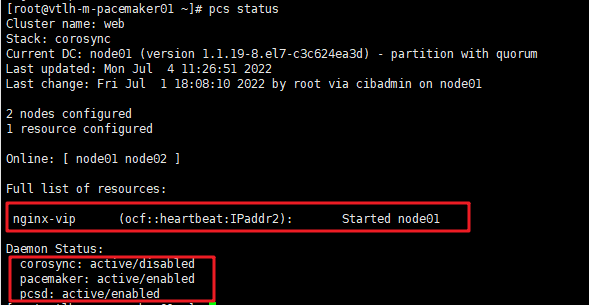
crm_verify -L -V ##检查集群是否有错
测试vip是否可以漂移
pcs cluster stop node01
pcs cluster start node01 ##再重新开启,vip不会切换回去
3.2.2.创建nginx资源
pcs resource create nginx systemd:nginx op monitor interval=1min
pcs resource show
systemctl status nginx
tail /var/log/messages
查看日志


查看集群资源可以发现vip与nginx不在同一台主机启动
crm_mon 或 pcs status
pcs resource show

3.2.3.创建集群资源组,让它们在一起
pcs resource group add nginx_group nginx-vip nginx ##group 特殊的资源
pcs resource show
特殊资源 - resource group
Resource group 是一种特殊的资源。它默认包含了 order + colocation. 比如,一个 resource group 包含以下 resources:
- httpd
- vip
这意味着,启动顺序是 filesystem -> httpd -> vip,停止顺序是 vip -> httpd -> filesystem. 而且这3个资源会在同一个节点上运行。
设置资源组之后,无须再对组内资源配置约束条件。

设置资源组后,不需要重启集群服务,集群会自动把它们集中运行到一个node上。
curl http://10.146.3.134


4.给集群添加fence,防止脑裂
esxi上的vm使用vcenter上或esxi主机充当stonith设备
用fence_vmware_soap类型的Fencing Agent配置STONITH设备
pcs stonith list ##查看fence agent设备类型,确认两个node上都安装了fence_vmware_soap
pcs stonith describe fence_vmware_soap ##fence_vmware_soap相关配置参数
fence_vmware_soap --ip <Your IP Address or Host Name> --ssl --ssl-insecure --action list --username="<Your UserName>" --password="<Your Password>" | grep RedHat
##确认当前机器是否可以通过fence_vmware_soap获取vmware上的机器列表
5.DRBD
5.1.概述:
5.2.安装
#rpm -Uvh http: //www .elrepo.org /elrepo-release-7 .0-2.el7.elrepo.noarch.rpm #yum install -y kmod-drbd84 drbd84-utils
#modprobe drbd
#lsmod |grep drbd
5.3.配置
/etc/drbd.conf #主配置文件 /etc/drbd.d/global_common.conf #全局配置文件
用LVM的方式配置(也可以直接用裸盘)
两个节点都要配置
#pvcreate /dev/sdb #vgcreate datavg /dev/sdb #lvcreate -l +100%FREE -n drbd_data datavg
创建drbd配置文件(两个节点都要配置)
cat >> /etc/drbd.d/db.res <<EOF
resource drbd_data{ protocol C; startup { wfc-timeout 0; degr-wfc-timeout 120; } disk { on-io-error detach; } net { timeout 60; connect-int 10; ping-int 10; max-buffers 2048; max-epoch-size 2048; } syncer{ verify-alg sha1; rate 100M; } on vtlh-m-pacemaker01{ ##必须是主机名(drbd用主机名来识别),否则会报没有定义主机的错误。 device /dev/drbd1; disk /dev/mapper/datavg-drbd_data; address 10.146.3.102:7788; meta-disk internal; } on vtlh-m-pacemaker02{ device /dev/drbd1; disk /dev/mapper/datavg-drbd_data; address 10.146.3.115:7788; meta-disk internal; } }
EOF
启动DRBD
drbdadm create-md drbd_data ##初始化节点
出现“success”字样则表示成功。
#systemctl start drbd
#drbdadm up drbd_data
#cat /proc/drbd ##查看状态
#drbd-overview ##用命令查看狀態
0:mydrbd Connected Secondary/Secondary Inconsistent/Inconsistent C r----- ---顯示都是從節點,為不致狀態。因為沒有主節點
#drbdsetup /dev/drbd1 primary -o ---把一個節點設為主節點,即可以立即同步。----在哪個節點執行,哪個節點即為主。
也可以用以下命令執行。
#drbdadm -- --overwrite-data-of-peer primary drbd_data ##drbd_data ---resource的名字
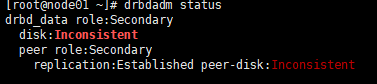
#drbdadm --force primary drbd_data ##--force强制抢占为primary,在哪台主机均执行,哪台就是主节点。 #查看drbd状态 #drbdadm status ##查看角色 #drbdadm role drbd_data

第一次初始化drbdadm status应是出现disk:Inconsistent
初始化很慢,50G的磁盘,初始化约费了40-50分钟
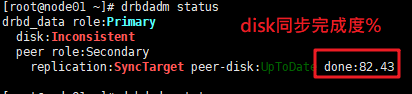
之后就是UpToDate状态
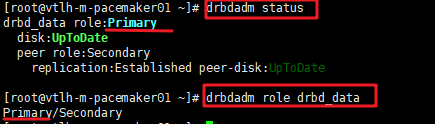
格式化分区
#mkdir /drbd_data
以下2步只在primary上执行 #mkfs.xfs /dev/drbd1 ##/dev/drbd1是在db.res配置文件中设置的,不能使用/dev/mapper/drbdvg-data/ #mount /dev/drbd1 /drbd_data #df -h
检查是否同步完成
#cat /proc/drbd

下面表示同步完成。

在Secondary节点上不允许对DRBD设备进行任何操作,包括挂载;所有的读写操作只能在Primary节点上进行,只有当Primary节点挂掉时,Secondary节点才能提升为Primary节点,并挂载DRBD继续工作。
切换主备节点
在节点01上先umount /drbd_data
vtlh-m-pacemaker01#drbdadm secondary drbd_data ##在节01上上设置,手动设置为secondary角色。 vtlh-m-pacemaker02#drbdadm primary drbd_data ##在02上设置 vtlh-m-pacemaker02#mount /dev/drbd1 /drbd_data
5.4.查看drbd角色及同步状态。
# cat /proc/drbd
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20980176
输出的含义解释:
ro表示角色信息,第一次启动drbd时,两个drbd节点默认都处于Secondary状态,
ds是磁盘状态信息,“Inconsistent/Inconsisten”,即为“不一致/不一致”状态,表示两个节点的磁盘数据处于不一致状态。
Ns表示网络发送的数据包信息。
Dw是磁盘写信息
Dr是磁盘读信息
5.5.常见drbd故障处理
1.DRBD UpToDate/DUnknown
解决方法:
1.确保卸载所有drbd设备
drbd1:~# umount /dev/drbd1
drbd2:~# umount /dev/drbd1
2.将所有节点设为Secondary
drbd1:~# drbdadm secondary drbd_data
drbd2:~# drbdadm secondary drbd_data
3.中断节点的连接
drbd2:~# drbdadm disconnect drbd_data
??: Failure: (162) Invalid configuration request
additional info from kernel:
unknown connection
Command 'drbdsetup-84 disconnect ipv4:10.11.8.158:7789 ipv4:10.11.8.145:7789' terminated with exit code 10
4.drbd2 上执行
drbd2:~# drbdadm connect drbd_data --discard-my-data
drbd2:~# cat /proc/drbd0:data/0 WFConnection Secondary/Unknown UpToDate/DUnknown
状态 WFConnection: 表示本节点将会等待, 直到对点网络实现连接
5.drbd1 上执行
drbd1:~# drbdadm connect drbd_data
drbd1:~# cat /proc/drbd0:data/0 Connected Secondary/Secondary UpToDate/UpToDate
2.进行上面操作不行,还可以把secondary重新初始化
在从节点上
drbdadm detach drbd_data
dd if=/dev/zero bs=1M count=100 of=/dev/sdb
drbdadm down drbd_data
drbdadm create-md drbd_data
在主节点上执行
drbdadm connect drbd_data
5.6.补充:/proc/drbd状态文件说明
1连接状态 Connected资源的连接状态;一个资源可能有以下连接状态中的一种 StandAlone 独立的:网络配置不可用;资源还没有被连接或是被管理断开(使用 drbdadm disconnect 命令),或是由于出现认证失败或是脑裂的情况 Disconnecting 断开:断开只是临时状态,下一个状态是StandAlone独立的 Unconnected 悬空:是尝试连接前的临时状态,可能下一个状态为WFconnection和WFReportParams Timeout 超时:与对等节点连接超时,也是临时状态,下一个状态为Unconected悬空 BrokerPipe:与对等节点连接丢失,也是临时状态,下一个状态为Unconected悬空 NetworkFailure:与对等节点推动连接后的临时状态,下一个状态为Unconected悬空 ProtocolError:与对等节点推动连接后的临时状态,下一个状态为Unconected悬空 TearDown 拆解:临时状态,对等节点关闭,下一个状态为Unconected悬空 WFConnection:等待和对等节点建立网络连接 WFReportParams:已经建立TCP连接,本节点等待从对等节点传来的第一个网络包 Connected 连接:DRBD已经建立连接,数据镜像现在可用,节点处于正常状态 StartingSyncS:完全同步,有管理员发起的刚刚开始同步,未来可能的状态为SyncSource或PausedSyncS StartingSyncT:完全同步,有管理员发起的刚刚开始同步,下一状态为WFSyncUUID WFBitMapS:部分同步刚刚开始,下一步可能的状态为SyncSource或PausedSyncS WFBitMapT:部分同步刚刚开始,下一步可能的状态为WFSyncUUID WFSyncUUID:同步即将开始,下一步可能的状态为SyncTarget或PausedSyncT SyncSource:以本节点为同步源的同步正在进行 SyncTarget:以本节点为同步目标的同步正在进行 PausedSyncS:以本地节点是一个持续同步的源,但是目前同步已经暂停,可能是因为另外一个同步正在进行或是使用命令(drbdadm pause-sync)暂停了同步 PausedSyncT:以本地节点为持续同步的目标,但是目前同步已经暂停,这可以是因为另外一个同步正在进行或是使用命令(drbdadm pause-sync)暂停了同步 VerifyS:以本地节点为验证源的线上设备验证正在执行 VerifyT:以本地节点为验证目标的线上设备验证正在执行
硬盘状态
# drbdadm dstate drbd_data ##drbd_data drbd资源 UpToDate/UpToDate 本地和对等节点的硬盘有可能为下列状态之一: Diskless 无盘:本地没有块设备分配给DRBD使用,这表示没有可用的设备,或者使用drbdadm命令手工分离或是底层的I/O错误导致自动分离 Attaching:读取无数据时候的瞬间状态 Failed 失败:本地块设备报告I/O错误的下一个状态,其下一个状态为Diskless无盘 Negotiating:在已经连接的DRBD设置进行Attach读取无数据前的瞬间状态 Inconsistent:数据是不一致的,在两个节点上(初始的完全同步前)这种状态出现后立即创建一个新的资源。此外,在同步期间(同步目标)在一个节点上出现这种状态 Outdated:数据资源是一致的,但是已经过时 DUnknown:当对等节点网络连接不可用时出现这种状态 Consistent:一个没有连接的节点数据一致,当建立连接时,它决定数据是UpToDate或是Outdated UpToDate:一致的最新的数据状态,这个状态为正常状态
6.mysql设置
# yum install epel* -y
# yum install mariadb mariadb-server MySQL-python 备注:修改 /etc/my.cnf 指定的数据库绑定目录(datadir=/mnt/drbd) 和修改 数据库绑定的目录 权限(chown –R mysql.mysql /mnt/drbd) 禁止mysql开机启动 # chkconfig mariadb off
7.配置drbd高可用
先停止drbd服务 ,并且在节点上umount /dev/drbd1,两个节点均设置为secondary状态
systemctl stop drbd
查看面注册的2台集群
#cat /etc/corosync/corosync.conf
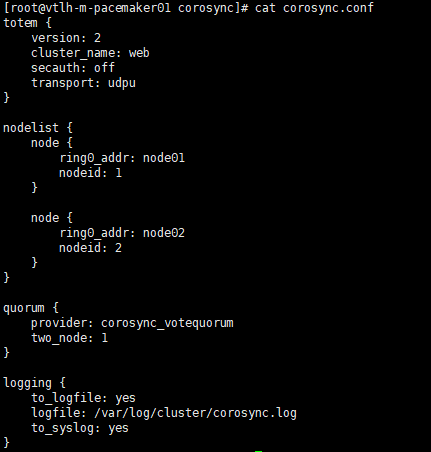
检查集群
#corosync-cfgtool -s #集群状态 #crm_verify -L -V #集群是否有错
# pcs property list #集群stonith及仲裁设置

drbd是主從資源,在配置主從資源之前必須先配置為基本資源,再配置為主從資源。
drbd是主从资源,多态资源
7.1.配置drbd的集群
a.创建基本资源 (用crm方式创建没成功,一直报错no configure错误,改用后面的pcs命令创建可以。)
查看drbd的ra:
#crm ra
#providers drbd
#meta ocf:heartbeat:drbd
#meta ocf:linbit:drbd
#crm configure
(configure)# primitive DRBD ocf:linbit:drbd params drbd_resource=drbd_data op start timeout=240 op stop timeout=100 op monitor role=Master interval=10s timeout=20s op monitor role=Slave interval=20s timout=20s
(configure)#verify
b.创建主从资源
(configure)#ms ms_drbd DRBD meta master-max=1 master-node-max=1 clone-node-max=1
(configure)#verify
(configure)#show ##查看资源。
(configure)# commit ##提交。
(configure)#status
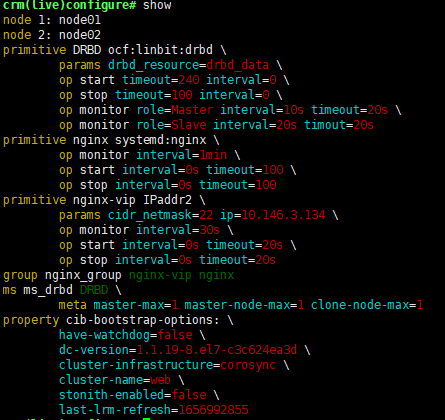

c.增加文件系统资源
#crm
(live)#configure
(configure)#primitive filemount ocf:heartbeat:Filesystem params device=/dev/drbd1 directory=/drbd_data fstype=xfs op start timeout=60
d.资源间亲缘关系
给文件系统类型和drbd做亲缘性绑定(inf为正数为接近,当位负数时候为分离)。
crm(live)configure #colocation filemount_with_ms_drbd inf: filemount msdrbd:Master
crm(live)configure #verify
e.资源顺序
做顺序约束,当drbd起来之后才对文件系统进行绑定:
crm(live)configure #order filemount_after_ms_drbd mandatory: ms_drbd:promote filemount:start
crm(live)configure #verify
crm(live)configure #commit
crm(live)configure #show


用pcs方式创建,经过验证可以。
pcs cluster cib pcs cluster cib drbd_cfg ##drbd_cfg自已起的配置名,并会存在当前文件夹中 ,使用-f 参数,将对资源的改动保存到drbd_cfg文件中,直到通过pcs cluster cib-push命令才会使整个cluster更新。 pcs -f drbd_cfg resource create DRBDData ocf:linbit:drbd drbd_resource=drbd_data op monitor interval=60s #DRBDData 是resource的名称(自己起),drbd_data是DRBD中配置的资源名称 pcs -f drbd_cfg resource master DRBDDataClone DRBDData master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true #DRBDDataClone是自己起的备用节点resource的名称 pcs -f drbd_cfg constraint colocation add DRBDDataClone with nginx-vip INFINITY #配置cluster使drbd_data跟随VIP运行在同一个节点上,Colocation 主要定义资源与资源间的位置关系位置约束,Pacemaker 首先会决定在哪个节点上启动 , 然后会决定 -f drbd_cfg resource show pcs cluster cib-push drbd_cfg --config pcs cluster cib fs_cfg pcs -f fs_cfg resource create DRBDFS Filesystem device="/dev/drbd1" directory="/drbd_data" fstype="xfs" #DRBDFS是自己起的名称;/dev/drbd1是对应的DRBD设备;/drbd_data 是要挂载的目录;xfs是文件系统类型 pcs -f fs_cfg constraint colocation add DRBDFS with DRBDDataClone INFINITY with-rsc-role=Master #位置约束,DRBDFS、DRBDDataClone; 文件系统要跟随DRBDDataClone在相同的节点启动。需要留意的是,colocation 对资源的启动顺序没有要求 pcs
pcs -f fs_cfg constraint order promote DRBDDataClone then start DRBDFS #顺序约束,先提升备,在挂载文件系统 pcs -f fs_cfg resource show pcs cluster cib-push fs_cfg --config ##提交配置 crm configure pcs status
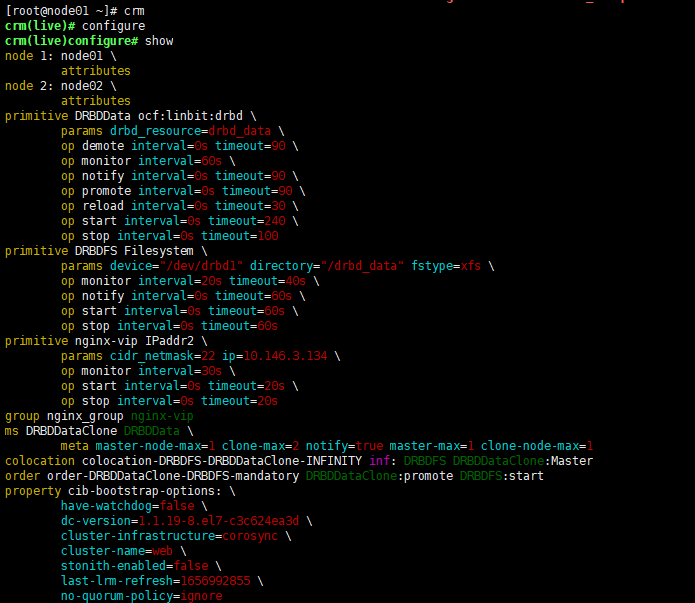
配置好后drbd一直处理脑裂状态
node02节点上查看


node01节点上查看
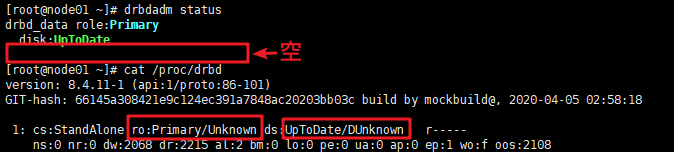
ss -atn 主、从节点上也查不到7788端口。
查看日志显示出现脑裂:
如下面两行关键信息:Split-Brain ; error receiving ReportState, e: -5 l: 0!
Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: block drbd1: Split-Brain detected but unresolved, dropping connection! Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: block drbd1: helper command: /sbin/drbdadm split-brain minor-1 Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: block drbd1: helper command: /sbin/drbdadm split-brain minor-1 exit code 0 (0x0) Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: conn( WFReportParams -> Disconnecting ) Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: error receiving ReportState, e: -5 l: 0! Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: ack_receiver terminated Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: Terminating drbd_a_drbd_dat Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: Connection closed Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: conn( Disconnecting -> StandAlone ) Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: receiver terminated Aug 8 08:37:27 vtlh-m-pacemaker01 kernel: drbd drbd_data: Terminating drbd_r_drbd_dat
处理:
状态为secondary的节点上 (如果两个都为primary,就先drbdadm secondary drbd_data) node02#drbdadm connect --discard-my-data drbd_data 状态为primary的节点上 node01#drbdadm connect dard_data
处理完成后
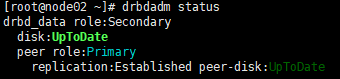
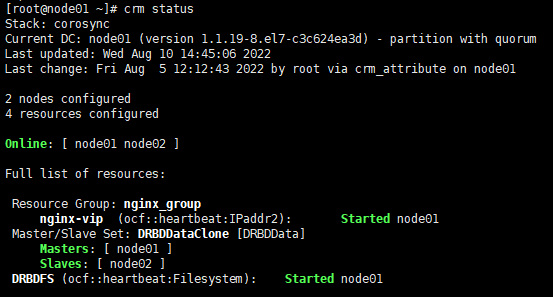
7.2.集群节点主备切换
a.切换前主节点在 node01
b.把node01切换成standby
node01# crm node standby 或用:pcs cluster standby node01
node01#crm status pcs status
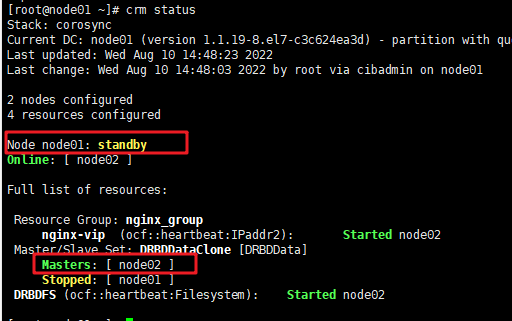
node01成为standby节点,此时它上面的drbd服务是停的,所以两端的drbd数据不会同步,即也是不一致的

在node02上查看


c. 把node01 上线
在node01上执行:
node01#crm node online
或#pcs cluster unstandby node01
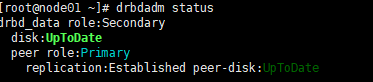
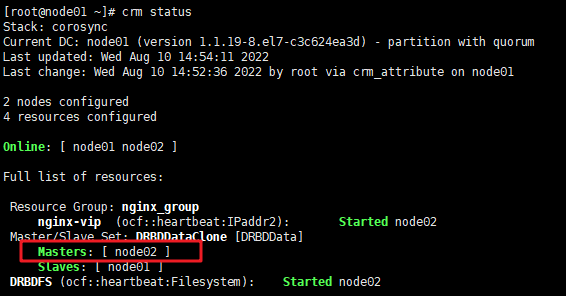
切换完成。
e.再次把node01切换成primary/Masters 验证drbd在node01恢复后数据否正常同步过来。

f.在node02上建的node02在node01上能看到,数据同步过来了

g.此时在node01上drbd监听端口正常

h.恢复node02节点
node01#pcs cluster unstandby node02
8.mariadb高可用配置(未验证,懒得弄了,跟前面差不多)
pcs resource create Mysql systemd:mariadbbinary="/usr/libexec/mysqld" config="/etc/my.cnf"datadir="/mnt/drbd/" pid="/var/run/mariadb/mariadb.pid" socket="/var/lib/mysql/mysql.sock"op start timeout=180s op stop timeout=180s op monitor interval=20s timeout=60s 配置资源关系 # pcs constraint colocation add Mysql vip INFINITY pcs constraintcolocation add vip dbFS INFINITY 设置启动顺序 # pcs constraintorder dbFS then Mysql
四、pcs常用命令配置示例
一、建立群集:
1、配置群集节点的认证as the hacluster user:
[shell]# pcs cluster auth node1 node2
2、创建一个二个节点的群集
[shell]# pcs cluster setup --name mycluster node1 node2
[shell]# pcs cluster start --all ## 启动群集
3、设置资源默认粘性(防止资源回切)
[shell]# pcs resource defaults resource-stickiness=100
[shell]# pcs resource defaults
4、设置资源超时时间
[shell]# pcs resource op defaults timeout=90s
[shell]# pcs resource op defaults
5、二个节点时,忽略节点quorum功能
[shell]# pcs property set no-quorum-policy=ignore
6、没有 Fencing设备时,禁用STONITH 组件功能
在 stonith-enabled="false" 的情况下,分布式锁管理器 (DLM) 等资源以及依赖DLM 的所有服务(例如 cLVM2、GFS2 和 OCFS2)都将无法启动。
[shell]# pcs property set stonith-enabled=false
[shell]# crm_verify -L -V ## 验证群集配置信息
二、建立群集资源
1、查看可用资源
[shell]# pcs resource list ## 查看支持资源列表,pcs resource list ocf:heartbeat
[shell]# pcs resource describe agent_name ## 查看资源使用参数,pcs resource describe ocf:heartbeat:IPaddr2
2、配置虚拟IP
[shell]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 \
ip="192.168.10.15" cidr_netmask=32 nic=eth0 op monitor interval=30s
3、配置Apache(httpd)
[shell]# pcs resource create WebServer ocf:heartbeat:apache \
httpd="/usr/sbin/httpd" configfile="/etc/httpd/conf/httpd.conf" \
statusurl="" op monitor interval=1min
4、配置Nginx
[shell]# pcs resource create WebServer ocf:heartbeat:nginx \
httpd="/usr/sbin/nginx" configfile="/etc/nginx/nginx.conf" \
statusurl="" op monitor interval=30s
5.1、配置FileSystem
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="/dev/sdb1" directory="/var/www/html" fstype="ext4"
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="-U 32937d65eb" directory="/var/www/html" fstype="ext4"
5.2、配置FileSystem-NFS
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="192.168.10.18:/mysqldata" directory="/var/lib/mysql" fstype="nfs" \
options="-o username=your_name,password=your_password" \
op start timeout=60s op stop timeout=60s op monitor interval=20s timeout=60s
6、配置Iscsi
[shell]# pcs resource create WebData ocf:heartbeat:iscsi \
portal="192.168.10.18" target="iqn.2008-08.com.starwindsoftware:" \
op monitor depth="0" timeout="30" interval="120"
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="-U 32937d65eb" directory="/var/www/html" fstype="ext4" options="_netdev"
7、配置DRBD
[shell]# pcs resource create WebData ocf:linbit:drbd \
drbd_resource=wwwdata op monitor interval=60s
[shell]# pcs resource master WebDataClone WebData \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="/dev/drbd1" directory="/var/www/html" fstype="ext4"
8、配置MySQL
[shell]# pcs resource create MySQL ocf:heartbeat:mysql \
binary="/usr/bin/mysqld_safe" config="/etc/my.cnf" datadir="/var/lib/mysql" \
pid="/var/run/mysqld/mysql.pid" socket="/tmp/mysql.sock" \
op start timeout=180s op stop timeout=180s op monitor interval=20s timeout=60s
9、配置Pingd,检测节点与目标的连接有效性
[shell]# pcs resource create PingCheck ocf:heartbeat:pingd \
dampen=5s multiplier=100 host_list="192.168.10.1 router" \
op monitor interval=30s timeout=10s
10、创建资源clone,克隆的资源会在全部节点启动
[shell]# pcs resource clone PingCheck
[shell]# pcs resource clone ClusterIP clone-max=2 clone-node-max=2 globally-unique=true ## clone-max=2,数据包分成2路
[shell]# pcs resource update ClusterIP clusterip_hash=sourceip ## 指定响应请求的分配策略为:sourceip
三、调整群集资源
1、配置资源约束
[shell]# pcs resource group add WebSrvs ClusterIP ## 配置资源组,组中资源会在同一节点运行
[shell]# pcs resource group remove WebSrvs ClusterIP ## 移除组中的指定资源
[shell]# pcs resource master WebDataClone WebData ## 配置具有多个状态的资源,如 DRBD master/slave状态
[shell]# pcs constraint colocation add WebServer ClusterIP INFINITY ## 配置资源捆绑关系
[shell]# pcs constraint colocation remove WebServer ## 移除资源捆绑关系约束中资源
[shell]# pcs constraint order ClusterIP then WebServer ## 配置资源启动顺序
[shell]# pcs constraint order remove ClusterIP ## 移除资源启动顺序约束中资源
[shell]# pcs constraint show ## 查看资源约束关系, pcs constraint --full
ftp-group内启停顺序:FTP-VIP--> FTP-LVM-->FTP-FS-->FTP (后启--->先启)
tomcat-group内启停顺序:TOMCAT-VIP-->TOMCAT-LVM-->TOMCAT-FS-->TOMCAT
2、配置资源位置(资源粘性)
[shell]# pcs constraint location WebServer prefers node11 ## 指定资源默认运行在某个节点(WebServer优先运行在node11上),如果写成node11=200,node12=20,同样有这个效果,资源会运行在node11上。node=50 指定增加的 score
[shell]# pcs constraint location WebServer avoids node11 ## 指定资源避开某个节点,node=50 指定减少的 score
[shell]# pcs constraint location remove location-WebServer ## 移除资源节点位置约束中资源ID,可用pcs config获取
[shell]# pcs constraint location WebServer prefers node11=INFINITY ## 手工移动资源节点,指定节点资源的 score of INFINITY(无穷大)
[shell]# crm_simulate -sL ## 验证节点资源 score 值
3、修改资源配置
[shell]# pcs resource update WebFS ## 更新资源配置
[shell]# pcs resource delete WebFS ## 删除指定资源
4、管理群集资源
[shell]# pcs resource disable ClusterIP ## 禁用资源
[shell]# pcs resource enable ClusterIP ## 启用资源
[shell]# pcs resource failcount show ClusterIP ## 显示指定资源的错误计数
[shell]# pcs resource failcount reset ClusterIP ## 清除指定资源的错误计数
[shell]# pcs resource cleanup ClusterIP ## 清除指定资源的状态与错误计数
四、配置Fencing设备,启用STONITH
1、查询Fence设备资源
[shell]# pcs stonith list ## 查看支持Fence列表
[shell]# pcs stonith describe agent_name ## 查看Fence资源使用参数,pcs stonith describe fence_vmware_soap
2、配置fence设备资源
[shell]# pcs stonith create ipmi-fencing fence_ipmilan \
pcmk_host_list="pcmk-1 pcmk-2" ipaddr="10.0.0.1" login=testuser passwd=acd123 \
op monitor interval=60s
mark:
If the device does not support the standard port parameter or may provide additional ones, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
If the device does not know how to fence nodes based on their uname, you may also need to set the special pcmk_host_map parameter. See man stonithd for details.
If the device does not support the list command, you may also need to set the special pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
If the device does not expect the victim to be specified with the port parameter, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
example: pcmk_host_argument="uuid" pcmk_host_map="node11:4;node12:5;node13:6" pcmk_host_list="node11,node12" pcmk_host_check="static-list"
3、配置VMWARE (fence_vmware_soap)
特别说明:本次实例中使用了第3项(pcs stonith create vmware-fencing fence_vmware_soap)这个指定pcmk配置参数才能正常执行Fencing动作。
3.1、确认vmware虚拟机的状态:
[shell]# fence_vmware_soap -o list -a vcenter.example.com -l cluster-admin -p -z ## 获取虚拟机UUID
[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -U ## 查看状态
[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -n
3.2、配置fence_vmware_soap
[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
port="node11" shell_timeout=60s login_timeout=60s op monitor interval=90s
[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
uuid="421dec5f-c484-3d69-ddfb-65af46530581" shell_timeout=60s login_timeout=60s op monitor interval=90s
[shell]# pcs stonith create vmware-fencing fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
pcmk_host_argument="uuid" pcmk_host_check="static-list" pcmk_host_list="node11,node12" \
pcmk_host_map="node11:421dec5f-c484-3d69-ddfb-65af46530581;node12:421dec5f-c484-3d69-ddfb-65af46530582" \
shell_timeout=60s login_timeout=60s op monitor interval=90s
注:如果配置fence_vmware_soap设备时用port=vm name在测试时不能识别,则使用uuid=vm uuid代替;
建议使用 pcmk_host_argument、pcmk_host_map、pcmk_host_check、pcmk_host_list 参数指明节点与设备端口关系,格式:
pcmk_host_argument="uuid" pcmk_host_map="node11:uuid4;node12:uuid5;node13:uuid6" pcmk_host_list="node11,node12,node13" pcmk_host_check="static-list"
4、配置SCSI
[shell]# ls /dev/disk/by-id/wwn-* ## 获取Fencing磁盘UUID号,磁盘须未格式化
[shell]# pcs stonith create iscsi-fencing fence_scsi \
action="reboot" devices="/dev/disk/by-id/wwn-0x600e002" meta provides=unfencing
5、配置DELL DRAC
[shell]# pcs stonith create dell-fencing-node11 fence_drac
.....
6、管理 STONITH
[shell]# pcs resource clone vmware-fencing ## clone stonith资源,供多节点启动
[shell]# pcs property set stonith-enabled=true ## 启用 stonith 组件功能
[shell]# pcs stonith cleanup vmware-fencing ## 清除Fence资源的状态与错误计数
[shell]# pcs stonith fence node11 ## fencing指定节点
7、管理tomcat
[shell]#pcs resource create tomcat ersweb statusurl= java_home=/usr/java/jdk1.6.0_12/ catalina_home=/usr/local/Ers/tomcat/ op monitor interval=30s
五、群集操作命令
1、验证群集安装
[shell]# pacemakerd -F ## 查看pacemaker组件,ps axf | grep pacemaker
[shell]# corosync-cfgtool -s ## 查看corosync序号
[shell]# corosync-cmapctl | grep members ## corosync 2.3.x
[shell]# corosync-objctl | grep members ## corosync 1.4.x
2、查看群集资源
[shell]# pcs resource standards ## 查看支持资源类型
[shell]# pcs resource providers ## 查看资源提供商
[shell]# pcs resource agents ## 查看所有资源代理
[shell]# pcs resource list ## 查看支持资源列表
[shell]# pcs stonith list ## 查看支持Fence列表
[shell]# pcs property list --all ## 显示群集默认变量参数
[shell]# crm_simulate -sL ## 检验资源 score 值
3、使用群集脚本
[shell]# pcs cluster cib ra_cfg ## 将群集资源配置信息保存在指定文件
[shell]# pcs -f ra_cfg resource create ## 创建群集资源并保存在指定文件中(而非保存在运行配置)
[shell]# pcs -f ra_cfg resource show ## 显示指定文件的配置信息,检查无误后
[shell]# pcs cluster cib-push ra_cfg ## 将指定配置文件加载到运行配置中
4、STONITH 设备操作
[shell]# stonith_admin -I ## 查询fence设备
[shell]# stonith_admin -M -a agent_name ## 查询fence设备的元数据,stonith_admin -M -a fence_vmware_soap
[shell]# stonith_admin --reboot nodename ## 测试 STONITH 设备
5、查看群集配置
[shell]# crm_verify -L -V ## 检查配置有无错误
[shell]# pcs property ## 查看群集属性
[shell]# pcs stonith ## 查看stonith
[shell]# pcs constraint ## 查看资源约束
[shell]# pcs config ## 查看群集资源配置
[shell]# pcs cluster cib ## 以XML格式显示群集配置
6、管理群集
[shell]# pcs status ## 查看群集状态
[shell]# pcs status cluster
[shell]# pcs status corosync
[shell]# pcs cluster stop [node11] ## 停止群集
[shell]# pcs cluster start --all ## 启动群集
[shell]# pcs cluster standby node11 ## 将节点置为后备standby状态,pcs cluster unstandby node11
[shell]# pcs cluster destroy [--all] ## 删除群集,[--all]同时恢复corosync.conf文件
[shell]# pcs resource cleanup ClusterIP ## 清除指定资源的状态与错误计数
[shell]# pcs stonith cleanup vmware-fencing ## 清除Fence资源的状态与错误计数
五、附录(摘抄网上一篇文章)
背景
对于一些重要应用,我们希望实现高可用(High-Availability). 在 RHEL7 中,可以使用 Pacemaker 达到这样的效果。
Pacemaker 是一个集群资源管理器,它负责管理集群环境中资源(服务)的整个生命周期。除了传统意义上的 Active/Passive 高可用,Pacemaker 可以灵活管理各节点上的不同资源,实现如 Active/Active,或者多活多备等架构。
下图是一个经典的 Active/Passive 高可用例子, Host1/Host2 只有一台服务器在提供服务,另一台服务器作为备机时刻准备着接管服务。
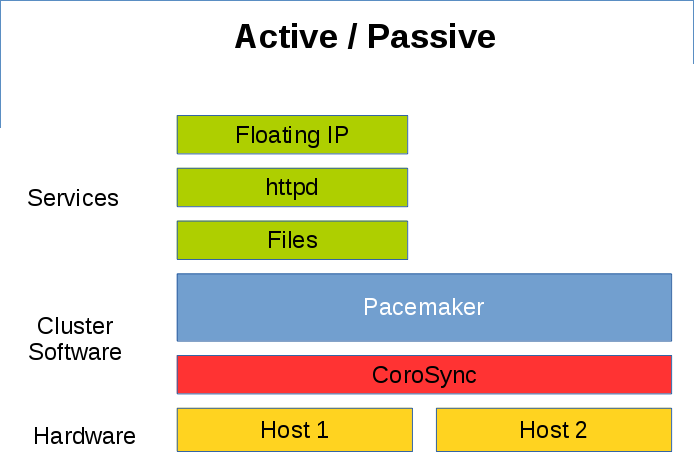 Pacemaker Active Passive
Pacemaker Active Passive
为了节省服务器资源,有时候可以采取 Shared Failover 的策略,两台服务器同时提供不同的服务,留有一台备用服务器接管失效的服务。
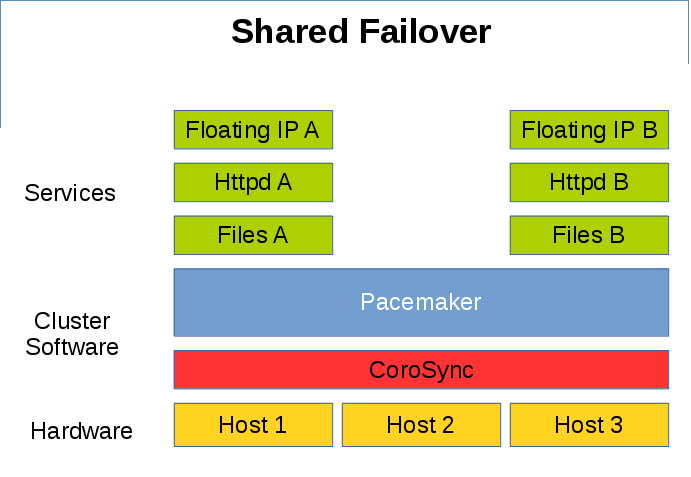 Pacemaker Shared Failover
Pacemaker Shared Failover
通过共享文件系统如 GFS2,也可以实现 Active/Active 的多活形式。
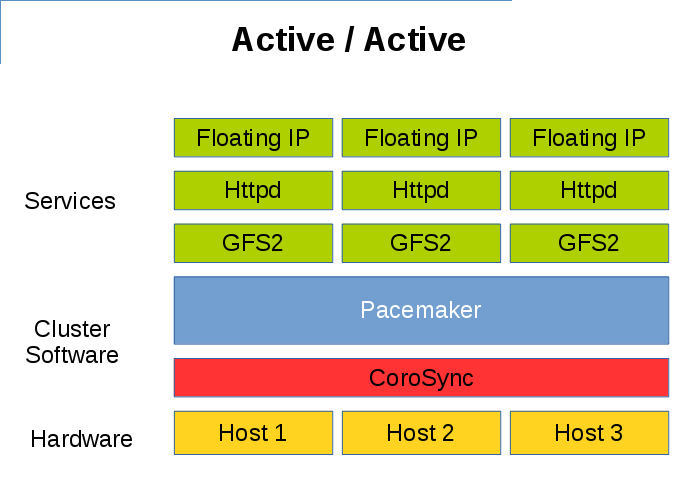 Pacemaker Active Active
Pacemaker Active Active
Pacemaker 内部构成
Pacemaker 主要由以下部件组成:
CIB - Cluster Information Base
CRMd - Cluster Resource Management daemon
LRMd - Local Resource Management daemon
PEngine - Policy Engine
STONITHd - Fencing daemon
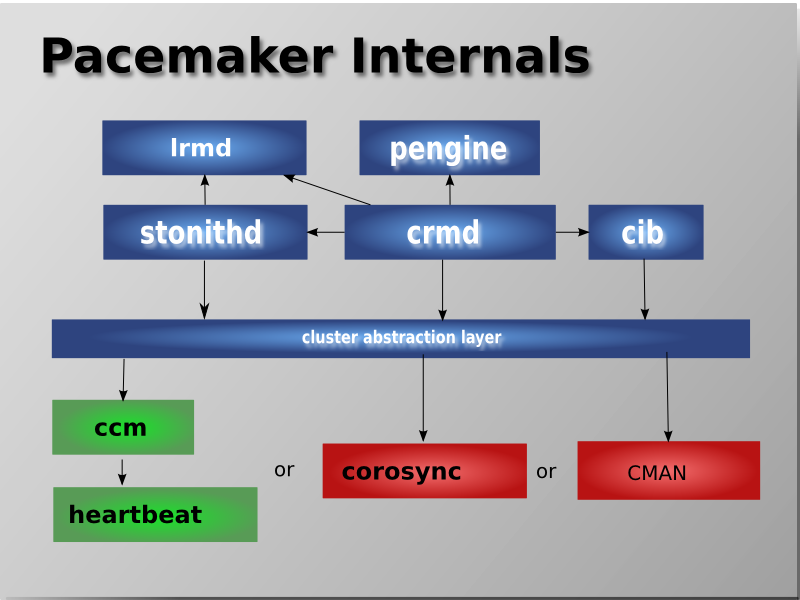
消息传递层 (Messaging and Infrastructure Layer)
这是最基础的一层,集群需要依靠这一层来正常工作。这一层主要的工作是向外发出“我还活着”的信息,以及其他交换信息。RHEL7 HA-Addon 使用的是 Corosync 项目。
资源管理层 (Resource Allocation Layer)
上面一层是资源管理层,这一层是 Pacemaker 的核心,也是结构相对复杂的一层。它由以下组件构成:
Cluster Resource Manager (CRM)
在这一层中,每个动作都需要 CRM 来进行沟通协调。在每个节点上,CRM 都会维护一个 CIB 来记录状态信息。
Cluster Information Base (CIB)
CIB 是一个 in-memory XML, 它记录着整个集群的配置和当前状态。每个节点上都有一个 CIB, DC 节点上的 CIB 是 Master CIB, 它会自动同步所有变更到其他节点上。
Designated Coordinator (DC)
每个节点上都运行着 CRM,其中一个节点的 CRM 会被选举为 DC。 DC 是集群中唯一可以决定集群层面可以做什么变化的 CRM,比如说 fencing 或者移动一个资源。
每当集群中的成员出现变化时,会自动重新选举 DC。
Policy Engine (PE)
在 DC 需要对事件进行应对时(比如集群状态出现变化), PE 会根据配置和当前的状态,计算出集群应有的下一个状态,以及行动计划 (transition graph),DC 会根据行动计划执行相应的动作。
Local Resource Manager (LRM)
LRM 是本地资源管理器,它会根据 CRM 的指令,调用本地的 Resource Agents,实现对资源的启动/停止/监控动作,它还会将这些动作的结果反馈给本地的 CRM.
Shoot The Other Node In The Head (Stonith)
工作流 - 这些组件是怎样协同工作的?
- 在集群启动时,首先会建立起 Corosync 的通信,使节点能互相“看见对方”。
- 每一个节点上都会启动一个 crmd 后台进程,它们会自动选举其中一个节点上的 crmd 作为 DC. DC 上的 CIB 是 Master CIB, 它的变更会自动同步到其他节点上。
- 很多动作,比如增加/移除资源,增加/移除资源约束,都会引起集群层面的变化。比如,我们要添加一个虚拟IP资源。我们可以在任一节点上,通过管理工具添加一个虚拟IP资源,它会告知 DC,DC 会修改相应的 CIB 并同步到所以节点中。
- 基于变化了的 CIB, PE 会计算当前配置和状态对应的下一个应有的状态,同时 PE 会计算出实现这个状态的行动计划,告知 DC.
- DC 得到行动计划后,会想相应节点的 CRM 发送指令,相应节点的 CRM 接收到指令后会调用它本地的 LRM 对资源进行操作。
- 每个节点的 LRM 进行完操作后,会将结果报告本地的 CRM,随后每个节点的 CRM 会将结果汇报给 DC, DC 再进行后续决定。
- 在某些情况下,需要 fence 某个节点(比如丢心跳的时候),这时候会调用 stonith 来进行操作。
成员管理 - Corosync 2.x 特性
要使集群工作,存活的节点数量必须要满足 quorum = expected vote / 2 + 1, 即需要集群中大于半数的节点才能正常提供服务。
在 RHEL7 中, Corosync 使用 UDPU 作为默认的通信协议。(RHEL6 的 cman + rgmanager 架构中,默认使用 multicast). 如果需要改为 Multicast, 可以在 /etc/corosync/corosync.conf 中进行修改。
RHEL7 中使用的是 Corosync 2. 相对与 Corosync/cman, 它提供了以下的新选项。
two_node
two_node 是从 cman 时代就开始存在的选项。它是为“两节点集群”而设计的。按照正常计算,两节点集群需要获得2票(两个节点都存活)才能工作, quorum = 2 / 2 + 1 = 2. 而这就无法达到高可用的效果。
设置 two_node 模式后,集群只需要1票即可工作。为了避免 split-brain 的问题,两个节点的 fence 和心跳需要使用同一个网络。(如果某个节点断网了,它就不能去 fence 另一节点,而另一个未断网的节点则可以 fence 该节点)。
设置了 two_node 之后, wait_for_all 选项也会默认开启,以避免 fence_loop.
wait_for_all
如果全新启动一个集群(全新启动:集群启动前所有节点都没有加入这个集群),wait_for_all 会对比已加入节点的数量是否与 expected vote 相等,在所有节点都顺利加入集群后,才会变成 quorate 状态。
如果不设置 wait_for_all, 只要节点数到达 expect_vote/2 + 1 这部分节点就会开始提供服务。对于两节点的集群,wait_for_all 非常重要,如果不设置 wait_for_all,会导致 fence loop.
auto_tie_breaker
在遇到 50/50 的脑裂情况的时候,比如4节点集群出现 2 个节点 + 2 个节点 的分裂情况,按照 quorum = expected vote / 2 + 1, 两边都不能达到 quorate 的状态。 默认配置下, auto_tie_breaker 可以使拥有“最小节点序号”的一边达到 quorate 状态,使之能继续提供服务。
Auto_tie_breaker 只应该用于偶数节点数的集群,但不能用于 2 节点集群。(2 节点集群应使用 two_node 选项)
last_man_standing & last_man_standing_window
假设有个8节点集群,在默认情况下,它需要 8/2+1=5 个节点在集群中才能提供服务。也就是说,好不容易买了8台服务器,而只能容忍3台挂掉。在某些情况下,我们希望这个8节点集群能在只剩2个节点的时候还能提供服务,这时候 last_man_standing 就能派上用场了。
设置了 last_man_standing 之后,如果集群中有节点被 fence,剩余节点中的 expected votes 会在 last_man_standing_window (默认10秒)后,自动减少至当前节点数量。要留意的是,剩余节点的数量首先需要达到 quorate 才能进行这样的减少 expected_votes 的动作。通过这样的操作,能允许 quorate 一边的节点数量逐渐减少至 2 还能提供服务。
corosync_votequorum 的 man 手册里有这么个例子:
provider: corosync_votequorum
expected_votes: 8
wait_for_all: 1
last_man_standing: 1
last_man_standing_window: 10000
}
Example chain of events:
a. The cluster is fully operational with 8 nodes. (expected_votes: 8 quorum: 5)
b. 3 nodes die, cluster is quorate with 5 nodes.
c. After last_man_standing_window timer expires, expected_votes and quorum are recalculated. (expected_votes: 5 quorum: 3)
d. At this point, 2 more nodes can die and cluster will still be quorate with 3.
e. Once again, after last_man_standing_window timer expires expected_votes and quorum are recalculated. (expected_votes: 3 quorum: 2)
f. At this point, 1 more node can die and cluster will still be quorate with 2.
g. After one more last_man_standing_window timer (expected_votes: 2 quorum: 2)
在正常情况下, last_man_standing 只能允许节点数量减少至 2。如果需要省下 1 个节点也能提供服务,则需要同时设置 auto_tie_breaker.
资源约束 - Constrains
相比于 rgmanager 通过将资源组合成服务的管理方式, pacemaker 可以直接对资源设置各类约束,使资源管理更加灵活。
Pacemaker 可以对资源设置以下约束(Constrains):
order
order 主要定义资源的启动/停止顺序。
在 pcs 中,定义 order 约束的命令是:
比如, 设置 start then start ,当需要启动 的时候, 会先被启动,且要等到 启动完成后, 才会被启动。如果没有特别设置(默认 symmetrical=true),设置了启动顺序后,停止资源的顺序也会与之对称,即先停 才能停 .
location
location 主要定义资源应该在哪个节点上启动。
在 pcs 中,定义 location 约束的命令是:
<resource id> prefers <node[=score]>
<resource id> avoids <node[=score]>
在 pacemaker 中,每个 <资源,节点> 的组合都会有一个对应的分数(score), pacemaker 会把资源启动在分数最高的可用节点上。在命令中,如果不指定分数, prefers 默认会将分数设置为 INFINITY, avoids 则会将分数设置为 -INFINITY.
比如,设置
那么,在 pcmk-node1 可用的情况下, vip-1 将会在 pcmk1-node1 上启动。
colocation
colocation 主要定义资源与资源间的位置关系。
在 pcs 中,可以通过以下命令设置 colocation 约束:
Pacemaker 首先会决定在哪个节点上启动 , 然后
rules
通常用不上,如有需要请参考官方文档: https://clusterlabs.org/doc/en-US/Pacemaker/1.1/html/Pacemaker_Explained/ch08.html
特殊资源 - resource group
Resource group 是一种特殊的资源。它默认包含了 order + colocation. 比如,一个 resource group 包含以下 resources:
- httpd
- vip
这意味着,启动顺序是 filesystem -> httpd -> vip,停止顺序是 vip -> httpd -> filesystem. 而且这3个资源会在同一个节点上运行。
设置资源组之后,无须再对组内资源配置约束条件。
支持范围与限制
搭建一个集群,首先要符合国家相关法律法规,然后需要满足以下基本条件:
- 在 RHEL7 的支持策略中,节点数量不能超过 16 个;
- // TODO 节点通信延时?
- 节点间不能通过网线直连,必须经过交换机;
- 必须要有 Power fence 的设备,比如 iLo 控制卡,VMware soap 等;
更详细的支持策略,可参考:
https://access.redhat.com/articles/2912891
Demo: 搭建一个HA集群
准备工作
配置各节点的 hostname
在搭建集群之前,首先要给个节点分配一个静态IP,然后将各节点的 hostname 和 IP 信息写到 /etc/hosts 中。写到 /etc/hosts 中而不是使用 DNS 的原因,是 DNS 可能会有很长延迟,或者 DNS 可能会因为各种原因不返回,这将可能导致心跳丢失,pacemaker 服务不可用等问题。
192.168.122.12 node2 node2.example.com
配置 NTP 保证各节点时间准确
每个节点的时间需要同步,否则出现问题的时候将难以从日志中对比线索。
安装所需软件包
在 RHEL7 中,可以通过以下命令安装 pacemaker 所需的软件包:
另外,集群中各节点的软件版本,比如 kernel, corosync, pacemaker 应该保持一致。
启动 pcsd 服务
[root@node1 ~]# systemctl start pcsd
[root@node2 ~]# systemctl enable pcsd
[root@node2 ~]# systemctl start pcsd
防火墙
在每个节点上执行以下命令,允许心跳以及pcs管理工具的通信。
[root@node2 ~]# firewall-cmd --add-service=high-availability
[root@node1 ~]# firewall-cmd --permanent --add-service=high-availability
[root@node2 ~]# firewall-cmd --permanent --add-service=high-availability
认证各节点的 pcs
认证各个节点的 pcs, 使得 pcs 这个管理工具能访问各节点。(需要在所有节点上给 hacluster 设置相同的密码)
[root@node2 ~]# echo redhat | passwd --stdin hacluster
在任一节点执行,建立起各个节点之间的认证关系。
Username: hacluster
Password:
node1: Authorized
node2: Authorized
建立集群
在任一节点执行:
这个命令会创建一个名为 mycluster 的集群,其中包含 node1 和 node2 两个节点。--start 表示在集群建立完成后自动启动该集群。
通过 pcs status 命令,可以验证该集群已经建立并正常通信。
Cluster name: mycluster <<---------
WARNING: no stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: node2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Fri Aug 18 13:10:49 2017
Last change: Fri Aug 18 13:10:42 2017 by hacluster via crmd on node2
2 nodes configured
0 resources configured
Online: [ node1 node2 ] <<---------
配置 Fence - Stonith
当节点出现故障时,Pacemaker 会进行资源切换,把运行在故障节点上的资源切换到正常运行的节点上,以保证服务的高可用。
如果节点没有响应,处于“大多数”(quorate)状态的节点会杀掉没有响应的节点,以:
1. 使集群成员状态明确(不希望有节点处于“生死未卜”状态);
2. 确保没有响应的节点不能够访问存储;
杀掉节点的行为我们可以成为 fence. Pacemaker 中, fence 由 Stonith 进行管理。
手动测试 fence agent
在 KVM 实验环境中,可以使用 fence_xvm 作为 fence agent.
1. 把 KVM Host 中预先生成的 /etc/cluster/fence_xvm.key 复制到 node1 和 node2 的 /etc/cluster/fence_xvm.key 中;
2. 在两个节点上放行 1229 端口:
[root@node2 ~]# firewall-cmd --permanent --add-port="1229/udp" --add-port="1229/tcp"
[root@node1 ~]# firewall-cmd --reload
[root@node2 ~]# firewall-cmd --reload
3. 测试能否通过 fence_xvm 获取虚拟机信息:
Status: ON
[root@node2 ~]# fence_xvm -H feichashao_RHEL74_node1 -o status
Status: ON
4. 尝试通过 fence agent 进行 fence. 可以观察到, node2 会被 fence. 同理,测试对 node1 的 fence.
配置 stonith
确认 fence agent 没有问题之后,可以使用 pcs 配置 stonith.
[root@node1 ~]# pcs stonith create fence_node2 fence_xvm port=feichashao_RHEL74_node2 pcmk_host_list=node2
测试能否通过 stonith 进行 fence.
Node: node2 fenced
拔网线测试
如果使用物理机,可以通过拔网线的方式来测试当心跳丢失后,节点能否被顺利 fence. 切勿使用如"ifdown"/"ip link down"的方式进行测试。
添加服务 - Resource
[root@node2 ~]# yum install -y httpd
[root@node1 ~]# pcs resource create httpd apache configfile="/etc/httpd/conf/httpd.conf" --group webservice
[root@node1 ~]# pcs resource create vip IPaddr2 ip=192.168.122.11 cidr_netmask=24 --group webservice
[root@node1 ~]# pcs resource
Resource Group: webservice
html-fs (ocf::heartbeat:Filesystem): Started node1
httpd (ocf::heartbeat:apache): Started node1
vip (ocf::heartbeat:IPaddr2): Started node1
测试验证
测试能否通过vip访问网页服务。
This is a HA web server.
测试 httpd 意外退出时能否重启
## /var/log/messages
Aug 19 19:41:34 node1 apache(httpd)[9201]: INFO: apache not running
Aug 19 19:41:34 node1 crmd[1671]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Aug 19 19:41:34 node1 pengine[1670]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:41:34 node1 pengine[1670]: notice: Recover httpd#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Restart vip#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Calculated transition 158, saving inputs in /var/lib/pacemaker/pengine/pe-input-57.bz2
Aug 19 19:41:34 node1 pengine[1670]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:41:34 node1 pengine[1670]: notice: Recover httpd#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Restart vip#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Calculated transition 159, saving inputs in /var/lib/pacemaker/pengine/pe-input-58.bz2
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating stop operation vip_stop_0 locally on node1
Aug 19 19:41:34 node1 IPaddr2(vip)[9247]: INFO: IP status = ok, IP_CIP=
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of stop operation for vip on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating stop operation httpd_stop_0 locally on node1
Aug 19 19:41:34 node1 apache(httpd)[9302]: INFO: apache is not running.
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of stop operation for httpd on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating start operation httpd_start_0 locally on node1
Aug 19 19:41:34 node1 apache(httpd)[9349]: INFO: AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using node1.example.com. Set the 'ServerName' directive globally to suppress this message
Aug 19 19:41:34 node1 apache(httpd)[9349]: INFO: Successfully retrieved http header at http://localhost:80
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of start operation for httpd on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating monitor operation httpd_monitor_10000 locally on node1
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating start operation vip_start_0 locally on node1
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: Adding inet address 192.168.122.11/24 with broadcast address 192.168.122.255 to device ens3
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: Bringing device ens3 up
Aug 19 19:41:34 node1 apache(httpd)[9433]: INFO: Successfully retrieved http header at http://localhost:80
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: /usr/libexec/heartbeat/send_arp -i 200 -c 5 -p /var/run/resource-agents/send_arp-192.168.122.11 -I ens3 -m auto 192.168.122.11
Aug 19 19:41:38 node1 crmd[1671]: notice: Result of start operation for vip on node1: 0 (ok)
Aug 19 19:41:38 node1 crmd[1671]: notice: Initiating monitor operation vip_monitor_10000 locally on node1
Aug 19 19:41:38 node1 crmd[1671]: notice: Transition 159 (Complete=11, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-58.bz2): Complete
Aug 19 19:41:38 node1 crmd[1671]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
Aug 19 19:41:44 node1 apache(httpd)[9652]: INFO: Successfully retrieved http header at http://localhost:80
[root@node1 ~]# curl 192.168.122.11
This is a HA web server.
在 KVM 中,对 node1 按下“暂停”键,模拟 node1 无响应的情况。
Aug 19 19:58:04 node2 corosync[1628]: [TOTEM ] A processor failed, forming new configuration.
Aug 19 19:58:05 node2 corosync[1628]: [TOTEM ] A new membership (192.168.122.230:36) was formed. Members left: 1
Aug 19 19:58:05 node2 corosync[1628]: [TOTEM ] Failed to receive the leave message. failed: 1
Aug 19 19:58:05 node2 corosync[1628]: [QUORUM] Members[1]: 2
Aug 19 19:58:05 node2 corosync[1628]: [MAIN ] Completed service synchronization, ready to provide service.
Aug 19 19:58:05 node2 stonith-ng[1637]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 pacemakerd[1635]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 cib[1636]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 cib[1636]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 attrd[1639]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 attrd[1639]: notice: Removing all node1 attributes for peer loss
Aug 19 19:58:05 node2 attrd[1639]: notice: Lost attribute writer node1
Aug 19 19:58:05 node2 attrd[1639]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 crmd[1641]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 crmd[1641]: warning: Our DC node (node1) left the cluster
Aug 19 19:58:05 node2 crmd[1641]: notice: State transition S_NOT_DC -> S_ELECTION
Aug 19 19:58:05 node2 stonith-ng[1637]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 crmd[1641]: notice: State transition S_ELECTION -> S_INTEGRATION
Aug 19 19:58:05 node2 crmd[1641]: warning: Input I_ELECTION_DC received in state S_INTEGRATION from do_election_check
Aug 19 19:58:07 node2 pengine[1640]: warning: Node node1 will be fenced because the node is no longer part of the cluster
Aug 19 19:58:07 node2 pengine[1640]: warning: Node node1 is unclean
Aug 19 19:58:07 node2 pengine[1640]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action fence_node1_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action html-fs_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action httpd_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action vip_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Scheduling Node node1 for STONITH
Aug 19 19:58:07 node2 pengine[1640]: notice: Move fence_node1#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move html-fs#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move httpd#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move vip#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: warning: Calculated transition 0 (with warnings), saving inputs in /var/lib/pacemaker/pengine/pe-warn-0.bz2
Aug 19 19:58:07 node2 crmd[1641]: notice: Requesting fencing (reboot) of node node1
Aug 19 19:58:07 node2 crmd[1641]: notice: Initiating start operation fence_node1_start_0 locally on node2
常见错误排查
心跳丢失
心跳丢失主要的现象是节点被 fence,随之发生资源切换。
发生心跳丢失,首先需要排查网络情况,心跳丢失很有可能是由于网络错误或者拥塞导致的。另外需要排查系统负载,如果系统负载过高使得 corosync 没有被及时调度,那么 corosync 可能来不及发出心跳,导致被其他节点 fence.
接下来还可以排查节点的电源情况,以及是否发生过 kernel panic.
对于网络问题,可以在搭建集群的时候,通过配置网卡 bonding 或者 冗余心跳 (rrp)来预防。
fence 失败
fence 失败的主要现象是节点无法被 fence,导致其他节点无法启动资源。
可以查看 stonith 相关日志来排查原因。
Aug 21 14:39:53 node1 crmd[23707]: notice: Peer node2 was not terminated (reboot) by <anyone> for node1: No route to host (ref=4d6457ee-cef8-4a20-9891-3b7c0c1c56d7) by client stonith_admin.25479
资源切换/资源无法启动
当出现了资源 monitor 失败或者资源无法启动,可以检查 crmd/lrmd 相关的日志,查看失败原因。
Aug 19 19:58:10 node2 crmd[1641]: notice: node2-html-fs_start_0:67 [ mount: can't find UUID="df102cd7-adb0-4272-a079-8c194f74408e"\nocf-exit-reason:Couldn't mount filesystem -U df102cd7-adb0-4272-a079-8c194f74408e on /var/www/html\n ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号