opencv-python 车牌检测和识别
首先利用级联分类器把车牌位置找到取出来,然后用ocr进行车牌识别。
1 OCR之Tesseract安装
Tesseract安装可以参考这个链接: https://blog.csdn.net/m0_53192838/article/details/127432761
写的比较详细,我在使用的时候有一个报错有点意思,记录一下:
Tesseract ocr识别报错:tesseract is not installed or it‘s not in your PATH
已经安装好tesseract,python中的pytesseract也装好了,但是代码里面用pytesseract的时候报错了,看起来是路径有问题,但是环境变量是已经配置好了的。
网上分析是pytesseract.py文件里的路径有问题。
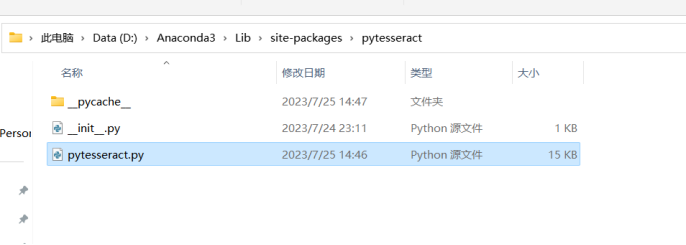
把文件中的路径 tesseract_cmd = ‘tesseract’ 改为本地的绝对路径就行
tesseract_cmd = r ’D\Tesseract_ocr\tesseract.exe’
2 车牌检测和识别
网上找了三幅带有车牌的图片,肉眼看起来都比较清晰,作为此次车牌识别的原图。



首先用opencv的级联分类器把车牌提取出来,然后可以进行适当的形态学操作方便ocr更好的识别,然后直接用pytesseract进行识别就行了。
import cv2
import numpy as np
import pytesseract
#创建级联分类器
car = cv2.CascadeClassifier('./haarcascade_russian_plate_number.xml')
img = cv2.imread('./car1.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3,3)) #形态学结构元
car_nums = car.detectMultiScale(gray) #车牌检测(检测出来的框偏大)
for car_num in car_nums:
(x,y,w,h) = car_num
cv2.rectangle(img,(x,y),(x+w,y+h),[0,0,255],2) #用矩形把车牌框起来
roi = gray[y:y+h,x:x+w] #把车牌图片提取出来
_,roi_thresh = cv2.threshold(roi,0,255,cv2.THRESH_BINARY | cv2.THRESH_OTSU) #对提取的车牌二值化
open_img = cv2.morphologyEx(roi_thresh,cv2.MORPH_OPEN,kernel) #形态学开操作(二值化后效果还是差点)
cv2.imshow('open_img',open_img)
print(pytesseract.image_to_string(open_img,lang='chi_sim+eng',config='--psm 7 --oem 3')) # 进行ocr识别
cv2.imshow('car',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
识别结果如下:

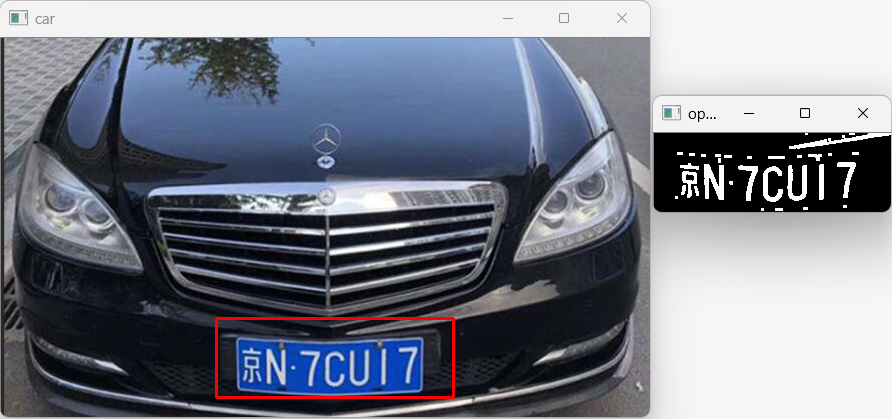

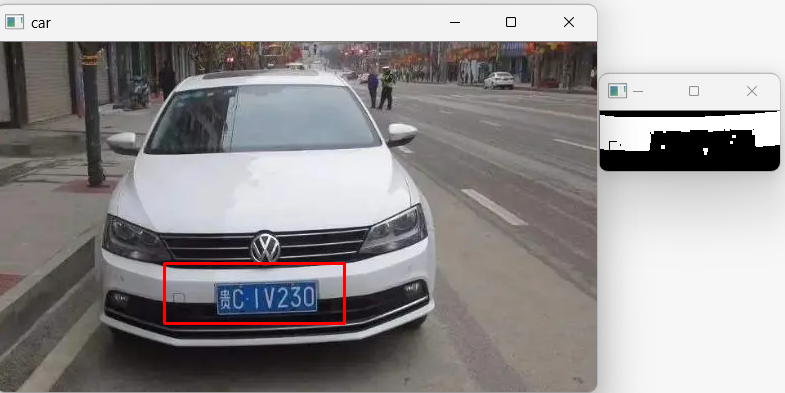
总体来说,效果都不是很好(第三个车牌识别失败),还可以进行其他形态学操作尝试,还有部分原因是车牌框太大了,干扰比较多。
通过观察,车牌的颜色都比较固定,且和车身差距比较大,可以用之前的颜色mask方法来提取车牌(形态学操作--小狗提取优化),然后进行适当形态学操作,再进行轮廓和轮廓外接矩形的计算,然后再提取车牌,这样提取的车牌框应该会更准确一些。
import cv2
import numpy as np
import pytesseract
img = cv2.imread('./car2.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# print(img.shape)
HSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #转换到hsv空间
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3,3)) #形态学结构元
LowerBlue = np.array([90, 190, 100]) #检测hsv的上下限(蓝色车牌)
UpperBlue = np.array([130, 230, 200])
#inRange 函数将颜色的值设置为 1,如果颜色存在于给定的颜色范围内,则设置为白色,如果颜色不存在于指定的颜色范围内,则设置为 0
mask = cv2.inRange(HSV,LowerBlue,UpperBlue) #车牌mask
cv2.imshow('mask',mask)
dilate = cv2.morphologyEx(mask,cv2.MORPH_DILATE,kernel,iterations=4) #形态学膨胀和开操作把提取的蓝色点连接起来
morph = cv2.morphologyEx(dilate,cv2.MORPH_CLOSE,kernel,iterations=6)
cv2.imshow('morph',morph)
_,contours,_ = cv2.findContours(morph,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) #找车牌的轮廓,只找外轮廓就行
# print(len(contours))
img_copy = img.copy()
cv2.drawContours(img_copy,contours,-1,[0,0,255],2) #把轮廓画出来
cv2.imshow('img_copy',img_copy)
rect = cv2.boundingRect(contours[0]) #用矩形把轮廓框出来(轮廓外接矩形)
(x,y,w,h) = rect
cv2.rectangle(img,(x,y),(x+w,y+h),[0,0,255],2)
cv2.imshow('car',img)
roi_img = gray[y:y+h,x:x+w] #提取车牌区域进行ocr识别
# _,roi_thresh = cv2.threshold(roi_img,0,255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# open_img = cv2.morphologyEx(roi_thresh,cv2.MORPH_OPEN,kernel) #适当的形态学操作提高识别率
# cv2.imshow('open_img',open_img)
print(pytesseract.image_to_string(roi_img,lang='chi_sim+eng',config='--psm 8 --oem 3')) #ocr识别
cv2.waitKey(0)
cv2.destroyAllWindows()





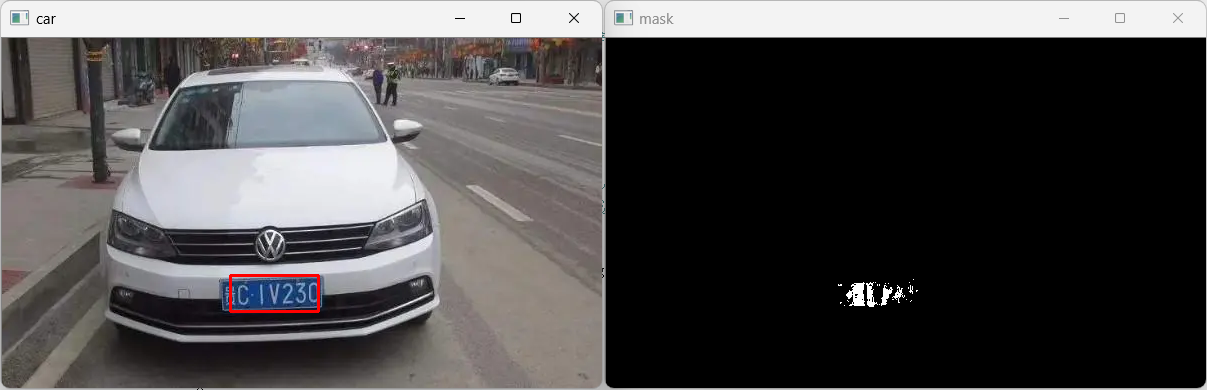
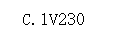
车牌框比较准确,识别效果相对好了不少,针对具体问题还可以继续微调形态学和 inRange 的范围参数,提高识别率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号