

[docker]docker实现原理
一,简介
二,Docker Engine
三,Docker架构
四,底层技术
启动一个容器实例,需要用到的最主要的基础知识包括Control groups(控制组),Namespaces(命名空间),Union file systems(联合文件系统),Container format(容器格式)
以下内容对三种技术做简略的介绍
1, cgroup
此处参考内容有: https://time.geekbang.org/column/article/14642, https://docs.docker.com/get-started/overview/
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。我们重点探讨它与容器关系最紧密的“限制”能力,并通过一组实践来带你认识一下 Cgroups。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
在 Ubuntu 20.04 机器里,我可以用 mount 指令把它们展示出来,这条命令是:
$ mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct) cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
它的输出结果,是一系列文件系统目录。如果你在自己的机器上没有看到这些目录,那你就需要自己去挂载 Cgroups,具体做法可以自行 Google。
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。
而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
2, namespace
此处参考内容有: https://time.geekbang.org/column/article/14642, https://docs.docker.com/get-started/overview/
Namespace 的使用方式:它其实只是 Linux 创建新进程的一个可选参数。
我们知道,在 Linux 系统中创建线程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。
而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
当然,我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID Namespace 里的具体情况。
而除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
很多人会把 Docker 项目称为“轻量级”虚拟化技术的原因,实际上就是把虚拟机的概念套在了容器上。可是这样的说法,却并不严谨。
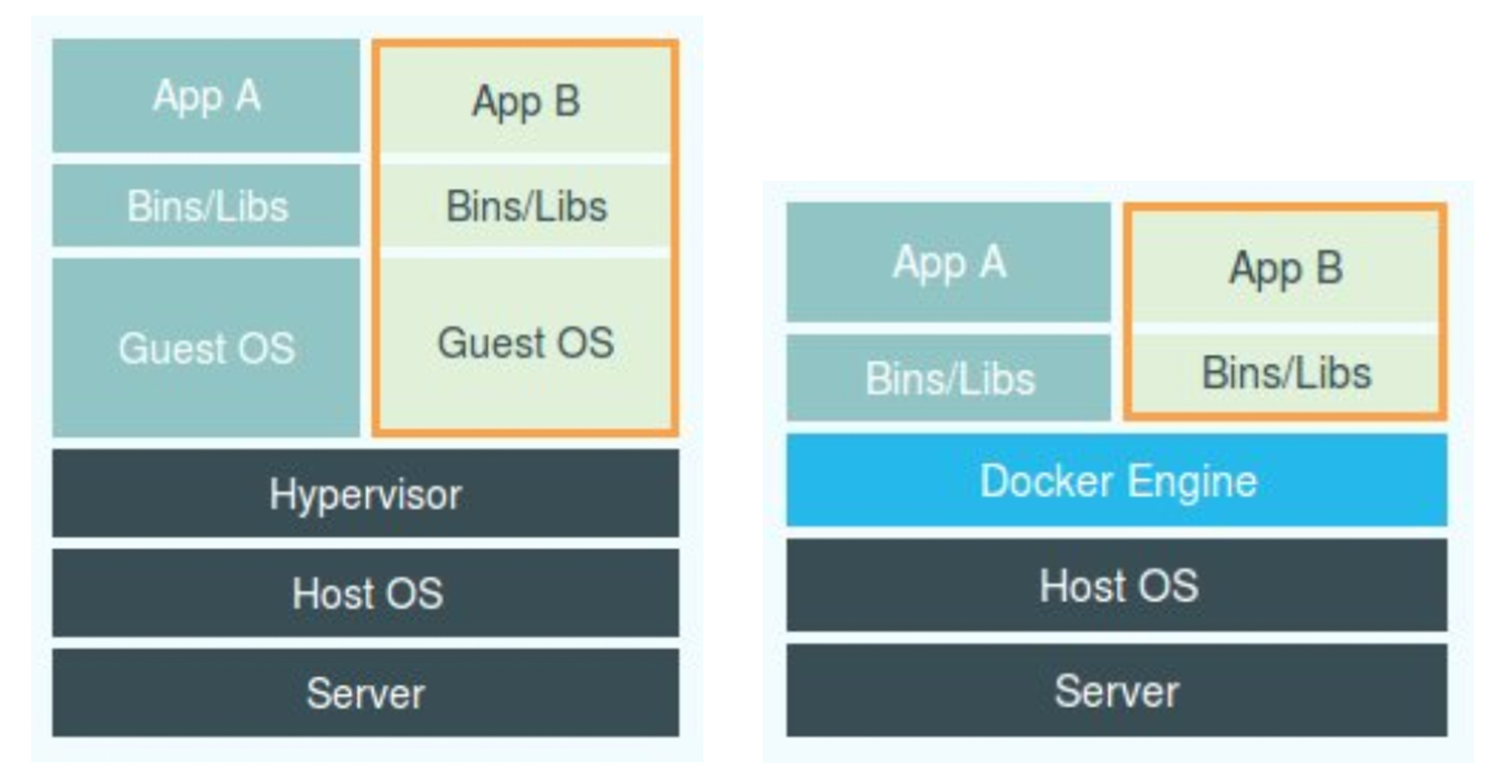
上图是虚拟化和容器的对比图(注:在这个对比图里,我们应该把 Docker 画在跟应用同级别并且靠边的位置。这意味着,用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。)
在理解了 Namespace 的工作方式之后,你就会明白,跟真实存在的虚拟机不同,在使用 Docker 的时候,并没有一个真正的“Docker 容器”运行在宿主机里面。
Docker 项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。
这时,这些进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。
以下为docker官方文档的解释
docker使用一种叫做namespace的技术来提供名为container的隔离工作区,当你开始运行一个容器,docker会为该容器创建一组命名空间.
这些命名空间提供了一个隔离层,容器的各个面都被限制在单独的命名空间中运行,并且其访问边界也被限制在相应的命名空间中.
Docker Engine在linux中使用如下的命名空间:
- pid namespace: 进程隔离(PID: Process ID).
- net namespace: 管理网络接口,网络隔离
- ipc namespace: 管理对ipc资源的访问 (IPC: 进程间通信).
- mnt namespace: 管理文件系统挂载点(MNT:mount)
- uts namespace: 隔离内核和版本标识符(UTS: Unix Timesharing System).which defines the system name and domain

