运行期优化--逃逸分析
在《深入理解Java虚拟机中》关于Java堆内存有这样一段对逃逸分析的描述:
那么究竟怎么理解逃逸分析?我们先来看一个例子
运行期优化示例
两层循环,内层循环创建1000次对象,外层循环对内层循环进行计时统计。



public class JIT1 { public static void main(String[] args) { for (int i = 0; i < 200; i++) { long start = System.nanoTime(); for (int j = 0; j < 1000; j++) { new Object(); } long end = System.nanoTime(); System.out.printf("%d\t%d\n",i,(end - start)); } } }
运行结果
运行时间随着次数不断下降,最终到达三位数。

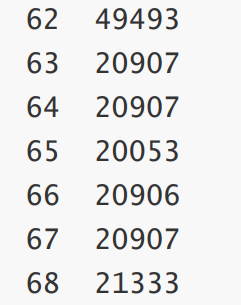

然后可以使用 -XX:- DoEscapeAnalysis 关闭逃逸分析,再运行刚才的示例观察结果,会发现在100多次后运行时间达不到3位数。
原因是什么呢?
JVM 将执行状态分成了 5 个层次:
0 层,解释执行(Interpreter)
1 层,使用 C1 即时编译器编译执行(不带 profiling)
2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
4 层,使用 C2 即时编译器编译执行
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的 回边次数】等
即时编译器(JIT)与解释器的区别
(1)解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释。
(2)JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需 再编译。
(3)解释器是将字节码解释为针对所有平台都通用的机器码。
(4)JIT 会根据平台类型,生成平台特定的机器码。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由 来),刚才的一种优化手段称之为【逃逸分析】,发现新建的对象是否逃逸。可以使用 -XX:- DoEscapeAnalysis 关闭逃逸分析,再运行刚才的示例观察结果。
参考资料:https://docs.oracle.com/en/java/javase/12/vm/java-hotspot-virtual-machine-performance-enhancements.html#GUID-D2E3DC58-D18B-4A6C-8167-4A1DFB4888E4
JIT(即时编译)的出现
在Java的编译体系中,一个Java的源代码文件变成计算机可执行的机器指令的过程中,需要经过两段编译:
第一段编译,指前端编译器把*.java文件转换成*.class文件(字节码文件)。编译器产品可以是JDK的Javac、Eclipse JDT中的增量式编译器。
第二编译阶段,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。这就是传统的JVM的解释器(Interpreter)的功能。为了解决这种效率问题,引入了JIT(即时编译器,Just In Time Compiler)技术。
引入了 JIT 技术后,Java程序还是通过解释器进行解释执行,当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。其中有一部分优化的目的就是减少内存堆分配压力,其中JIT优化中一种重要的技术叫做逃逸分析。
逃逸分析?
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。这是一种可以有效减少Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本原理是:分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;示例:
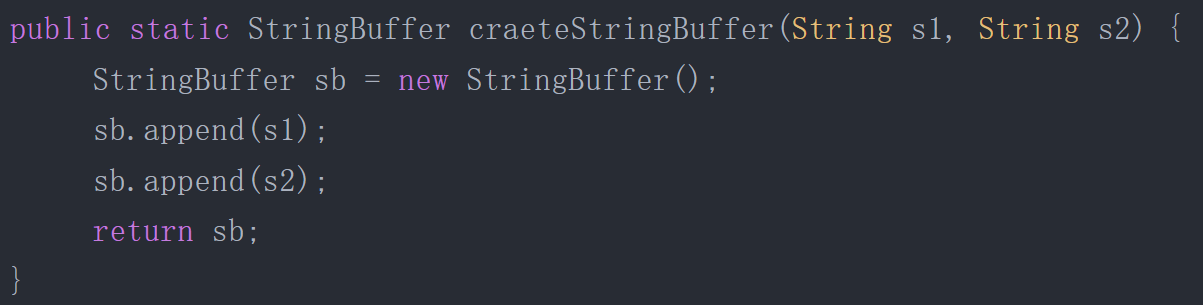
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:
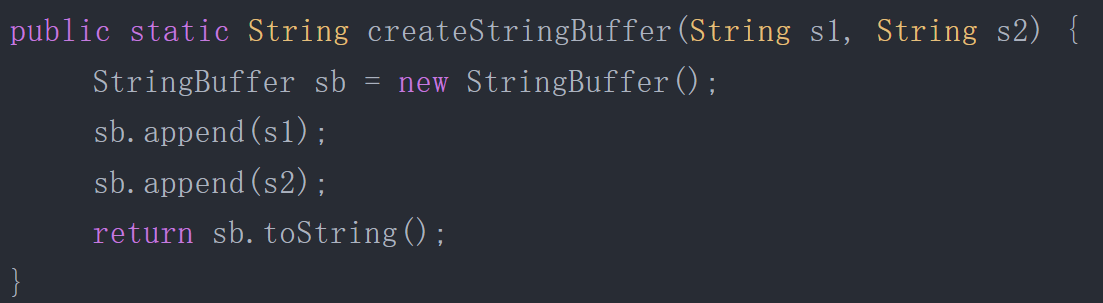
不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。从不逃逸、方法逃逸到线程逃逸,称为对象由低到高的不同逃逸程度。如果能证明一个对象不会逃逸到方法或线程之外(换句话说是别的方法或线程无法通过任何途径访问到这个对象),或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化。
使用逃逸分析,编译器可以对代码做如下优化:
一、同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
二、将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
三、分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。

