分区表-理论
对理论不感兴趣?那直接看分区实战吧--分区实战
目的
分区表的主要目的是方便数据的维护,而不是提升 MySQL 数据库的性能。
《高性能MySQL》中:分区的一个主要目的是将数据按照一个较粗的粒度分在不同的表中,这样做可以将相关的数据放在一起,另外,如果想一次批量删除整个分区的数据也会变得很方便。
定义
对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成。实现分区的代码实际上是对一组底层表的句柄对象(Handle Object)的封装。对分区表的请求,都是通过句柄对象转化成对存储引擎的接口的调用。当前 MySQL 数据库支持的分区函数类型有 RANGE、LIST、HASH、KEY、COLUMNS。无论选择哪种分区函数,都要指定相关列成为分区算法的输入条件,这些列就叫“分区列”。
MySQL实现分区的方式——对底层表的封装——意味着索引也是按照分区的子表定义的,而没有全局索引。MySQL在创建表时使用PARTITION BY子句定义每个分区存放的数据。在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就无须扫描所有分区,只需要查询包含需要数据的分区就可以了。
理解分区时可以将其当作索引的最初形态,以代价非常小的方式定位到需要的数据在哪一片“区域”。
优点
(1)查询优化:分区最大的优点是在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,可以让查询扫描更少的数据(在某些情况)。所以对于访问分区表来说,很重要的一点就是要在WHERE条件中带入分区列,有时候即使看似多余也要带上,这样就可以让优化器能过滤掉无须访问的分区。如果没有这些条件,就会访问所有分区。
注意:MySQL只能在使用分区函数的列本身进行比较时才能过滤分区,而不能根据表达式的值去过滤分区,即使这个表达式就是分区函数也不行。这就和查询中使用独立的列才能使用索引的道理一样。
(2)分区表的数据更容易维护。例如想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化、检查、修复等操作。
(3)分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
(4)可以使用分区表来避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3文件系统的inode锁竞争等。
(5)如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好。
使用场景
表非常大以至无法全部都放在内存中,或者只在表的最后部分有热点数据,其他都是历史数据。Eg:假设我们希望从一个非常大的表中查询出一段时间的记录(好比查询10亿条记录的表中最近几个月的数据),而这个表中包含了很多年的历史数据,数据是按照时间排序的。因为数据量巨大,肯定不能在每次查询的时候都扫描全表。考虑到索引在空间和维护上的消耗,也不希望使用索引。
注意:当数据量超大的时候,B-Tree索引就无法起作用了。除非是索引覆盖查询,否则数据库服务器需要根据索引扫描的结果回表,查询所有符合条件的记录,如果数据量巨大,这将产生大量随机I/O,随之,数据库的响应时间将大到不可接受的程度。另外,索引维护(磁盘空间、I/O操作)的代价也非常高。
重要限制
(1)一个表最多只能有1024个分区。
(2)在MySQL5.1中分区表达式必须是整数,或者是返回整数的表达式,MySQL5.5之后,可以直接使用列(RANGE COLUMNS类型)来进行分区,这样即使是基于时间的分区也无需再将其转成一个整数。
(3)如果分区字段中有主键或者唯一索引列,那么所有主键列和唯一索引列都必须包含进来。(若不理解请看下面分区表使用注意事项)
(4)分区表中无法使用外键约束。
原理
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
在分区表上进行增删改查记录时,分区表先打开并锁住所有的底层表,MySQL先确定这条记录属于哪个分区,再对相应底层表进行操作。虽然每个操作都有“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的。如果存储引擎能够自己实现行级锁,例如innoDb,则会在分区层释放对应表锁。这个加锁和解锁过程与普通InnoDB上的查询类似。
分区表使用注意事项
(1)主键中必须包含表的分区函数中的所有列
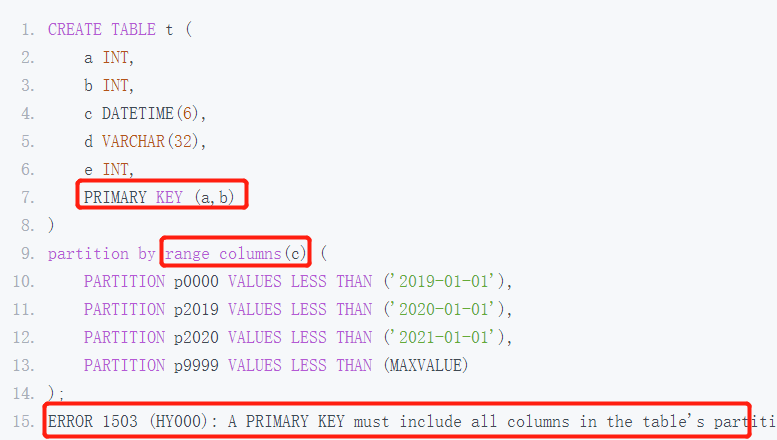
在创建分区时如果表中存在主键,那么分区列必须是主键或包含于主键中。否则会报
![]()
意思是主键中必须包含表的分区函数中的所有列。所以如果我们在使用创建时间作为分区列进行分区的时候,就需要将创建时间和主键id当作联合主键。
所以,要创建基于列c 的数据分片的分区表,主键必须包含列 c,比如下面的建表语句:

创建完表后,在物理存储上会看到四个分区所对应 ibd 文件,也就是把数据根据时间列 c 存储到对应的 4 个文件中:
![]()
所以,你要理解的是:MySQL 中的分区表是把一张大表拆成了多张表,每张表有自己的索引,从逻辑上看是一张表,但物理上存储在不同文件中。
(2)唯一索引必须包含分区函数中所有列
在 MySQL 数据库中,分区表的索引都是局部,而非全局。也就是说,索引在每个分区文件中都是独立的,所以分区表上的唯一索引必须包含分区列信息,否则创建会报错,比如:

你可以看到错误提示: 唯一索引必须包含分区函数中所有列。而下面的创建才能成功:
![]()
但是,正因为唯一索引包含了分区列,唯一索引也就变成仅在当前分区唯一,而不是全局唯一了。那么对于上面的表 t,插入下面这两条记录都是可以的:

你可以看到,列 d 都是字符串‘aaa’,但依然可以插入。这样带来的影响是列 d 并不是唯一的,所以你要由当前分区唯一实现全局唯一。
那如何实现全局唯一索引呢?
和之前表结构设计时一样,唯一索引使用全局唯一的字符串(如类似 UUID 的实现),这样就能避免局部唯一的问题。
分区表在业务上的设计
而为了让你更好理解分区表的使用,我们继续看一个真实业务的分区表设计。
以电商中的订单表 Orders 为例,如果在类似淘宝的海量互联网业务中,Orders 表的数据量会非常巨大,假设一天产生 5000 万的订单,那么一年表 Orders 就有近 180 亿的记录。
所以对于订单表,在数据库中通常只保存最近一年甚至更短时间的数据,而历史订单数据会入历史库。除非存在 1 年以上退款的订单,大部分订单一旦完成,这些数据从业务角度就没用了。
那么如果你想方便管理订单表中的数据,可以对表 Orders 按年创建分区表,如:
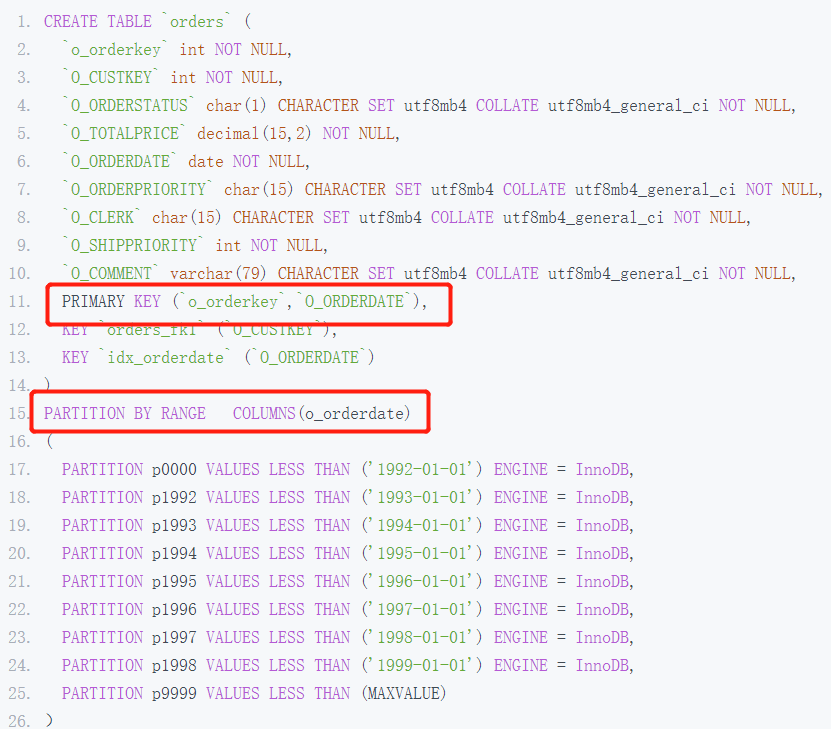
你可以看到,这时 Orders 表的主键修改为了(o_orderkey,O_ORDERDATE),数据按照年进行分区存储。那么如果要删除 1 年前的数据,比如删除 1998 年的数据,之前需要使用下面的 SQL,比如:
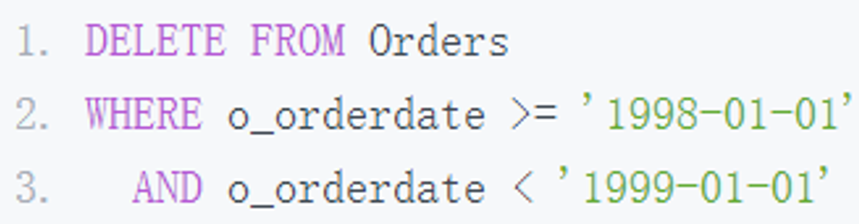
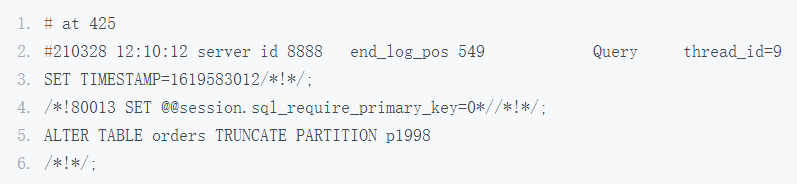
可这条 SQL 的执行相当慢,产生大量二进制日志,在生产系统上,也会导致数据库主从延迟的问题。而使用分区表的话,对于数据的管理就容易多了,你直接使用清空分区的命令就行:

上述 SQL 执行速度非常快,因为实际执行过程是把分区文件删除和重建。另外产生的日志也只有一条 DDL 日志,也不会导致主从复制延迟问题。