缓存 -- 介绍
使用缓存的收益和成本(优缺点)
如图左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构.
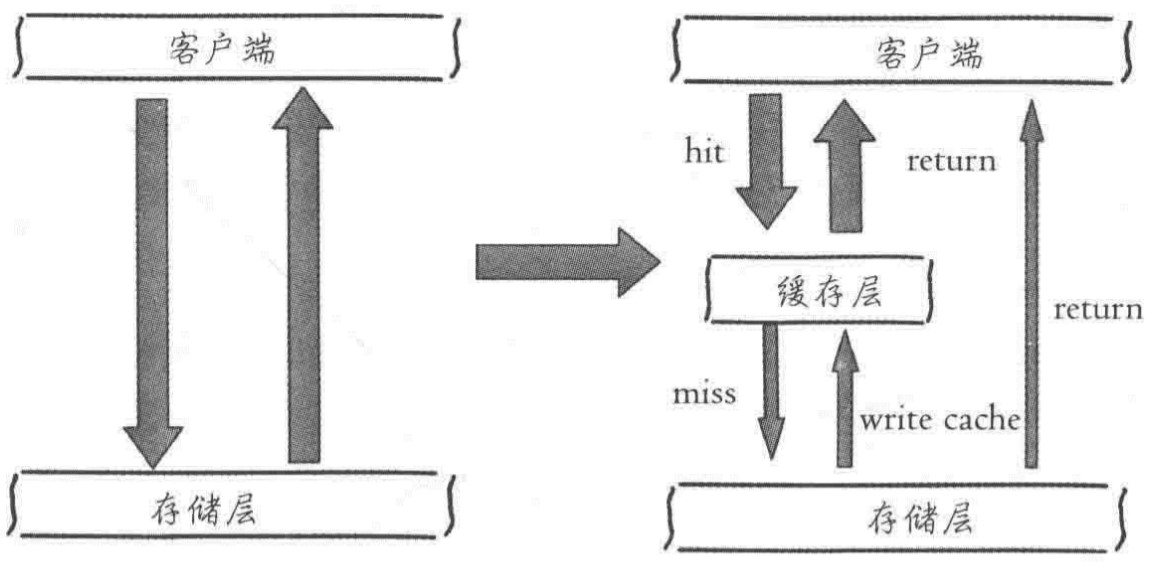
下面分析一下缓存加入后带来的收益和成本。
收益(优点)
(1)加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
(2)降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
成本(缺点)
(1)数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
(2)代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
(3)运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
使用场景
(1)开销大的复杂计算:以MySQL为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
(2)加速请求响应:即使查询单条后端数据足够快(例如select * from table where id=xxx),那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。
缓存的更新策略
缓存中的数据会和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新,下面会介绍几种主要的缓存更新策略。

1.LRU/LFU/FIFO算法剔除
使用场景:剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
一致性:要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
维护成本:算法不需要开发人员自己来实现,通常只需要配置最大 maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。
2.超时剔除
使用场景:超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
一致性:一段时间窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源的数据不一致。
维护成本:维护成本不是很高,只需设置expire过期时间即可,当然前提是应用方允许这段时间可能发生的数据不一致。
3.主动更新
使用场景:应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。
一致性:一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
维护成本:维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
4.最佳实践
(1)低一致性业务建议配置最大内存和淘汰策略的方式使用。
(2)高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。
如何实现本地缓存和分布式缓存?
•本地缓存是指程序级别的缓存组件,它的特点是应用程序和本地缓存会运行在同一个进程中,所以本地缓存的操作会非常快,因为在同一个进程内也意味着不会有网络上的延迟和开销。本地缓存适用于单节点非集群的应用场景,它的优点是快,缺点是多程序无法共享缓存,比如分布式用户 Session 会话信息保存,由于每次用户访问的服务器可能是不同的,如果不能共享缓存,那么就意味着每次的请求操作都有可能被系统阻止,因为会话信息只保存在某一个服务器上,当请求没有被转发到这台存储了用户信息的服务器时,就会被认为是非登录的违规操作。除此之外,无法共享缓存可能会造成系统资源的浪费,这是因为每个系统都单独维护了一份属于自己的缓存,而同一份缓存有可能被多个系统单独进行存储,从而浪费了系统资源。本地缓存可以使用 EhCache 和 Google 的 Guava 来实现.
•分布式缓存是指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,以及缓存共享的程序运行机制。而分布式缓存可以使用 Redis 或 Memcached 来实现。由于 Redis 本身就是独立的缓存系统,因此可以作为第三方来提供共享的数据缓存,而 Redis 的分布式支持主从、哨兵和集群的模式,所以它就可以支持分布式的缓存,而 Memcached 的情况也是类似的。
数据不一致相关
缓存和数据库一致性问题,存储的数据随着时间可能会发生变化,而缓存中的数据就会不一致。具体能容忍的不一致时间,需要具体业务具体分析,但是通常的业务,都需要做到最终一致性。
一致性介绍
一致性又可以分为强一致性与弱一致性。
1.强一致性
强一致性可以理解为在任意时刻,所有节点中的数据是一样的。同一时间点,你在节点A中获取到key1的值与在节点B中获取到key1的值应该都是一样的。
2.弱一致性
弱一致性包含很多种不同的实现,分布式系统中广泛实现的是最终一致性。
3.最终一致性
所谓最终一致性,是弱一致性的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新。但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。也可以简单的理解为在一段时间后,节点间的数据会最终达到一致状态。对于最终一致性最好的例子就是DNS系统,由于DNS多级缓存的实现,所以修改DNS记录后不会在全球所有DNS服务节点生效,需要等待DNS服务器缓存过期后向源服务器更新新的记录才能实现。
如何解决缓存一致性?
(1)更新数据库,不更新缓存
(2)先删除缓存,再更新数据库
删除缓存不更新缓存的理由
选择更新缓存(数据不但写入数据库,还会写入缓存)还是删除缓存呢?主要取决于“更新缓存的复杂度”,更新缓存的代价很大,那么更倾向于删除缓存。删除缓存操作简单,并且带来的副作用只是增加了一次cache miss,建议作为通用的处理方式。
先删除缓存,再更新数据库的理由
(1)假设先更新数据库,再删除缓存
第一步写更新数据库成功,第二步删除缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。
(2)假设先淘汰缓存,再写数据库
第一步删除缓存成功,第二步更新数据库失败,那没关系,起码数据是一致的。

