数据库设计--三范式
一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,使用三范式可以避免数据的冗余,而且在更新表操作时,只需要更新单张表就可以了。
三范式介绍
第一范式(The First Normal Form,1NF),符合原子性,字段(属性)是不可分割的。
第二范式(The Second Normal Form,2NF),消除部份依赖。即:一张表存在组合主键时,其他非主键字段不能部分依赖。
第三范式(The Third Normal Form,3NF),消除传递依赖。即:其他非主键字段必须依赖主键。
第一范式
要求对属性的原子性,也就是说要求数据库中的字段需要具备原子性,不能再被拆分。
eg:学生表中有字段:学生 ID、学生名、电话;而其中电话又可以分为:家庭电话和移动电话等。因此,此表不符合第一范式,如下图所示:
不符合第一范式

符合第一范式

第二范式
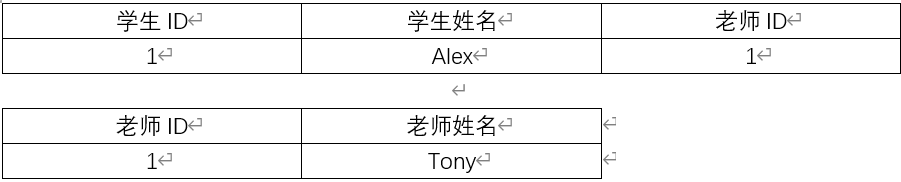
例如学生信息详情表有学生 ID、老师 ID、学生姓名、老师姓名这些字段。其中,学生 ID和老师 ID 为联合主键,但这个表中的"学生姓名"字段只依赖学生 ID,和老师 ID就没有任何关系了,因此这个表也不符合第二范式。我们可以拆分为学生表和老师表,其中学生表包含:学生 ID、老师 ID、学生姓名等字段;而老师表包含:老师 ID、老师姓名等字段。这样就消除了老师姓名多次重复出现的情况了,从而避免了冗余数据的产生。
不符合第二范式

符合第二范式
第三范式
想要满足第三范式必须先满足第二范式,第三范式要求所有的非主键字段必须直接依赖主键,且不存在传递依赖的情况。
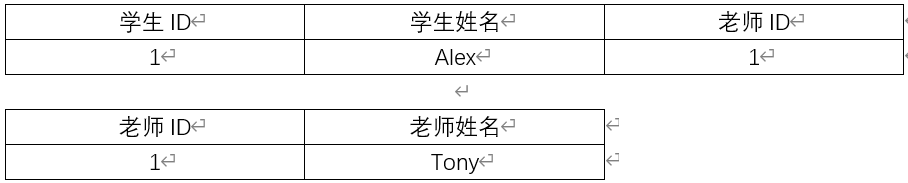
例如,有一个学生表中包含了:学生 ID、学生姓名、老师 ID、老师姓名等字段。这个表的所有字段(除去主键字段)都完全依赖唯一的主键字段(学生 ID),所以符合第二范式。但它存在一个问题,老师姓名依赖非主键字段老师 ID,而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合第三范式。
我们可以把学生表分为两张表,一张是学生表包含了:学生 ID、学生姓名、老师ID等字段;另一张为老师表包含了:老师 ID、老师姓名等字段,这样就满足第三范式的要求了。
不符合第三范式

符合三范式