利用scrapy爬取文件后并基于管道化的持久化存储
一、爬取数据
在创建爬虫程序之后写入爬取数据的代码
1 import scrapy 2 3 from boss.items import BossItem 4 5 class SecondSpider(scrapy.Spider): 6 name = 'second' 7 # allowed_domains = ['www.xxx.com'] 8 start_urls = ['https://www.zhipin.com/c101270100/?query=python%爬虫&ka=sel-city-101270100'] 9 10 def parse(self, response): 11 12 li_list = response.xpath('//div[@class="job-list"]/ul/li') 13 for li in li_list: 14 job_name = li.xpath('./div/div[1]/h3/a/div[1]/text()').extract_first() 15 salary = li.xpath('.//div[@class="info-primary"]/h3/a/span/text()').extract_first() 16 company = li.xpath('./div/div[2]/div/h3/a/text()').extract_first() 17 print(job_name, salary, company) 18 # 实例化item对象 19 item = BossItem() 20 # 将获取到的数据保存到当前对象中 21 item['job_name'] = job_name 22 item['salary'] = salary 23 item['company'] = company 24 25 # 将item提交给管道 26 yield item
之后在items.py 文件里为item对象设置属性
我们将爬取到的信息全部设置为item的属性
import scrapy
1 class BossItem(scrapy.Item): 2 # define the fields for your item here like: 3 # name = scrapy.Field() 4 # 实例化对象属性 5 job_name = scrapy.Field() 6 salary = scrapy.Field() 7 company = scrapy.Field()
二、写入pipelines.py内容
1 import pymysql 2 from redis import Redis 3 import json 4 5 6 class BossPipeline(object): 7 fp = None 8 9 def open_spider(self, spider): 10 print('开始爬虫') 11 self.fp = open('./boss.txt', 'w', encoding='utf8') 12 13 def close_spider(self, spider): 14 print('关闭爬虫') 15 self.fp.close() 16 17 # 爬虫文件每提交一次item,该方法就会被调用一次 18 def process_item(self, item, spider): 19 self.fp.write(item['job_name']+':'+item['salary']+':'+item['company']) 20 # return 是将item返回给下一个管道类 21 return item
我们自定义一个类,将item的数据写入到mysql里(在这之前将mysql和redis都启动)
1 class MysqlPileLine(object): 2 3 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='', db='bms', charset="utf8") 4 cursor = conn.cursor() 5 6 def open_spider(self, spider): 7 print('开始爬虫') 8 # 建立连接数据库 9 10 def process_item(self, item, spider): 11 12 try: 13 self.cursor.execute('insert into boss values("%s","%s","%s")' % (item['job_name'], item['salary'], item['company'])) 14 print('写入数据。。。。。。。。') 15 self.conn.commit() 16 except Exception as e: 17 print(e) 18 self.conn.rollback() 19 20 def close_spider(self, spider): 21 self.cursor.close() 22 self.conn.close()
在相同的文件下创建redis类写入数据
1 class RedisPileLine(object): 2 conn = Redis(host='127.0.0.1', port=6379) 3 4 def open_spider(self,spider): 5 print('开始爬虫') 6 7 def process_item(self, item, spider): 8 dic = { 9 'name': item['job_name'], 10 'salary': item['salary'], 11 'company': item['company'] 12 } 13 dic_json = json.dumps(dic) 14 self.conn.lpush('boss', dic_json)
三、更改配置文件(其他配置这里不作演示)
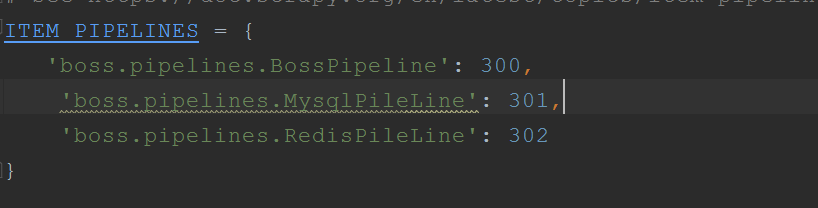
最后我们在终端去指定爬虫程序
scrapy crawl second

 浙公网安备 33010602011771号
浙公网安备 33010602011771号