


hadoop记录篇11-关系型数据库导入导出组件 sqoop
一 。sqoop简介
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,
可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
sqoop1架构(直接使用shell sqoop直接和关系型数据库与hadoop对接)

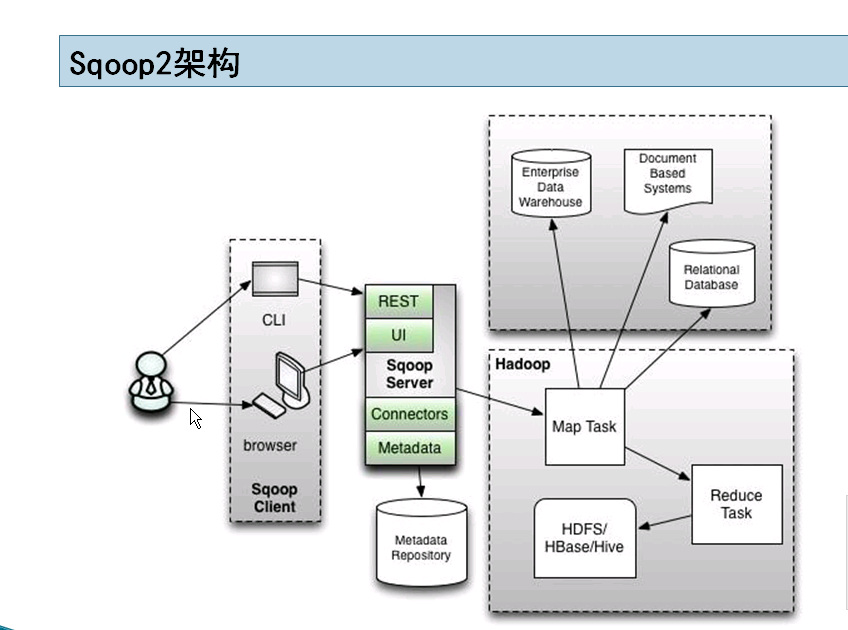
sqoop2架构
sqoop2引入了sqoop server(具体服务器为tomcat),对connector实现了集中的管理。其访问方式也变得多样化了,其可以通过REST API、JAVA API、WEB UI以及CLI控制台方式进行访问。另外,其在安全性能方面也有一定的改善,在sqoop1中我们经常用脚本的方式将HDFS中的数据导入到mysql中,或者反过来将mysql数据导入到HDFS中,其中在脚本里边都要显示指定mysql数据库的用户名和密码的,安全性做的不是太完善。在sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到
sqoop官网 http://sqoop.apache.org/
sqoop2用户手册地址 http://sqoop.apache.org/docs/1.99.7/admin/Installation.html
二 。chd安装sqoop
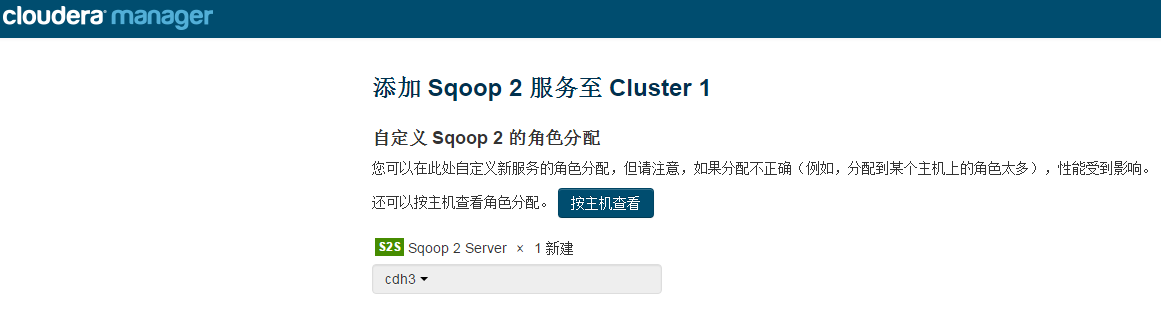
使用cdh admin console添加服务 选择 sqoop2 (不使用cdh参考手册Admin Guide)
角色分配 选择一台服务器 我选择cdh3 (cdh自动将hadoop配置分发给sqoop)
sqoop元数据数据库配置 默认是derby
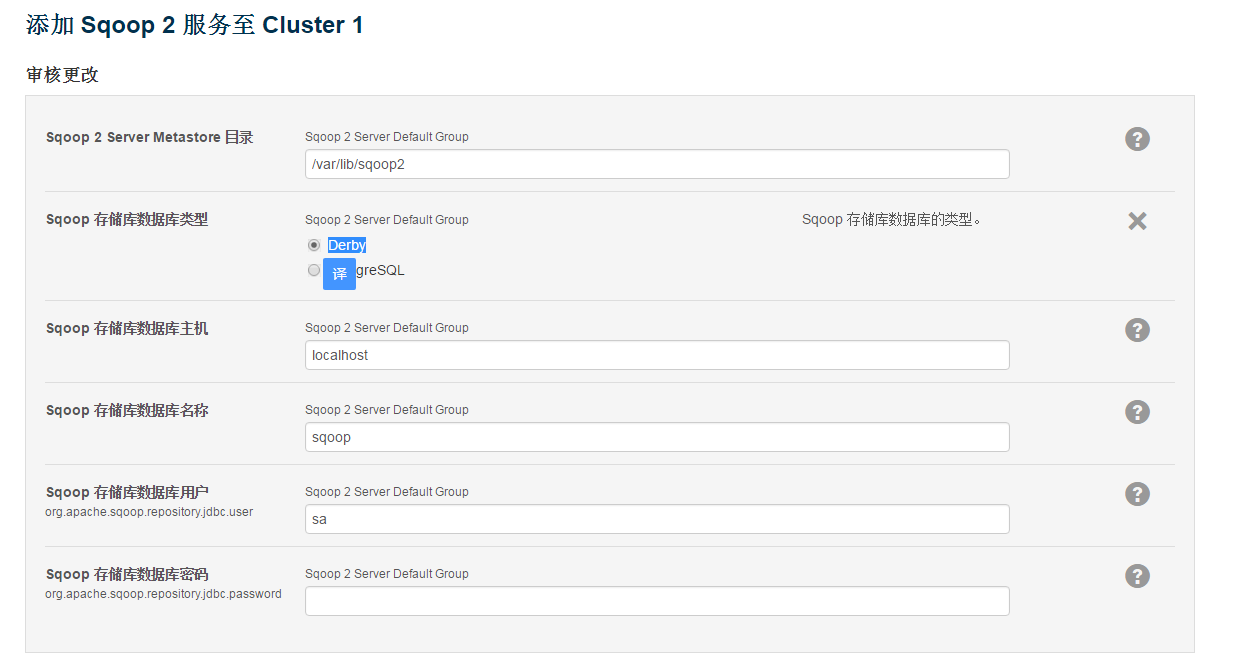
创建成功
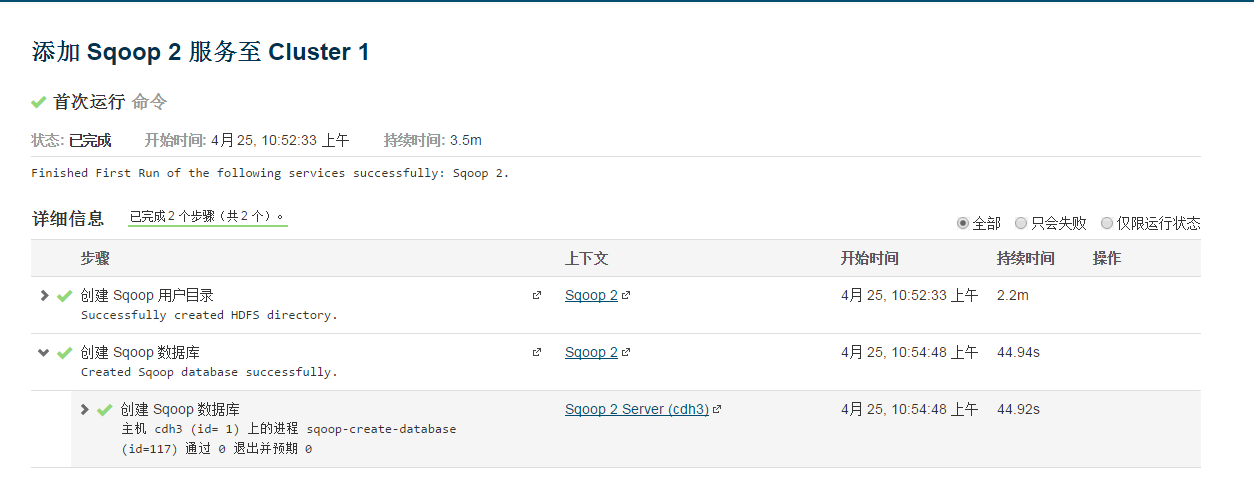
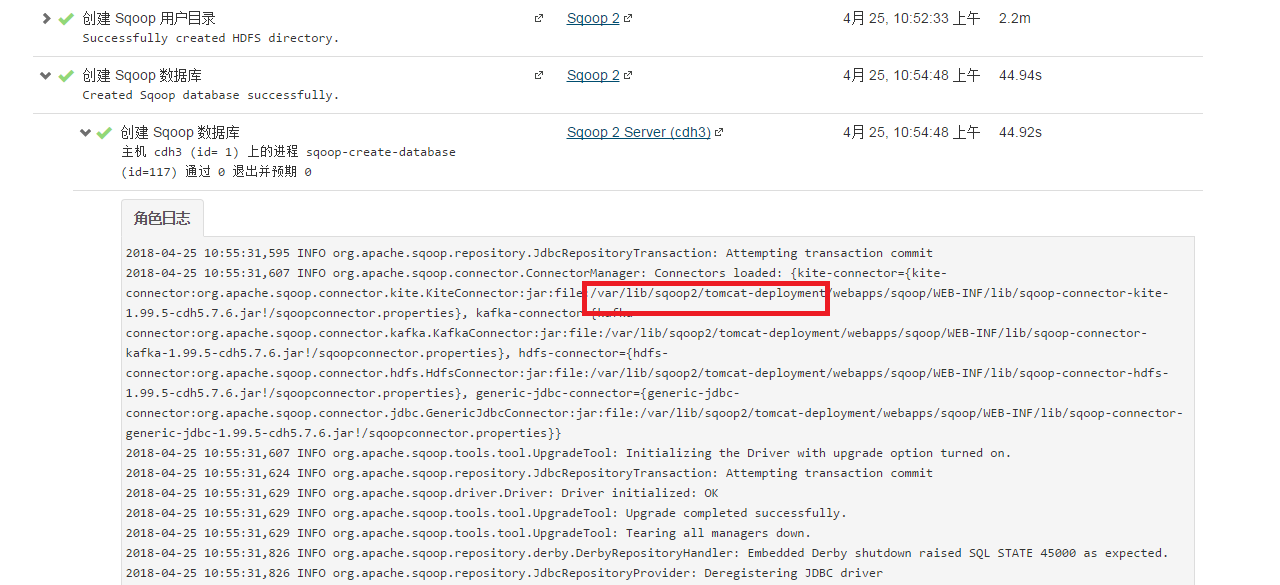
sqoopserver实际上是部署在tomcat中 从日志可以看出
sqoop-shell客户端 cdh未提供 下载sqoop安装包 解压使用bin目录接口
下载 http://mirror.bit.edu.cn/apache/sqoop/1.99.7/sqoop-1.99.7-bin-hadoop200.tar.gz
解压 进入就如bin目录 就可以使用 sqoop2-shell命令
sqoop1因为没有sqoopserver 如果安装了 直接使用sqoop-import 或者sqoop-export导入和导出
同理 在cdh添加 服务 选择sqoop1 只是个命令 就没有启动的说话
三 。sqoop脚本实现导入和导出
1。sqoop1实现
》》数据导入
CDH添加服务 sqoop1的客户端 实际上就是设置参数
(http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html#_sqoop_tools)
官网描述 sqoop导入数据到hadoop中 调用hadoop命令 所有这里必须确保 本机有操作hadoop目录的命令(检测hdfs dfs -ls /能否查看hdfs内容) 否则目标地址
就只能使用 hdfs://这种了 cdh中下载hdfs客户端配置文件
查看帮助
[root@cdh3 conf]# sqoop-import --help
Warning: /opt/cloudera/parcels/CDH-5.7.6-1.cdh5.7.6.p0.6/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
18/04/25 16:57:34 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.7.6
usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS]
Common arguments:
--connect <jdbc-uri> 连接url
--driver <class-name> 驱动类
--password <password> 密码
--username <username> 用户名
Import control arguments:
--append 追加数据模式
--as-avrodatafile 导入avro格式
--as-parquetfile Parquet格式
--as-sequencefile Imports data
--as-textfile 文本文件
--columns <col,col,col...> 导入的列
--compression-codec <codec> 压缩算法类
--delete-target-dir
-e,--query <statement> 指定导入sql语句
-m,--num-mappers <n> map个数决定了输出几个文件
--table <table-name> 数据库读取的表
--target-dir <dir> 目标hdfs目录
--where <where clause> WHERE 条件
-z,--compress 启用压缩
Output line formatting arguments:
--fields-terminated-by <char> 设置字段间分隔符
--lines-terminated-by <char> 行结尾符号 默认 \n
Input parsing arguments:
--input-fields-terminated-by <char> 设置字段间分隔符
--input-lines-terminated-by <char> 行结尾符号 默认 \n
Hive arguments:
--create-hive-table 创建hive的表 必须hive中不存在该表
--hive-database <database-name> 导入数据指定的数据库名称
--hive-import 表示是hive导入
--hive-table <table-name> 指定hive表名
-libjars 指定包含classpath下的jar文件.
演示个简单例子 演示在cdh1上数据库 启用mysql的general_log
set global general_log=on; # 开启general log模式
set global log_output='table' 自动将日志写入到 mysql.general_log表
MariaDB [mysql]> desc general_log;
+--------------+------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------------+------+-----+-------------------+-----------------------------+
| event_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| user_host | mediumtext | NO | | NULL | |
| thread_id | int(11) | NO | | NULL | |
| server_id | int(10) unsigned | NO | | NULL | |
| command_type | varchar(64) | NO | | NULL | |
| argument | mediumtext | NO | | NULL | |
+--------------+------------------+------+-----+-------------------+-----------------------------+
6 rows in set (0.00 sec)测试数据
MariaDB [mysql]> select * from general_log limit 0,5;
+---------------------+----------------------------------+-----------+-----------+--------------+---------------------------------------------------------+
| event_time | user_host | thread_id | server_id | command_type | argument |
+---------------------+----------------------------------+-----------+-----------+--------------+---------------------------------------------------------+
| 2018-04-25 17:14:47 | scm[scm] @ localhost [127.0.0.1] | 19 | 0 | Query | commit |
| 2018-04-25 17:14:47 | scm[scm] @ localhost [127.0.0.1] | 19 | 0 | Query | SET autocommit=1 |
| 2018-04-25 17:14:47 | scm[scm] @ localhost [127.0.0.1] | 19 | 0 | Query | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ |
| 2018-04-25 17:14:48 | scm[scm] @ localhost [127.0.0.1] | 19 | 0 | Query | SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED |
| 2018-04-25 17:14:48 | scm[scm] @ localhost [127.0.0.1] | 19 | 0 | Query | SET autocommit=0 |
+---------------------+----------------------------------+-----------+-----------+--------------+---------------------------------------------------------+sqoop-import --connect jdbc:mysql://node1:3306/mysql \
--driver com.mysql.jdbc.Driver \
--password hive \
--username hive \
--as-textfile \
--query 'select * from general_log where' \
--num-mappers 1 \
--target-dir /im18/04/25 17:27:15 INFO tool.CodeGenTool: Beginning code generation
18/04/25 17:27:16 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: Query [select * from general_log] must contain '$CONDITIONS' in WHERE clause.
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:332)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1856)sqoop-import --connect jdbc:mysql://node1:3306/mysql \
--driver com.mysql.jdbc.Driver \
--password hive \
--username hive \
--as-textfile \
--query 'select * from general_log where $CONDITIONS' \
--num-mappers 1 \
--target-dir /im[root@cdh4 init.d]# hdfs dfs -ls /im
Found 2 items
-rw-r--r-- 3 root supergroup 0 2018-04-25 17:56 /im/_SUCCESS
-rw-r--r-- 3 root supergroup 8435938 2018-04-25 17:56 /im/part-m-00000sqoop-import --connect jdbc:mysql://node1:3306/mysql \
--driver com.mysql.jdbc.Driver \
--password hive \
--username hive \
--as-textfile \
--query 'select * from general_log where $CONDITIONS' \
--num-mappers 1 \
--target-dir /im1 \
--hive-import \
--create-hive-table \
--hive-database default \
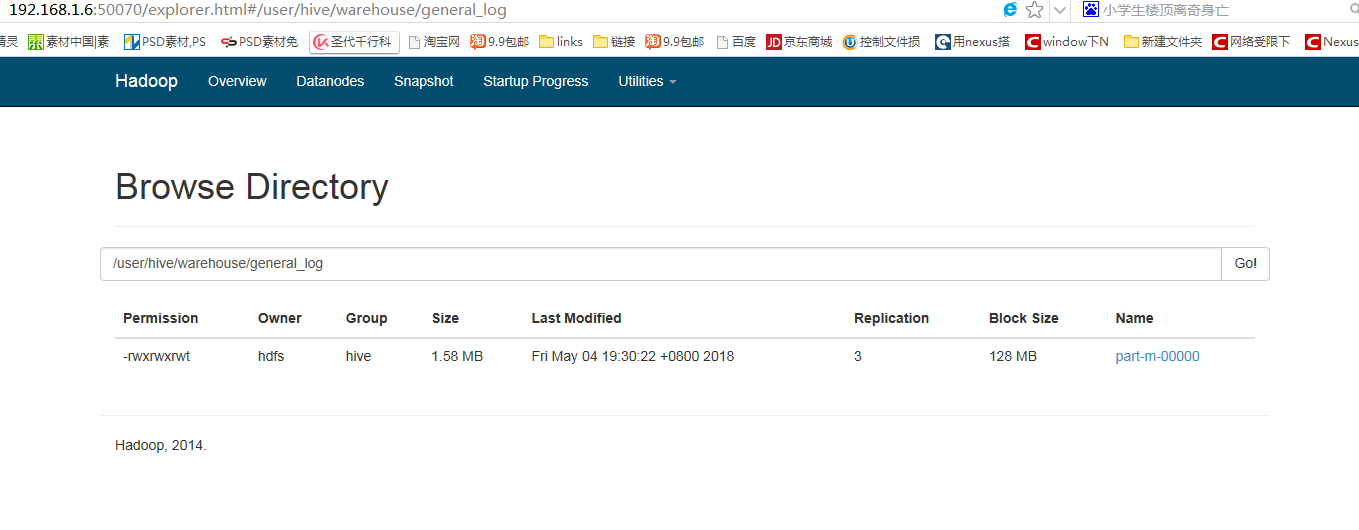
--hive-table general_log这里指定的target-dir只是个临时的存储 最终导入//user/hive/warehouse/general_log下
sqoop-import --connect jdbc:mysql://node1:3306/mysql \
--driver com.mysql.jdbc.Driver \
--password hive \
--username hive \
--as-textfile \
--query 'select * from general_log where $CONDITIONS' \
--num-mappers 1 \
--target-dir /im1 \
--hive-import \
--create-hive-table \
--hive-database default \
--hive-table general_log》》数据导出
对应的使用 sqoop-export即可 将之前导入到hive的表导入到test数据库的ttt表 创建ttt表的结构
mysql> create table ttt as select * from mysql.general_log where 1!=1;
Query OK, 0 rows affected (0.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc ttt;
+--------------+------------------+------+-----+---------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------------+------+-----+---------------------+-------+
| event_time | timestamp | NO | | 0000-00-00 00:00:00 | |
| user_host | mediumtext | NO | | NULL | |
| thread_id | int(11) | NO | | NULL | |
| server_id | int(10) unsigned | NO | | NULL | |
| command_type | varchar(64) | NO | | NULL | |
| argument | mediumtext | NO | | NULL | |
+--------------+------------------+------+-----+---------------------+-------+
6 rows in set (0.00 sec)导出命令
sqoop-export --connect jdbc:mysql://node1:3306/test \
--driver com.mysql.jdbc.Driver \
--password hive \
--username hive \
--table ttt \
--num-mappers 1 \
--hcatalog-database default \
--hcatalog-table general_log最后查询mysql 查看到导出数据
mysql> select count(*) from ttt;
+----------+
| count(*) |
+----------+
| 4838 |
+----------+
1 row in set (0.00 sec)2。sqoop2实现
(暂略)

