

Linux内核同步机制之(一):原子操作
http://www.wowotech.net/linux_kenrel/atomic.html
一、源由
我们的程序逻辑经常遇到这样的操作序列:
1、读一个位于memory中的变量的值到寄存器中
2、修改该变量的值(也就是修改寄存器中的值)
3、将寄存器中的数值写回memory中的变量值
如果这个操作序列是串行化的操作(在一个thread中串行执行),那么一切OK,然而,世界总是不能如你所愿。在多CPU体系结构中,运行在两个CPU上的两个内核控制路径同时并行执行上面操作序列,有可能发生下面的场景:
| CPU1上的操作 | CPU2上的操作 |
| 读操作 | |
| 读操作 | |
| 修改 | 修改 |
| 写操作 | |
| 写操作 |
多个CPUs和memory chip是通过总线互联的,在任意时刻,只能有一个总线master设备(例如CPU、DMA controller)访问该Slave设备(在这个场景中,slave设备是RAM chip)。因此,来自两个CPU上的读memory操作被串行化执行,分别获得了同样的旧值。完成修改后,两个CPU都想进行写操作,把修改的值写回到memory。但是,硬件arbiter的限制使得CPU的写回必须是串行化的,因此CPU1首先获得了访问权,进行写回动作,随后,CPU2完成写回动作。在这种情况下,CPU1的对memory的修改被CPU2的操作覆盖了,因此执行结果是错误的。
不仅是多CPU,在单CPU上也会由于有多个内核控制路径的交错而导致上面描述的错误。一个具体的例子如下:
| 系统调用的控制路径 | 中断handler控制路径 |
| 读操作 | |
| 读操作 | |
| 修改 | |
| 写操作 | |
| 修改 | |
| 写操作 |
系统调用的控制路径上,完成读操作后,硬件触发中断,开始执行中断handler。这种场景下,中断handler控制路径的写回的操作被系统调用控制路径上的写回覆盖了,结果也是错误的。
二、对策
对于那些有多个内核控制路径进行read-modify-write的变量,内核提供了一个特殊的类型atomic_t,具体定义如下:
typedef struct {
int counter;
} atomic_t;
从上面的定义来看,atomic_t实际上就是一个int类型的counter,不过定义这样特殊的类型atomic_t是有其思考的:内核定义了若干atomic_xxx的接口API函数,这些函数只会接收atomic_t类型的参数。这样可以确保atomic_xxx的接口函数只会操作atomic_t类型的数据。同样的,如果你定义了atomic_t类型的变量(你期望用atomic_xxx的接口API函数操作它),这些变量也不会被那些普通的、非原子变量操作的API函数接受。
具体的接口API函数整理如下:
| 接口函数 | 描述 |
| static inline void atomic_add(int i, atomic_t *v) | 给一个原子变量v增加i |
| static inline int atomic_add_return(int i, atomic_t *v) | 同上,只不过将变量v的最新值返回 |
| static inline void atomic_sub(int i, atomic_t *v) | 给一个原子变量v减去i |
| static inline int atomic_sub_return(int i, atomic_t *v) | 同上,只不过将变量v的最新值返回 |
| static inline int atomic_cmpxchg(atomic_t *ptr, int old, int new) | 比较old和原子变量ptr中的值,如果相等,那么就把new值赋给原子变量。 返回旧的原子变量ptr中的值 |
| atomic_read | 获取原子变量的值 |
| atomic_set | 设定原子变量的值 |
| atomic_inc(v) | 原子变量的值加一 |
| atomic_inc_return(v) | 同上,只不过将变量v的最新值返回 |
| atomic_dec(v) | 原子变量的值减去一 |
| atomic_dec_return(v) | 同上,只不过将变量v的最新值返回 |
| atomic_sub_and_test(i, v) | 给一个原子变量v减去i,并判断变量v的最新值是否等于0 |
| atomic_add_negative(i,v) | 给一个原子变量v增加i,并判断变量v的最新值是否是负数 |
| static inline int atomic_add_unless(atomic_t *v, int a, int u) | 只要原子变量v不等于u,那么就执行原子变量v加a的操作。 如果v不等于u,返回非0值,否则返回0值 |
三、ARM中的实现
我们以atomic_add为例,描述linux kernel中原子操作的具体代码实现细节:
#if __LINUX_ARM_ARCH__ >= 6 ----------------------(1)
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long tmp;
int result;prefetchw(&v->counter); -------------------------(2)
__asm__ __volatile__("@ atomic_add\n" ------------------(3)
"1: ldrex %0, [%3]\n" --------------------------(4)
" add %0, %0, %4\n" --------------------------(5)
" strex %1, %0, [%3]\n" -------------------------(6)
" teq %1, #0\n" -----------------------------(7)
" bne 1b"
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) ---对应%0,%1,%2
: "r" (&v->counter), "Ir" (i) -------------对应%3,%4
: "cc");
}#else
#ifdef CONFIG_SMP
#error SMP not supported on pre-ARMv6 CPUs
#endifstatic inline int atomic_add_return(int i, atomic_t *v)
{
unsigned long flags;
int val;raw_local_irq_save(flags);
val = v->counter;
v->counter = val += i;
raw_local_irq_restore(flags);return val;
}
#define atomic_add(i, v) (void) atomic_add_return(i, v)#endif
(1)ARMv6之前的CPU并不支持SMP,之后的ARM架构都是支持SMP的(例如我们熟悉的ARMv7-A)。因此,对于ARM处理,其原子操作分成了两个阵营,一个是支持SMP的ARMv6之后的CPU,另外一个就是ARMv6之前的,只有单核架构的CPU。对于UP,原子操作就是通过关闭CPU中断来完成的。
(2)这里的代码和preloading cache相关。在strex指令之前将要操作的memory内容加载到cache中可以显著提高性能。
(3)为了完整性,我还是重复一下汇编嵌入c代码的语法:嵌入式汇编的语法格式是:asm(code : output operand list : input operand list : clobber list)。output operand list 和 input operand list是c代码和嵌入式汇编代码的接口,clobber list描述了汇编代码对寄存器的修改情况。为何要有clober list?我们的c代码是gcc来处理的,当遇到嵌入汇编代码的时候,gcc会将这些嵌入式汇编的文本送给gas进行后续处理。这样,gcc需要了解嵌入汇编代码对寄存器的修改情况,否则有可能会造成大麻烦。例如:gcc对c代码进行处理,将某些变量值保存在寄存器中,如果嵌入汇编修改了该寄存器的值,又没有通知gcc的话,那么,gcc会以为寄存器中仍然保存了之前的变量值,因此不会重新加载该变量到寄存器,而是直接使用这个被嵌入式汇编修改的寄存器,这时候,我们唯一能做的就是静静的等待程序的崩溃。还好,在output operand list 和 input operand list中涉及的寄存器都不需要体现在clobber list中(gcc分配了这些寄存器,当然知道嵌入汇编代码会修改其内容),因此,大部分的嵌入式汇编的clobber list都是空的,或者只有一个cc,通知gcc,嵌入式汇编代码更新了condition code register。
大家对着上面的code就可以分开各段内容了。@符号标识该行是注释。
这里的__volatile__主要是用来防止编译器优化的。也就是说,在编译该c代码的时候,如果使用优化选项(-O)进行编译,对于那些没有声明__volatile__的嵌入式汇编,编译器有可能会对嵌入c代码的汇编进行优化,编译的结果可能不是原来你撰写的汇编代码,但是如果你的嵌入式汇编使用__asm__ __volatile__(嵌入式汇编)的语法格式,那么也就是告诉编译器,不要随便动我的嵌入汇编代码哦。
(4)我们先看ldrex和strex这两条汇编指令的使用方法。ldr和str这两条指令大家都是非常的熟悉了,后缀的ex表示Exclusive,是ARMv7提供的为了实现同步的汇编指令。
LDREX <Rt>, [<Rn>]
<Rn>是base register,保存memory的address,LDREX指令从base register中获取memory address,并且将memory的内容加载到<Rt>(destination register)中。这些操作和ldr的操作是一样的,那么如何体现exclusive呢?其实,在执行这条指令的时候,还放出两条“狗”来负责观察特定地址的访问(就是保存在[<Rn>]中的地址了),这两条狗一条叫做local monitor,一条叫做global monitor。
STREX <Rd>, <Rt>, [<Rn>]
和LDREX指令类似,<Rn>是base register,保存memory的address,STREX指令从base register中获取memory address,并且将<Rt> (source register)中的内容加载到该memory中。这里的<Rd>保存了memeory 更新成功或者失败的结果,0表示memory更新成功,1表示失败。STREX指令是否能成功执行是和local monitor和global monitor的状态相关的。对于Non-shareable memory(该memory不是多个CPU之间共享的,只会被一个CPU访问),只需要放出该CPU的local monitor这条狗就OK了,下面的表格可以描述这种情况
| thread 1 | thread 2 | local monitor的状态 |
| Open Access state | ||
| LDREX | Exclusive Access state | |
| LDREX | Exclusive Access state | |
| Modify | Exclusive Access state | |
| STREX | Open Access state | |
| Modify | Open Access state | |
| STREX | 在Open Access state的状态下,执行STREX指令会导致该指令执行失败 | |
| 保持Open Access state,直到下一个LDREX指令 |
开始的时候,local monitor处于Open Access state的状态,thread 1执行LDREX 命令后,local monitor的状态迁移到Exclusive Access state(标记本地CPU对xxx地址进行了LDREX的操作),这时候,中断发生了,在中断handler中,又一次执行了LDREX ,这时候,local monitor的状态保持不变,直到STREX指令成功执行,local monitor的状态迁移到Open Access state的状态(清除xxx地址上的LDREX的标记)。返回thread 1的时候,在Open Access state的状态下,执行STREX指令会导致该指令执行失败(没有LDREX的标记,何来STREX),说明有其他的内核控制路径插入了。
对于shareable memory,需要系统中所有的local monitor和global monitor共同工作,完成exclusive access,概念类似,这里就不再赘述了。
大概的原理已经描述完毕,下面回到具体实现面。
"1: ldrex %0, [%3]\n"
其中%3就是input operand list中的"r" (&v->counter),r是限制符(constraint),用来告诉编译器gcc,你看着办吧,你帮我选择一个通用寄存器保存该操作数吧。%0对应output openrand list中的"=&r" (result),=表示该操作数是write only的,&表示该操作数是一个earlyclobber operand,具体是什么意思呢?编译器在处理嵌入式汇编的时候,倾向使用尽可能少的寄存器,如果output operand没有&修饰的话,汇编指令中的input和output操作数会使用同样一个寄存器。因此,&确保了%3和%0使用不同的寄存器。
(5)完成步骤(4)后,%0这个output操作数已经被赋值为atomic_t变量的old value,毫无疑问,这里的操作是要给old value加上i。这里%4对应"Ir" (i),这里“I”这个限制符对应ARM平台,表示这是一个有特定限制的立即数,该数必须是0~255之间的一个整数通过rotation的操作得到的一个32bit的立即数。这是和ARM的data-processing instructions如何解析立即数有关的。每个指令32个bit,其中12个bit被用来表示立即数,其中8个bit是真正的数据,4个bit用来表示如何rotation。更详细的内容请参考ARM ARM文档。
(6)这一步将修改后的new value保存在atomic_t变量中。是否能够正确的操作的状态标记保存在%1操作数中,也就是"=&r" (tmp)。
(7)检查memory update的操作是否正确完成,如果OK,皆大欢喜,如果发生了问题(有其他的内核路径插入),那么需要跳转到lable 1那里,从新进行一次read-modify-write的操作。
Linux内核同步机制之(二):Per-CPU变量
http://www.wowotech.net/linux_kenrel/per-cpu.html
一、源由:为何引入Per-CPU变量?
1、lock bus带来的性能问题
在ARM平台上,ARMv6之前,SWP和SWPB指令被用来支持对shared memory的访问:
SWP <Rt>, <Rt2>, [<Rn>]
Rn中保存了SWP指令要操作的内存地址,通过该指令可以将Rn指定的内存数据加载到Rt寄存器,同时将Rt2寄存器中的数值保存到Rn指定的内存中去。
我们在原子操作那篇文档中描述的read-modify-write的问题本质上是一个保持对内存read和write访问的原子性的问题。也就是说对内存的读和写的访问不能被打断。对该问题的解决可以通过硬件、软件或者软硬件结合的方法来进行。早期的ARM CPU给出的方案就是依赖硬件:SWP这个汇编指令执行了一次读内存操作、一次写内存操作,但是从程序员的角度看,SWP这条指令就是原子的,读写之间不会被任何的异步事件打断。具体底层的硬件是如何做的呢?这时候,硬件会提供一个lock signal,在进行memory操作的时候设定lock信号,告诉总线这是一个不可被中断的内存访问,直到完成了SWP需要进行的两次内存访问之后再clear lock信号。
lock memory bus对多核系统的性能造成严重的影响(系统中其他的processor对那条被lock的memory bus的访问就被hold住了),如何解决这个问题?最好的锁机制就是不使用锁,因此解决这个问题可以使用釜底抽薪的方法,那就是不在系统中的多个processor之间共享数据,给每一个CPU分配一个不就OK了吗。
当然,随着技术的发展,在ARMv6之后的ARM CPU已经不推荐使用SWP这样的指令,而是提供了LDREX和STREX这样的指令。这种方法是使用软硬件结合的方法来解决原子操作问题,看起来代码比较复杂,但是系统的性能可以得到提升。其实,从硬件角度看,LDREX和STREX这样的指令也是采用了lock-free的做法。OK,由于不再lock bus,看起来Per-CPU变量存在的基础被打破了。不过考虑cache的操作,实际上它还是有意义的。
2、cache的影响
在The Memory Hierarchy文档中,我们已经了解了关于memory一些基础的知识,一些基础的内容,这里就不再重复了。我们假设一个多核系统中的cache如下:

每个CPU都有自己的L1 cache(包括data cache和instruction cache),所有的CPU共用一个L2 cache。L1、L2以及main memory的访问速度之间的差异都是非常大,最高的性能的情况下当然是L1 cache hit,这样就不需要访问下一阶memory来加载cache line。
我们首先看在多个CPU之间共享内存的情况。这种情况下,任何一个CPU如果修改了共享内存就会导致所有其他CPU的L1 cache上对应的cache line变成invalid(硬件完成)。虽然对性能造成影响,但是系统必须这么做,因为需要维持cache的同步。将一个共享memory变成Per-CPU memory本质上是一个耗费更多memory来解决performance的方法。当一个在多个CPU之间共享的变量变成每个CPU都有属于自己的一个私有的变量的时候,我们就不必考虑来自多个CPU上的并发,仅仅考虑本CPU上的并发就OK了。当然,还有一点要注意,那就是在访问Per-CPU变量的时候,不能调度,当然更准确的说法是该task不能调度到其他CPU上去。目前的内核的做法是在访问Per-CPU变量的时候disable preemptive,虽然没有能够完全避免使用锁的机制(disable preemptive也是一种锁的机制),但毫无疑问,这是一种代价比较小的锁。
二、接口
1、静态声明和定义Per-CPU变量的API如下表所示:
| 声明和定义Per-CPU变量的API | 描述 |
| DECLARE_PER_CPU(type, name) DEFINE_PER_CPU(type, name) | 普通的、没有特殊要求的per cpu变量定义接口函数。没有对齐的要求 |
| DECLARE_PER_CPU_FIRST(type, name) DEFINE_PER_CPU_FIRST(type, name) | 通过该API定义的per cpu变量位于整个per cpu相关section的最前面。 |
| DECLARE_PER_CPU_SHARED_ALIGNED(type, name) DEFINE_PER_CPU_SHARED_ALIGNED(type, name) | 通过该API定义的per cpu变量在SMP的情况下会对齐到L1 cache line ,对于UP,不需要对齐到cachine line |
| DECLARE_PER_CPU_ALIGNED(type, name) DEFINE_PER_CPU_ALIGNED(type, name) | 无论SMP或者UP,都是需要对齐到L1 cache line |
| DECLARE_PER_CPU_PAGE_ALIGNED(type, name) DEFINE_PER_CPU_PAGE_ALIGNED(type, name) | 为定义page aligned per cpu变量而设定的API接口 |
| DECLARE_PER_CPU_READ_MOSTLY(type, name) DEFINE_PER_CPU_READ_MOSTLY(type, name) | 通过该API定义的per cpu变量是read mostly的 |
看到这样“丰富多彩”的Per-CPU变量的API,你是不是已经醉了。这些定义使用在不同的场合,主要的factor包括:
-该变量在section中的位置
-该变量的对齐方式
-该变量对SMP和UP的处理不同
-访问per cpu的形态
例如:如果你准备定义的per cpu变量是要求按照page对齐的,那么在定义该per cpu变量的时候需要使用DECLARE_PER_CPU_PAGE_ALIGNED。如果只要求在SMP的情况下对齐到cache line,那么使用DECLARE_PER_CPU_SHARED_ALIGNED来定义该per cpu变量。
2、访问静态声明和定义Per-CPU变量的API
静态定义的per cpu变量不能象普通变量那样进行访问,需要使用特定的接口函数,具体如下:
get_cpu_var(var)
put_cpu_var(var)
上面这两个接口函数已经内嵌了锁的机制(preempt disable),用户可以直接调用该接口进行本CPU上该变量副本的访问。如果用户确认当前的执行环境已经是preempt disable(或者是更厉害的锁,例如关闭了CPU中断),那么可以使用lock-free版本的Per-CPU变量的API:__get_cpu_var。
3、动态分配Per-CPU变量的API如下表所示:
| 动态分配和释放Per-CPU变量的API | 描述 |
| alloc_percpu(type) | 分配类型是type的per cpu变量,返回per cpu变量的地址(注意:不是各个CPU上的副本) |
| void free_percpu(void __percpu *ptr) | 释放ptr指向的per cpu变量空间 |
4、访问动态分配Per-CPU变量的API如下表所示:
| 访问Per-CPU变量的API | 描述 |
| get_cpu_ptr | 这个接口是和访问静态Per-CPU变量的get_cpu_var接口是类似的,当然,这个接口是for 动态分配Per-CPU变量 |
| put_cpu_ptr | 同上 |
| per_cpu_ptr(ptr, cpu) | 根据per cpu变量的地址和cpu number,返回指定CPU number上该per cpu变量的地址 |
三、实现
1、静态Per-CPU变量定义
我们以DEFINE_PER_CPU的实现为例子,描述linux kernel中如何实现静态Per-CPU变量定义。具体代码如下:
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
type就是变量的类型,name是per cpu变量符号。DEFINE_PER_CPU_SECTION宏可以把一个per cpu变量放到指定的section中,具体代码如下:
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES \-----安排section
__typeof__(type) name----------------------定义变量
在这里具体arch specific的percpu代码中(arch/arm/include/asm/percpu.h)可以定义PER_CPU_DEF_ATTRIBUTES,以便控制该per cpu变量的属性,当然,如果arch specific的percpu代码不定义,那么在general arch-independent的代码中(include/asm-generic/percpu.h)会定义为空。这里可以顺便提一下Per-CPU变量的软件层次:
(1)arch-independent interface。在include/linux/percpu.h文件中,定义了内核其他模块要使用per cpu机制使用的接口API以及相关数据结构的定义。内核其他模块需要使用per cpu变量接口的时候需要include该头文件
(2)arch-general interface。在include/asm-generic/percpu.h文件中。如果所有的arch相关的定义都是一样的,那么就把它抽取出来,放到asm-generic目录下。毫无疑问,这个文件定义的接口和数据结构是硬件相关的,只不过软件抽象各个arch-specific的内容,形成一个arch general layer。一般来说,我们不需要直接include该头文件,include/linux/percpu.h会include该头文件。
(3)arch-specific。这是和硬件相关的接口,在arch/arm/include/asm/percpu.h,定义了ARM平台中,具体和per cpu相关的接口代码。
我们回到正题,看看__PCPU_ATTRS的定义:
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
PER_CPU_BASE_SECTION 定义了基础的section name symbol,定义如下:
#ifndef PER_CPU_BASE_SECTION
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
#else
#define PER_CPU_BASE_SECTION ".data"
#endif
#endif
虽然有各种各样的静态Per-CPU变量定义方法,但是都是类似的,只不过是放在不同的section中,属性不同而已,这里就不看其他的实现了,直接给出section的安排:
(1)普通per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu" section | ".data" section |
| defined in module | ".data..percpu" section | ".data" section |
(2)first per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu..first" section | ".data" section |
| defined in module | ".data..percpu..first" section | ".data" section |
(3)SMP shared aligned per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu..shared_aligned" section | ".data" section |
| defined in module | ".data..percpu" section | ".data" section |
(4)aligned per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu..shared_aligned" section | ".data..shared_aligned" section |
| defined in module | ".data..percpu" section | ".data..shared_aligned" section |
(5)page aligned per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu..page_aligned" section | ".data..page_aligned" section |
| defined in module | ".data..percpu..page_aligned" section | ".data..page_aligned" section |
(6)read mostly per cpu变量的section安排
| SMP | UP | |
| Build-in kernel | ".data..percpu..readmostly" section | ".data..readmostly" section |
| defined in module | ".data..percpu..readmostly" section | ".data..readmostly" section |
了解了静态定义Per-CPU变量的实现,但是为何要引入这么多的section呢?对于kernel中的普通变量,经过了编译和链接后,会被放置到.data或者.bss段,系统在初始化的时候会准备好一切(例如clear bss),由于per cpu变量的特殊性,内核将这些变量放置到了其他的section,位于kernel address space中__per_cpu_start和__per_cpu_end之间,我们称之Per-CPU变量的原始变量(我也想不出什么好词了)。
只有Per-CPU变量的原始变量还是不够的,必须为每一个CPU建立一个副本,怎么建?直接静态定义一个NR_CPUS的数组?NR_CPUS定义了系统支持的最大的processor的个数,并不是实际中系统processor的数目,这样的定义非常浪费内存。此外,静态定义的数据在内存中连续,对于UMA系统而言是OK的,对于NUMA系统,每个CPU上的Per-CPU变量的副本应该位于它访问最快的那段memory上,也就是说Per-CPU变量的各个CPU副本可能是散布在整个内存地址空间的,而这些空间之间是有空洞的。本质上,副本per cpu内存的分配归属于内存管理子系统,因此,分配per cpu变量副本的内存本文不会详述,大致的思路如下:

内存管理子系统会根据当前的内存配置为每一个CPU分配一大块memory,对于UMA,这个memory也是位于main memory,对于NUMA,有可能是分配最靠近该CPU的memory(也就是说该cpu访问这段内存最快),但无论如何,这些都是内存管理子系统需要考虑的。无论静态还是动态per cpu变量的分配,其机制都是一样的,只不过,对于静态per cpu变量,需要在系统初始化的时候,对应per cpu section,预先动态分配一个同样size的per cpu chunk。在vmlinux.lds.h文件中,定义了percpu section的排列情况:
#define PERCPU_INPUT(cacheline) \
VMLINUX_SYMBOL(__per_cpu_start) = .; \
*(.data..percpu..first) \
. = ALIGN(PAGE_SIZE); \
*(.data..percpu..page_aligned) \
. = ALIGN(cacheline); \
*(.data..percpu..readmostly) \
. = ALIGN(cacheline); \
*(.data..percpu) \
*(.data..percpu..shared_aligned) \
VMLINUX_SYMBOL(__per_cpu_end) = .;
对于build in内核的那些per cpu变量,必然位于__per_cpu_start和__per_cpu_end之间的per cpu section。在系统初始化的时候(setup_per_cpu_areas),分配per cpu memory chunk,并将per cpu section copy到每一个chunk中。
2、访问静态定义的per cpu变量
代码如下:
#define get_cpu_var(var) (*({ \
preempt_disable(); \
&__get_cpu_var(var); }))
再看到get_cpu_var和__get_cpu_var这两个符号,相信广大人民群众已经相当的熟悉,一个持有锁的版本,一个lock-free的版本。为防止当前task由于抢占而调度到其他的CPU上,在访问per cpu memory的时候都需要使用preempt_disable这样的锁的机制。我们来看__get_cpu_var:
#define __get_cpu_var(var) (*this_cpu_ptr(&(var)))
#define this_cpu_ptr(ptr) __this_cpu_ptr(ptr)
对于ARM平台,我们没有定义__this_cpu_ptr,因此采用asm-general版本的:
#define __this_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, __my_cpu_offset)
SHIFT_PERCPU_PTR这个宏定义从字面上就可以看出它是可以从原始的per cpu变量的地址,通过简单的变换(SHIFT)转成实际的per cpu变量副本的地址。实际上,per cpu内存管理模块可以保证原始的per cpu变量的地址和各个CPU上的per cpu变量副本的地址有简单的线性关系(就是一个固定的offset)。__my_cpu_offset这个宏定义就是和offset相关的,如果arch specific没有定义,那么可以采用asm general版本的,如下:
#define __my_cpu_offset per_cpu_offset(raw_smp_processor_id())
raw_smp_processor_id可以获取本CPU的ID,如果没有arch specific没有定义__per_cpu_offset这个宏,那么offset保存在__per_cpu_offset的数组中(下面只是数组声明,具体定义在mm/percpu.c文件中),如下:
#ifndef __per_cpu_offset
extern unsigned long __per_cpu_offset[NR_CPUS];#define per_cpu_offset(x) (__per_cpu_offset[x])
#endif
对于ARMV6K和ARMv7版本,offset保存在TPIDRPRW寄存器中,这样是为了提升系统性能。
3、动态分配per cpu变量
这部分内容留给内存管理子系统吧。
Linux内核同步机制之(三):memory barrier
http://www.wowotech.net/kernel_synchronization/memory-barrier.html
一、前言
我记得以前上学的时候大家经常说的一个词汇叫做所见即所得,有些编程工具是所见即所得的,给程序员带来极大的方便。对于一个c程序员,我们的编写的代码能所见即所得吗?我们看到的c程序的逻辑是否就是最后CPU运行的结果呢?很遗憾,不是,我们的“所见”和最后的执行结果隔着:
1、编译器
2、CPU取指执行
编译器将符合人类思考的逻辑(c代码)翻译成了符合CPU运算规则的汇编指令,编译器了解底层CPU的思维模式,因此,它可以在将c翻译成汇编的时候进行优化(例如内存访问指令的重新排序),让产出的汇编指令在CPU上运行的时候更快。然而,这种优化产出的结果未必符合程序员原始的逻辑,因此,作为程序员,作为c程序员,必须有能力了解编译器的行为,并在通过内嵌在c代码中的memory barrier来指导编译器的优化行为(这种memory barrier又叫做优化屏障,Optimization barrier),让编译器产出即高效,又逻辑正确的代码。
CPU的核心思想就是取指执行,对于in-order的单核CPU,并且没有cache(这种CPU在现实世界中还存在吗?),汇编指令的取指和执行是严格按照顺序进行的,也就是说,汇编指令就是所见即所得的,汇编指令的逻辑被严格的被CPU执行。然而,随着计算机系统越来越复杂(多核、cache、superscalar、out-of-order),使用汇编指令这样贴近处理器的语言也无法保证其被CPU执行的结果的一致性,从而需要程序员(看,人还是最不可以替代的)告知CPU如何保证逻辑正确。
综上所述,memory barrier是一种保证内存访问顺序的一种方法,让系统中的HW block(各个cpu、DMA controler、device等)对内存有一致性的视角。
二、不使用memory barrier会导致问题的场景
1、编译器的优化
我们先看下面的一个例子:
preempt_disable()
临界区
preempt_enable
有些共享资源可以通过禁止任务抢占来进行保护,因此临界区代码被preempt_disable和preempt_enable给保护起来。其实,我们知道所谓的preempt enable和disable其实就是对当前进程的struct thread_info中的preempt_count进行加一和减一的操作。具体的代码如下:
#define preempt_disable() \
do { \
preempt_count_inc(); \
barrier(); \
} while (0)
linux kernel中的定义和我们的想像一样,除了barrier这个优化屏障。barrier就象是c代码中的一个栅栏,将代码逻辑分成两段,barrier之前的代码和barrier之后的代码在经过编译器编译后顺序不能乱掉。也就是说,barrier之后的c代码对应的汇编,不能跑到barrier之前去,反之亦然。之所以这么做是因为在我们这个场景中,如果编译为了榨取CPU的performace而对汇编指令进行重排,那么临界区的代码就有可能位于preempt_count_inc之外,从而起不到保护作用。
现在,我们知道了增加barrier的作用,问题来了,barrier是否够呢?对于multi-core的系统,只有当该task被调度到该CPU上执行的时候,该CPU才会访问该task的preempt count,因此对于preempt enable和disable而言,不存在多个CPU同时访问的场景。但是,即便这样,如果CPU是乱序执行(out-of-order excution)的呢?其实,我们也不用担心,正如前面叙述的,preempt count这个memory实际上是不存在多个cpu同时访问的情况,因此,它实际上会本cpu的进程上下文和中断上下文访问。能终止当前thread执行preempt_disable的只有中断。为了方便描述,我们给代码编址,如下:
| 地址 | 该地址的汇编指令 | CPU的执行顺序 |
| a | preempt_disable() | 临界区指令1 |
| a+4 | 临界区指令1 | preempt_disable() |
| a+8 | 临界区指令2 | 临界区指令2 |
| a+12 | preempt_enable | preempt_enable |
当发生中断的时候,硬件会获取当前PC值,并精确的得到了发生指令的地址。有两种情况:
(1)在地址a发生中断。对于out-of-order的CPU,临界区指令1已经执行完毕,preempt_disable正在pipeline中等待执行。由于是在a地址发生中断,也就是preempt_disable地址上发生中断,对于硬件而言,它会保证a地址之前(包括a地址)的指令都被执行完毕,并且a地址之后的指令都没有执行。因此,在这种情况下,临界区指令1的执行结果被抛弃掉,因此,实际临界区指令不会先于preempt_disable执行
(2)在地址a+4发生中断。这时候,虽然发生中断的那一刻的地址上的指令(临界区指令1)已经执行完毕了,但是硬件会保证地址a+4之前的所有的指令都执行完毕,因此,实际上CPU会执行完preempt_disable,然后跳转的中断异常向量执行。
上面描述的是优化屏障在内存中的变量的应用,下面我们看看硬件寄存器的场景。一般而言,串口的驱动都会包括控制台部分的代码,例如:
static struct console xx_serial_console = {
……
.write = xx_serial_console_write,
……
};
如果系统enable了串口控制台,那么当你的驱动调用printk的时候,实际上最终是通过console的write函数输出到了串口控制台。而这个console write的函数可能会包含下面的代码:
do {
获取TX FIFO状态寄存器
barrier();
} while (TX FIFO没有ready);
写TX FIFO寄存器;
对于某些CPU archtecture而言(至少ARM是这样的),外设硬件的IO地址也被映射到了一段内存地址空间,对编译器而言,它并不知道这些地址空间是属于外设的。因此,对于上面的代码,如果没有barrier的话,获取TX FIFO状态寄存器的指令可能和写TX FIFO寄存器指令进行重新排序,在这种情况下,程序逻辑就不对了,因为我们必须要保证TX FIFO ready的情况下才能写TX FIFO寄存器。
对于multi core的情况,上面的代码逻辑也是OK的,因为在调用console write函数的时候,要获取一个console semaphore,确保了只有一个thread进入,因此,console write的代码不会在多个CPU上并发。和preempt count的例子一样,我们可以问同样的问题,如果CPU是乱序执行(out-of-order excution)的呢?barrier只是保证compiler输出的汇编指令的顺序是OK的,不能确保CPU执行时候的乱序。 对这个问题的回答来自ARM architecture的内存访问模型:对于program order是A1-->A2的情况(A1和A2都是对Device或是Strongly-ordered的memory进行访问的指令),ARM保证A1也是先于A2执行的。因此,在这样的场景下,使用barrier足够了。 对于X86也是类似的,虽然它没有对IO space采样memory mapping的方式,但是,X86的所有操作IO端口的指令都是被顺执行的,不需要考虑memory access order。
2、cpu architecture和cache的组织
注:本章节的内容来自对Paul E. McKenney的Why memory barriers文档理解,更细致的内容可以参考该文档。这个章节有些晦涩,需要一些耐心。作为一个c程序员,你可能会抱怨,为何设计CPU的硬件工程师不能屏蔽掉memory barrier的内容,让c程序员关注在自己需要关注的程序逻辑上呢?本章可以展开叙述,或许能解决一些疑问。
(1)基本概念
在The Memory Hierarchy文档中,我们已经了解了关于cache一些基础的知识,一些基础的内容,这里就不再重复了。我们假设一个多核系统中的cache如下:

我们先了解一下各个cpu cache line状态的迁移过程:
(a)我们假设在有一个memory中的变量为多个CPU共享,那么刚开始的时候,所有的CPU的本地cache中都没有该变量的副本,所有的cacheline都是invalid状态。
(b)因此当cpu 0 读取该变量的时候发生cache miss(更具体的说叫做cold miss或者warmup miss)。当该值从memory中加载到chache 0中的cache line之后,该cache line的状态被设定为shared,而其他的cache都是Invalid。
(c)当cpu 1 读取该变量的时候,chache 1中的对应的cache line也变成shared状态。其实shared状态就是表示共享变量在一个或者多个cpu的cache中有副本存在。既然是被多个cache所共享,那么其中一个CPU就不能武断修改自己的cache而不通知其他CPU的cache,否则会有一致性问题。
(d)总是read多没劲,我们让CPU n对共享变量来一个load and store的操作。这时候,CPU n发送一个read invalidate命令,加载了Cache n的cache line,并将状态设定为exclusive,同时将所有其他CPU的cache对应的该共享变量的cacheline设定为invalid状态。正因为如此,CPU n实际上是独占了变量对应的cacheline(其他CPU的cacheline都是invalid了,系统中就这么一个副本),就算是写该变量,也不需要通知其他的CPU。CPU随后的写操作将cacheline设定为modified状态,表示cache中的数据已经dirty,和memory中的不一致了。modified状态和exclusive状态都是独占该cacheline,但是modified状态下,cacheline的数据是dirty的,而exclusive状态下,cacheline中的数据和memory中的数据是一致的。当该cacheline被替换出cache的时候,modified状态的cacheline需要write back到memory中,而exclusive状态不需要。
(e)在cacheline没有被替换出CPU n的cache之前,CPU 0再次读该共享变量,这时候会怎么样呢?当然是cache miss了(因为之前由于CPU n写的动作而导致其他cpu的cache line变成了invalid,这种cache miss叫做communiction miss)。此外,由于CPU n的cache line是modified状态,它必须响应这个读得操作(memory中是dirty的)。因此,CPU 0的cacheline变成share状态(在此之前,CPU n的cache line应该会发生write back动作,从而导致其cacheline也是shared状态)。当然,也可能是CPU n的cache line不发生write back动作而是变成invalid状态,CPU 0的cacheline变成modified状态,这和具体的硬件设计相关。
(2)Store buffer
我们考虑另外一个场景:在上一节中step e中的操作变成CPU 0对共享变量进行写的操作。这时候,写的性能变得非常的差,因为CPU 0必须要等到CPU n上的cacheline 数据传递到其cacheline之后,才能进行写的操作(CPU n上的cacheline 变成invalid状态,CPU 0则切换成exclusive状态,为后续的写动作做准备)。而从一个CPU的cacheline传递数据到另外一个CPU的cacheline是非常消耗时间的,而这时候,CPU 0的写的动作只是hold住,直到cacheline的数据完成传递。而实际上,这样的等待是没有意义的,因此,这时候cacheline的数据仍然会被覆盖掉。为了解决这个问题,多核系统中的cache修改如下:

这样,问题解决了,写操作不必等到cacheline被加载,而是直接写到store buffer中然后欢快的去干其他的活。在CPU n的cacheline把数据传递到其cache 0的cacheline之后,硬件将store buffer中的内容写入cacheline。
虽然性能问题解决了,但是逻辑错误也随之引入,我们可以看下面的例子:
我们假设a和b是共享变量,初始值都是0,可以被cpu0和cpu1访问。cpu 0的cache中保存了b的值(exclusive状态),没有a的值,而cpu 1的cache中保存了a的值,没有b的值,cpu 0执行的汇编代码是(用的是ARM汇编,没有办法,其他的都不是那么熟悉):
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r4, [pc, #20] -------------------------- 取变量b的地址
mov r3, #1
str r3, [r2] --------------------------a=1
str r3, [r4] --------------------------b=1
CPU 1执行的代码是:
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r3, [pc, #20] -------------------------- 取变量b的地址
start: ldr r3, [r3] -------------------------- 取变量b的值
cmp r3, #0 ------------------------ b的值是否等于0?
beq start ------------------------ 等于0的话跳转到startldr r2, [r2] -------------------------- 取变量a的值
当cpu 1执行到--取变量a的值--这条指令的时候,b已经是被cpu0修改为1了,这也就是说a=1这个代码已经执行了,因此,从汇编代码的逻辑来看,这时候a值应该是确定的1。然而并非如此,cpu 0和cpu 1执行的指令和动作描述如下:
| cpu 0执行的指令 | cpu 0动作描述 | cpu 1执行的指令 | cpu 1动作描述 |
| str r3, [r2] (a=1) | 1、发生cache miss 2、将1保存在store buffer中 3、发送read invalidate命令,试图从cpu 1的cacheline中获取数据,并invalidate其cache line 注:这里无需等待response,立刻执行下一条指令 | ldr r3, [r3] (获取b的值) | 1、发生cache miss 2、发送read命令,试图加载b对应的cacheline 注:这里cpu必须等待read response,下面的指令依赖于这个读取的结果 |
| str r3, [r4] (b=1) | 1、cache hit 2、cacheline中的值被修改为1,状态变成modified | ||
| 响应cpu 1的read命令,发送read response(b=1)给CPU 0。write back,将状态设定为shared | |||
| cmp r3, #0 | 1、cpu 1收到来自cpu 0的read response,加载b对应的cacheline,状态为shared 2、b等于1,因此不必跳转到start执行 | ||
| ldr r2, [r2] (获取a的值) | 1、cache hit 2、获取了a的旧值,也就是0 | ||
| 响应CPU 0的read invalid命令,将a对应的cacheline设为invalid状态,发送read response和invalidate ack。但是已经酿成大错了。 | |||
| 收到来自cpu 1的响应,将store buffer中的1写入cache line。 |
对于硬件,CPU不清楚具体的代码逻辑,它不可能直接帮助软件工程师,只是提供一些memory barrier的指令,让软件工程师告诉CPU他想要的内存访问逻辑顺序。这时候,cpu 0的代码修改如下:
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r4, [pc, #20] -------------------------- 取变量b的地址
mov r3, #1
str r3, [r2] --------------------------a=1确保清空store buffer的memory barrier instruction
str r3, [r4] --------------------------b=1
这种情况下,cpu 0和cpu 1执行的指令和动作描述如下:
| cpu 0执行的指令 | cpu 0动作描述 | cpu 1执行的指令 | cpu 1动作描述 |
| str r3, [r2] (a=1) | 1、发生cache miss 2、将1保存在store buffer中 3、发送read invalidate命令,试图从cpu 1的cacheline中获取数据,并invalidate其cache line 注:这里无需等待response,立刻执行下一条指令 | ldr r3, [r3] (获取b的值) | 1、发生cache miss 2、发送read命令,试图加载b对应的cacheline 注:这里cpu必须等待read response,下面的指令依赖于这个读取的结果 |
| memory barrier instruction | CPU收到memory barrier指令,知道软件要控制访问顺序,因此不会执行下一条str指令,要等到收到read response和invalidate ack后,将store buffer中所有数据写到cacheline之后才会执行后续的store指令 | ||
| cmp r3, #0 beq start | 1、cpu 1收到来自cpu 0的read response,加载b对应的cacheline,状态为shared 2、b等于0,跳转到start执行 | ||
| 响应CPU 0的read invalid命令,将a对应的cacheline设为invalid状态,发送read response和invalidate ack。 | |||
| 收到来自cpu 1的响应,将store buffer中的1写入cache line。 | |||
| str r3, [r4] (b=1) | 1、cache hit,但是cacheline状态是shared,需要发送invalidate到cpu 1 2、将1保存在store buffer中 注:这里无需等待invalidate ack,立刻执行下一条指令 | ||
| … | … | … | … |
由于增加了memory barrier,保证了a、b这两个变量的访问顺序,从而保证了程序逻辑。
(3)Invalidate Queue
我们先回忆一下为何出现了stroe buffer:为了加快cache miss状态下写的性能,硬件提供了store buffer,以便让CPU先写入,从而不必等待invalidate ack(这些交互是为了保证各个cpu的cache的一致性)。然而,store buffer的size比较小,不需要特别多的store命令(假设每次都是cache miss)就可以将store buffer填满,这时候,没有空间写了,因此CPU也只能是等待invalidate ack了,这个状态和memory barrier指令的效果是一样的。
怎么解决这个问题?CPU设计的硬件工程师对性能的追求是不会停歇的。我们首先看看invalidate ack为何如此之慢呢?这主要是因为cpu在收到invalidate命令后,要对cacheline执行invalidate命令,确保该cacheline的确是invalid状态后,才会发送ack。如果cache正忙于其他工作,当然不能立刻执行invalidate命令,也就无法会ack。
怎么破?CPU设计的硬件工程师提供了下面的方法:

Invalidate Queue这个HW block从名字就可以看出来是保存invalidate请求的队列。其他CPU发送到本CPU的invalidate命令会保存于此,这时候,并不需要等到实际对cacheline的invalidate操作完成,CPU就可以回invalidate ack了。
同store buffer一样,虽然性能问题解决了,但是对memory的访问顺序导致的逻辑错误也随之引入,我们可以看下面的例子(和store buffer中的例子类似):
我们假设a和b是共享变量,初始值都是0,可以被cpu0和cpu1访问。cpu 0的cache中保存了b的值(exclusive状态),而CPU 1和CPU 0的cache中都保存了a的值,状态是shared。cpu 0执行的汇编代码是:
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r4, [pc, #20] -------------------------- 取变量b的地址
mov r3, #1
str r3, [r2] --------------------------a=1确保清空store buffer的memory barrier instruction
str r3, [r4] --------------------------b=1
CPU 1执行的代码是:
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r3, [pc, #20] -------------------------- 取变量b的地址
start: ldr r3, [r3] -------------------------- 取变量b的值
cmp r3, #0 ------------------------ b的值是否等于0?
beq start ------------------------ 等于0的话跳转到startldr r2, [r2] -------------------------- 取变量a的值
这种情况下,cpu 0和cpu 1执行的指令和动作描述如下:
| cpu 0执行的指令 | cpu 0动作描述 | cpu 1执行的指令 | cpu 1动作描述 |
| str r3, [r2] (a=1) | 1、a值在CPU 0的cache中状态是shared,是read only的,因此,需要通知其他的CPU 2、将1保存在store buffer中 3、发送invalidate命令,试图invalidate CPU 1中a对应的cache line 注:这里无需等待response,立刻执行下一条指令 | ldr r3, [r3] (获取b的值) | 1、发生cache miss 2、发送read命令,试图加载b对应的cacheline 注:这里cpu必须等待read response,下面的指令依赖于这个读取的结果 |
| 收到来自CPU 0的invalidate命令,放入invalidate queue,立刻回ack。 | |||
| memory barrier instruction | CPU收到memory barrier指令,知道软件要控制访问顺序,因此不会执行下一条str指令,要等到收到invalidate ack后,将store buffer中所有数据写到cacheline之后才会执行后续的store指令 | ||
| 收到invalidate ack后,将store buffer中的1写入cache line。OK,可以继续执行下一条指令了 | |||
| str r3, [r4] (b=1) | 1、cache hit 2、cacheline中的值被修改为1,状态变成modified | ||
| 收到CPU 1发送来的read命令,将b值(等于1)放入read response中,回送给CPU 1,write back并将状态修改为shared。 | |||
| 收到response(b=1),并加载cacheline,状态是shared | |||
| cmp r3, #0 | b等于1,不会执行beq指令,而是执行下一条指令 | ||
| ldr r2, [r2] (获取a的值) | 1、cache hit (还没有执行invalidate动作,命令还在invalidate queue中呢) 2、获取了a的旧值,也就是0 | ||
| 对a对应的cacheline执行invalidate 命令,但是,已经晚了 |
可怕的memory misorder问题又来了,都是由于引入了invalidate queue引起,看来我们还需要一个memory barrier的指令,我们将程序修改如下:
ldr r2, [pc, #28] -------------------------- 取变量a的地址
ldr r3, [pc, #20] -------------------------- 取变量b的地址
start: ldr r3, [r3] -------------------------- 取变量b的值
cmp r3, #0 ------------------------ b的值是否等于0?
beq start ------------------------ 等于0的话跳转到start确保清空invalidate queue的memory barrier instruction
ldr r2, [r2] -------------------------- 取变量a的值
这种情况下,cpu 0和cpu 1执行的指令和动作描述如下:
| cpu 0执行的指令 | cpu 0动作描述 | cpu 1执行的指令 | cpu 1动作描述 |
| str r3, [r2] (a=1) | 1、a值在CPU 0的cache中状态是shared,是read only的,因此,需要通知其他的CPU 2、将1保存在store buffer中 3、发送invalidate命令,试图invalidate CPU 1中a对应的cache line 注:这里无需等待response,立刻执行下一条指令 | ldr r3, [r3] (获取b的值) | 1、发生cache miss 2、发送read命令,试图加载b对应的cacheline 注:这里cpu必须等待read response,下面的指令依赖于这个读取的结果 |
| 收到来自CPU 0的invalidate命令,放入invalidate queue,立刻回ack。 | |||
| memory barrier instruction | CPU收到memory barrier指令,知道软件要控制访问顺序,因此不会执行下一条str指令,要等到收到invalidate ack后,将store buffer中所有数据写到cacheline之后才会执行后续的store指令 | ||
| 收到invalidate ack后,将store buffer中的1写入cache line。OK,可以继续执行下一条指令了 | |||
| str r3, [r4] (b=1) | 1、cache hit 2、cacheline中的值被修改为1,状态变成modified | ||
| 收到CPU 1发送来的read命令,将b值(等于1)放入read response中,回送给CPU 1,write back并将状态修改为shared。 | |||
| 收到response(b=1),并加载cacheline,状态是shared | |||
| cmp r3, #0 | b等于1,不会执行beq指令,而是执行下一条指令 | ||
| memory barrier instruction | CPU收到memory barrier指令,知道软件要控制访问顺序,因此不会执行下一条ldr指令,要等到执行完invalidate queue中的所有的invalidate命令之后才会执行下一个ldr指令 | ||
| ldr r2, [r2] (获取a的值) | 1、cache miss 2、发送read命令,从CPU 0那里加载新的a值 |
由于增加了memory barrier,保证了a、b这两个变量的访问顺序,从而保证了程序逻辑。
三、linux kernel的API
linux kernel的memory barrier相关的API列表如下:
| 接口名称 | 作用 |
| barrier() | 优化屏障,阻止编译器为了进行性能优化而进行的memory access reorder |
| mb() | 内存屏障(包括读和写),用于SMP和UP |
| rmb() | 读内存屏障,用于SMP和UP |
| wmb() | 写内存屏障,用于SMP和UP |
| smp_mb() | 用于SMP场合的内存屏障,对于UP不存在memory order的问题(对汇编指令),因此,在UP上就是一个优化屏障,确保汇编和c代码的memory order是一致的 |
| smp_rmb() | 用于SMP场合的读内存屏障 |
| smp_wmb() | 用于SMP场合的写内存屏障 |
barrier()这个接口和编译器有关,对于gcc而言,其代码如下:
#define barrier() __asm__ __volatile__("": : :"memory")
这里的__volatile__主要是用来防止编译器优化的。而这里的优化是针对代码块而言的,使用嵌入式汇编的代码分成三块:
1、嵌入式汇编之前的c代码块
2、嵌入式汇编代码块
3、嵌入式汇编之后的c代码块
这里__volatile__就是告诉编译器:不要因为性能优化而将这些代码重排,我需要清清爽爽的保持这三块代码块的顺序(代码块内部是否重排不是这里的__volatile__管辖范围了)。
barrier中的嵌入式汇编中的clobber list没有描述汇编代码对寄存器的修改情况,只是有一个memory的标记。我们知道,clober list是gcc和gas的接口,用于gas通知gcc它对寄存器和memory的修改情况。因此,这里的memory就是告知gcc,在汇编代码中,我修改了memory中的内容,嵌入式汇编之前的c代码块和嵌入式汇编之后的c代码块看到的memory是不一样的,对memory的访问不能依赖于嵌入式汇编之前的c代码块中寄存器的内容,需要重新加载。
优化屏障是和编译器相关的,而内存屏障是和CPU architecture相关的,当然,我们选择ARM为例来描述内存屏障。
Linux内核同步机制之(四):spin lock
http://www.wowotech.net/kernel_synchronization/spinlock.html
一、前言
在linux kernel的实现中,经常会遇到这样的场景:共享数据被中断上下文和进程上下文访问,该如何保护呢?如果只有进程上下文的访问,那么可以考虑使用semaphore或者mutex的锁机制,但是现在中断上下文也参和进来,那些可以导致睡眠的lock就不能使用了,这时候,可以考虑使用spin lock。本文主要介绍了linux kernel中的spin lock的原理以及代码实现。由于spin lock是architecture dependent代码,因此,我们在第四章讨论了ARM32和ARM64上的实现细节。
注:本文需要进程和中断处理的基本知识作为支撑。
二、工作原理
1、spin lock的特点
我们可以总结spin lock的特点如下:
(1)spin lock是一种死等的锁机制。当发生访问资源冲突的时候,可以有两个选择:一个是死等,一个是挂起当前进程,调度其他进程执行。spin lock是一种死等的机制,当前的执行thread会不断的重新尝试直到获取锁进入临界区。
(2)只允许一个thread进入。semaphore可以允许多个thread进入,spin lock不行,一次只能有一个thread获取锁并进入临界区,其他的thread都是在门口不断的尝试。
(3)执行时间短。由于spin lock死等这种特性,因此它使用在那些代码不是非常复杂的临界区(当然也不能太简单,否则使用原子操作或者其他适用简单场景的同步机制就OK了),如果临界区执行时间太长,那么不断在临界区门口“死等”的那些thread是多么的浪费CPU啊(当然,现代CPU的设计都会考虑同步原语的实现,例如ARM提供了WFE和SEV这样的类似指令,避免CPU进入busy loop的悲惨境地)
(4)可以在中断上下文执行。由于不睡眠,因此spin lock可以在中断上下文中适用。
2、 场景分析
对于spin lock,其保护的资源可能来自多个CPU CORE上的进程上下文和中断上下文的中的访问,其中,进程上下文包括:用户进程通过系统调用访问,内核线程直接访问,来自workqueue中work function的访问(本质上也是内核线程)。中断上下文包括:HW interrupt context(中断handler)、软中断上下文(soft irq,当然由于各种原因,该softirq被推迟到softirqd的内核线程中执行的时候就不属于这个场景了,属于进程上下文那个分类了)、timer的callback函数(本质上也是softirq)、tasklet(本质上也是softirq)。
先看最简单的单CPU上的进程上下文的访问。如果一个全局的资源被多个进程上下文访问,这时候,内核如何交错执行呢?对于那些没有打开preemptive选项的内核,所有的系统调用都是串行化执行的,因此不存在资源争抢的问题。如果内核线程也访问这个全局资源呢?本质上内核线程也是进程,类似普通进程,只不过普通进程时而在用户态运行、时而通过系统调用陷入内核执行,而内核线程永远都是在内核态运行,但是,结果是一样的,对于non-preemptive的linux kernel,只要在内核态,就不会发生进程调度,因此,这种场景下,共享数据根本不需要保护(没有并发,谈何保护呢)。如果时间停留在这里该多么好,单纯而美好,在继续前进之前,让我们先享受这一刻。
当打开premptive选项后,事情变得复杂了,我们考虑下面的场景:
(1)进程A在某个系统调用过程中访问了共享资源R
(2)进程B在某个系统调用过程中也访问了共享资源R
会不会造成冲突呢?假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态。
多CPU core的场景和单核CPU打开preemptive选项的效果是一样的,这里不再赘述。
我们继续向前分析,现在要加入中断上下文这个因素。访问共享资源的thread包括:
(1)运行在CPU0上的进程A在某个系统调用过程中访问了共享资源R
(2)运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源R
(3)外设P的中断handler中也会访问共享资源R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本CPU上的中断联合使用。
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就OK了。
最后,我们讨论一下中断上下文之间的竞争。同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的sofirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。tasklet更简单,因为同一种tasklet不会多个CPU上并发,具体我就不分析了,大家自行思考吧。
三、通用代码实现
1、文件整理
和体系结构无关的代码如下:
(1)include/linux/spinlock_types.h。这个头文件定义了通用spin lock的基本的数据结构(例如spinlock_t)和如何初始化的接口(DEFINE_SPINLOCK)。这里的“通用”是指不论SMP还是UP都通用的那些定义。
(2)include/linux/spinlock_types_up.h。这个头文件不应该直接include,在include/linux/spinlock_types.h文件会根据系统的配置(是否SMP)include相关的头文件,如果UP则会include该头文件。这个头文定义UP系统中和spin lock的基本的数据结构和如何初始化的接口。当然,对于non-debug版本而言,大部分struct都是empty的。
(3)include/linux/spinlock.h。这个头文件定义了通用spin lock的接口函数声明,例如spin_lock、spin_unlock等,使用spin lock模块接口API的驱动模块或者其他内核模块都需要include这个头文件。
(4)include/linux/spinlock_up.h。这个头文件不应该直接include,在include/linux/spinlock.h文件会根据系统的配置(是否SMP)include相关的头文件。这个头文件是debug版本的spin lock需要的。
(5)include/linux/spinlock_api_up.h。同上,只不过这个头文件是non-debug版本的spin lock需要的
(6)linux/spinlock_api_smp.h。SMP上的spin lock模块的接口声明
(7)kernel/locking/spinlock.c。SMP上的spin lock实现。
头文件有些凌乱,我们对UP和SMP上spin lock头文件进行整理:
| UP需要的头文件 | SMP需要的头文件 |
| linux/spinlock_type_up.h: linux/spinlock_types.h: linux/spinlock_up.h: linux/spinlock_api_up.h: linux/spinlock.h | asm/spinlock_types.h linux/spinlock_types.h: asm/spinlock.h linux/spinlock_api_smp.h: linux/spinlock.h |
2、数据结构
根据第二章的分析,我们可以基本可以推断出spin lock的实现。首先定义一个spinlock_t的数据类型,其本质上是一个整数值(对该数值的操作需要保证原子性),该数值表示spin lock是否可用。初始化的时候被设定为1。当thread想要持有锁的时候调用spin_lock函数,该函数将spin lock那个整数值减去1,然后进行判断,如果等于0,表示可以获取spin lock,如果是负数,则说明其他thread的持有该锁,本thread需要spin。
内核中的spinlock_t的数据类型定义如下:
typedef struct spinlock {
struct raw_spinlock rlock;
} spinlock_t;typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
} raw_spinlock_t;
由于各种原因(各种锁的debug、锁的validate机制,多平台支持什么的),spinlock_t的定义没有那么直观,为了让事情简单一些,我们去掉那些繁琐的成员。struct spinlock中定义了一个struct raw_spinlock的成员,为何会如此呢?好吧,我们又需要回到kernel历史课本中去了。在旧的内核中(比如我熟悉的linux 2.6.23内核),spin lock的命令规则是这样:
通用(适用于各种arch)的spin lock使用spinlock_t这样的type name,各种arch定义自己的struct raw_spinlock。听起来不错的主意和命名方式,直到linux realtime tree(PREEMPT_RT)提出对spinlock的挑战。real time linux是一个试图将linux kernel增加硬实时性能的一个分支(你知道的,linux kernel mainline只是支持soft realtime),多年来,很多来自realtime branch的特性被merge到了mainline上,例如:高精度timer、中断线程化等等。realtime tree希望可以对现存的spinlock进行分类:一种是在realtime kernel中可以睡眠的spinlock,另外一种就是在任何情况下都不可以睡眠的spinlock。分类很清楚但是如何起名字?起名字绝对是个技术活,起得好了事半功倍,可维护性好,什么文档啊、注释啊都素那浮云,阅读代码就是享受,如沐春风。起得不好,注定被后人唾弃,或者拖出来吊打(这让我想起给我儿子起名字的那段不堪回首的岁月……)。最终,spin lock的命名规范定义如下:
(1)spinlock,在rt linux(配置了PREEMPT_RT)的时候可能会被抢占(实际底层可能是使用支持PI(优先级翻转)的mutext)。
(2)raw_spinlock,即便是配置了PREEMPT_RT也要顽强的spin
(3)arch_spinlock,spin lock是和architecture相关的,arch_spinlock是architecture相关的实现
对于UP平台,所有的arch_spinlock_t都是一样的,定义如下:
typedef struct { } arch_spinlock_t;
什么都没有,一切都是空啊。当然,这也符合前面的分析,对于UP,即便是打开的preempt选项,所谓的spin lock也不过就是disable preempt而已,不需定义什么spin lock的变量。
对于SMP平台,这和arch相关,我们在下一节描述。
3、spin lock接口API
我们整理spin lock相关的接口API如下:
| spinlock中的定义 | raw_spinlock的定义 | 接口API的类型 |
| DEFINE_SPINLOCK | DEFINE_RAW_SPINLOCK | 定义spin lock并初始化 |
| spin_lock_init | raw_spin_lock_init | 动态初始化spin lock |
| spin_lock | raw_spin_lock | 获取指定的spin lock |
| spin_lock_irq | raw_spin_lock_irq | 获取指定的spin lock同时disable本CPU中断 |
| spin_lock_irqsave | raw_spin_lock_irqsave | 保存本CPU当前的irq状态,disable本CPU中断并获取指定的spin lock |
| spin_lock_bh | raw_spin_lock_bh | 获取指定的spin lock同时disable本CPU的bottom half |
| spin_unlock | raw_spin_unlock | 释放指定的spin lock |
| spin_unlock_irq | raw_spin_unock_irq | 释放指定的spin lock同时enable本CPU中断 |
| spin_unlock_irqstore | raw_spin_unlock_irqstore | 释放指定的spin lock同时恢复本CPU的中断状态 |
| spin_unlock_bh | raw_spin_unlock_bh | 获取指定的spin lock同时enable本CPU的bottom half |
| spin_trylock | raw_spin_trylock | 尝试去获取spin lock,如果失败,不会spin,而是返回非零值 |
| spin_is_locked | raw_spin_is_locked | 判断spin lock是否是locked,如果其他的thread已经获取了该lock,那么返回非零值,否则返回0 |
在具体的实现面,我们不可能把每一个接口函数的代码都呈现出来,我们选择最基础的spin_lock为例子,其他的读者可以自己阅读代码来理解。
spin_lock的代码如下:
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
当然,在linux mainline代码中,spin_lock和raw_spin_lock是一样的,在realtime linux patch中,spin_lock应该被换成可以sleep的版本,当然具体如何实现我没有去看(也许直接使用了Mutex,毕竟它提供了优先级继承特性来解决了优先级翻转的问题),有兴趣的读者可以自行阅读,我们这里重点看看(本文也主要focus这个主题)真正的,不睡眠的spin lock,也就是是raw_spin_lock,代码如下:
#define raw_spin_lock(lock) _raw_spin_lock(lock)
UP中的实现:
#define _raw_spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)SMP的实现:
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
UP中很简单,本质上就是一个preempt_disable而已,和我们在第二章中分析的一致。SMP中稍显复杂,preempt_disable当然也是必须的,spin_acquire可以略过,这是和运行时检查锁的有效性有关的,如果没有定义CONFIG_LOCKDEP其实就是空函数。如果没有定义CONFIG_LOCK_STAT(和锁的统计信息相关),LOCK_CONTENDED就是调用do_raw_spin_lock而已,如果没有定义CONFIG_DEBUG_SPINLOCK,它的代码如下:
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}
__acquire和静态代码检查相关,忽略之,最终实际的获取spin lock还是要靠arch相关的代码实现。
四、ARM平台的细节
代码位于arch/arm/include/asm/spinlock.h和spinlock_type.h,和通用代码类似,spinlock_type.h定义ARM相关的spin lock定义以及初始化相关的宏;spinlock.h中包括了各种具体的实现。
1、回忆过去
在分析新的spin lock代码之前,让我们先回到2.6.23版本的内核中,看看ARM平台如何实现spin lock的。和arm平台相关spin lock数据结构的定义如下(那时候还是使用raw_spinlock_t而不是arch_spinlock_t):
typedef struct {
volatile unsigned int lock;
} raw_spinlock_t;
一个整数就OK了,0表示unlocked,1表示locked。配套的API包括__raw_spin_lock和__raw_spin_unlock。__raw_spin_lock会持续判断lock的值是否等于0,如果不等于0(locked)那么其他thread已经持有该锁,本thread就不断的spin,判断lock的数值,一直等到该值等于0为止,一旦探测到lock等于0,那么就设定该值为1,表示本thread持有该锁了,当然,这些操作要保证原子性,细节和exclusive版本的ldr和str(即ldrex和strexeq)相关,这里略过。立刻临界区后,持锁thread会调用__raw_spin_unlock函数是否spin lock,其实就是把0这个数值赋给lock。
这个版本的spin lock的实现当然可以实现功能,而且在没有冲突的时候表现出不错的性能,不过存在一个问题:不公平。也就是所有的thread都是在无序的争抢spin lock,谁先抢到谁先得,不管thread等了很久还是刚刚开始spin。在冲突比较少的情况下,不公平不会体现的特别明显,然而,随着硬件的发展,多核处理器的数目越来越多,多核之间的冲突越来越剧烈,无序竞争的spinlock带来的performance issue终于浮现出来,根据Nick Piggin的描述:
On an 8 core (2 socket) Opteron, spinlock unfairness is extremely noticable, with a userspace test having a difference of up to 2x runtime per thread, and some threads are starved or "unfairly" granted the lock up to 1 000 000 (!) times.
多么的不公平,有些可怜的thread需要饥饿的等待1000000次。本质上无序竞争从概率论的角度看应该是均匀分布的,不过由于硬件特性导致这么严重的不公平,我们来看一看硬件block:

lock本质上是保存在main memory中的,由于cache的存在,当然不需要每次都有访问main memory。在多核架构下,每个CPU都有自己的L1 cache,保存了lock的数据。假设CPU0获取了spin lock,那么执行完临界区,在释放锁的时候会调用smp_mb invalide其他忙等待的CPU的L1 cache,这样后果就是释放spin lock的那个cpu可以更快的访问L1cache,操作lock数据,从而大大增加的下一次获取该spin lock的机会。
2、回到现在:arch_spinlock_t
ARM平台中的arch_spinlock_t定义如下(little endian):
typedef struct {
union {
u32 slock;
struct __raw_tickets {
u16 owner;
u16 next;
} tickets;
};
} arch_spinlock_t;
本来以为一个简单的整数类型的变量就搞定的spin lock看起来没有那么简单,要理解这个数据结构,需要了解一些ticket-based spin lock的概念。如果你有机会去九毛九去排队吃饭(声明:不是九毛九的饭托,仅仅是喜欢面食而常去吃而已)就会理解ticket-based spin lock。大概是因为便宜,每次去九毛九总是无法长驱直入,门口的笑容可掬的靓女会给一个ticket,上面写着15号,同时会告诉你,当前状态是10号已经入席,11号在等待。
回到arch_spinlock_t,这里的owner就是当前已经入席的那个号码,next记录的是下一个要分发的号码。下面的描述使用普通的计算机语言和在九毛九就餐(假设九毛九只有一张餐桌)的例子来进行描述,估计可以让吃货更有兴趣阅读下去。最开始的时候,slock被赋值为0,也就是说owner和next都是0,owner和next相等,表示unlocked。当第一个个thread调用spin_lock来申请lock(第一个人就餐)的时候,owner和next相等,表示unlocked,这时候该thread持有该spin lock(可以拥有九毛九的唯一的那个餐桌),并且执行next++,也就是将next设定为1(再来人就分配1这个号码让他等待就餐)。也许该thread执行很快(吃饭吃的快),没有其他thread来竞争就调用spin_unlock了(无人等待就餐,生意惨淡啊),这时候执行owner++,也就是将owner设定为1(表示当前持有1这个号码牌的人可以就餐)。姗姗来迟的1号获得了直接就餐的机会,next++之后等于2。1号这个家伙吃饭巨慢,这是不文明现象(thread不能持有spin lock太久),但是存在。又来一个人就餐,分配当前next值的号码2,当然也会执行next++,以便下一个人或者3的号码牌。持续来人就会分配3、4、5、6这些号码牌,next值不断的增加,但是owner岿然不动,直到欠扁的1号吃饭完毕(调用spin_unlock),释放饭桌这个唯一资源,owner++之后等于2,表示持有2那个号码牌的人可以进入就餐了。
3、接口实现
同样的,这里也只是选择一个典型的API来分析,其他的大家可以自行学习。我们选择的是arch_spin_lock,其ARM32的代码如下:
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;prefetchw(&lock->slock);------------------------(1)
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"-------------------------(2)
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"------------------------(3)
" teq %2, #0\n"----------------------------(4)
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");while (lockval.tickets.next != lockval.tickets.owner) {------------(5)
wfe();-------------------------------(6)
lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);------(7)
}smp_mb();------------------------------(8)
}
(1)和preloading cache相关的操作,主要是为了性能考虑
(2)将slock的值保存在lockval这个临时变量中
(3)将spin lock中的next加一
(4)判断是否有其他的thread插入。更具体的细节参考<Linux内核同步机制之(一):原子操作>中的描述
(5)判断当前spin lock的状态,如果是unlocked,那么直接获取到该锁
(6)如果当前spin lock的状态是locked,那么调用wfe进入等待状态。更具体的细节请参考ARM WFI和WFE指令中的描述。
(7)其他的CPU唤醒了本cpu的执行,说明owner发生了变化,该新的own赋给lockval,然后继续判断spin lock的状态,也就是回到step 5。
(8)memory barrier的操作,具体可以参考<memory barrier>中的描述。
arch_spin_lock函数ARM64的代码(来自4.1.10内核)如下:
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;asm volatile(
/* Atomically increment the next ticket. */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"-----(A)-----------lockval = lock
" add %w1, %w0, %w5\n"-------------newval = lockval + (1 << 16),相当于next++
" stxr %w2, %w1, %3\n"--------------lock = newval
" cbnz %w2, 1b\n"--------------是否有其他PE的执行流插入?有的话,重来。
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"--lockval中的next域就是自己的号码牌,判断是否等于owner
" cbz %w1, 3f\n"----------------如果等于,持锁进入临界区
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"--------------------否则进入spin
" ldaxrh %w2, %4\n"----(A)---------其他cpu唤醒本cpu,获取当前owner值
" eor %w1, %w2, %w0, lsr #16\n"---------自己的号码牌是否等于owner?
" cbnz %w1, 2b\n"----------如果等于,持锁进入临界区,否者回到2,即继续spin
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
基本的代码逻辑的描述都已经嵌入代码中,这里需要特别说明的有两个知识点:
(1)Load-Acquire/Store-Release指令的应用。Load-Acquire/Store-Release指令是ARMv8的特性,在执行load和store操作的时候顺便执行了memory barrier相关的操作,在spinlock这个场景,使用Load-Acquire/Store-Release指令代替dmb指令可以节省一条指令。上面代码中的(A)就标识了使用Load-Acquire指令的位置。Store-Release指令在哪里呢?在arch_spin_unlock中,这里就不贴代码了。Load-Acquire/Store-Release指令的作用如下:
-Load-Acquire可以确保系统中所有的observer看到的都是该指令先执行,然后是该指令之后的指令(program order)再执行
-Store-Release指令可以确保系统中所有的observer看到的都是该指令之前的指令(program order)先执行,Store-Release指令随后执行
(2)第二个知识点是关于在arch_spin_unlock代码中为何没有SEV指令?关于这个问题可以参考ARM ARM文档中的Figure B2-5,这个图是PE(n)的global monitor的状态迁移图。当PE(n)对x地址发起了exclusive操作的时候,PE(n)的global monitor从open access迁移到exclusive access状态,来自其他PE上针对x(该地址已经被mark for PE(n))的store操作会导致PE(n)的global monitor从exclusive access迁移到open access状态,这时候,PE(n)的Event register会被写入event,就好象生成一个event,将该PE唤醒,从而可以省略一个SEV的指令。
注:
(1)+表示在嵌入的汇编指令中,该操作数会被指令读取(也就是说是输入参数)也会被汇编指令写入(也就是说是输出参数)。
(2)=表示在嵌入的汇编指令中,该操作数会是write only的,也就是说只做输出参数。
(3)I表示操作数是立即数
Linux内核同步机制之(五):Read/Write spin lock
http://www.wowotech.net/kernel_synchronization/rw-spinlock.html
一、为何会有rw spin lock?
在有了强大的spin lock之后,为何还会有rw spin lock呢?无他,仅仅是为了增加内核的并发,从而增加性能而已。spin lock严格的限制只有一个thread可以进入临界区,但是实际中,有些对共享资源的访问可以严格区分读和写的,这时候,其实多个读的thread进入临界区是OK的,使用spin lock则限制一个读thread进入,从而导致性能的下降。
本文主要描述RW spin lock的工作原理及其实现。需要说明的是Linux内核同步机制之(四):spin lock是本文的基础,请先阅读该文档以便保证阅读的畅顺。
二、工作原理
1、应用举例
我们来看一个rw spinlock在文件系统中的例子:
static struct file_system_type *file_systems;
static DEFINE_RWLOCK(file_systems_lock);
linux内核支持多种文件系统类型,例如EXT4,YAFFS2等,每种文件系统都用struct file_system_type来表示。内核中所有支持的文件系统用一个链表来管理,file_systems指向这个链表的第一个node。访问这个链表的时候,需要用file_systems_lock来保护,场景包括:
(1)register_filesystem和unregister_filesystem分别用来向系统注册和注销一个文件系统。
(2)fs_index或者fs_name等函数会遍历该链表,找到对应的struct file_system_type的名字或者index。
这些操作可以分成两类,第一类就是需要对链表进行更新的动作,例如向链表中增加一个file system type(注册)或者减少一个(注销)。另外一类就是仅仅对链表进行遍历的操作,并不修改链表的内容。在不修改链表的内容的前提下,多个thread进入这个临界区是OK的,都能返回正确的结果。但是对于第一类操作则不然,这样的更新链表的操作是排他的,只能是同时有一个thread在临界区中。
2、基本的策略
使用普通的spin lock可以完成上一节中描述的临界区的保护,但是,由于spin lock的特定就是只允许一个thread进入,因此这时候就禁止了多个读thread进入临界区,而实际上多个read thread可以同时进入的,但现在也只能是不停的spin,cpu强大的运算能力无法发挥出来,如果使用不断retry检查spin lock的状态的话(而不是使用类似ARM上的WFE这样的指令),对系统的功耗也是影响很大的。因此,必须有新的策略来应对:
我们首先看看加锁的逻辑:
(1)假设临界区内没有任何的thread,这时候任何read thread或者write thread可以进入,但是只能是其一。
(2)假设临界区内有一个read thread,这时候新来的read thread可以任意进入,但是write thread不可以进入
(3)假设临界区内有一个write thread,这时候任何的read thread或者write thread都不可以进入
(4)假设临界区内有一个或者多个read thread,write thread当然不可以进入临界区,但是该write thread也无法阻止后续read thread的进入,他要一直等到临界区一个read thread也没有的时候,才可以进入,多么可怜的write thread。
unlock的逻辑如下:
(1)在write thread离开临界区的时候,由于write thread是排他的,因此临界区有且只有一个write thread,这时候,如果write thread执行unlock操作,释放掉锁,那些处于spin的各个thread(read或者write)可以竞争上岗。
(2)在read thread离开临界区的时候,需要根据情况来决定是否让其他处于spin的write thread们参与竞争。如果临界区仍然有read thread,那么write thread还是需要spin(注意:这时候read thread可以进入临界区,听起来也是不公平的)直到所有的read thread释放锁(离开临界区),这时候write thread们可以参与到临界区的竞争中,如果获取到锁,那么该write thread可以进入。
三、实现
1、通用代码文件的整理
rw spin lock的头文件的结构和spin lock是一样的。include/linux/rwlock_types.h文件中定义了通用rw spin lock的基本的数据结构(例如rwlock_t)和如何初始化的接口(DEFINE_RWLOCK)。include/linux/rwlock.h。这个头文件定义了通用rw spin lock的接口函数声明,例如read_lock、write_lock、read_unlock、write_unlock等。include/linux/rwlock_api_smp.h文件定义了SMP上的rw spin lock模块的接口声明。
需要特别说明的是:用户不需要include上面的头文件,基本上普通spinlock和rw spinlock使用统一的头文件接口,用户只需要include一个include/linux/spinlock.h文件就OK了。
2、数据结构。rwlock_t数据结构定义如下:
typedef struct {
arch_rwlock_t raw_lock;
} rwlock_t;
rwlock_t依赖arch对rw spinlock相关的定义。
3、API
我们整理RW spinlock的接口API如下表:
| rw spinlock API | 接口API描述 |
| DEFINE_RWLOCK | 定义rw spin lock并初始化 |
| rwlock_init | 动态初始化rw spin lock |
| read_lock write_lock | 获取指定的rw spin lock |
| read_lock_irq write_lock_irq | 获取指定的rw spin lock同时disable本CPU中断 |
| read_lock_irqsave write_lock_irqsave | 保存本CPU当前的irq状态,disable本CPU中断并获取指定的rw spin lock |
| read_lock_bh write_lock_bh | 获取指定的rw spin lock同时disable本CPU的bottom half |
| read_unlock write_unlock | 释放指定的spin lock |
| read_unlock_irq write_unlock_irq | 释放指定的rw spin lock同时enable本CPU中断 |
| read_unlock_irqrestore write_unlock_irqrestore | 释放指定的rw spin lock同时恢复本CPU的中断状态 |
| read_unlock_bh write_unlock_bh | 获取指定的rw spin lock同时enable本CPU的bottom half |
| read_trylock write_trylock | 尝试去获取rw spin lock,如果失败,不会spin,而是返回非零值 |
在具体的实现面,如何将archtecture independent的代码转到具体平台的代码的思路是和spin lock一样的,这里不再赘述。
2、ARM上的实现
对于arm平台,rw spin lock的代码位于arch/arm/include/asm/spinlock.h和spinlock_type.h(其实普通spin lock的代码也是在这两个文件中),和通用代码类似,spinlock_type.h定义ARM相关的rw spin lock定义以及初始化相关的宏;spinlock.h中包括了各种具体的实现。我们先看arch_rwlock_t的定义:
typedef struct {
u32 lock;
} arch_rwlock_t;
毫无压力,就是一个32-bit的整数。从定义就可以看出rw spinlock不是ticket-based spin lock。我们再看看arch_write_lock的实现:
static inline void arch_write_lock(arch_rwlock_t *rw)
{
unsigned long tmp;prefetchw(&rw->lock); -------知道后面需要访问这个内存,先通知hw进行preloading cache
__asm__ __volatile__(
"1: ldrex %0, [%1]\n" -----获取lock的值并保存在tmp中
" teq %0, #0\n" --------判断是否等于0
WFE("ne") ----------如果tmp不等于0,那么说明有read 或者write的thread持有锁,那么还是静静的等待吧。其他thread会在unlock的时候Send Event来唤醒该CPU的
" strexeq %0, %2, [%1]\n" ----如果tmp等于0,将0x80000000这个值赋给lock
" teq %0, #0\n" --------是否str成功,如果有其他thread在上面的过程插入进来就会失败
" bne 1b" ---------如果不成功,那么需要重新来过,否则持有锁,进入临界区
: "=&r" (tmp) ----%0
: "r" (&rw->lock), "r" (0x80000000)-------%1和%2
: "cc");smp_mb(); -------memory barrier的操作
}
对于write lock,只要临界区有一个thread进行读或者写的操作(具体判断是针对32bit的lock进行,覆盖了writer和reader thread),该thread都会进入spin状态。如果临界区没有任何的读写thread,那么writer进入临界区,并设定lock=0x80000000。我们再来看看write unlock的操作:
static inline void arch_write_unlock(arch_rwlock_t *rw)
{
smp_mb(); -------memory barrier的操作__asm__ __volatile__(
"str %1, [%0]\n"-----------恢复0值
:
: "r" (&rw->lock), "r" (0) --------%0和%1
: "cc");dsb_sev();-------memory barrier的操作加上send event,wakeup其他 thread(那些cpu处于WFE状态)
}
write unlock看起来很简单,就是一个lock=0x0的操作。了解了write相关的操作后,我们再来看看read的操作:
static inline void arch_read_lock(arch_rwlock_t *rw)
{
unsigned long tmp, tmp2;prefetchw(&rw->lock);
__asm__ __volatile__(
"1: ldrex %0, [%2]\n"--------获取lock的值并保存在tmp中
" adds %0, %0, #1\n"--------tmp = tmp + 1
" strexpl %1, %0, [%2]\n"----如果tmp结果非负值,那么就执行该指令,将tmp值存入lock
WFE("mi")---------如果tmp是负值,说明有write thread,那么就进入wait for event状态
" rsbpls %0, %1, #0\n"-----判断strexpl指令是否成功执行
" bmi 1b"----------如果不成功,那么需要重新来过,否则持有锁,进入临界区
: "=&r" (tmp), "=&r" (tmp2)----------%0和%1
: "r" (&rw->lock)---------------%2
: "cc");smp_mb();
}
上面的代码比较简单,需要说明的是adds指令更新了状态寄存器(指令中s那个字符就是这个意思),strexpl会根据adds指令的执行结果来判断是否执行。pl的意思就是positive or zero,也就是说,如果结果是正数或者0(没有thread在临界区或者临界区内有若干read thread),该指令都会执行,如果是负数(有write thread在临界区),那么就不执行。OK,最后我们来看read unlock的函数:
static inline void arch_read_unlock(arch_rwlock_t *rw)
{
unsigned long tmp, tmp2;smp_mb();
prefetchw(&rw->lock);
__asm__ __volatile__(
"1: ldrex %0, [%2]\n"--------获取lock的值并保存在tmp中
" sub %0, %0, #1\n"--------tmp = tmp - 1
" strex %1, %0, [%2]\n"------将tmp值存入lock中
" teq %1, #0\n"------是否str成功,如果有其他thread在上面的过程插入进来就会失败
" bne 1b"-------如果不成功,那么需要重新来过,否则离开临界区
: "=&r" (tmp), "=&r" (tmp2)------------%0和%1
: "r" (&rw->lock)-----------------%2
: "cc");if (tmp == 0)
dsb_sev();-----如果read thread已经等于0,说明是最后一个离开临界区的reader,那么调用sev去唤醒WFE的cpu core
}
最后,总结一下:

32个bit的lock,0~30的bit用来记录进入临界区的read thread的数目,第31个bit用来记录write thread的数目,由于只允许一个write thread进入临界区,因此1个bit就OK了。在这样的设计下,read thread的数目最大就是2的30次幂减去1的数值,超过这个数值就溢出了,当然这个数值在目前的系统中已经足够的大了,姑且认为它是安全的吧。
四、后记
read/write spinlock对于read thread和write thread采用相同的优先级,read thread必须等待write thread完成离开临界区才可以进入,而write thread需要等到所有的read thread完成操作离开临界区才能进入。正如我们前面所说,这看起来对write thread有些不公平,但这就是read/write spinlock的特点。此外,在内核中,已经不鼓励对read/write spinlock的使用了,RCU是更好的选择。如何解决read/write spinlock优先级问题?RCU又是什么呢?我们下回分解。
Linux内核同步机制之(六):Seqlock
http://www.wowotech.net/kernel_synchronization/seqlock.html
一、前言
普通的spin lock对待reader和writer是一视同仁,RW spin lock给reader赋予了更高的优先级,那么有没有让writer优先的锁的机制呢?答案就是seqlock。本文主要描述linux kernel 4.0中的seqlock的机制,首先是seqlock的工作原理,如果想浅尝辄止,那么了解了概念性的东东就OK了,也就是第二章了,当然,我还是推荐普通的驱动工程师了解seqlock的API,第三章给出了一个简单的例子,了解了这些,在驱动中(或者在其他内核模块)使用seqlock就可以易如反掌了。细节是魔鬼,概念性的东西需要天才的思考,不是说就代码实现的细节就无足轻重,如果想进入seqlock的内心世界,推荐阅读第四章seqlock的代码实现,这一章和cpu体系结构相关的内容我们选择了ARM64(呵呵~~要跟上时代的步伐)。最后一章是参考资料,如果觉得本文描述不清楚,可以参考这些经典文献,在无数不眠之夜,她们给我心灵的慰籍,也愿能够给读者带来快乐。
二、工作原理
1、overview
seqlock这种锁机制是倾向writer thread,也就是说,除非有其他的writer thread进入了临界区,否则它会长驱直入,无论有多少的reader thread都不能阻挡writer的脚步。writer thread这么霸道,reader肿么办?对于seqlock,reader这一侧需要进行数据访问的过程中检测是否有并发的writer thread操作,如果检测到并发的writer,那么重新read。通过不断的retry,直到reader thread在临界区的时候,没有任何的writer thread插入即可。这样的设计对reader而言不是很公平,特别是如果writer thread负荷比较重的时候,reader thread可能会retry多次,从而导致reader thread这一侧性能的下降。
总结一下seqlock的特点:临界区只允许一个writer thread进入,在没有writer thread的情况下,reader thread可以随意进入,也就是说reader不会阻挡reader。在临界区只有有reader thread的情况下,writer thread可以立刻执行,不会等待。
2、writer thread的操作
对于writer thread,获取seqlock操作如下:
(1)获取锁(例如spin lock),该锁确保临界区只有一个writer进入。
(2)sequence counter加一
释放seqlock操作如下:
(1)释放锁,允许其他writer thread进入临界区。
(2)sequence counter加一(注意:不是减一哦,sequence counter是一个不断累加的counter)
由上面的操作可知,如果临界区没有任何的writer thread,那么sequence counter是偶数(sequence counter初始化为0),如果临界区有一个writer thread(当然,也只能有一个),那么sequence counter是奇数。
3、reader thread的操作如下:
(1)获取sequence counter的值,如果是偶数,可以进入临界区,如果是奇数,那么等待writer离开临界区(sequence counter变成偶数)。进入临界区时候的sequence counter的值我们称之old sequence counter。
(2)进入临界区,读取数据
(3)获取sequence counter的值,如果等于old sequence counter,说明一切OK,否则回到step(1)
4、适用场景。一般而言,seqlock适用于:
(1)read操作比较频繁
(2)write操作较少,但是性能要求高,不希望被reader thread阻挡(之所以要求write操作较少主要是考虑read side的性能)
(3)数据类型比较简单,但是数据的访问又无法利用原子操作来保护。我们举一个简单的例子来描述:假设需要保护的数据是一个链表,header--->A node--->B node--->C node--->null。reader thread遍历链表的过程中,将B node的指针赋给了临时变量x,这时候,中断发生了,reader thread被preempt(注意,对于seqlock,reader并没有禁止抢占)。这样在其他cpu上执行的writer thread有充足的时间释放B node的memory(注意:reader thread中的临时变量x还指向这段内存)。当read thread恢复执行,并通过x这个指针进行内存访问(例如试图通过next找到C node),悲剧发生了……
三、API示例
在kernel中,jiffies_64保存了从系统启动以来的tick数目,对该数据的访问(以及其他jiffies相关数据)需要持有jiffies_lock这个seq lock。
1、reader side代码如下:
u64 get_jiffies_64(void)
{do {
seq = read_seqbegin(&jiffies_lock);
ret = jiffies_64;
} while (read_seqretry(&jiffies_lock, seq));
}
2、writer side代码如下:
static void tick_do_update_jiffies64(ktime_t now)
{
write_seqlock(&jiffies_lock);临界区会修改jiffies_64等相关变量,具体代码略
write_sequnlock(&jiffies_lock);
}
对照上面的代码,任何工程师都可以比着葫芦画瓢,使用seqlock来保护自己的临界区。当然,seqlock的接口API非常丰富,有兴趣的读者可以自行阅读seqlock.h文件。
四、代码实现
1、seq lock的定义
typedef struct {
struct seqcount seqcount;----------sequence counter
spinlock_t lock;
} seqlock_t;
seq lock实际上就是spin lock + sequence counter。
2、write_seqlock/write_sequnlock
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);sl->sequence++;
smp_wmb();
}
唯一需要说明的是smp_wmb这个用于SMP场合下的写内存屏障,它确保了编译器以及CPU都不会打乱sequence counter内存访问以及临界区内存访问的顺序(临界区的保护是依赖sequence counter的值,因此不能打乱其顺序)。write_sequnlock非常简单,留给大家自己看吧。
3、read_seqbegin
static inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret;repeat:
ret = ACCESS_ONCE(sl->sequence); ---进入临界区之前,先要获取sequenc counter的快照
if (unlikely(ret & 1)) { -----如果是奇数,说明有writer thread
cpu_relax();
goto repeat; ----如果有writer,那么先不要进入临界区,不断的polling sequenc counter
}smp_rmb(); ---确保sequenc counter和临界区的内存访问顺序
return ret;
}
如果有writer thread,read_seqbegin函数中会有一个不断polling sequenc counter,直到其变成偶数的过程,在这个过程中,如果不加以控制,那么整体系统的性能会有损失(这里的性能指的是功耗和速度)。因此,在polling过程中,有一个cpu_relax的调用,对于ARM64,其代码是:
static inline void cpu_relax(void)
{
asm volatile("yield" ::: "memory");
}
yield指令用来告知硬件系统,本cpu上执行的指令是polling操作,没有那么急迫,如果有任何的资源冲突,本cpu可以让出控制权。
4、read_seqretry
static inline unsigned read_seqretry(const seqlock_t *sl, unsigned start)
{
smp_rmb();---确保sequenc counter和临界区的内存访问顺序
return unlikely(sl->sequence != start);
}
start参数就是进入临界区时候的sequenc counter的快照,比对当前退出临界区的sequenc counter,如果相等,说明没有writer进入打搅reader thread,那么可以愉快的离开临界区。
还有一个比较有意思的逻辑问题:read_seqbegin为何要进行奇偶判断?把一切都推到read_seqretry中进行判断不可以吗?也就是说,为何read_seqbegin要等到没有writer thread的情况下才进入临界区?其实有writer thread也可以进入,反正在read_seqretry中可以进行奇偶以及相等判断,从而保证逻辑的正确性。当然,这样想也是对的,不过在performance上有欠缺,reader在检测到有writer thread在临界区后,仍然放reader thread进入,可能会导致writer thread的一些额外的开销(cache miss),因此,最好的方法是在read_seqbegin中拦截。
五、参考文献
1、Understanding the Linux Kernel 3rd Edition
2、Linux Kernel Development 3rd Edition
3、Perfbook (https://www.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html)
RCU synchronize原理分析
http://www.wowotech.net/kernel_synchronization/223.html
RCU(Read-Copy Update)是Linux内核比较成熟的新型读写锁,具有较高的读写并发性能,常常用在需要互斥的性能关键路径。在kernel中,rcu有tiny rcu和tree rcu两种实现,tiny rcu更加简洁,通常用在小型嵌入式系统中,tree rcu则被广泛使用在了server, desktop以及android系统中。本文将以tree rcu为分析对象。
1 如何度过宽限期
RCU的核心理念是读者访问的同时,写者可以更新访问对象的副本,但写者需要等待所有读者完成访问之后,才能删除老对象。这个过程实现的关键和难点就在于如何判断所有的读者已经完成访问。通常把写者开始更新,到所有读者完成访问这段时间叫做宽限期(Grace Period)。内核中实现宽限期等待的函数是synchronize_rcu。
1.1 读者锁的标记
在普通的TREE RCU实现中,rcu_read_lock和rcu_read_unlock的实现非常简单,分别是关闭抢占和打开抢占:
- static inline void __rcu_read_lock(void)
- {
- preempt_disable();
- }
- static inline void __rcu_read_unlock(void)
- {
- preempt_enable();
- }
这时是否度过宽限期的判断就比较简单:每个CPU都经过一次抢占。因为发生抢占,就说明不在rcu_read_lock和rcu_read_unlock之间,必然已经完成访问或者还未开始访问。
1.2 每个CPU度过quiescnet state
接下来我们看每个CPU上报完成抢占的过程。kernel把这个完成抢占的状态称为quiescent state。每个CPU在时钟中断的处理函数中,都会判断当前CPU是否度过quiescent state。
这里补充一个细节说明,Tree RCU有多个类型的RCU State,用于不同的RCU场景,包括rcu_sched_state、rcu_bh_state和rcu_preempt_state。不同的场景使用不同的RCU API,度过宽限期的方式就有所区别。例如上面代码中的rcu_sched_qs和rcu_bh_qs,就是为了标记不同的state度过quiescent state。普通的RCU例如内核线程、系统调用等场景,使用rcu_read_lock或者rcu_read_lock_sched,他们的实现是一样的;软中断上下文则可以使用rcu_read_lock_bh,使得宽限期更快度过。
- void update_process_times(int user_tick)
- {
- ......
- rcu_check_callbacks(cpu, user_tick);
- ......
- }
- void rcu_check_callbacks(int cpu, int user)
- {
- ......
- if (user || rcu_is_cpu_rrupt_from_idle()) {
- /*在用户态上下文,或者idle上下文,说明已经发生过抢占*/
- rcu_sched_qs(cpu);
- rcu_bh_qs(cpu);
- } else if (!in_softirq()) {
- /*仅仅针对使用rcu_read_lock_bh类型的rcu,不在softirq,
- *说明已经不在read_lock关键区域*/
- rcu_bh_qs(cpu);
- }
- rcu_preempt_check_callbacks(cpu);
- if (rcu_pending(cpu))
- invoke_rcu_core();
- ......
- }
细分这些场景是为了提高RCU的效率。rcu_preempt_state将在下文进行说明。
1.3 汇报宽限期度过
每个CPU度过quiescent state之后,需要向上汇报直至所有CPU完成quiescent state,从而标识宽限期的完成,这个汇报过程在软中断RCU_SOFTIRQ中完成。软中断的唤醒则是在上述的时钟中断中进行。
update_process_times
-> rcu_check_callbacks
-> invoke_rcu_core
RCU_SOFTIRQ软中断处理的汇报流程如下:
rcu_process_callbacks
-> __rcu_process_callbacks
-> rcu_check_quiescent_state
-> rcu_report_qs_rdp
-> rcu_report_qs_rnp
其中rcu_report_qs_rnp是从叶子节点向根节点的遍历过程,同一个节点的子节点都通过quiescent state后,该节点也设置为通过。

这个树状的汇报过程,也就是“Tree RCU”这个名字得来的缘由。
树结构每层的节点数量和叶子节点数量由一系列的宏定义来决定:
- #define MAX_RCU_LVLS 4
- #define RCU_FANOUT_1 (CONFIG_RCU_FANOUT_LEAF)
- #define RCU_FANOUT_2 (RCU_FANOUT_1 * CONFIG_RCU_FANOUT)
- #define RCU_FANOUT_3 (RCU_FANOUT_2 * CONFIG_RCU_FANOUT)
- #define RCU_FANOUT_4 (RCU_FANOUT_3 * CONFIG_RCU_FANOUT)
- #if NR_CPUS <= RCU_FANOUT_1
- # define RCU_NUM_LVLS 1
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 (NR_CPUS)
- # define NUM_RCU_LVL_2 0
- # define NUM_RCU_LVL_3 0
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_2
- # define RCU_NUM_LVLS 2
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_2 (NR_CPUS)
- # define NUM_RCU_LVL_3 0
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_3
- # define RCU_NUM_LVLS 3
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_2)
- # define NUM_RCU_LVL_2 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_3 (NR_CPUS)
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_4
- # define RCU_NUM_LVLS 4
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_3)
- # define NUM_RCU_LVL_2 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_2)
- # define NUM_RCU_LVL_3 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_4 (NR_CPUS)
1.3 宽限期的发起与完成
所有宽限期的发起和完成都是由同一个内核线程rcu_gp_kthread来完成。通过判断rsp->gp_flags & RCU_GP_FLAG_INIT来决定是否发起一个gp;通过判断! (rnp->qsmask) && !rcu_preempt_blocked_readers_cgp(rnp))来决定是否结束一个gp。
发起一个GP时,rsp->gpnum++;结束一个GP时,rsp->completed = rsp->gpnum。
1.4 rcu callbacks处理
rcu的callback通常是在sychronize_rcu中添加的wakeme_after_rcu,也就是唤醒synchronize_rcu的进程,它正在等待GP的结束。
callbacks的处理同样在软中断RCU_SOFTIRQ中完成
rcu_process_callbacks
-> __rcu_process_callbacks
-> invoke_rcu_callbacks
-> rcu_do_batch
-> __rcu_reclaim
这里RCU的callbacks链表采用了一种分段链表的方式,整个callback链表,根据具体GP结束的时间,分成若干段:nxtlist -- *nxttail[RCU_DONE_TAIL] -- *nxttail[RCU_WAIT_TAIL] -- *nxttail[RCU_NEXT_READY_TAIL] -- *nxttail[RCU_NEXT_TAIL]。
rcu_do_batch只处理nxtlist -- *nxttail[RCU_DONE_TAIL]之间的callbacks。每个GP结束都会重新调整callback所处的段位,每个新的callback将会添加在末尾,也就是*nxttail[RCU_NEXT_TAIL]。
2 可抢占的RCU
如果config文件定义了CONFIG_TREE_PREEMPT_RCU=y,那么sychronize_rcu将默认使用rcu_preempt_state。这类rcu的特点就在于read_lock期间是允许其它进程抢占的,因此它判断宽限期度过的方法就不太一样。
从rcu_read_lock和rcu_read_unlock的定义就可以知道,TREE_PREEMPT_RCU并不是以简单的经过抢占为CPU渡过GP的标准,而是有个rcu_read_lock_nesting计数
- void __rcu_read_lock(void)
- {
- current->rcu_read_lock_nesting++;
- barrier(); /* critical section after entry code. */
- }
- void __rcu_read_unlock(void)
- {
- struct task_struct *t = current;
- if (t->rcu_read_lock_nesting != 1) {
- --t->rcu_read_lock_nesting;
- } else {
- barrier(); /* critical section before exit code. */
- t->rcu_read_lock_nesting = INT_MIN;
- barrier(); /* assign before ->rcu_read_unlock_special load */
- if (unlikely(ACCESS_ONCE(t->rcu_read_unlock_special)))
- rcu_read_unlock_special(t);
- barrier(); /* ->rcu_read_unlock_special load before assign */
- t->rcu_read_lock_nesting = 0;
- }
- }
当抢占发生时,__schedule函数会调用rcu_note_context_switch来通知RCU更新状态,如果当前CPU处于rcu_read_lock状态,当前进程将会放入rnp->blkd_tasks阻塞队列,并呈现在rnp->gp_tasks链表中。
从上文1.3节宽限期的结束处理过程我们可以知道,rcu_gp_kthread会判断! (rnp->qsmask) && !rcu_preempt_blocked_readers_cgp(rnp))两个条件来决定GP是否完成,其中!rnp->qsmask代表每个CPU都经过一次quiescent state,quiescent state的定义与传统RCU一致;!rcu_preempt_blocked_readers_cgp(rnp)这个条件就代表了rcu是否还有阻塞的进程。
Linux内核同步机制之(七):RCU基础
http://www.wowotech.net/kernel_synchronization/rcu_fundamentals.html
一、前言
关于RCU的文档包括两份,一份讲基本的原理(也就是本文了),一份讲linux kernel中的实现。第二章描述了为何有RCU这种同步机制,特别是在cpu core数目不断递增的今天,一个性能更好的同步机制是如何解决问题的,当然,再好的工具都有其适用场景,本章也给出了RCU的一些应用限制。第三章的第一小节描述了RCU的设计概念,其实RCU的设计概念比较简单,比较容易理解,比较困难的是产品级别的RCU实现,我们会在下一篇文档中描述。第三章的第二小节描述了RCU的相关操作,其实就是对应到了RCU的外部接口API上来。最后一章是参考文献,perfbook是一本神奇的数,喜欢并行编程的同学绝对不能错过的一本书,强烈推荐。和perfbook比起来,本文显得非常的丑陋(主要是有些RCU的知识还是理解不深刻,可能需要再仔细看看linux kernel中的实现才能了解其真正含义),除了是中文表述之外,没有任何的优点,英语比较好的同学可以直接参考该书。
二、为何有RCU这种同步机制呢?
前面我们讲了spin lock,rw spin lock和seq lock,为何又出现了RCU这样的同步机制呢?这个问题类似于问:有了刀枪剑戟这样的工具,为何会出现流星锤这样的兵器呢?每种兵器都有自己的适用场合,内核同步机制亦然。RCU在一定的应用场景下,解决了过去同步机制的问题,这也是它之所以存在的基石。本章主要包括两部分内容:一部分是如何解决其他内核机制的问题,另外一部分是受限的场景为何?
1、性能问题
我们先回忆一下spin lcok、RW spin lcok和seq lock的基本原理。对于spin lock而言,临界区的保护是通过next和owner这两个共享变量进行的。线程调用spin_lock进入临界区,这里包括了三个动作:
(1)获取了自己的号码牌(也就是next值)和允许哪一个号码牌进入临界区(owner)
(2)设定下一个进入临界区的号码牌(next++)
(3)判断自己的号码牌是否是允许进入的那个号码牌(next == owner),如果是,进入临界区,否者spin(不断的获取owner的值,判断是否等于自己的号码牌,对于ARM64处理器而言,可以使用WFE来降低功耗)。
注意:(1)是取值,(2)是更新并写回,因此(1)和(2)必须是原子操作,中间不能插入任何的操作。
线程调用spin_unlock离开临界区,执行owner++,表示下一个线程可以进入。
RW spin lcok和seq lock都类似spin lock,它们都是基于一个memory中的共享变量(对该变量的访问是原子的)。我们假设系统架构如下:
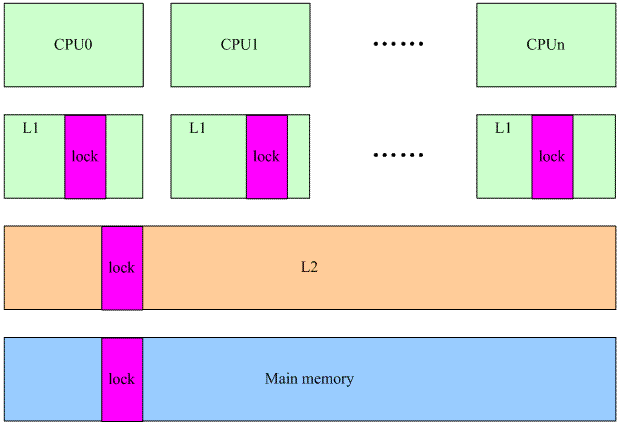
当线程在多个cpu上争抢进入临界区的时候,都会操作那个在多个cpu之间共享的数据lock(玫瑰色的block)。cpu 0操作了lock,为了数据的一致性,cpu 0的操作会导致其他cpu的L1中的lock变成无效,在随后的来自其他cpu对lock的访问会导致L1 cache miss(更准确的说是communication cache miss),必须从下一个level的cache中获取,同样的,其他cpu的L1 cache中的lock也被设定为invalid,从而引起下一次其他cpu上的communication cache miss。
RCU的read side不需要访问这样的“共享数据”,从而极大的提升了reader侧的性能。
2、reader和writer可以并发执行
spin lock是互斥的,任何时候只有一个thread(reader or writer)进入临界区,rw spin lock要好一些,允许多个reader并发执行,提高了性能。不过,reader和updater不能并发执行,RCU解除了这些限制,允许一个updater(不能多个updater进入临界区,这可以通过spinlock来保证)和多个reader并发执行。我们可以比较一下rw spin lock和RCU,参考下图:

rwlock允许多个reader并发,因此,在上图中,三个rwlock reader愉快的并行执行。当rwlock writer试图进入的时候(红色虚线),只能spin,直到所有的reader退出临界区。一旦有rwlock writer在临界区,任何的reader都不能进入,直到writer完成数据更新,立刻临界区。绿色的reader thread们又可以进行愉快玩耍了。rwlock的一个特点就是确定性,白色的reader一定是读取的是old data,而绿色的reader一定获取的是writer更新之后的new data。RCU和传统的锁机制不同,当RCU updater进入临界区的时候,即便是有reader在也无所谓,它可以长驱直入,不需要spin。同样的,即便有一个updater正在临界区里面工作,这并不能阻挡RCU reader的步伐。由此可见,RCU的并发性能要好于rwlock,特别如果考虑cpu的数目比较多的情况,那些处于spin状态的cpu在无谓的消耗,多么可惜,随着cpu的数目增加,rwlock性能不断的下降。RCU reader和updater由于可以并发执行,因此这时候的被保护的数据有两份,一份是旧的,一份是新的,对于白色的RCU reader,其读取的数据可能是旧的,也可能是新的,和数据访问的timing相关,当然,当RCU update完成更新之后,新启动的RCU reader(绿色block)读取的一定是新的数据。
3、适用的场景
我们前面说过,每种锁都有自己的适用的场景:spin lock不区分reader和writer,对于那些读写强度不对称的是不适合的,RW spin lcok和seq lock解决了这个问题,不过seq lock倾向writer,而RW spin lock更照顾reader。看起来一切都已经很完美了,但是,随着计算机硬件技术的发展,CPU的运算速度越来越快,相比之下,存储器件的速度发展较为滞后。在这种背景下,获取基于counter(需要访问存储器件)的锁(例如spin lock,rwlock)的机制开销比较大。而且,目前的趋势是:CPU和存储器件之间的速度差别在逐渐扩大。因此,那些基于一个multi-processor之间的共享的counter的锁机制已经不能满足性能的需求,在这种情况下,RCU机制应运而生(当然,更准确的说RCU一种内核同步机制,但不是一种lock,本质上它是lock-free的),它克服了其他锁机制的缺点,但是,甘蔗没有两头甜,RCU的使用场景比较受限,主要适用于下面的场景:
(1)RCU只能保护动态分配的数据结构,并且必须是通过指针访问该数据结构
(2)受RCU保护的临界区内不能sleep(SRCU不是本文的内容)
(3)读写不对称,对writer的性能没有特别要求,但是reader性能要求极高。
(4)reader端对新旧数据不敏感。
三、RCU的基本思路
1、原理
RCU的基本思路可以通过下面的图片体现:

RCU涉及的数据有两种,一个是指向要保护数据的指针,我们称之RCU protected pointer。另外一个是通过指针访问的共享数据,我们称之RCU protected data,当然,这个数据必须是动态分配的 。对共享数据的访问有两种,一种是writer,即对数据要进行更新,另外一种是reader。如果在有reader在临界区内进行数据访问,对于传统的,基于锁的同步机制而言,reader会阻止writer进入(例如spin lock和rw spin lock。seqlock不会这样,因此本质上seqlock也是lock-free的),因为在有reader访问共享数据的情况下,write直接修改data会破坏掉共享数据。怎么办呢?当然是移除了reader对共享数据的访问之后,再让writer进入了(writer稍显悲剧)。对于RCU而言,其原理是类似的,为了能够让writer进入,必须首先移除reader对共享数据的访问,怎么移除呢?创建一个新的copy是一个不错的选择。因此RCU writer的动作分成了两步:
(1)removal。write分配一个new version的共享数据进行数据更新,更新完毕后将RCU protected pointer指向新版本的数据。一旦把RCU protected pointer指向的新的数据,也就意味着将其推向前台,公布与众(reader都是通过pointer访问数据的)。通过这样的操作,原来read 0、1、2对共享数据的reference被移除了(对于新版本的受RCU保护的数据而言),它们都是在旧版本的RCU protected data上进行数据访问。
(2)reclamation。共享数据不能有两个版本,因此一定要在适当的时机去回收旧版本的数据。当然,不能太着急,不能reader线程还访问着old version的数据的时候就强行回收,这样会让reader crash的。reclamation必须发生在所有的访问旧版本数据的那些reader离开临界区之后再回收,而这段等待的时间被称为grace period。
顺便说明一下,reclamation并不需要等待read3和4,因为write端的为RCU protected pointer赋值的语句是原子的,乱入的reader线程要么看到的是旧的数据,要么是新的数据。对于read3和4,它们访问的是新的共享数据,因此不会reference旧的数据,因此reclamation不需要等待read3和4离开临界区。
2、基本RCU操作
对于reader,RCU的操作包括:
(1)rcu_read_lock,用来标识RCU read side临界区的开始。
(2)rcu_dereference,该接口用来获取RCU protected pointer。reader要访问RCU保护的共享数据,当然要获取RCU protected pointer,然后通过该指针进行dereference的操作。
(3)rcu_read_unlock,用来标识reader离开RCU read side临界区
对于writer,RCU的操作包括:
(1)rcu_assign_pointer。该接口被writer用来进行removal的操作,在witer完成新版本数据分配和更新之后,调用这个接口可以让RCU protected pointer指向RCU protected data。
(2)synchronize_rcu。writer端的操作可以是同步的,也就是说,完成更新操作之后,可以调用该接口函数等待所有在旧版本数据上的reader线程离开临界区,一旦从该函数返回,说明旧的共享数据没有任何引用了,可以直接进行reclaimation的操作。
(3)call_rcu。当然,某些情况下(例如在softirq context中),writer无法阻塞,这时候可以调用call_rcu接口函数,该函数仅仅是注册了callback就直接返回了,在适当的时机会调用callback函数,完成reclaimation的操作。这样的场景其实是分开removal和reclaimation的操作在两个不同的线程中:updater和reclaimer。
四、参考文档
1、perfbook
2、linux-4.1.10\Documentation\RCU\*
