ng-深度学习-课程笔记-16: 自然语言处理与词嵌入(Week2)
1 词汇表征(Word representation)
用one-hot表示单词的一个缺点就是它把每个词孤立起来,这使得算法对词语的相关性泛化不强。
可以使用词嵌入(word embedding)来解决这个问题,对于每个词,有潜在的比如300个特征,每个特征给个值,以此来表示每个词。
最终学到的词嵌入的特征不是那么好理解的,有些特征可能是几种常见特征的组合,总之可能是各种各样潜在的不知名特征。
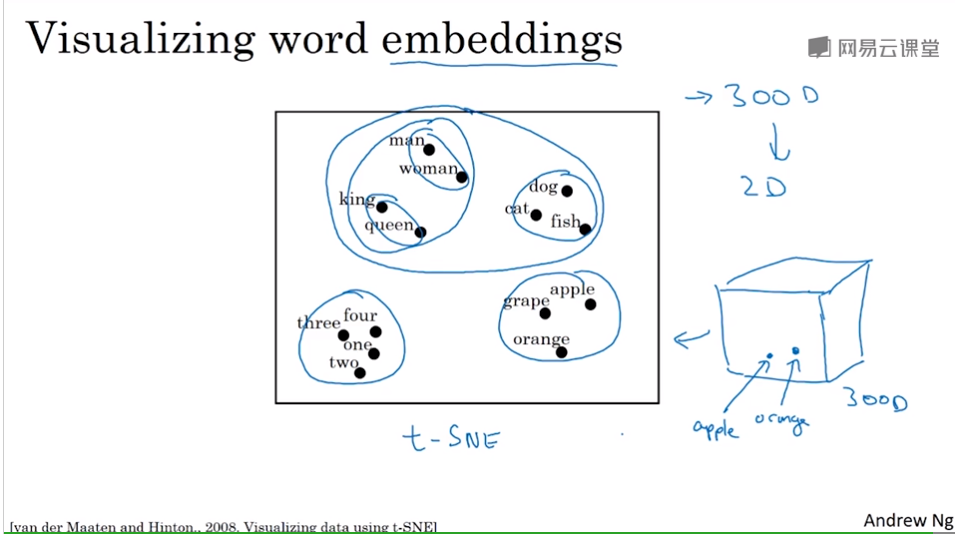
最终学到的300维特征,如果用t-SNE映射到2维,相关性较强的词会聚在一起,相近的词语学到的特征会相似。
被称为词嵌入的原因就是,一个词在300维的空间里,就像被嵌在这个空间里一样。
2 使用词嵌入(Using word embeddings)
用词嵌入表示来处理文本任务时,比如命名实体识别,学习“Sally Johnson is an organe farmer ”之后,直到Sally Johnson是人名,因为橘子种植者肯定是个人。
那么在对" Robert Lin is an apple farmer "进行处理时你的模型可以预测出apple和orange具有相似性,它们都是水果,从而预测出Robert Lin也是个人。
但是对于一些冷门的词,比如durian榴莲,这个词在你的训练集中没有出现,你只有少量的数据集,模型就不能识别出它为水果。
如果你有一个已经学好的词嵌入(词向量)的模型,它会告诉你榴莲是水果,那就好了。
一般词嵌入模型都会考察大量的无标签文本数据集,1 billion甚至是100billion,你可以把这些词嵌入模型应用到你的文本处理任务当中,即使你的训练集词汇很小。这就利用了迁移学习的思想。
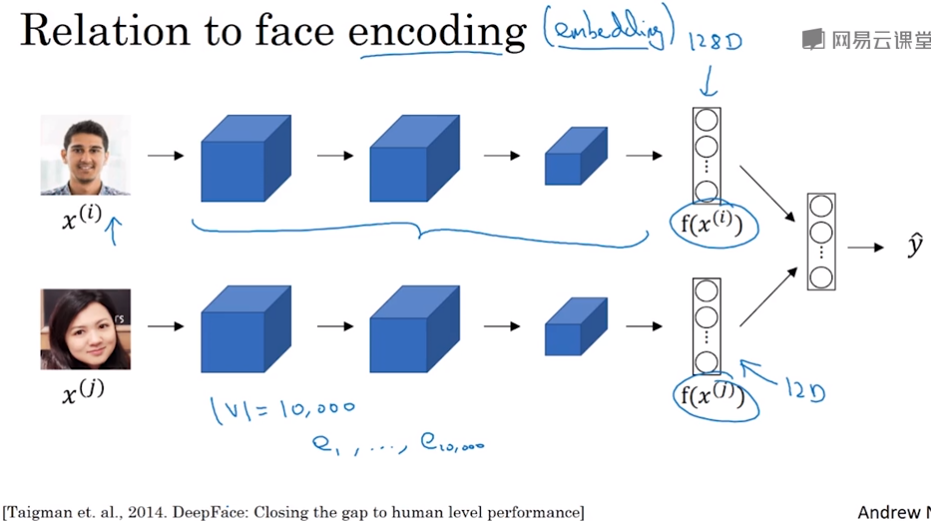
词嵌入和人脸编码之间有奇妙的关系,比如人脸网路中会学到128维的一个编码encoding,通过比较人脸的编码来判断是否两张图片是同一个人脸。词嵌入的意思跟这个差不多,embedding和encoding这两个术语是可以互换的。而人脸领域的编码和词语的嵌入有一个不同就是,人脸识别中给定任一图片甚至是没见过的都能给出一个编码,而词嵌入的词是从一个固定的词汇表中来的。
3 词嵌入的特征(Properties of word embeddings)
词嵌入有一个迷人的特性,它能帮助实现类比推理。
man和woman的关系,对应于king和XXX的关系,词嵌入可以自动推理出这个关系,知道XXX就是queen。
具体做法是找一个w,使得w和 (king - man + woman)的相似度最大,相似度可以使用余弦相似度,或者欧式距离。

4 学习词嵌入(Learning word embeddings)
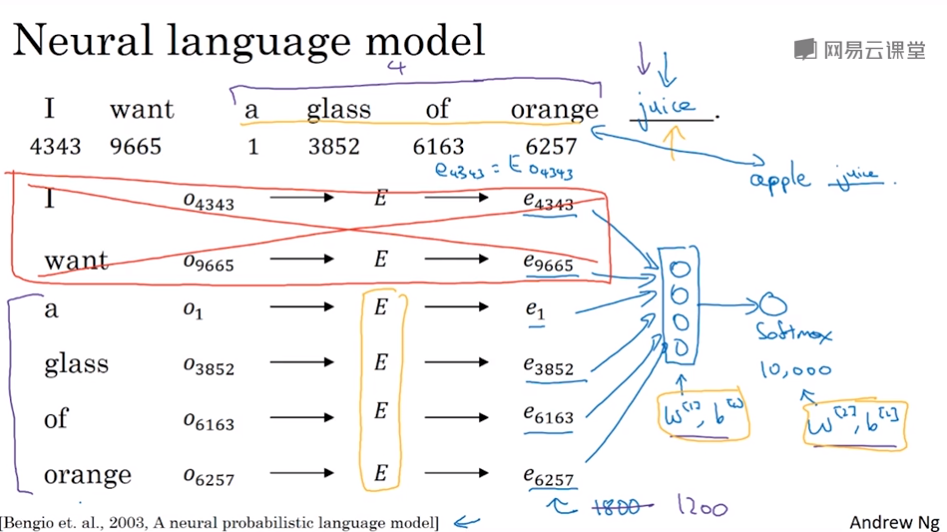
如何从one-hot向量得到词向量(词嵌入)呢?假设词汇表有10000个词,每个词有一个one-hot向量,shape为(10000,1)
假设每个词的词向量维度为300维,那么就可以生成一个随机矩阵E,shape为(300,10000)
我们希望E和one-hot向量相乘,可以得到词向量,shape为(300,1)
对于一句话,想预测某个位置未知的单词,可以把其它的单词词向量,丢进神经网络,输出softmax概率(10000个单元)来预测句子中未知的单词。然后用梯度下降来优化网络和矩阵E。
更常见的做法可以使用一个固定的窗口值(上下文范围),比如只用前四个单词和后四个单词来预测 。
这是早期学习词向量学习的不错的一个模型。
5 Word2Vec
假设训练集中给定了一个句子。
在skip-gram模型中我们要做的是抽取上下文Context和目标词Target,来构造一个监督学习问题。
我们要做的是随机选一个词作为Context
然后在一定词距内随机选择另一个词作为Target,重复数次就会得到好多个target,构造的监督学习问题就是希望在这些target里找出正确target。

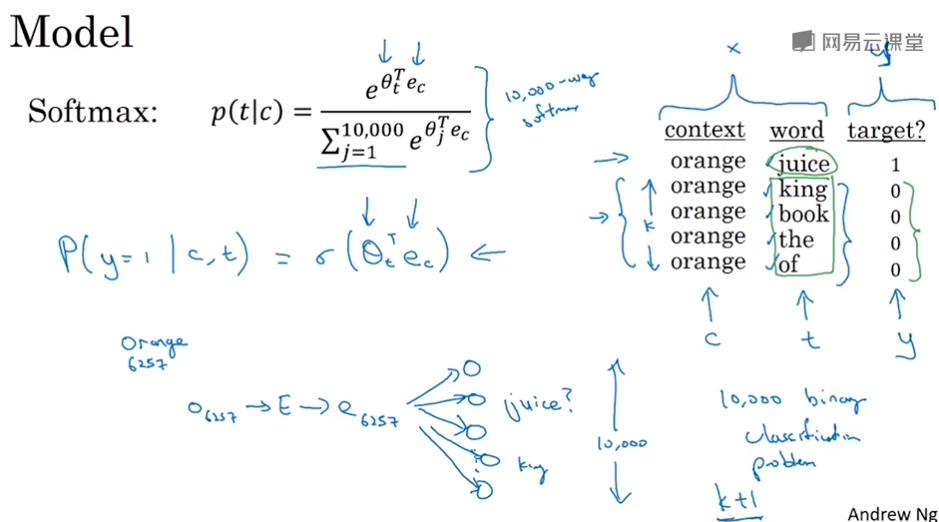
比如输入Context是“orange”,先用orange的one-hot向量和E矩阵得到orange的词向量,然后丢进神经网络,输出是softmax概率,得到从左数或从右数的某些词(some words skipping a few words from left or the right)
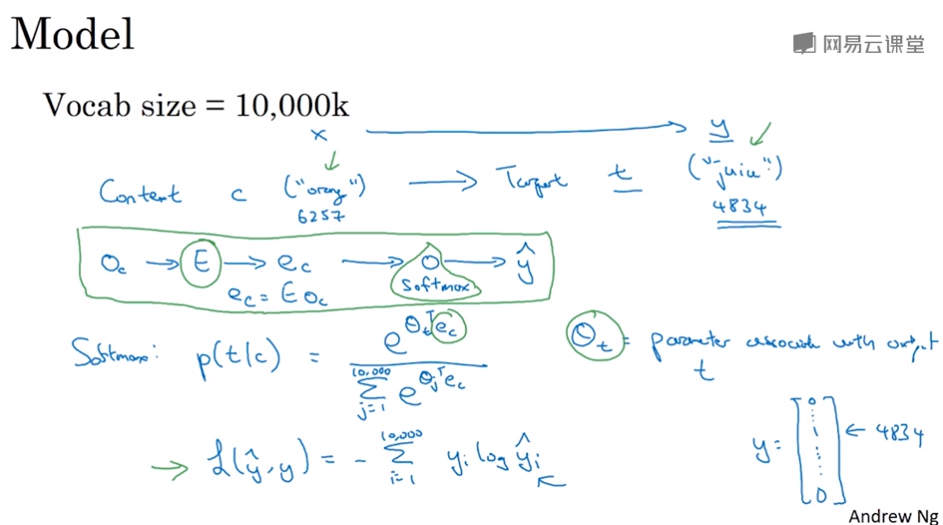
这样的skip-gram有一些问题,首要的问题就是计算速度,比如计算softmax概率,词汇量是10000就要对所有10000个词做求和计算。如果词汇量很大,这个计算是相当慢的。
一个加速softmax的解决办法就是Hierarchical softmax分类器,它不是一下子就确定到底是属于10000类的哪一类,而是使用一颗二叉树来分类。实践上树被设计成树顶的是常用词,树底的是冷门词语。
还有一个值得注意的是如何采样Context,如果你均匀地采样,采样到很多the,of,a,and,to这样的词,你可能不希望你的训练集里的数据都是这些出现很频繁的词。所以实际上采样要采用启发式的方法来采样一些常见的词和一些不那么常见的词。
实际上,论文中还有另一个模型叫CBOW(Continous Bag-of-Words)它获取中间词两边的上下文,用周围的词去预测中间的词,这个模型也很有效,也有一些优点和缺点。
6 负采样(Negative sampling)
skip-gram中softmax的计算太慢,可以使用负采样,它能做到和skip-gram模型类似的事,但是使用了更高效的学习算法
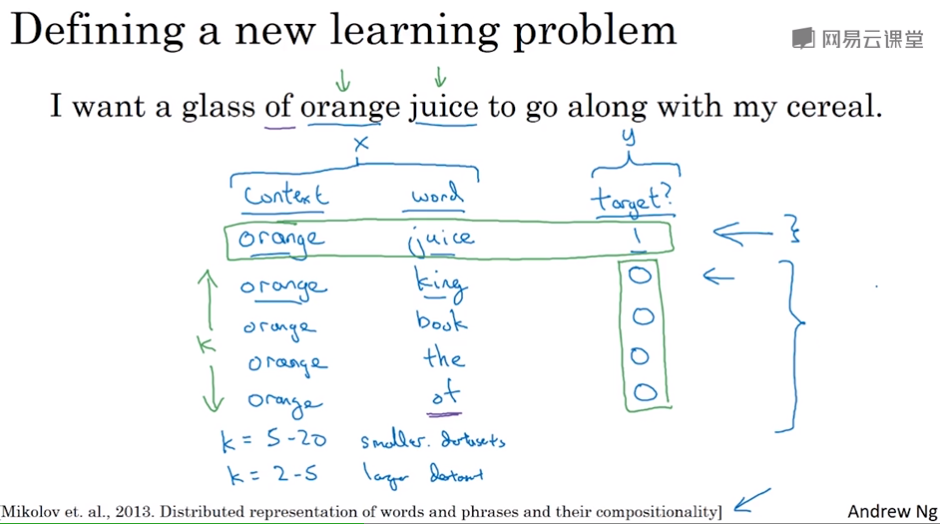
这个方法要构造的是一个新的监督学习问题
给定一对单词,比如orange和juice,我们要去预测这是否是一对(context,target),这里标记为1,生成一个正样本
再取orange和一个不相关的target,比如orange和king,我们则标记为0,生成了一个负样本
以此类推,可以随机抽取很多个target(随机刚好抽中相关的词也没关系),生成很多负样本,比如K个
也就是说每1个正样本,有对应的K个负样本
我们要构造的监督学习问题就是希望输入一对(context,target),输出0或1
论文中推荐,小数据集k从5-20比较好,数据集很大的话k就选小一点,为2~5
那么在网络训练的时候就不用训练一个10000维的softmax函数,而是把它转为10000个二分类(sigmoid)问题
假设k为4的话,训练迭代的时候,输出层只需要用5个simoid函数,1个表示正样本的输出,其它4个表示负样本的输出。
还有一个细节问题就是负样本应该如何采样,一个办法就是根据候选的目标词在语料库出现的频率来取样,但是这会导致你取到很多the,of,and这样的词上,另一个办法是均匀随机地采,使用1/|V|的概率采,V是词汇量大小,这样也是不好的选择。论文中给出了一个折中的经验值,很多研究者都在用,如下图所示,其中f(wi)是wi出现的frequency

7 情感分类(Sentiment classification)
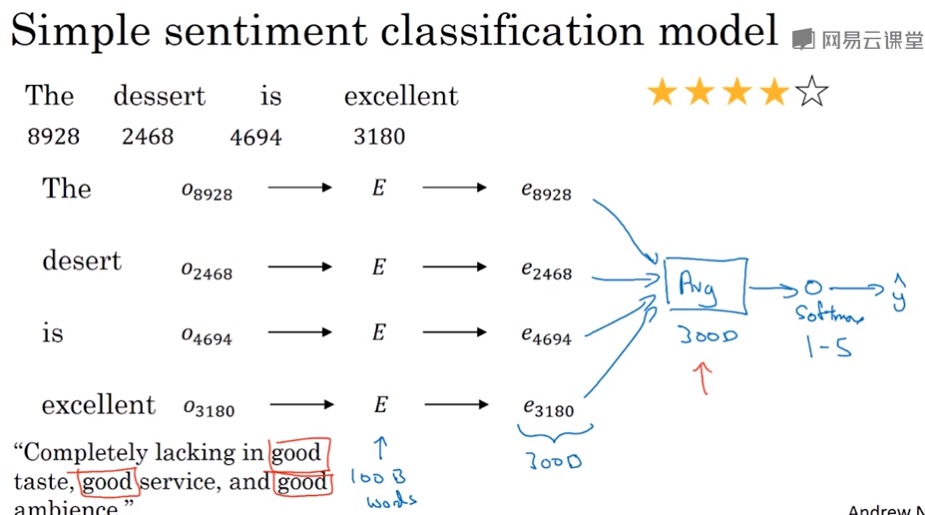
一个简单的做法,将评论用词向量表示,然后相加取平均,丢进softmax取进行分类
其中E可以是从大量的文本数据中训练好的矩阵,然后拿来用,词和矩阵E操作,可以得到这个词对应的词向量。
有一个问题就是,比如一句话出现了很多good,你的分类器可能会认为这是一个好评论,但是前面有个lacking,这实际上是个差评论。
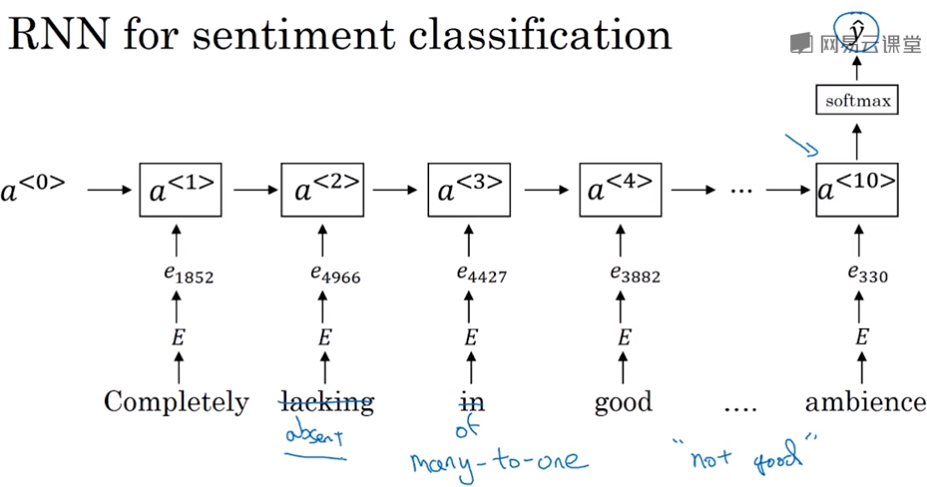
所以更好的做法是用一个RNN来做,它能意识到“没有好味道”是一个负面评价