ng-深度学习-课程笔记-1: 介绍深度学习(Week1)
1 什么是神经网络( What is a neural network )
深度学习一般是指非常非常大的神经网络,那什么是神经网络呢?
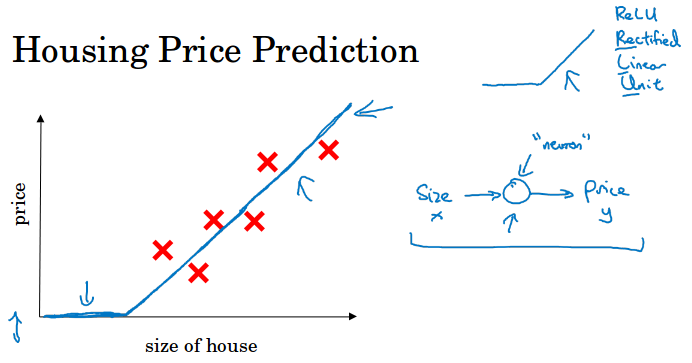
以房子价格预测为例,现在你有6个房子(样本数量),你知道房子的大小和对应价格,你想要建立一个函数来用房子的大小来预测价格。
我们可以用线性回归( linear regression) 来拟合这些数据。
可以把这个函数视作最为简单的神经元,用房子的大小x作为对神经元的输出,把房价y作为神经元的输出。神经网络就是有很多个这样的神经元堆积起来的。
所有的神经元都计算这个直线拟合的线性方程,结果输出取max(0,y),这里取max是因为价格不能为负。这个函数叫做relu函数( Rectified Linear Unite 线性整流 )
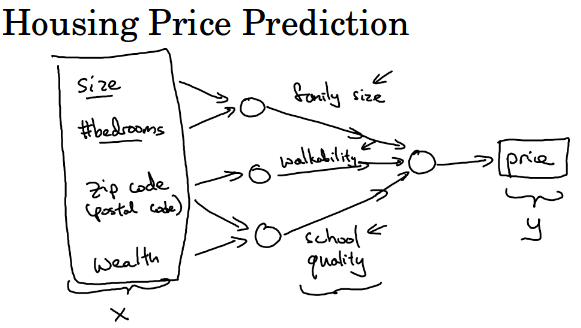
假设我们除了房子的大小外还有新的特征来预测价格。人们究竟要为房子花多少钱,取决于它们看重的这些因素,这些能帮助你去预测房价。
比如卧室的数量,你认为房子大小和卧室的数量决定了家庭人口的容量,而家庭人口容量是一个重要的因素。
比如邮编,你认为它可以告诉你步行的便利程度,像是去便利店,去上学是否比较方便,是否需要开车。
比如街区的富裕程度,你认为邮编和街区的富裕程度可以告诉你附近学校质量的好坏。
在这个例子中,输入x的四个维度为(房屋大小,卧室数量,邮政编码,富裕程度),输出y就是你要预测的价格。
图中的每一个小圈圈可以使relu函数或者其它的非线性函数。通过堆叠一些单一的神经元,我们可以得到稍微大一些的神经网络。
你只需要给神经网络大量的训练数据(输入x和输出y),而所有在中间的东西,神经网络会自己搞清楚。
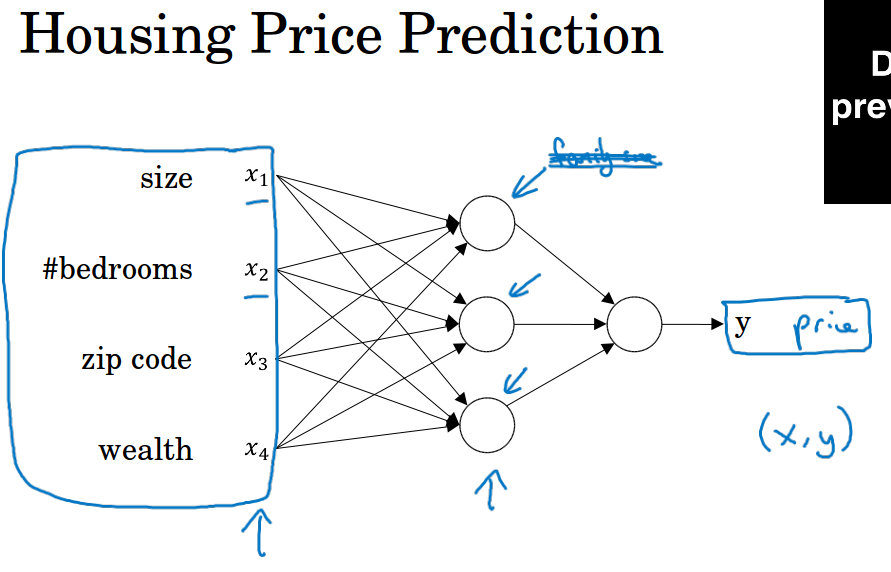
所以你要实现的其实就是输入x,神经网络根据x来预测y。
只要给出足够多的数据x和y,神经网络就能拟合出一个函数来建立x和y之间的映射关系。
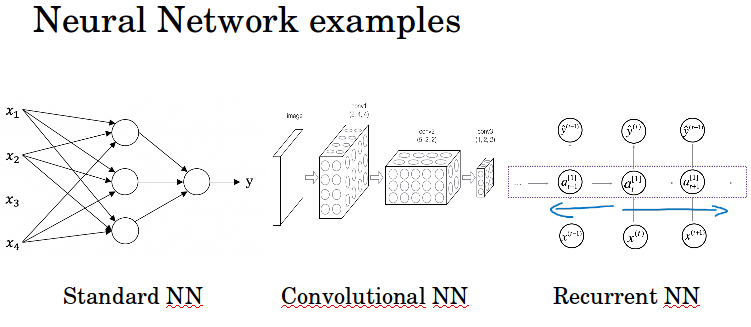
x1, x2, x3, x4就是输入层,这一层有4个神经元,代表4个特征。
中间三个圆圈是隐藏层,每个圆圈叫做隐藏神经元。每个神经元将所有4个特征作为输入,所以这一层在功能上叫做全连接层。
神经网络自己来决定这些网络节点是什么,我们只给出4个特征来完成你想要的任务。
比如隐藏层的第一个圆圈可能代表的是family size,神经网络认为它由x1和x2决定,在训练的时候x3和x4的权重就为0。
2 用神经网络做监督学习( Supervised Learning with Neural Networks )
监督学习是通过大量已有的输入x和输出y训练模型,建立x和y的映射关系,然后模型可以对新的输入x给出一个输出y。
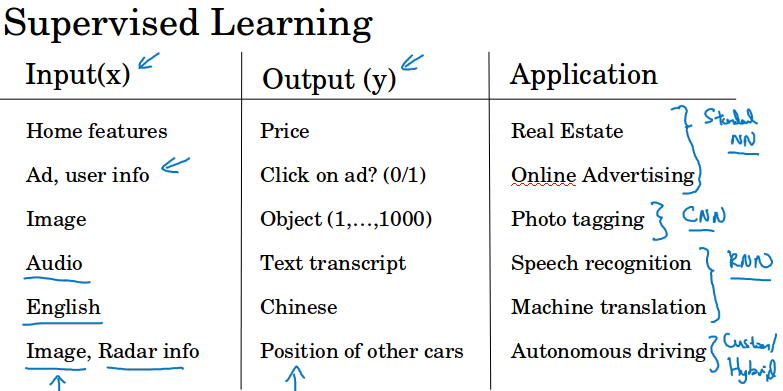
下面是几个监督学习的应用例子,比如房价预测,广告预测,图像分类,语音识别,机器翻译,自动驾驶。
事实证明,结构稍有不同的神经网络在不同的应用领域都非常有用。
比如房价预测和广告预测用标准的NN,图像分类适合用CNN,语音识别和机器翻译(序列数据)适合用RNN。对于自动驾驶一般需要定制的/混合的网络结构。
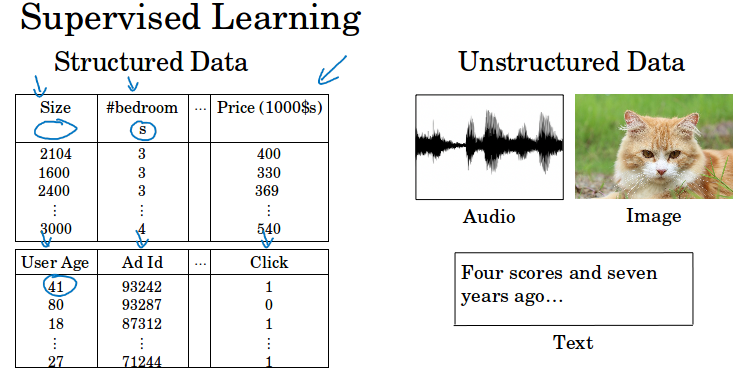
机器学习能够应用于结构化数据和非结构化数据。结构化数据是基于数据库的。非结构化数据是原始音频,图片,文本这些数据,这些数据的训练相对困难许多。
人类能够很直接地理解这些非结构化数据,而近些年来深度学习的发展使神经网络能更好的解释这些数据,做出了很多amazing的应用,比如识别猫。
但神经网络带来的经济效益主要集中在结构化数据上,比如广告推荐,在海量数据库上有更好的数据处理能力。很多公司都基于这些做出更精准的预测。
3 为什么深度学习会兴起( Why is Deep Learning taking off? )
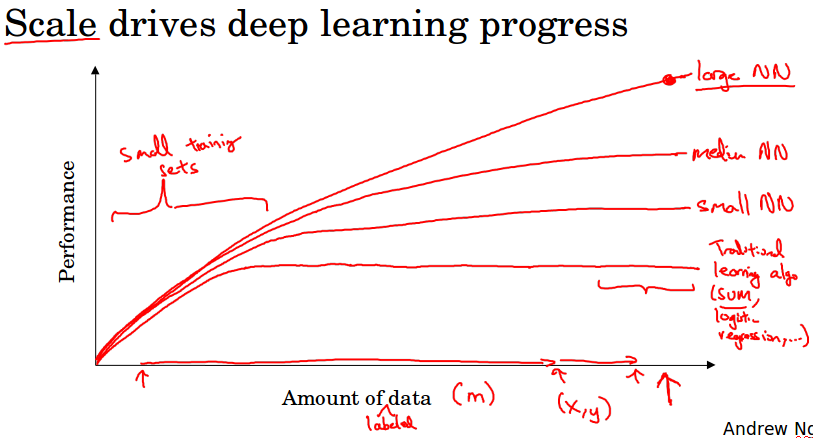
如果用传统的机器学习方法,比如SVM,逻辑回归,训练数据刚开始增加的时候,模型性能的曲线是逐渐上升,到了某个点后就趋于平稳了。(见下图红线)
随着社会的信息化发展和人类活动的增加,我们的数据从小数据变成了大数据。过去20年,我们仅仅是在累积数据,累积传统学习已经无法有效利用的数据。
而对于神经网络,当你数据逐渐增大时,表现会越来越好,见下图的曲线比较。
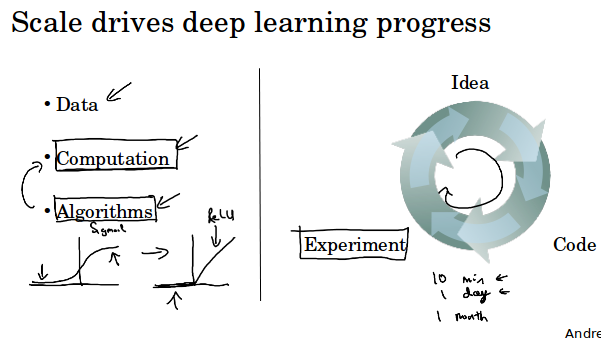
基于这些观察,如果你希望得到非常好的性能,第一需要很大的神经网络,第二需要很多的数据。所以通常说规模(神经网络的规模和数据的规模)推动了深度学习的进步。
但往往有限制,你的数据通常会被用光或者神经网络太大了训练时间难以接受。
m代表训练集样本数量,也就是图中的横轴。在m很小的时候算法的性能差不多,所以如果你数据不多的话,性能的好坏取决于你手动选择特征的技巧。
所以对于图中的左边区域,算法的优劣是很难说清的。性能往往取决于选取特征的技巧以及算法底层细节。
只有当m很大的时候,就是图像右边的区域,神经网络碾压了别的算法。
深度学习的初期,得意于数据的增长和计算规模的增加,我们只需要在CPU/GPU上训练一个非常大的神经网络,就能获得很好的结果。
但是渐渐的,特别是过去几年,我们看到了巨大的算法创新。有趣的是,很多算法创新在试图使神经网络运行的更快。
例如神经网络一个突破就是激活函数从sigmoid函数变成relu函数,因为使用sigmoid函数训练时有可能出现梯度消失,训练变的非常慢。而对于relu正的输入值梯度都为1,梯度很少会逐渐掉到0,训练变快很多。
训练神经网络需要一段时间,idea-code-experiment就是1次迭代。我们往往需要迭代很多次迭代,从想法,到编码,到实验,实验结果让你产生新的想法,修改算法细节,继续实验,不断循环。
如果训练一次需要很长时间的话,你将会花很多时间来进行这个循环。
所以快的运算能够帮助我们,它加快了得到实验结果的速度,这个确实帮助很多深度学习的从业者和研究者更快的改进自己的想法,这一切加快了深度学习社区的研究,使得每个月都有新算法发明。
这个社会在不可思议的发明新算法,并不断探索最前沿的知识。总之一些力量在驱动深度学习发展。所以快是深度学习兴起的一个重要原因( 算法的改进,硬件的提升比如GPU等等)