论文笔记:2018 PRCV 顶会顶刊墙展
Global Gated Mixture of Second-order Pooling for Imporving Deep Convolutional Neural Network(2018 NIPS,大工李培华组)
论文motivation:
(1)现存的池化:一阶GAP(全局均值池化)是很多CNN结构的标配,有研究者提出高阶池化来提高性能
(2)缺点:但是这些池化都有个缺点就是假设了样本服从了单峰分布,限制了CNN的表达能力。
(3)论文的改进:于是论文提出了基于二阶池化的门混合结构来提高CNN对复杂特征和多模态分布的建模。
论文贡献:
(1)提出了门混合结构:在最后一层之前,适应性地从N个分组模型中选择K个模型来生成最后的特征表示。
(2)提出了带参数的二阶池化:在N个分组模型中使用了池化层,为了克服一阶GAP和二阶池化带来的局限性,提出了带参数的二阶池化。
(3)实验:在下采样的ImageNet-1K和Places365两个数据集上跑了实验,以ResNet和WRN为骨架,发现加入本文的模型后能够提高准确率。
架构解释
(1)门混合模型:受hinton在ICLR2017的一篇论文“专家混合模型”启发,提出了如下图所示的结构。对于最后一层之前的输入X,自适应地从N个CM(组件模型)选择K个CM来让X流入,其它分支都关闭,这个K是通过另外的预测层计算得到的。

(2)Balance Loss:单纯的门混合模型学习可能会使得模型每次只训练特定的几个组件,所以为了让所有组件都充分训练,加入了一个Balance Loss,如下所示,让组件权重的变异系数(标准差除以均值)尽可能小,减小组件权重之间的差异。其中S表示min-batch的大小,\(\omega\)表示N个分支的权重(向量)。
(3)二阶池化(SOP):全局均值池化(一阶池化)后得到的特征图为1x1xC,而二阶池化是计算的是特征图之间的协方差,因为有C个特征图计算后得到对称的CxC矩阵。
(4)平方根归一化的二阶池化(SR-SOP):对二阶池化后的结果(也就是上面说的协方差)做矩阵的平方根分解,如下公式(用矩阵分解来计算),其中\(X\in \mathbb{R}^{L \times d}\),1表示全为1的L维向量。这么做的原因是因为在小样本高维特征的场景下,用协方差来估计样本(分布)并不鲁棒,使用平方根后的协方差来估计更加合适。
(5)带参数的二阶池化(Parametric SR-SOP):上面的池化都是假设了样本服从一个高斯分布的场景下计算的。然而样本在现实中往往并不是这样的,于是论文提出了带参数的二阶池化的计算,这种计算基于的假设是样本服从一个多元的高斯分布。如下公式,其中\(Q_j\)是可学习的参数,可以用卷积的方式来实现这种矩阵乘法,这就是为什么上图中的组件中含有1x1的卷积。
个人思考
(1)论文中的门混合模型很直觉,把对于不同样本最后应该选择性地让它经过不同的组件模型,有点类似Inception块里面让样本经过不同的卷积模块从而让网络自己学习对于不同的样本应该用哪些不同的卷积去卷。在论文中可以看到其实是借鉴了hinton的一篇专家混合模型的论文,不管怎么说,这种分成不同组件模型来进行训练的想法还是很不错的。
(2)对于论文中带参数二阶池化的提出,其实之前有看到过涉及二阶池化的论文,把最后一层的全局均值池化换成二阶池化,计算协方差可以建模通道和通道之间的关系,以此来提升模型表现,但是论文中在这个基础上的修改和推进(平方根和带参数)涉及到一些统计和线代上的知识,感觉比较难想到。
(3)对于论文的实验,论文用了下采样的Imagenet(64x64),让人想到的是,如果跑不动那么大的数据集,为了保证能跑,可以对图像做下采样,或者取其中一部分数据来跑,然后比较算法的时候用别人的算法也跑一遍,感觉这么做也是可行的。还有就是做对比实验的时候最好保证两个模型的参数处于一个量级,这样更有说服力。
### Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild(2017 CVPR,北邮模式识别组)
motivation和贡献
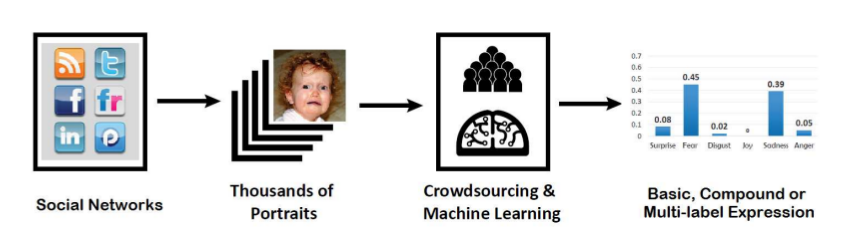
(1)数据集:目前的人脸数据集很多是实验控制得到,缺少in-the-wild的数据集,于是本文提出了一个人脸数据集RAF-DB,收集数据的过程发现人脸表情具有混合属性而不是单一的一种,如下图所示,于是把数据集按两种类型划分成两个数据集,除了6种基本表情还有12种混合表情。
(2)DLP-CNN:因为RAF-DB是in-the-wild的,会具有更强的多样性,所以分类起来会更困难,为了应对这个问题,论文提出了Deep Locality preserving loss,在网络最后加入一个局部保留loss,使得类内样本更加紧凑
![Alt text]
关于数据集:
(1)采集:用关键词和图片共享网站的API爬取数据,获得29672张人脸;
(2)情感标注:雇佣315个标注者(大学里的学生和员工),开发一个网页让他们线上对图像进行标注,选择7类情感中最符合的情感,每张图像会经过40个人的独立标注,标注前对他们进行一小时的情感心理学指导;
(3)额外信息:图像含有精准的位置,人脸区域大小,还有手动标记的5个landmark点(根据这5个landmark计算他们的姿态),同时用Face++ API进行37个landmark点的标注,还手动标注了性别,年龄,种族的基本属性。
(4)可靠性评估:用EM算法对标注者进行可靠性评估,最后留下285名标注者的标注数据,最后根据标注数据按6种基本表情划分一个数据集,按12种混合表情划分成另一个数据集。
(5)数据集分析和效果评估:做了RAF->CK+ 和CK+ -> RAF的两个迁移实验,发现 RAF -> CK+ 表现效果更好,通过分析说明RAF具有更强的多样性,识别更困难。
关于DLP-CNN
(1)Local Proserving Loss:在最后一层加多一个loss(当然要加一个\(\alpha\)超参控制权重),如下式所示(其中x指的是softmax前一层的输出特征),就是计算跟同类中k紧邻点的距离,希望它们能够尽量小,这样就增强了类内样本的紧凑性,也使得类间样本距离更远,如下效果图。
(2)缺点:加了loss的缺点也很明显,每次训练的时候要计算样本之间的两两距离,增加了计算时间。
(3)和center loss的联系:当这个k等于nc-1(nc表示所属类的所有样本数)时这个loss就是center loss(2016 ECCV提出)。

个人思考
(1)数据集:论文很大一部分在解释数据集的构成,解释数据集经过一系列的采集,标注,过滤,分析和评估,有这样一套过程会更有说服力。其中使用了EM算法来进行标注者评估,还给出了公式算法和解释分析,这样可以让人更加可信。
(2)加个loss:加了loss是个常用的创新点,前提是确实有道理,有根据,能够让人信服。这个局部保留loss就很直觉,引入了大家都普遍认同的观点,类间距离最大,类内距离最小,其实就是经典的fisher分类器的思想。
(3)特殊形式的一般化:局部保留loss其实就是center loss的一种特殊形式。局部保留loss把center loss中的nc-1抽象成了一个可变的k,使得模型可以更加灵活,可以看作是将特殊形式一般化。
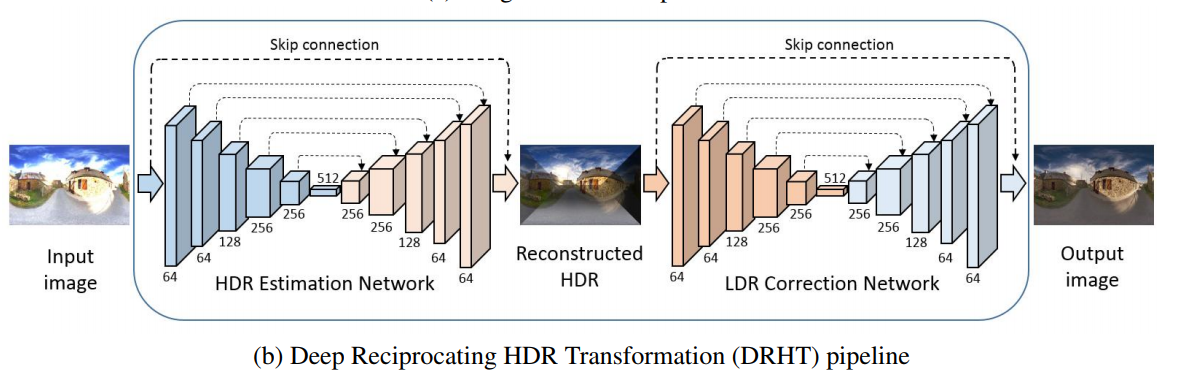
### 其它论文 (1)**Image Correction via Deep Reciprocating HDR Transformation(2018 CVPR,大工,港城大,腾讯AI Lab)** **做了啥(what)**:根据相机成像的过程,提出了往复式HDR的思想,用于恢复过曝光或欠曝光图像在图像恢复过程中易丢失的细节。 **怎么做(how)**:如下图所示,用了2个encoder-decoder(其中使用了类似ResNet的skip-connect),先将输入图像转为HDR(High-Dynamic Range高动态范围图像)以此获得更丰富的细节信息,做一个高动态细节重建。然后再将其经过LDR(Low-Dynamic Range低动态范围图像)纠正来进行恢复,做一个低动态细节校正。 **个人思考**:第一个启发是在encoder-decoder中加入跳连接,组合创新。第二个启发是用encoder-decoder来输入映射到另一个空间来获取更丰富的信息,然后再映射回原来的空间,有点像在encoder-decoder里面内嵌了encoder-decoder,对原结构做一个“自包含”来创新,很有脑洞。
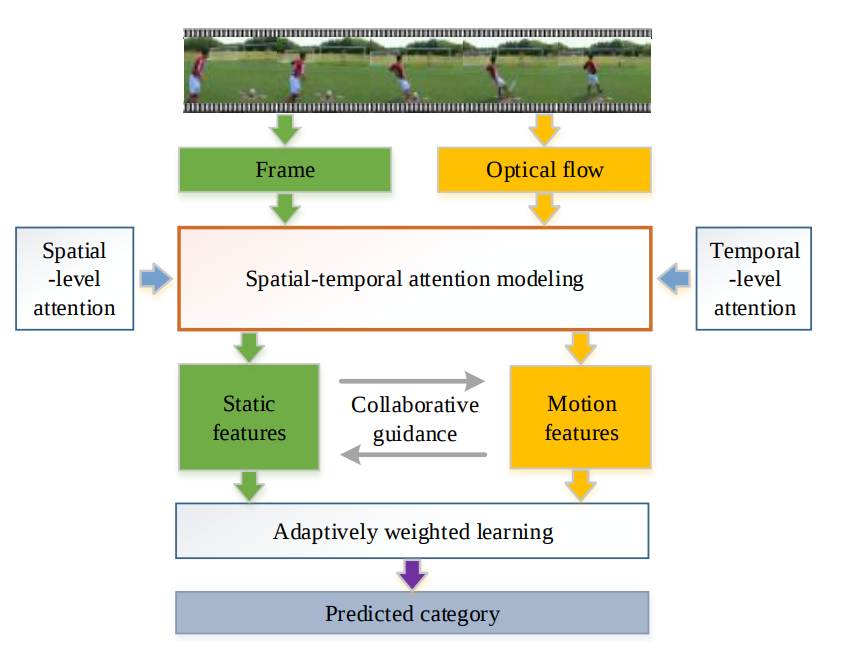
(2)Two-stream Collaborative Learning with Spatial-Temporal Attention for Video Classification(2018 TCSVT,北大多媒体信息处理组)
空间-时间的注意力模型:如图中上半部分所示,输入是视频中的帧信息和光流信息,然后使用时间注意力来获取更具判别信息的时间帧(动态特征)。使用空间注意力来获取显著性区域(静态特征)。
动态-静态的协作模型:如图中下半部分所示,指导静态特征和动态特征进行协作,自适应地学习权重(最后做出预测,进行视频分类)。
个人思考:框架看上去很合理,利用视频的特点(图像空间上的静态性和时间上的动态性)来构建网络,然后相互协作。启发就是要根据实际任务的特点去开脑洞,有理有据,更有道理,更有说服力,本文的模型就是分析了视频的特点提出的。
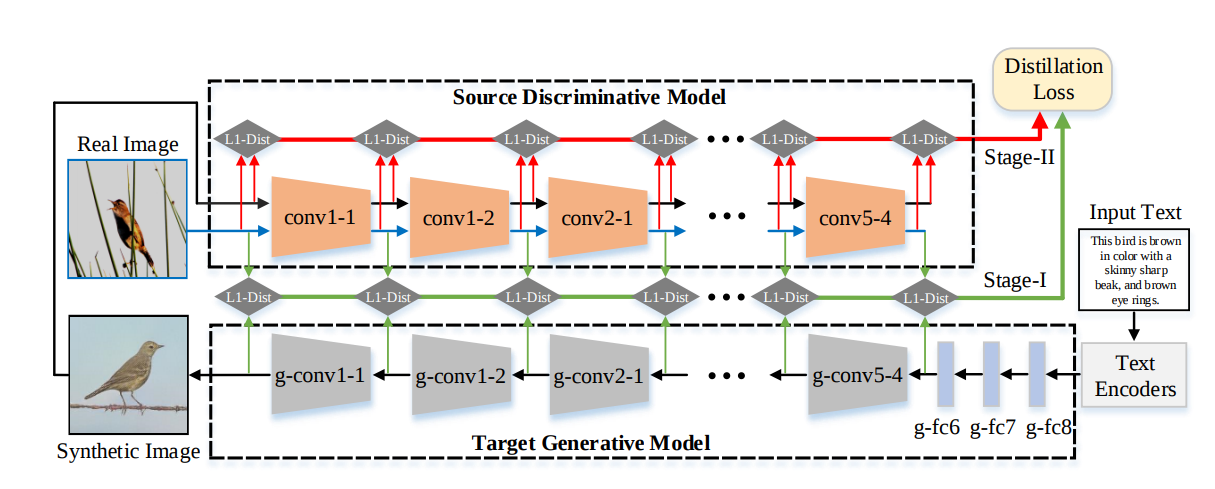
(3)Text-to-image Synthesis via Symmetrical Distillation Networks(2018 ACM MM,北大多媒体信息处理组)
源判别模型:如下图中的上半部分所示,输入真实图像和合成图像,产生多水平的特征,可以作为训练目标模型的指导。
目标生成模型:如下图中的下半部分所示,在文本的条件下生成图像,利用了一个蒸馏loss把源判别模型的多层次信息转移给目标生成模型。
两阶段蒸馏:第一个阶段,目标模型根据源模型给定的信息和文本信息得到的视觉信息,画出一个模糊的图像。第二个阶段,目标模型学到更多合成图像和真实图像之间的细小差异,用更多的细节来合成图像。
个人思考:第一个启发还是要根据实际问题的特点分析,第二个启发就是要分解。本文就是把合成问题分解成两步,第一步是先从真实图像中学习大致特征,第二部是学习真实图像和生成图像的差异。同时模型也分成了两个,一个用来提供需要的信息,一个直接生成。
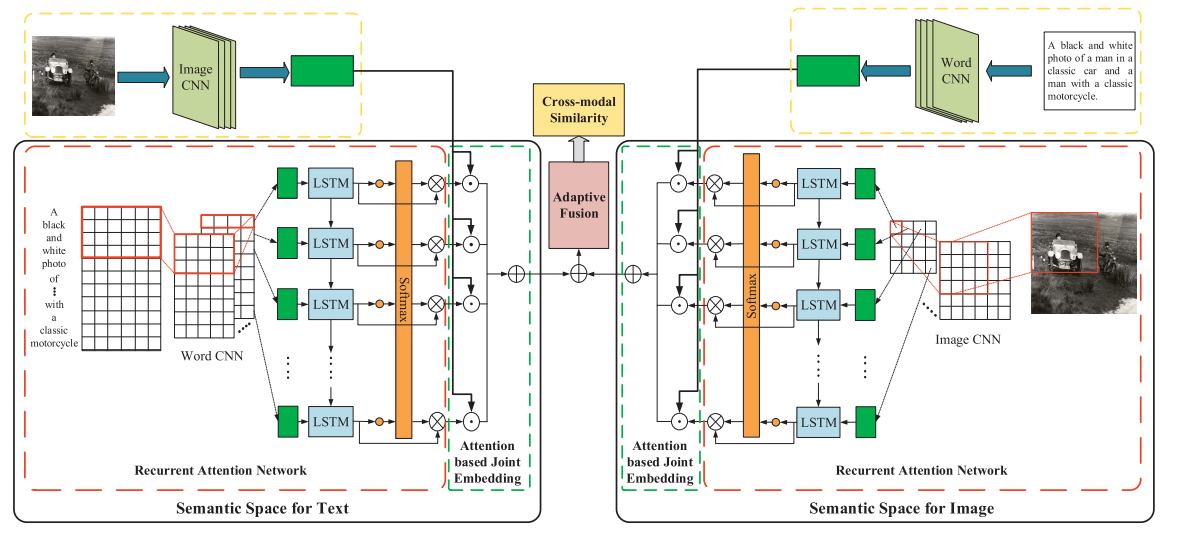
(4)Modality-Specific Cross-Modal Similarity Measurement With Recurrent Attention Network(2018 TIP,北大多媒体信息处理组)
文本的语义空间:如下图中的左半部分所示,输入文本,经过CNN和LSTM后得到文本模态的特征,然后联合图像的CNN特征进行跨模态学习,获得一个联合特征。
图像的语义空间:如下图中的右半部分所示,输入图像,经过CNN和LSTM后得到图像模态的特征,然后联合文本的CNN特征进行跨模态学习,获得一个联合特征。
动态融合:最后把这两个联合特征进行动态融合,得到一个跨模态的相似度。有了这个相似度就可以根据这个相似度来提升跨模态检索的表现。
个人思考:第一个比较大的启发就是对称的设计,左边是文本语义空间结合图像特征,右边是图像语义空间结合文本特征,一个对称的结构通常会带来美感。第二个启发是考虑多模态,复杂现实中很多任务是多模态的,不一定是文本和图像的跨模态的,可以是各种多模态,比如前面那篇门混合结构就是考虑了现实中样本往往不是单模态的高斯分布,而是复杂的多模态分布,所以假设样本服从多元高斯分布,然后提出了带参数的二阶池化。
(5)Learning Multi-view Representation with LSTM for 3D Shape Recognition and Retrieval(2018 TMM,国防科技大)
做了啥:如下图所示,模型输入多个角度的图像给不同CNN,后面接不同的HighWay,LSTM,然后序列投票,全连接层,分类。
个人思考:emm貌似看不出特别新颖的点子,可能是把这个结构用在了3D上的识别,然后实验效果好,论文中的分析写的好。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号