

AI应用开发实战(转)
AI应用开发实战 - 从零开始配置环境
与本篇配套的视频教程请访问:https://www.bilibili.com/video/av24421492/
建议和反馈,请发送到
https://github.com/Microsoft/vs-tools-for-ai/issues
联系我们
OpenmindChina@microsoft.com
零、前提条件
- 一台能联网的电脑,使用win10 64位操作系统
- 请确保鼠标、键盘、显示器都是好的
一、Windows下开发环境搭建
本教材主要参考了如下资源:
官方github教程:https://github.com/microsoft/vs-tools-for-ai
斗鱼tv教程:https://v.douyu.com/show/V6Aw87OBmXZvYGkg
本教程分为五步:
- 安装VS:难度一星
- 安装python:难度一星
- 安装CUDA和cuDNN:这是本教程最
繁琐的一步,这一步直接拉高本教程的平均难度。 - 配置机器学习环境:这是本教程最简单的一步,为了方便用户配置环境,微软提供了一键安装工具!没错,一键安装工具!业界良心阿!
- 安装VS Tools For AI插件:难度一星
note:本教程对各个软件需要使用的版本都做出了明确说明,请安装指定的版本
请放轻松,接下来的傻瓜教程不需要动脑子,你甚至可以打开手机边刷微博边配置环境
0.安装Git
访问 https://git-scm.com/download/win
选择64-bit Git for Windows Setup下载
双击.exe开始安装
选择好自己的安装路径,一路next,直到Adjusting your PATH environment
请选择Use Git from the Windows Command Prompt
这一步就已经将Git添加到环境变量中了,然后就可以直接在命令行里使用Git啦。

然后继续next,直到安装结束
1.安装VS
访问 https://www.visualstudio.com/zh-hans/products/
在产品中点击Visual Studio 2017

选择Community版本下载

打开Visual Studio Installer进行如下的配置:
仅选择.NET桌面开发与Python开发即可
仅选择.NET桌面开发与Python开发即可
仅选择.NET桌面开发与Python开发即可
note:请自行决定Visual Studio的安装路径

等待数分钟,时长视网络状况而定,这个时候你可以去泡一杯茶,或者听一首歌,如果你的网络不是很好,那你可以去看集美剧或者别的什么,等待安装结束。
note:坐 和 放宽
2.安装python
注意!!!如果你已经安装了VS2017带Python开发的环境,就不需要再装一遍python了。打开vs2017, 点击Tools->Python->Python Environments,应该可以看到Python 3.6已经安装,在下面有个folder,大概是“c:\Program Files(x86)\Microsoft Visual Studio\Shared\Python36_64”,把这个字符串copy下来。然后打开Settings->Home->About->System info,在弹出的窗口中选择Advanced system settings->Advanced->Environment Variables->System variables->Path->Edit->New,把刚才的python环境变量字符串paste进来。如果有多个python环境,建议把一些旧的版本卸载先,保证你的机器没有那么多垃圾。
点击OK后,再打开一个command窗口,输入Python,就可以正常使用了。
访问 https://www.python.org/downloads/
选择版本3.5.4或3.6.5 ,Windows x86-64 executable installer下载。

打开安装包,在安装前,请选择Add Python 3.X to PATH,随后按照默认选项安装即可。
点选后,程序将自动将Python加入环境变量,这样避免在安装后手动配置环境变量。
安装结束后,请进行如下操作验证python是否安装成功
1.同时按下 win 与 R,在弹出的输入框里输入cmd
2.在弹出的窗口中输入 python
3.输入exit()退出
4.输入python -m pip install -U pip以更新pip到最新版本note: pip是一个用来管理python包的工具


自此,你已经完成了python的安装,在朝着AI技术大牛的路上又前进了一步!
note:请伸出大拇指给自己一个赞👍
3.安装CUDA与cuDNN
如果你的电脑装有Nvidia的显卡,请进行这一步配置,否则请跳过。
首先通过操作系统更新,升级显卡驱动到最新版。
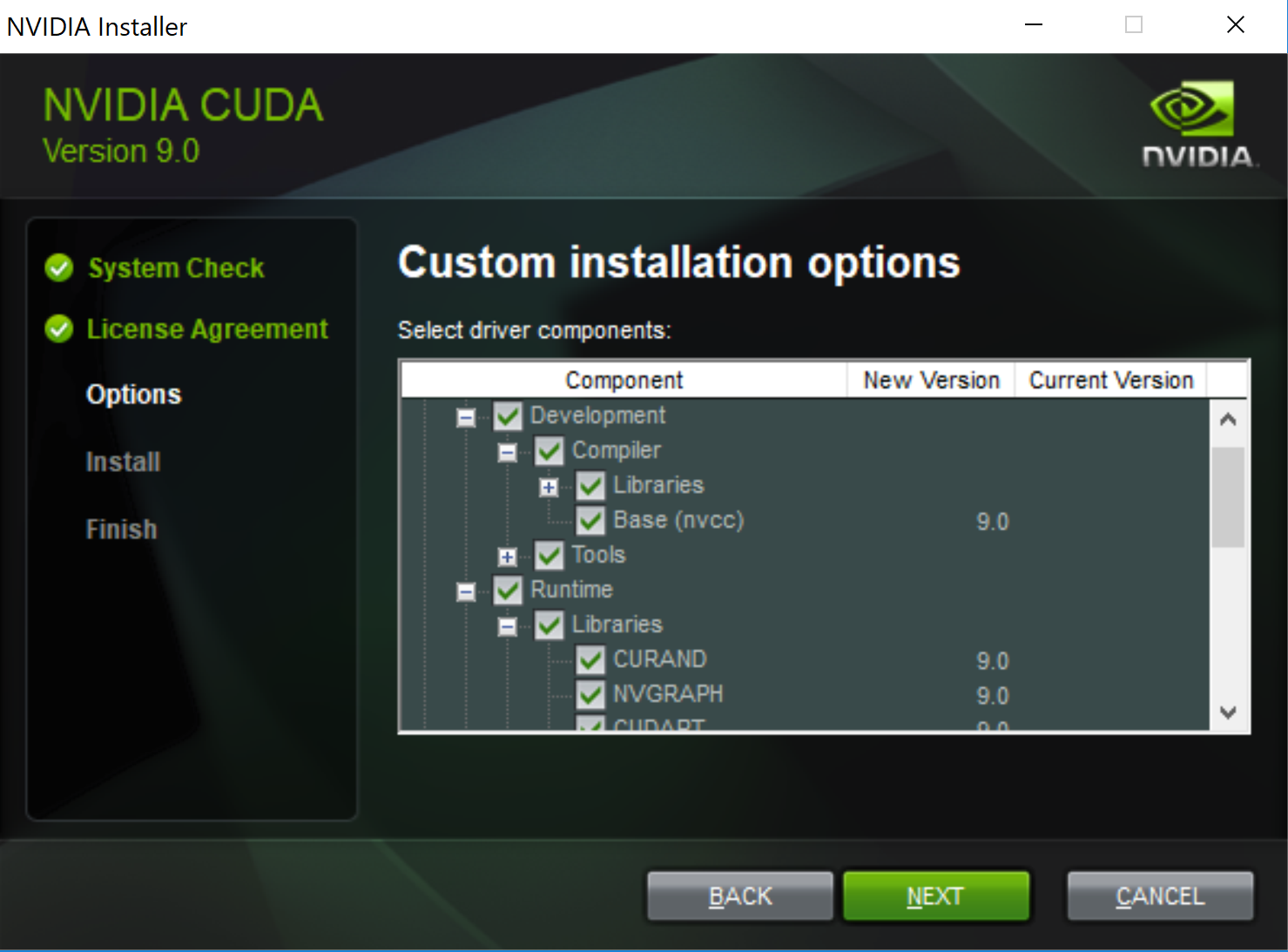
3.1 安装CUDA
打开 https://developer.nvidia.com/cuda-toolkit-archive
选择CUDA 9.0 进行安装。

点击后,选择如下的配置:
note:请选择local版本下载,一旦失败还可以重新再来;如果使用network版本,一旦失败,需要重新下载1.4GB的安装包

打开安装包,进行安装,请自行配置CUDA的安装路径,并手动将CUDA库添加至PATH环境变量中。
note:在Windows中,CUDA的默认安装路径是:
"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin"
3.2 安装cuDNN
note:打起精神!这是操作最复杂的一步!
访问 https://developer.nvidia.com/rdp/cudnn-archive 找到我们需要的cuDNN版本:
cuDNN v7.0.5 (Dec 5, 2017), for CUDA 9.0
cuDNN v7.0.5 Library for Windows 10

点击链接,等待着你的并不是文件下载,而是:

↑这就是本教程里最麻烦的一步:在下载cuDNN之前需要注册Nvidia会员并验证邮箱。不过还好可以微信登录,省掉一些步骤。
一番令人窒息的操作之后,我们终于得到了cuDNN,我们把文件解压,取出这个路径的cudnn64_7.dll,复制到CUDA的bin目录下即可。默认的地址是:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin
note:到这里,我们已经完成了本教程最复杂的一步了
4.安装机器学习的软件及依赖
这一步虽然是整个教程最简单的一步,甚至比把大象关进冰箱更简单。
你只需要:
win + R ,打开cmd,在命令行中输入:
cd c:\ //选择一个你喜欢的路径
md AI //在这里创建一个AI目录
cd AI //打开这个目录
//克隆仓库到本地
git clone https://github.com/Microsoft/samples-for-ai.git
cd samples-for-ai //打开这个目录
cd installer //还有这个目录
python.exe install.py //开始安装然后刷会微博,等待安装结束即可。
成功之后是这样的:

或者你觉得自己不怕麻烦,那么请访问:https://github.com/Microsoft/vs-tools-for-ai/blob/master/docs/zh-hans/docs/prepare-localmachine.md
根据教程按步安装,相信我,你会回来选择一键安装的。
note:就差一步啦!成功就在眼前!
5.安装tools for ai插件
打开Visual Studio,选择工具->扩展和更新->选择“联机”->搜索“AI”
就像这样:

等待下载完成之后,关闭Visual Studio,没错,关闭Visual Studio,系统将自动安装AI插件。
安装完毕后再次打开Visual Studio,你将在界面上看到这样的内容:

那么恭喜你!安装成功!
note:千里之行始于足下,恭喜你成功地完成了环境的搭建,接下来就已经可以使用Visual Studio Tools For AI进行开发了😀
二、离线模型的训练
6.14日更新
GitHub上的samples-for-ai进行了一定的更新,目前MNIST文件夹下只有一个mnist.py文件,
下述步骤中,请使用最新的mnist.py文件
在进行完环境搭建后,我们马上就可以开始训练第一个模型了,我们选择tensorflow下的MNIST作为第一个例子。
MNIST的介绍请参考这个链接 https://www.tensorflow.org/versions/r1.1/get_started/mnist/beginners
首先我们打开这个路径:C:\AI\samples-for-ai\examples\tensorflow,如果你在别的目录下克隆了目录,那么请打开你对应的目录。然后双击TensorflowExamples.sln
就像这样:

note:如果存在多个Python环境,你需要为Visual Studio的AI项目设置默认的Python环境。
例如,手动安装的Python 3.5与Visual Studio 2017 Python开发负载自动安装了64位的Python 3.6
如果要为Visual Studio设置全局的默认Python环境,请打开工具->Python -> Python环境。然后,选择自己需要的Python版本,点击将此作为新项目的默认环境。

然后在解决方案资源管理器中,选择MNIST,单击右键,选择设为启动项目

然后选择MNIST中的mnist.py,单击右键,选择在不调试的情况下启动

然后程序就开始运行了,就像这样:

等待一段时间之后,模型就训练好了!这个时候打开MNIST所在的文件夹,MNIST下是否多了三个文件夹?分别是input和output还有export,这三个文件夹分别存储了训练模型的输入文件、训练时的检查点文件,还有最终导出的模型文件
检查点文件:
模型文件:

可能存在的问题
GPU ran out of memory
方法一:
修改convolutional.py第45行或第47行的BATCH_SIZE或EVAL_BATCH_SIZE为一个更小的数字。具体修改哪一个,需要视你在程序运行的哪个部分得到了ERROR决定。
方法二:
不使用GPU训练,在项目MNIST上单击右键,选择属性(R)

修改环境变量为CUDA_VISIBLE_DEVICES=" "

AI应用开发实战 - 手写识别应用入门
手写体识别的应用已经非常流行了,如输入法,图片中的文字识别等。但对于大多数开发人员来说,如何实现这样的一个应用,还是会感觉无从下手。本文从简单的MNIST训练出来的模型开始,和大家一起入门手写体识别。
在本教程结束后,会得到一个能用的AI应用,也许是你的第一个AI应用。虽然离实际使用还有较大的距离(具体差距在文章后面会分析),但会让你对AI应用有一个初步的认识,有能力逐步搭建出能够实际应用的模型。
建议和反馈,请发送到
https://github.com/Microsoft/vs-tools-for-ai/issues
联系我们
OpenmindChina@microsoft.com
准备工作
- 使用win10 64位操作系统的计算机
- 参考上一篇博客AI应用开发实战 - 从零开始配置环境。在电脑上训练并导出MNIST模型。
一、 思路
通过上一篇文章搭建环境的介绍后,就能得到一个能识别单个手写数字的模型了,并且识别的准确度会在98%,甚至99%以上了。那么我们要怎么使用这个模型来搭建应用呢?
大致的步骤如下:
- 实现简单的界面,将用户用鼠标或者触屏的
输入变成图片。 - 将生成的模型
包装起来,成为有公开数据接口的类。 - 将输入的图片进行
规范化,成为数据接口能够使用的格式。 - 最后通过模型来推理(inference)出图片应该是哪个数字,并显示出来。
是不是很简单?
二、动手
步骤一:获取手写的数字
提问:那我们要怎么获取手写的数字呢?
回答:我们可以写一个简单的WinForm画图程序,让我们可以用鼠标手写数字,然后把图片保存下来。
首先,我们打开Visual Studio,选择文件->新建->项目。

在弹出的窗口里选择Visual C#->Windows窗体应用,项目名称不妨叫做DrawDigit,解决方案名称不妨叫做MnistForm,点击确定。

此时,Visual Studio也自动弹出了一个窗口的设计图。

在DrawDigit项目上点击右键,选择属性,在生成一栏将平台目标从Any CPU改为x64。

否则,DrawDigit(首选32位)与它引用的MnistForm(64位)的编译平台不一致会引发System.BadImageFormatException的异常。
然后我们对这个窗口做一些简单的修改:
首先我们打开VS窗口左侧的工具箱,这个窗口程序需要以下三种组件:
- PictureBox:用来手写数字,并且把数字保存成图片
- Label:用来显示模型的识别结果
- Button:用来清理PictureBox的手写结果
那经过一些简单的选择与拖动还有调整大小,这个窗口现在是这样的:

一些注意事项
- 这些组件都可以通过
右键->查看属性,在属性里修改它们的设置 - 为了方便把PictureBox里的图片转化成Mnist能识别的格式,PictureBox的需要是正方形
- 可以给这些控件起上有意义的名称。
- 可以调整一下label控件大小、字体等,让它更美观。
经过一些简单的调整,这个窗口现在是这样的:

现在来让我们愉快地给这些组件添加事件!
还是在属性窗口,我们选择某个组件,右键->查看属性,点击闪电符号,给组件绑定对应的事件。每次绑定后,会跳到代码部分,生成一个空函数。点回设计视图继续操作即可。
| 组件类型 | 事件 |
|---|---|
| pictureBox1 | 在Mouse下双击MouseDown、MouseUp、MouseMove来生成对应的响应事件函数。 |
| button1 | 如上,在Action下双击Click。 |
| Form1 | 如上,在Behavior下双击Load。 |
然后我们开始补全对应的函数体内容。
注意,如果在上面改变了控件的名称,下面的代码需要做对应的更改。
废话少说上代码!
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Drawing.Drawing2D;//用于优化绘制的结果
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using MnistModel;
namespace DrawDigit
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private Bitmap digitImage;//用来保存手写数字
private Point startPoint;//用于绘制线段,作为线段的初始端点坐标
private Mnist model;//用于识别手写数字
private const int MnistImageSize = 28;//Mnist模型所需的输入图片大小
private void Form1_Load(object sender, EventArgs e)
{
//当窗口加载时,绘制一个白色方框
model = new Mnist();
digitImage = new Bitmap(pictureBox1.Width, pictureBox1.Height);
Graphics g = Graphics.FromImage(digitImage);
g.Clear(Color.White);
pictureBox1.Image = digitImage;
}
private void clean_click(object sender, EventArgs e)
{
//当点击清除时,重新绘制一个白色方框,同时清除label1显示的文本
digitImage = new Bitmap(pictureBox1.Width, pictureBox1.Height);
Graphics g = Graphics.FromImage(digitImage);
g.Clear(Color.White);
pictureBox1.Image = digitImage;
label1.Text = "";
}
private void pictureBox1_MouseDown(object sender, MouseEventArgs e)
{
//当鼠标左键被按下时,设置isPainting为true,并记录下需要绘制的线段的起始坐标
startPoint = (e.Button == MouseButtons.Left) ? e.Location : startPoint;
}
private void pictureBox1_MouseMove(object sender, MouseEventArgs e)
{
//当鼠标在移动,且当前处于绘制状态时,根据鼠标的实时位置与记录的起始坐标绘制线段,同时更新需要绘制的线段的起始坐标
if (e.Button == MouseButtons.Left)
{
Graphics g = Graphics.FromImage(digitImage);
Pen myPen = new Pen(Color.Black, 40);
myPen.StartCap = LineCap.Round;
myPen.EndCap = LineCap.Round;
g.DrawLine(myPen,startPoint, e.Location);
pictureBox1.Image = digitImage;
g.Dispose();
startPoint = e.Location;
}
}
private void pictureBox1_MouseUp(object sender, MouseEventArgs e)
{
//当鼠标左键释放时
//同时开始处理图片进行推理
//暂时不处理这里的代码
}
}
}
步骤二:把模型包装成一个类
将模型包装成一个C#是整个过程中比较麻烦的一步。所幸的是,Tools for AI对此提供了很好的支持。进一步了解,可以看这里。
首先,我们在解决方案MnistForm下点击鼠标右键,选择添加->新建项目,在弹出的窗口里选择AI Tools->Inference->模型推理类库,名称不妨叫做MnistModel,点击确定,于是我们又多了一个项目,

然后自己配置好这个项目的名称、位置,点击确定。
然后弹出一个模型推理类库创建向导,这个时候就需要我们选择自己之前训练好的模型了~

首先在模型路径里选择保存的模型文件的路径。这里我们使用在AI应用开发实战 - 从零开始配置环境博客中训练并导出的模型
note:模型可在
/samples-for-ai/examples/tensorflow/MNIST目录下找到,其中output文件夹保存了检查点文件,export文件夹保存了模型文件。
对于TensorFlow,我们可以选择检查点的.meta文件,或者是保存的模型的.pb文件
这里我们选择在AI应用开发实战 - 从零开始配置环境这篇博客最后生成的export目录下的检查点的SavedModel.pb文件,这时程序将自动配置好配置推理接口,见下图:

类名可以自己定义,因为我们用的是MNIST,那么类名就叫Mnist好了,然后点击确定。
这样,在解决方案资源管理器里,在解决方案MnistForm下,就多了一个MnistModel:

双击Mnist.cs,我们可以看到项目自动把模型进行了封装,生成了一个公开的infer函数。
然后我们在MnistModel上右击,再选择生成,等待一会,这个项目就可以使用了~
步骤三:连接两个部分
这一步差不多就是这么个感觉:
I have an apple , I have a pen. AH~ , Applepen
首先,我们来给DrawDigit添加引用,让它能使用MnistModel。在DrawDigit项目的引用上点击鼠标右键,点击添加引用,在弹出的窗口中选择MnistModel,点击确定。


然后,由于MNIST的模型的输入是一个28×28的白字黑底的灰度图,因此我们首先要对图片进行一些处理。
首先将图片转为28×28的大小。
然后将RGB图片转化为灰阶图,将灰阶标准化到[-0.5,0.5]区间内,转换为黑底白字。
最后将图片用mnist模型要求的格式包装起来,并传送给它进行推理。
于是,我们在pictureBox1_MouseUp中添加上这些代码,并且在文件最初添加上using MnistModel;:
private void pictureBox1_MouseUp(object sender, MouseEventArgs e)
{
//当鼠标左键释放时
//同时开始处理图片进行推理
if (e.Button == MouseButtons.Left)
{
// 复制pictureBox中的图片并缩放到28*28成为新的图片(tmpBmp)
Bitmap tmpBmp = new Bitmap(digitImage, MinstImageSize, MinstImageSize);
//将图片转为灰阶图,并将图片的像素信息保存在list中
var imageData = new List<float>(MnistImageSize * MnistImageSize);
for (var y = 0; y < MnistImageSize; y++)
{
for (var x = 0; x < MnistImageSize; x++)
{
var color = tmpBmp.GetPixel(x, y);
var pixel = (float)(0.5 - (color.R + color.G + color.B) / (3.0 * 255));
imageData.Add(pixel);
}
}
//将图片信息包装为mnist模型规定的输入格式
var batchData = new List<IEnumerable<float>>();
batchData.Add(imageData);
//将图片传送给mnist模型进行推理
var result = model.Infer(batchData);
//将推理结果输出
label1.Text = result.First().First().ToString();
}
}
最后让我们尝试一下运行~
三、效果展示
现在我们就有了一个简单的小程序,可以识别手写的数字了。
赶紧试试效果怎么样~

注意
- 路径中不能有中文字符,否则可能找不到模型。
扩展
尝试识别多个数字
我们已经支持了单个手写数字的识别,那能不能支持多个手写数字的识别呢?同时写下多个数字,正是现实中更为常见的情形。相比之下,如果只能一次识别一个手写数字,应用就会有比较大的局限性。
首先,我们可以尝试在现有的应用里一次写下两个数字,看看识别效果(为了更好的展示效果,将笔画的宽度由40调整为20。这一改动对单个数字的识别并无大的影响):
识别效果不尽人意。
右上角展示的结果准确地反应了模型对我们手写输入的推理结果(即result.First().First().ToString()),然而这一结果并不像我们期望的那样是“42”。
了解MNIST数据集的读者们可能已经意识到了,这是“理所当然”的。归根结底,这一问题的症结在于:作为我们AI应用核心的AI模型,本身并不具备识别多个数字的能力——当前案例中我们使用的AI模型是基于MNIST数据集训练的(训练过程请回顾我们之前的博客AI应用开发实战 - 从零开始配置环境),而MNIST数据集只覆盖了单个的手写数字;并且,我们并未对笔迹图形作额外的处理。
结果是在写下多个数字的情况下,我们实际上在“强行”让AI模型做超出其适应性范围的判断。这属于AI模型的误用。其结果自然难以令人满意。
那么,为了增强应用的可用性,我们能不能改善它、让它能识别多个数字呢?我们很自然地想到,既然MNIST模型已经能很好地识别单个数字,那我们只需要把多个数字分开,一个一个地让MNIST模型进行识别就好了。这样,我们就引入了一个新的子问题,即是“多个手写数字的分割”。
子问题:分割多个手写数字
我们注意到本文介绍的应用有一个特点,那就是最终用作输入的图形,是用户当场写下的,而非通过图片文件导入的静态图片,即我们拥有笔画产生过程中的全部动态信息,比如笔画的先后顺序,笔画的重叠关系等等。考虑到这些信息,我们可以设计一种基本的分割规则:在水平面上的投影相重叠的笔画,我们就认为它们同属于一个数字。
笔画和水平方向上投影的关系示意如下图:
因此书写时,就要求不同的数字之间尽量隔开。当然为了尽可能处理不经意的重叠,我们还可以为重叠部分相对每一笔画的位置设定一个阈值,如至少进入笔画一端的10%以内。
应用这样的规则后,我们就能比较好的把多个手写数字分割开,并能利用Visual Studio Tools for AI提供的批量推理功能,一次性对所有分割出的图形做推理。
多个手写数字识别的最终效果如图:
当然,我们对问题的定义还是非常理想化,分割算法也比较简单。在实际应用中,我们还经常要考虑非二值图形、噪点、非数字的判别等等。并且对手写数字的分割可能比我们设定的规则要复杂,因为在现实场景中,水平方向上的重叠可能会影响图形的涵义。
将两个手写数字分割开这一问题,实际上和经典的图像分割问题非常类似。虽然本文示例中的图像非常简单,但仍然可能具有相当复杂的语义需要处理。为此,我们可能需要引入更多的模型,或者扩展现有的模型来正确判断多个图形之间的关系。
进阶
那么,如果要识别多个连写的数字,或支持字母该怎么做呢?大家多用用也会发现,如果数字写得很小,或者没写到正中,识别起来正确率也会不高。要解决这些问题,做成真正的产品,就不止这一个模型了。比如在多个数字识别中,可能要根据经验来切分图,或者训练另一个模型来检测并分割数字。要支持字母,则需要重新训练一个包含手写字母的模型,并准备更多的字母的数据。要解决字太小的问题,还要检测一下字的大小,做合适的放大等等。
我们可以看到,一个训练出来的模型本身到一个实际的应用之间还有不少的功能要实现。希望我们这一系列的介绍,能够帮助大家将机器学习的概念带入到传统的编程领域中,做出更聪明的产品。
| 此时,界面会提示注册Azure,因为定制化视觉服务实际上是Azure提供的一项云服务,正式使用这项服务需要有Azure订阅。 不过我们现在只是免费试用,所以选择 Continue With trial,如果在根据这篇博客流程做完了一个小应用之后,你觉得确实需要使用这项服务,那么你可以去注册Azure账号,获取Azure订阅。 |
三、创建定制化视觉服务项目
点击New Project,填写项目信息。
这里不妨以一个熊的分类模型作为例子来实践吧。
填写好Name和Description,这里Name不妨填写为BearClassification。
随后选择Classification和General(compact),点击Create
| 截图 | 操作 |
|---|---|
 |
在Project Type一栏,定制化视觉服务提供了识别和分类两种服务,另外提供了多种识别场景,其中末尾带有(compact),也即压缩字样的三种。压缩模型,顾名思义,模型占用的空间更少,运行更快,甚至可以放到手机这种移动设备里。 当然,会有一个小问题就是精确度会受影响。导出模型后,模型文件的使用是没有任何限制的,而其余的几种场景只能通过调用API来进行预测,由于当前属于免费试用,因此这种方式有10000次调用上限。 |
 |
由于分类服务需要准备用来训练的数据集,请自行准备几种不同的熊的照片,将同种的熊放在以这种熊的名字命名的文件夹里,最后再将这些文件夹放在一个data文件夹中。然后点击Add images |
 |
选择一种熊的全部照片,然后创建对应的标签,点击Up load xxx files |
 |
在添加了所有的数据集和标签之后,点击网页上方的Train,开始训练模型。 |
 |
一小会之后,点击网页上方的performance,就可以看到这次训练的结果了。这里简单解释一下Precision和Recall,这是两个评估模型好坏的主要指标。 简单来说,两个数都是越大越好。在这个项目中,以Brown Bear为例: Precision就是识别出来的结果的准确率,即在所有被识别为棕熊的图片中真正有棕熊的图片所占的比例;而Recall则是测试结果中正确识别为棕熊的图片占测试集中所有棕熊图片的比例。 |
 |
这时再点击界面右上角的齿轮,可以看到免费用户每个项目能够使用的服务额度: 一共可以上传5000张图片,创建50个不同标签,保存10次迭代的结果。 这十次迭代有什么用呢?当需要增删标签、给标签添加或删除训练图片时,这次再训练,就会花费掉一次迭代。 这些都是当前项目的总数而不是累计值。对于一般的免费用户,这基本上就相当于你可以随意使用这项服务了,如果有大量的训练数据,那么建议您还是订阅Azure云服务,Azure秉持着使用多少,收费多少的原则,即使收费,也仍然良心。 |
 |
然后选择刚刚训练好的这次迭代,点击Export。视觉认知服务一共提供了适用于四种平台的模型导出,对三大操作系统都能支持。 选择ONNX,这个格式由微软、脸书、亚马逊等大厂鼎力支持,点击 Export,等待服务器把模型导出,然后点击Download,即可下载模型。最后得到了一个.onnx文件,然后就可以使用它来构建应用了。 |
如果需要上传大量的图片数据,那么点击鼠标的方式肯定不够方便,微软同时提供了代码的支持,详见官方文档:
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/home
四、使用Windows ML构建应用
这次不写Winform程序,而是搭建一个识别熊的UWP的AI应用,通过这个应用来教大家如何使用Windows ML导入模型。
这部分的代码已经完成了,请使用git克隆samples-for-ai到本地,UWP项目的代码在/samples-for-ai/projects/BearClassificationUWPDemo中。
在运行代码之前,请先安装开发UWP所需的工作负载,流程如下:
- 打开Visual Studio Installer
- 在工作负载中勾选Universal Windows Platform development
- 在单个组件一栏中下拉到最下方,确认Windows 10 SDK(10.0.17134.0)已被勾选上,这是使用Windows ML开发的核心组件


另外,请将您的操作系统更新到1803版本,否则本程序将不能安装。
如果您将进行类似的开发,请将UWP项目设置成最低运行目标版本为17134,否则对于版本低于17134的用户,在运行时会出现:
"Requested Windows Runtime type 'Windows.AI.MachineLearning.Preview.LearningModelPreview' is not registered."
详见:https://github.com/MicrosoftDocs/windows-uwp/issues/575
安装需要的时间比较长,可以先看看UWP的视频教程,做一做头脑预热: https://www.bilibili.com/video/av7997007
Visual Studio 和 Windows 更新完毕后,我们打开CustomVisionApp.sln,运行这个程序。
你可以从必应上查找一些熊的图片,复制图片的URL,粘贴到输入框内,然后点击识别按钮;或者,点击浏览按钮,选择一张本地图片,点击确定,你就可以看到识别结果了:


现在来看看这个程序是怎么实现的。
我们来梳理一下这个应用的逻辑,这个应用的逻辑与上一篇博客中的手写数字识别大体上是一样的:
- 导入模型
- 按下按钮后,通过某种方式获取要用来识别的图片
- 将图片交给模型识别
- 将图片与识别结果展示在界面上
1. 文件结构:
文件结构见下图:

- Assets文件夹存放了这个项目的资产文件,比如程序图标等等,在本示例程序中,.onnx文件也存放在其中。
- Strings文件夹存放了用于本地化与全球化资源文件,这样可以支持不同的语言。
- ViewModel文件夹中则存放了本项目的关键代码,整个程序运行的逻辑都在ResultViewModel.cs中
- BearClassification.cs则是系统自动生成的模型包装文件
- MainPage.xaml是程序的UI布局文件
2. 核心代码一:BearClassification.cs
这部分的代码是自动生成的,教程详见链接:https://docs.microsoft.com/zh-cn/windows/uwp/machine-learning/
- 将.onnx文件添加到UWP项目的Assets文件夹中,随后将自动生成一个对应的包装
.cs文件,在本例中为BearClassification.cs。 - 由于目前存在的一些BUG,生成的类名会有乱码,需要将乱码替换为别的字符串。
- 修改
BearClassification.onnx的属性->生成操作,将其改为内容,确保在生成时,能够调用到这个模型。
生成的文件共有三个类:
- BearClassificationModelInput:定义了该模型的输入格式是VideoFrame
- BearClassificationModelOutput:定义了该模型的输出为一个list和一个dict,list存储了所有标签按照probability降序排列,dict则存储了标签与概率的键值对
- BearClassificationModel:定义了该模型的初始化函数与推理函数
// 模型的输入格式为VideoFrame
public sealed class BearClassificationModelInput
{
public VideoFrame data { get; set; }
}
// 模型的输出格式,其中包含了一个列表:classLabel和一个字典:loss
// 列表中包含每种熊的标签,按照概率降序排列
// 字典中则包含了每种熊的标签和其概率,按照用户在创建模型时的添加顺序排列
public sealed class BearClassificationModelOutput
{
public IList<string> classLabel { get; set; }
public IDictionary<string, float> loss { get; set; }
public BearClassificationModelOutput()
{
this.classLabel = new List<string>();
this.loss = new Dictionary<string, float>(){...}
}
}
// 模型的包装类,提供了两个函数
// CreateBearClassificationModel:从.onnx文件中创建模型
// EvaluateAsync:对输入对象进行评估,并返回结果
public sealed class BearClassificationModel
{
private LearningModelPreview learningModel;
public static async Task<BearClassificationModel> CreateBearClassificationModel(StorageFile file)
{
...
}
public async Task<BearClassificationModelOutput> EvaluateAsync(BearClassificationModelInput input)
{
...
}
}3. 核心代码二:ResultViewModel.cs
通过之前的运行可以发现:每次识别图片,UI中的内容需要进行频繁地更新,为了简化更新控件内容的代码逻辑,这个程序使用UWP开发中常用的MVVM(model-view-viewmodel)这一组合模式开发,使用“绑定”的方式,将UI控件与数据绑定起来,让数据与界面自动地同步更新,简化了代码逻辑,保证了ResultViewModel职责单一。
| 绑定源(ResultViewMode.cs) | 绑定目标(MainPage.xaml) |
|---|---|
| string BearUrl | TextBox InputUriBox |
| ObservableCollection Results | ListView ResultArea |
| BitmapImage BearImage | Image DisplayArea |
| string Description | TextBox DescribeArea |
| ICommand RecognizeCommand | Button RecognizeButton |
| ICommand BrowseCommand | Button BrowseButton |
绑定好之后,程序还需要一系列逻辑才能运行,这里就包括:
导入与初始化模型:
在程序一开始,需要调用LoadModel进行模型初始化工作。
private async void LoadModel()
{
//导入模型文件,实例化模型对象
StorageFile modelFile = await StorageFile.GetFileFromApplicationUriAsync(new Uri("ms-appx:///Assets/BearClassification.onnx"));
model = await BearClassificationModel.CreateBearClassificationModel(modelFile);
}图片推理:
本程序提供了两种方式访问图片资源:
- 通过URL访问网络图片
- 通过文件选取器访问本地图片
private async void EvaluateNetPicAsync()
{
try
{
...
//BearClassification要求的输入格式为VideoFrame
//程序需要以stream的形式从URL中读取数据,生成VideoFrame
var response = await new HttpClient().GetAsync(BearUrl);
var stream = await response.Content.ReadAsStreamAsync();
BitmapDecoder decoder = await BitmapDecoder.CreateAsync(stream.AsRandomAccessStream());
VideoFrame imageFrame = VideoFrame.CreateWithSoftwareBitmap(await decoder.GetSoftwareBitmapAsync());
//将videoframe交给函数进行识别
EvaluateAsync(imageFrame);
}
catch (Exception ex){ ... }
}
private async void EvaluateLocalPicAsync()
{
try
{
...
// 从文件选取器中获得文件
StorageFile file = await openPicker.PickSingleFileAsync();
var stream = await file.OpenReadAsync();
...
// 生成videoframe
BitmapDecoder decoder = await BitmapDecoder.CreateAsync(stream);
VideoFrame imageFrame = VideoFrame.CreateWithSoftwareBitmap(await decoder.GetSoftwareBitmapAsync());
// 将videoframe交给函数进行识别
EvaluateAsync(imageFrame);
}
catch (Exception ex){ ... }
}
private async void EvaluateAsync(VideoFrame imageFrame)
{
//将VideoFrame包装进BearClassificationModelInput中,交给模型识别
//模型的输出格式为BearClassificationModelOutput
//其中包含一个列表,存储了每种熊的标签名称,按照probability降序排列
//和一个字典,存储了每种熊的标签,和对应的probability
//这里取出输出中的字典,并对其进行降序排列
var result = await model.EvaluateAsync(new BearClassificationModelInput() { data = imageFrame });
var resultDescend = result.loss.OrderByDescending(p => p.Value).ToDictionary(p => p.Key, o => o.Value).ToList();
//根据结果生成图片描述
Description = DescribResult(resultDescend.First().Key, resultDescend.First().Value);
Results.Clear();
foreach (KeyValuePair<string, float> kvp in resultDescend)
{
Results.Add(resourceLoader.GetString(kvp.Key) + " : " + kvp.Value.ToString("0.000"));
}
}
五、使用其他方法构建应用
同样,用之前使用Visual Studio Tools for AI提供的推理类库生成器也能够构建相似的应用。想看视频教程的请移步:
【教程】普通程序员一小时入门AI应用——看图识熊(不含公式,包会)
该教程讲解了如何使用模型浏览工具Netron
想看图文教程请继续往下看:
1. 界面设计
创建Windows窗体应用(.NET Framework)项目,这里给项目起名ClassifyBear。
注意,项目路径不要包含中文。
在解决方案资源管理器中找到Form1.cs,双击,打开界面设计器。从工具箱中向Form中依次拖入控件并调整,最终效果如下图所示:

左侧从上下到依次是:
- Label控件,将内容改为“输入要识别的图片地址:”
- TextBox控件,可以将控件拉长一些,方便输入URL
- Button控件,将内容改为“识别”
- Lable控件,将label的内容清空,用来显示识别后的结果。因为label也没有边框,所以在界面看不出来。可以将此控件的字体调大一些,能更清楚的显示推理结果。
右侧的控件是一个PictureBox,用来预览输入的图片,同时,我们也从这个控件中取出对应的图片数据,传给我们的模型推理类库去推理。建议将控件属性的SizeMode更改为StretchImage,并将控件长和宽设置为同样的值,保持一个正方形的形状,这样可以方便我们直观的了解模型的输入,因为在前面查看模型信息的时候也看到了,该模型的输入图片应是正方形。
2. 查看模型信息
在将模型集成到应用之前,我们先来看一看模型的基本信息,比如模型需要什么样的输入和输出。打开Visual Studio中的AI工具菜单,选择模型工具下的查看模型,会启动Netron模型查看工具。该工具默认不随Tools for AI扩展一起安装,第一次使用时可以按照提示去下载并安装。
Netron打开后,点击Open model选择打开之前下载的BearModel.onnx文件。然后点击左上角的汉堡菜单显示模型的输入输出。

上图中可以看到该模型需要的输入data是一个float数组,数组中要求依次放置227*227图片的所有蓝色分量、绿色分量和红色分量,后面程序中调用时要对输入图片做相应的处理。
上图中还可以看到输出有两个值,第一个值loss包含所有分类的得分,第二个值classLabel是确定的分类的标签,这里只需用到第二个输出即可。
3. 封装模型推理类库
由于目前模型推理用到的库只支持x64,所以这里需要将解决方案平台设置为x64。打开解决方案资源管理器,在解决方案上点右键,选择配置管理器。

在配置管理器对话框中,点开活动解决方案平台下拉框,选择新建

在新建解决方案平台对话框中,输入新平台名x64,点击确定即可

下面添加模型推理类库,再次打开解决方案资源管理器,在解决方案上点右键,选择添加,然后选择新建项目。
添加新项目对话框中,将左侧目录树切换到AI Tools下的Inference,右侧选择模型推理类库,下方填入项目名称,这里用Model作为名称。

确定以后会出现检查环境的进度条,耐心等待一会就可以出现模型推理类库创建向导对话框。
点击模型路径后面的浏览按钮,选择前面下载的BearModel.onnx模型文件。
注意,这里会出现几处错误提示,我们需要手动修复一下。首先会看到“发现不支持的张量的数据类型”提示,可以直接点确定。

确定后如果弹出“正在创建项目…”的进度条,一直不消失,这里只需要在类名后面的输入框内点一下,切换下焦点即可。

然后,我们来手动配置一下模型的相关信息。类名输入框中填入模型推理类的名字,这里用Bear。然后点击推理接口右侧的添加按钮,在弹出的编辑接口对话框中,随便起个方法名,这里用Infer。输入节点的变量名和张量名填入data,输出节点的变量名和张量名填入classLabel,字母拼写要和之前查看模型时看到的拼写一模一样。然后一路确定,再耐心等待一会,就可以在解决方案资源管理器看到新建的模型推理类库了。

还有一处错误需要手动修复一下,切换到解决方案资源管理器,在Model项目的Bear目录下找到Bear.cs双击打开,将函数Infer的最后一行
return r0;替换为
List<List<string>> results = new List<List<string>>();
results.Add(r0);
return results;至此,模型推理类库封装完成。相信Tools for AI将来的版本中会修复这些问题,直接选择模型文件创建模型推理类库就可以了。
4. 使用模型推理类库
首先添加对模型推理类库的引用,切换到解决方案资源管理器,在ClassifyBear项目的引用上点右键,选择添加引用。

在弹出的引用管理器对话框中,选择项目、解决方案,右侧可以看到刚刚创建的模型推理类库,勾选该项目,点击确定即可。

在Form1.cs上点右键,选择查看代码,打开Form1.cs的代码编辑窗口。
添加两个成员变量
// 使用Netron查看模型,得到模型的输入应为227*227大小的图片
private const int imageSize = 227;
// 模型推理类
private Model.Bear model;回到Form1的设计界面,双击Form的标题栏,会自动跳转到代码页面并添加了Form1_Load方法,在其中初始化模型推理对象
private void Form1_Load(object sender, EventArgs e)
{
// 初始化模型推理对象
model = new Model.Bear();
}回到Form1的设计界面,双击识别按钮,会自动跳转到代码页面并添加了button1_Click方法,在其中添加以下代码:
首先,每次点击识别按钮时都先将界面上显示的上一次的结果清除
// 识别之前先重置界面显示的内容
label1.Text = string.Empty;
pictureBox1.Image = null;
pictureBox1.Refresh();然后,让图片控件加载图片
bool isSuccess = false;
try
{
pictureBox1.Load(textBox1.Text);
isSuccess = true;
}
catch (Exception ex)
{
MessageBox.Show($"读取图片时出现错误:{ex.Message}");
throw;
}如果加载成功,将图片数据传给模型推理类库来推理。
if (isSuccess)
{
// 图片加载成功后,从图片控件中取出227*227的位图对象
Bitmap bitmap = new Bitmap(pictureBox1.Image, imageSize, imageSize);
float[] imageArray = new float[imageSize * imageSize * 3];
// 按照先行后列的方式依次取出图片的每个像素值
for (int y = 0; y < imageSize; y++)
{
for (int x = 0; x < imageSize; x++)
{
var color = bitmap.GetPixel(x, y);
// 使用Netron查看模型的输入发现
// 需要依次放置227 *227的蓝色分量、227*227的绿色分量、227*227的红色分量
imageArray[y * imageSize + x] = color.B;
imageArray[y * imageSize + x + 1* imageSize * imageSize] = color.G;
imageArray[y * imageSize + x + 2* imageSize * imageSize] = color.R;
}
}
// 模型推理类库支持一次推理多张图片,这里只使用一张图片
var inputImages = new List<float[]>();
inputImages.Add(imageArray);
// 推理结果的第一个First()是取第一张图片的结果
// 之前定义的输出只有classLabel,所以第二个First()就是分类的名字
label1.Text = model.Infer(inputImages).First().First();
}注意,这里的数据转换一定要按照前面查看的模型的信息来转换,图片大小需要长宽都是227像素,并且要依次放置所有的蓝色分量、所有的绿色分量、所有的红色分量,如果顺序不正确,不能达到最佳的推理结果。
5. 测试
编译运行,然后在网上找一张熊的图片,把地址填到输入框内,然后点击识别按钮,就可以看到识别的结果了。注意,这个URL应该是图片的URL,而不是包含该图片的网页的URL。

六、下一步?
本篇博客我们学会了使用定制化视觉服务与在UWP应用中集成定制化视觉服务模型。这里我提两个课后习题:(想不到吧)
-
当训练含有多个标签、大量图片数据时,如何做到一键上传图片并训练?
-
如何通过调用REST接口的方式完成对图片的推理?
提示:请看看定制化视觉服务给我们提供的API,这一题肯定是要写代码做的
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/home
加油!
七、内容预告
接下来我们将会陆续推出:
- 微软认知服务使用教程
- 模型训练及推理的通常流程及原理
- 模型转换工具的使用
- 开放AI平台-大规模计算资源调度系统
请在下方留言,告知我们您最想阅读哪个教程,我们将优先考虑。
如果您有别的想要了解的内容,也可以在评论区留言。
AI应用开发基础傻瓜书系列的目录~
写在前面,为啥要出这个系列的教程呢?
总的说来,我们现在有了很多非常厉害的深度学习框架,比如tensorflow,pytorch,paddlepaddle,caffe2等等等等。然而,我们用这些框架在搭建我们自己的深度学习模型的时候,到底做了一些什么样的操作呢?我们试图去阅读框架的源码来理解框架到底帮助我们做了些什么,但是……很难!很难!很难!因为深度学习是需要加速啦,分布式计算啦,所以框架做了很多很多的优化,也让像我们这样的小白难以理解这些框架的源码。所以,为了帮助大家更进一步的了解神经网络模型的具体内容,我们整理了这样一个系列的教程。
对于这份教程的内容,如果没有额外的说明,我们通常使用如下表格的命名约定
| 符号 | 含义 |
|---|---|
| X | 输入样本 |
| Y | 输入样本的标签 |
| Z | 各层运算的结果 |
| A | 激活函数结果 |
| 大写字母 | 矩阵或矢量,如A,W,B |
| 小写字母 | 变量,标量,如a,w,b |
适用范围
没有各种基础想学习却无从下手哀声叹气的玩家,请按时跟踪最新博客,推导数学公式,跑通代码,并及时提出问题,以求最高疗效;
深度学习小白,有直观的人工智能的认识,强烈的学习欲望和需求,请在博客的基础上配合代码食用,效果更佳;
调参师,训练过模型,调过参数,想了解框架内各层运算过程,给玄学的调参之路添加一点心理保障;
超级高手,提出您宝贵的意见,给广大初学者指出一条明路!
前期准备
环境:
windows(Linux也行),python(最好用3),anaconda(或者自己装numpy之类的),tensorflow(嫌麻烦地请看这里《AI应用开发实战 - 从零开始配置环境》,tools for AI(按照链接教程走的就不用管这个了)。
自己:
清醒的头脑(困了的同学请自觉泡茶),纸和笔(如果像跟着推公式的话),闹钟(防止久坐按时起来转转),厚厚的衣服(有暖气的同学请忽略)
目录
- 1-神经网络的基本工作原理
- 2-神经网络中反向传播与梯度下降的基本概念
- 3-基本数学导数公式
- 4-激活函数
- 5-损失函数
- 6-单入单出的单层神经网络能做什么
- 7-单入单出的双层神经网络能做什么
- 徒手搭建神经网络
- 徒手搭建CNN网络
- 徒手搭建RNN网络
- 模型内部


{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2015-11-28 Net开发的部分知名网站案例