MADRL - COMA, VDAC
多智能体强化学习算法 - COMA, VDAC (Algorithm & Code)
1. COMA算法
1.1. COMA算法原理
COMA算法构建了AC算法的“值分解”类似的架构。
COMA算法的核心特点包括:
- 使用一个集中式的critic网络,在训练的过程中可以获取所有智能体的信息;
- 采用 counterfactual baseline (CB,反事实基线)来解决信用分配的问题(类似于值分解);
- Critic网络要能够对CB进行高效计算。
在任务协作的多智能体系统中,奖励函数是全局共享的(所有智能体共享奖励信号),因此只需要设置一个critic网络。这导致所有的智能体优化目标完全一致。对每个actor网络而言,从critic网络反向传播过来的误差是相同的。这种“吃大锅饭”式的训练方式显然是低效的,因为每个actor网络对整体性能的贡献是不一样,贡献大的反向传播的误差应该要稍微小些,贡献小的其反向传播误差应该要大一些。这同时造成了“懒惰智能体”的现象:一些智能体因为对整体贡献不大,出现消极训练。
回顾一下,在基于值分解的方法中,各个智能体的贡献通过对Q值进行分解,并反馈到到各个智能体来衡量的。在COMA中,研究对象是AC算法。作者的思路是利用critic网络输出的Q值,Q值分解利用CB。
具体来说,作者受到了差分奖励 (difference rewards) 思想的启发。智能体 \(a\) 执行动作 \(u^a\) 的贡献,是通过它在同等条件下执行一个设定的的默认动作 \(u'^a\) 来衡量的。这里的同等条件是指相同状态且其他智能体依然保持动作不变。
EXAMPLE: \(Q(s, \{\mathbf{u^{-a}}, u^a\}\) 表示智能体 \(a\) 执行动作 \(u^a\) 后获得的Q值,其中 \(\mathbf{u^{-a}}\) 表示其余智能体的动作集合;\(Q(s, \{\mathbf{u^{-a}}, u'^a\}\) 表示智能体 \(a\) 执行默认动作 \(u'^a\) 后获得的奖励。这两个奖励值的差值,\(Q(s, \{\mathbf{u^{-a}}, u^a\} - Q(s, \{\mathbf{u^{-a}}, u'^a\}\) 定义为智能体 \(a\) 执行动作 \(u^a\) 后对整体Q值的贡献。此处的 \(Q(s, \{\mathbf{u^{-a}}, u'^a\}\) 就是CB。这个差值越大,说明智能体 \(a\) 的贡献越大。
问题的关键是,默认动作并不好确定。
作者的解决方案是直接利用actor网络的输出来确定这个默认动作。具体来说,critic网络的输入包括\(s\) 和 \(\mathbf{u}^{-a}\),输出是 \(Q(s, (\mathbf{u}^{-a}, u'^a))|_{u'^a \in \mathcal{A}_a}\)。COMA的做法是以智能体 \(a\) 的Q值期望来代替 CB。贡献度 \(A^a(s, \mathbf{u})\) 形式化的表述是:
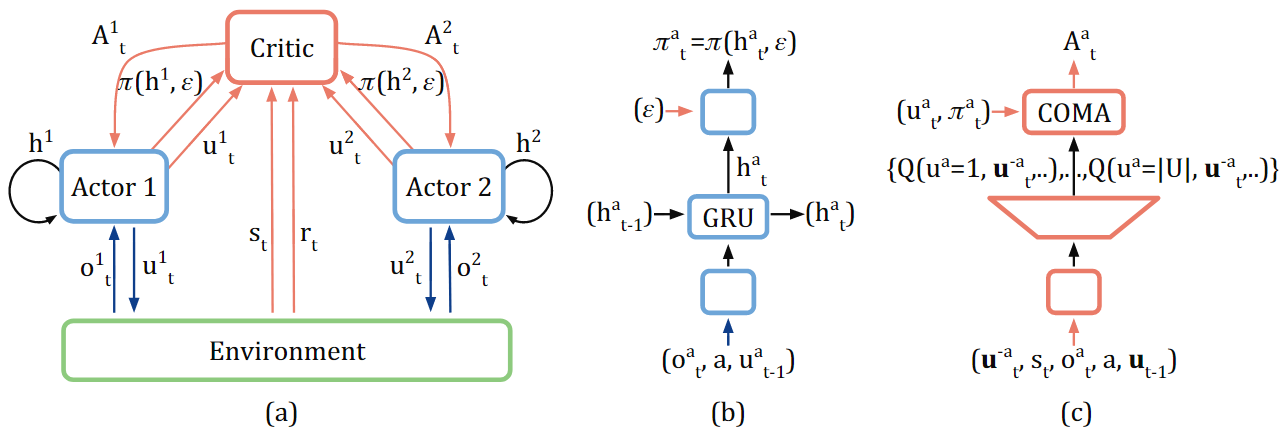
图1. COMA算法的结构
我们结合图1(c),再来体会一下公式(1)。图1(c)给出了COMA算法中critic网络的设计细节。
它的输入是:
- \(s_t\),当前全局状态;
- \(o^a_t\),智能体 \(a\) 的局部观测;
- \(a\),当前智能体的编号(文中假设智能体同质,所有智能体共享critic和actor网络参数,在critic引入一个区分位来区分不同的智能体);
- \(\mathbf{u}_{t-1}\),所有智能体在 \(t-1\) 时刻的动作集合;
- \(\mathbf{u}^{-a}_t\),除了智能体 \(a\) 之外,所有智能体在 \(t\) 时刻的动作集合;
输出是,\(Q(u^a=1, \mathbf{u}^{-a}_t, \cdots), \cdots\),表示智能体 \(a\) 在 \(t\) 时刻的各个工作的 Q 值。它们就是公式 (1) 中的 \(Q(s, (\mathbf{u}^{-a}, u'^a))\)。
REMARK:
- \(Q(s, \mathbf{u})\) 如何得到?
- 为何critic网络同时输入了 \(s_t\) 和 \(o^a_t\)?\(s_t\) 是全局状态,\(o^a_t\) 是智能体 \(a\) 对于全局状态从自身视角出发的局部观测。这两个信息在很多环境下并不相同,都是需要的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号