
HTTP 快速重传机制 SACK系列算法
原始的快速重传机制
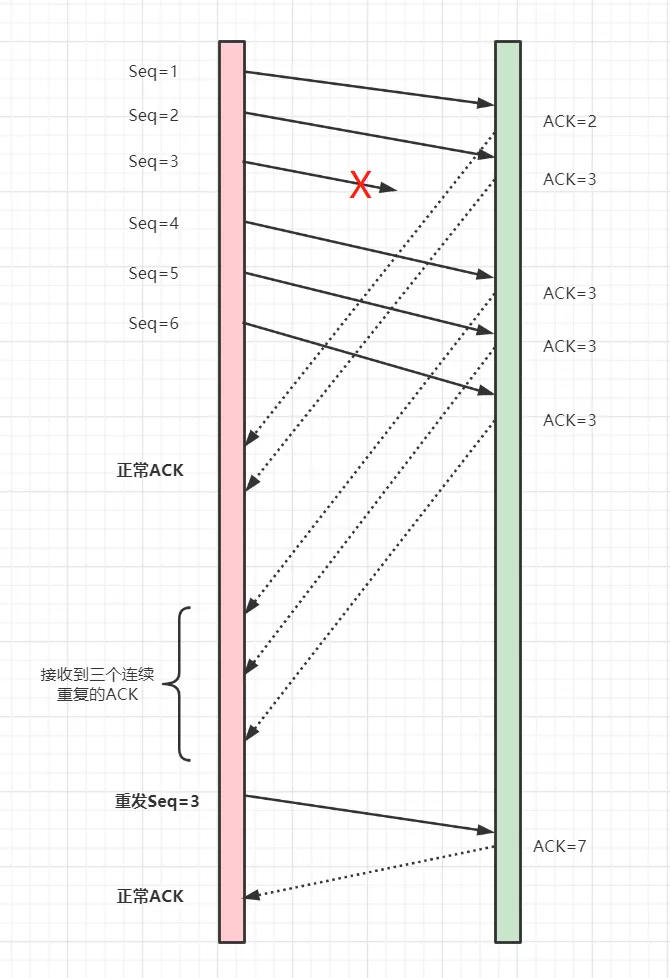
如图所示, 客户端与服务器交互数据之前 首先已经将数据分区然后依次上传了( 这大概是因为数据包大小的问题吧!以后我有了解了 再补充 )
假设客户端有一个数据A要发送给服务器 要经历以下步骤 (除开握手环节 这个请看我的TCP握手流程 随笔 )
1. 将数据A 标记为 N块 (这里假设为5块) 【 seq , seq , seq , seq , seq 】
2. 分好了组之后 按在循序在内部带上 序号发给服务
3. 首先发送seq1 服务器成功接收返回ack2
4 发送seq2也成功 服务器返回ack3 (意味着等着你的3号位呢)
5 发送seq3失败了 但是seq4成功了 服务器还是会返回一次ack3 (虽然我收到了,但是你得3呢!~~)
6 发送seq5成功了 但是还是返回ack3 (虽然我收到5了,但是你得3呢!~~)
7 发送seq6成功了 但是还是返回ack3 (虽然我收到6了,但是你得3呢!~~)
8 客户端:连续收到了3次提示没有收到3 看来3真的丢包了,再发一次把 (于是客户端有发了一次seq3 )
9 服务器: 你总算给我把3交出来了,我看看现在有最大到多少序号了 哦 是6呀 给你发个ack7找你要7 你要是没有了就算了
缺点: 很明显,如果出现多个连续丢包情况 无法识别 假如3丢失了 4也丢失了 但是 服务器只会返回ack3 一旦客户端补充了3 但是 成功了5,6的话 就会导致返回ack7 中间的4就彻底丢失了 再就是客户端会连续收到3次的提示没有3才会再次重发(因为有可能3的请求被4超车了也有可能的),导致如果这次丢失情况靠末尾最后可能会因为没有返回彻底丢包 (这是我的理解,有错误望指出)
SACK 带确认的重传机制
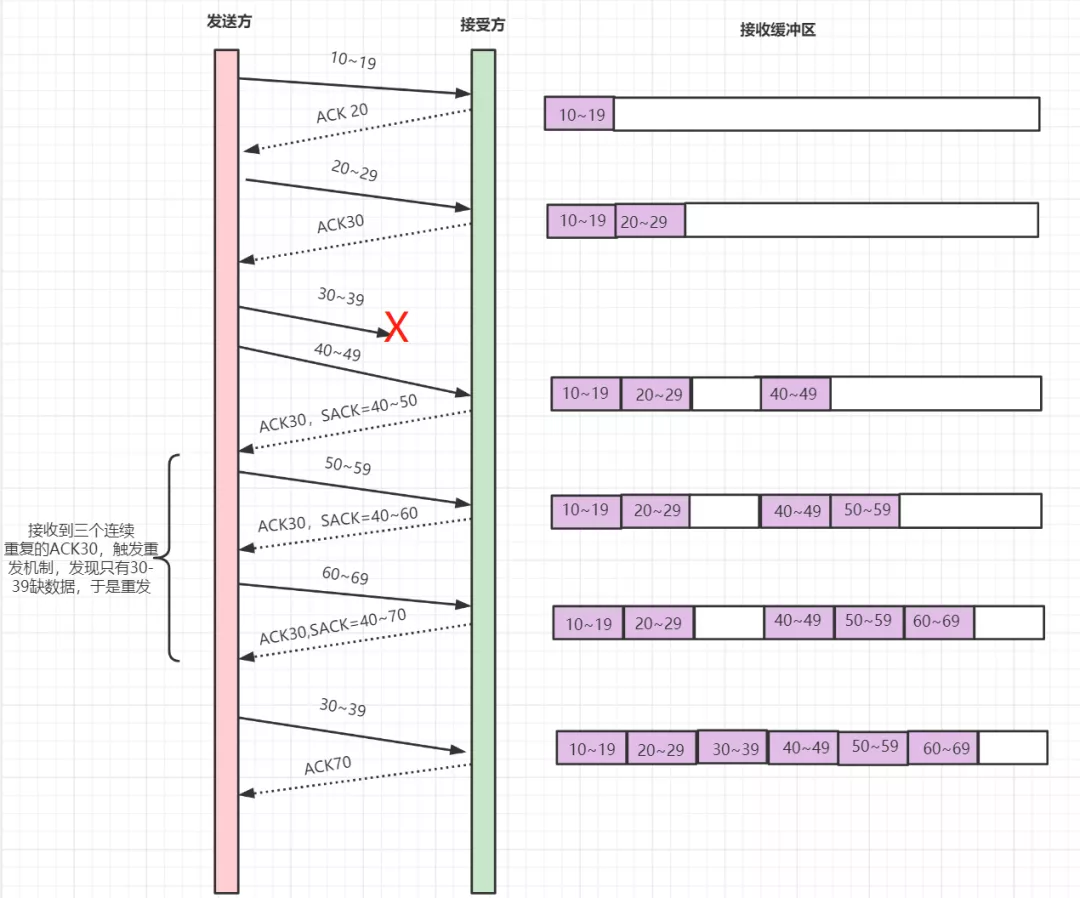
这个机制和原始机制才用的交互形式还是一样的 只是传递的参数发生了变化 一旦发生了丢包行为 就会在下一次成功中返回一个SACK数据,这个数据表明了除开ackX 丢包的位置以外成功的位置范围例如上图的 ACK30,SACK=40~50 就说嘛丢失的为30号 但是后面成功的序号为40~50, 哪怕后面的继续成功 ack30也不会变但是sack的成功范围会增加变为40~60;
优点:记录了成功的数据请求可以让客户端知道具体差了那
缺点:还是无法处理重复传值情况,(如果说服务器收到数据给与返回信息的时候信息丢失了,客户端无法就会因为没有收到回复,进入超时重传流程,数据会多次发送,为了解决这个情况 于是就出现了 D-SACK机制)
D-SACK 机制
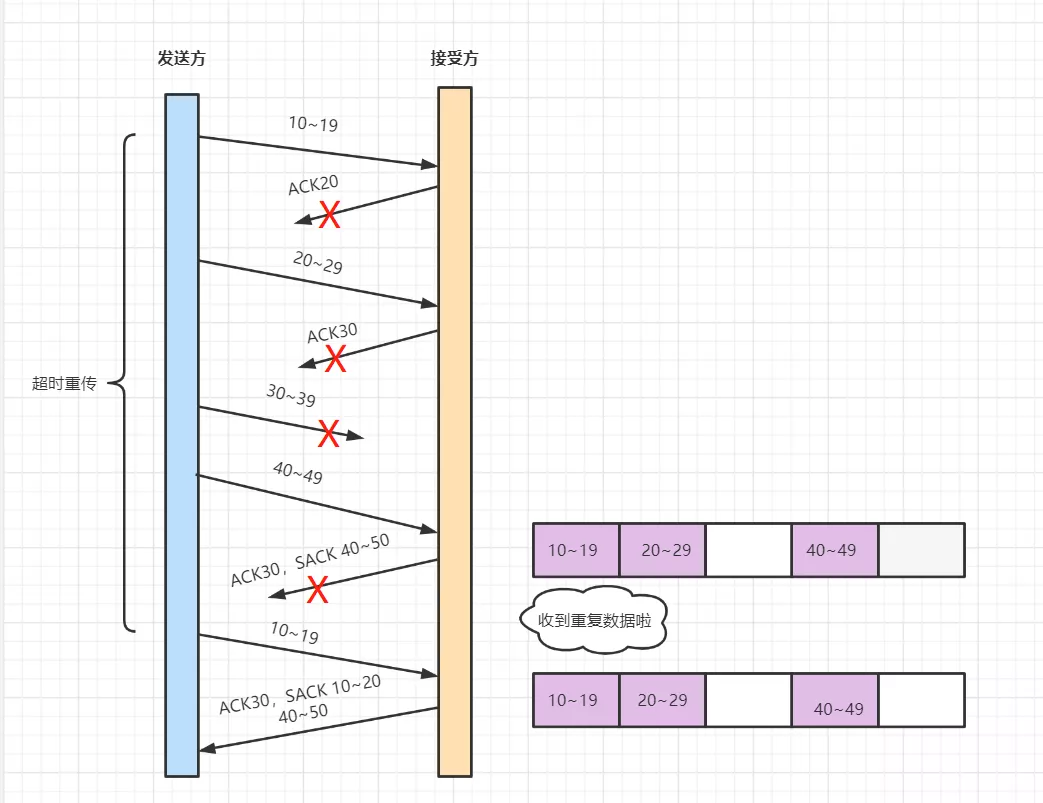
D-SACK机制实际上只是收到重复数据之后会返回一个除开当前缺少的序列 ack30之后的范围 40~50 还会在前面加上 30之前已经有的范围 SACK 10~20 40~50 (只是少了30 ~ 39) 其余的都有了 你别传了
额 应该算是讲的很清楚了吧!~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号