


神经网络学习笔记-入门篇*
1简单模型 vs 复杂模型
对于一个崭新的机器学习的任务,在模型选取和特征向量获取上通常我们会有两种选择方式:a. 简单模型 + 复杂特征项;b. 复杂模型 + 简单特征项。这两种方式各有各的优缺点:
1.1 简单模型
对于简单模型来说,其优点是容易理解、可解释性较强,但是为了达到相对好的预测效果,我们通常会考虑对原始特征进一步抽象,增加大量的特征项来弥补model在处理非线性问题上的缺陷:
假设我们现在有一个学习任务,首先我们抽取出100个不相关的特征属性 ,然后我们想要尝试使用逻辑回归(LR)模型,我们都知道LR是一种广义的线性模型,为了提高LR对非线性问题的处理能力,我们要引入多项式特征,为了充分考虑特征关联,通常我们也会执行特征之间交叉组合。若我们仅考虑2次项,也就是只考虑特征两两组合( ,这样我们也会得到接近5000
,然后我们想要尝试使用逻辑回归(LR)模型,我们都知道LR是一种广义的线性模型,为了提高LR对非线性问题的处理能力,我们要引入多项式特征,为了充分考虑特征关联,通常我们也会执行特征之间交叉组合。若我们仅考虑2次项,也就是只考虑特征两两组合( ,这样我们也会得到接近5000 个组合特征,若再考虑3次项,4此项呢?结果可想而知…!而随着初始特征n的增大,特征空间也会急剧膨胀。项数过多可能会带来的问题:模型容易过拟合、在处理这些项时计算量过大。
个组合特征,若再考虑3次项,4此项呢?结果可想而知…!而随着初始特征n的增大,特征空间也会急剧膨胀。项数过多可能会带来的问题:模型容易过拟合、在处理这些项时计算量过大。
1.2 复杂模型
对于神经网络这种复杂的模型,其缺点就是相对难理解、可解释性不强;优点是这种模型一般不需要像LR那样在特征获取上下这么大的功夫,它可以通过隐层神经元对特征不断抽象,从而自动发觉特征关联,进而使得模型达到良好的表型。下文,我们着重讨论一下,这一处处充满神秘的模型。
2初识神经网络(前馈)
神经网络模型是参考生物神经网络处理问题的模式而建立的一种复杂网络结构。在神经网络中,神经元又称激活单元,每个激活单元都会采纳大量的特征作为输入,然后根据自身特点提供一个输出,供下层神经元使用。logistic神经元的图示如下:
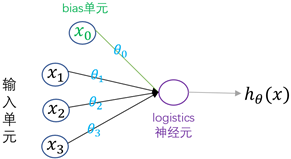
其中, 表示偏置项,它通常作为模型(单元)的固有属性而被添加到模型中,一般取值为1;
表示偏置项,它通常作为模型(单元)的固有属性而被添加到模型中,一般取值为1; 是模型参数,又称为权重,起到放大或缩小输入信息的作用;而logistics神经元会将输入信息进行汇总并添加一个非线性变换,从而获得神经元输出。神经网络就是由多个这样的logistics神经元按照不同层次组织起来的网络,每一层的输出都作为下一层的输入,如下图:
是模型参数,又称为权重,起到放大或缩小输入信息的作用;而logistics神经元会将输入信息进行汇总并添加一个非线性变换,从而获得神经元输出。神经网络就是由多个这样的logistics神经元按照不同层次组织起来的网络,每一层的输出都作为下一层的输入,如下图:
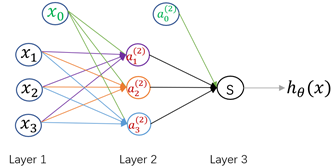
这是一个包含一个隐层的神经网络结构。其中,Layer1为输入层,Layer2为隐层,Layer3为输出层。
2.1模型表示
下面我们用数学符号来描述上述的神经网络模型。首先我们进行符号约定,如下:

故:
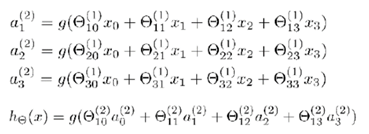
使用向量化的方式,可以表示成:

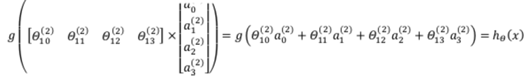
这也是前馈神经网络从输入变量获得输出结果的数学表示。
2.2模型理解
为了更加清晰的认识神经网络,我们可以将上图中的Layer1遮住,那么剩下的Layer2和Layer3就像是一个LR模型,其与真正LR的不同在于输入向量的差异:普通LR的输入向量是原始特征向量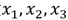 ,而该模型的输入是
,而该模型的输入是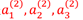 (经过学习后得到的特征属性)。
(经过学习后得到的特征属性)。
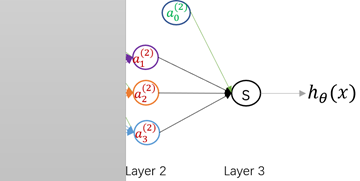
因此,对神经网络更直观的理解就是,它通过大量的隐层网络将输入向量进行一步步抽象(加权求和+非线性变换),生成能够更加容易解释模型的复杂新特征,最后将这些强大的新特征传入输出层获得预测结果。就像,单层神经元(无隐层)无法表示逻辑同或运算,但是若加上一个隐层结构就可以轻松表示出逻辑同或运算!
上面所说是二分类问题的假设模型,其实神经网络模型也非常擅长处理多分类任务。与二分类不同的时,多分类模型最后的输出层将是一个K维的向量,K表示类别数。

3 神经网络的学习
有了上面的描述我想大家对前馈神经网络应该已经有了一个全面的认识,那么接下来进入本文讨论的重点内容-神经网络的学习过程。神经网络的学习同其他模型的学习,首先我们要确定其损失函数,然后对参数进行估计,最后确定模型用于预测。本文针对分类问题中的神经网络模型的学习过程进行讨论。
3.1 代价函数
在分类问题,我们知道使用交叉熵误差函数而不是平方和误差函数,会使得训练速度更快,同时也提升了泛化能力。对于二元分类问题来说,神经网络可以使用单一的logistics神经元作为输出,同时也可以使用两个softmax神经元作为输出。对于多分类问题,同样有两方面的思考:
- 对于类别之间有交集的多分类问题,我们可以将多分类看成多个相互独立的二元分类问题,这时我们使用logistics输出神经元,而误差函数采用交叉熵误差函数
- 对于类别之间互斥的多分类问题,通常使用softmax输出神经元,误差函数同样采用交叉熵误差函数
下面我们将会介绍更加具有一般性的多分类的神经网络的损失函数。首先假设神经网络的输出单元有K个,而网络的第k个神经元的输出我们用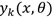 表示,同时其目标用
表示,同时其目标用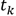 表示,基于两种不同的考量角度,损失函数被给出:
表示,基于两种不同的考量角度,损失函数被给出:
3.1.1 类别之间有交集的多分类问题
对于此类问题,我们可以将多分类看成多个相互独立的二元分类问题,每个输出神经元都有两种取值(t=0,1),并且输出神经元之间相互独立,故给定输入向量时,目标向量的条件概率分布为:
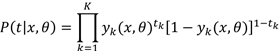
取似然函数的负对数,可以得到下面的误差函数:
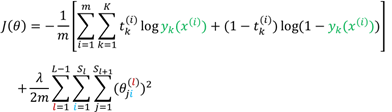
3.1.2 类别之间互斥的多分类问题
对于该问题,我们通常用"1-of-K"的表示方式来表示类别,从而网络的输出可以表示为: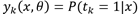 ,因此误差函数为:
,因此误差函数为:
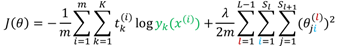
而网络输出的计算通常使用Softmax函数:
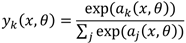
这里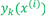 表示第i个样本第k个输出单元的输出值,是一个概率值。对于正则化项,我们依然采用l2正则项,将所有参数(不包含bias项的参数)的平方和相加,也就是不把i=0时的参数加进入
表示第i个样本第k个输出单元的输出值,是一个概率值。对于正则化项,我们依然采用l2正则项,将所有参数(不包含bias项的参数)的平方和相加,也就是不把i=0时的参数加进入
3.2 反向传播算法
绝大部分的训练算法都会涉及到用迭代的方式最小化误差函数和一系列的权值更新操作。具体来说,一般的训练算法可以分为两个阶段:
- 第一阶段:求解误差函数关于权值(参数)的导数。(bp)
- 第二阶段:用得到的导数进一步计算权值的调整量。(梯度下降等优化算法)
反向传播(bp)算法主要应用第一阶段,它能非常高效的计算这些导数。
3.2.1 误差函数导数的计算
接下来我们将会学习到bp算法是如何计算误差函数导数的。
首先为了使得推导过程更加直观,我们将会使用一个简单的层次网络结构说明(这个层次网络有两层sigmoid隐层神经元、误差函数使用均方误差函数)。网络结构如图:
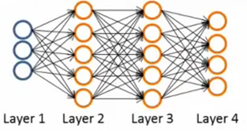
像前面提到的我们做如下符号约定:

首先考虑一个简单的线性模型,其中输出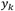 是输入变量
是输入变量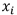 的线性组合:
的线性组合:
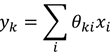 (1)
(1)
给定一个特定的输入模式n(x, t),则其误差函数为:
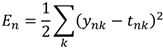 (2)
(2)
则这个误差函数关于参数的梯度为:
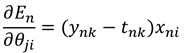 (3)
(3)
此时误差函数的梯度可以表示为与链接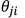 的输出端相关联"误差信号"和与链接输入端相关联的变量
的输出端相关联"误差信号"和与链接输入端相关联的变量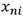 的乘积。(交叉熵误差函数也有类似的结果!)
的乘积。(交叉熵误差函数也有类似的结果!)
接下来计算神经网络中误差函数关于参数的梯度。首先,因为误差函数中只有加权求和项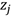 与参数
与参数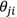 ,故可以通过链式求导法则得到:
,故可以通过链式求导法则得到:
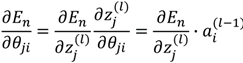 (4)
(4)
同上面线性函数的表示方式,我们通常引入新的符号:
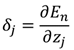 (5)
(5)
用其来表示与链接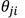 的输出端相关联"误差信号",此时误差函数关于参数的梯度可以写成:
的输出端相关联"误差信号",此时误差函数关于参数的梯度可以写成:
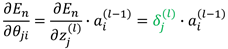 (6)
(6)
这个式子告诉我们:要求的导数 = 权值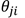 输出端单元的误差项
输出端单元的误差项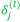 * 权值
* 权值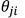 输入端单元的激活值
输入端单元的激活值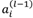 。因为每个结点的激活值在前馈阶段已经得出,因此,为了计算导数,我们只需要计算网络中每个隐层结点和输出结点的"误差信息"即可,然后应用(6)式得到导数值!
。因为每个结点的激活值在前馈阶段已经得出,因此,为了计算导数,我们只需要计算网络中每个隐层结点和输出结点的"误差信息"即可,然后应用(6)式得到导数值!
接下来带来了一个问题,每个隐层结点和输出结点的"误差信息"怎么计算?对于输出结点来说,第k个结点的误差等于该结点的输出值与目标值之间的差:
输出结点(线性激活函数)误差 : 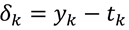 (7)
(7)
为了计算隐层结点的误差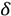 值,我们再次使用链式法则:
值,我们再次使用链式法则:
隐层结点的误差
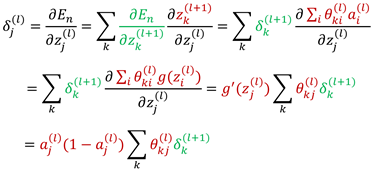 (8)
(8)
可见,l层第j个结点的误差取决于当前结点的激活值、l+1层结点的误差、以及l+1层结点于当前结点的链接权值。这种从输出到输入推导误差的方式叫做误差的反向传播。
公式说明: (8)式中的求和项是对所有与j单元有权值链接的上层单元进行求和。(8)式遵循了一个事实,l层第j个结点通过第l+1层所有与其关联的结点间接对误差函数产生影响!(以下是PRML中的图,可以帮助理解)

3.2.2 反向传播算法描述
首先,通过正向传播,找到所有隐层神经元和输出单元的激活;
使用(7)式得到所有输出单元的误差;
然后,利用误差的反向传播公式(8),获得网络中所有隐层神经元的误差;
最后,使用公式(6)计算得到误差函数相对于所有权值的导数。
注意:上述得到的导数只是对于单个样本而言的,因为开始时我们设定了训练样本只有一个(x,t),若使用多个训练样本,可以通过加和的形式求的导数:
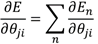
而有了梯度,我们接下来就可以使用梯度下降(SGD)更新权值参数了。
3.3 实用技巧
通过上面的讲述我们应该明白了神经网络中权值参数是如何更新的。下面我们将介绍一些在应用的实用技巧:
3.3.1 梯度检验
当我们对神经网络使用梯度下降时,使用bp计算的导数通常不知道是否正确,进而不能保证最终的结果是否将会是最优解。为了解决这个问题,通常对一些测试样例执行梯度检验操作,确保对于检验的样例通过数值计算的导数与通过bp得到的导数有着相近的结果(最多可以差几位小数),导数的数值计算如下:
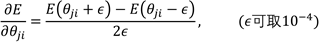
注意:若反向传播计算导数的开销为O(W),那么数值方法计算导数的时间复杂度为O(W^2)。故我们可以看出,数值方法计算导数时间复杂度比bp算法要高的多,所以当我们已经确认了反向传播算法正确执行时,在执行优化算法之前必须关掉梯度验证过程,否则训练过程将会非常缓慢!
3.3.2 随机初始化
首先要明确像LR那样将所有权值参数都初始化为0的操作在神经网络中是行不通的!若在神经网路中将所有权值都置为0或其它相同的值,这样我们第二层神经元所有激活单元都会有相同的值,这代表了计算神经元的高度冗余,这将导致神经网路功能的单一!从而训练不出有效解决问题的神经网络模型。为了避免这种问题的出现,通常采用随机初始化的思想,将所有的参数都初始化为 之间的值。
之间的值。
3.4 对神经网络的几点思考
神经网络和感知器的区别:神经网络的隐层神经元使用的是连续的Sigmoid非线性函数,而感知器使用阶梯函数这一非线性函数。这意味着神经网络函数对网络参数来说是可微的,这一性质在神经网络训练过程中起这重要的作用。
隐藏层的激活函数不可以取线性函数的原因:如果所有隐藏层神经元的激活函数都取线性函数的话,那么我们将总能找到一个没有隐藏层的网络与之等价。这是因为,多个线性变换的组合,也是一个线性变换(多个线性变换的组合可以用一个线性变换代替)。此时,如果隐藏层神经元的数量少于输入或输出神经元的数量,那么这个网络所产生的变换就不是一般意义上的从输入到输出的线性变换,这是因为隐含单元出现的维度降低造成了信息丢失。
实际应用中的神经网络结构:输入层单元数 = 特征的维度;输出层单元数 = 类别个数; 隐层单元数理论上是越多越好,但是单元数越多意味着计算量越大,故其取值一般稍大于传入特征数或者几倍关系也可以。基于隐藏层的数目,一般默认使用1个隐层的神经网络,也可以使用多个隐层的神经网络,若为多层神经网路一般默认所有隐层具有相同的单元数。
神经网络中的参数更新:一般使用随机梯度下降法(SGD),而非批量梯度下降,原因是:1. SGD可以更加高效的处理数据中的冗余性(假设我们将数据集中所有样本都复制一次,这样包含了一半的冗余信息,使用PGD的计算量也会增大一倍,而SGD不受影响);2. 有机会跳出局部最小值到达全局最小值(因为整个数据集的关于误差函数的驻点通常不会是每个数据点各自的驻点)

