
细品 - 过拟合与模型选择*
`欠拟合和过拟合
欠拟合是指模型不能很好的捕获到数据特征,不能很好的拟合数据,学习能力底下。解决方法:增加模型的复杂度
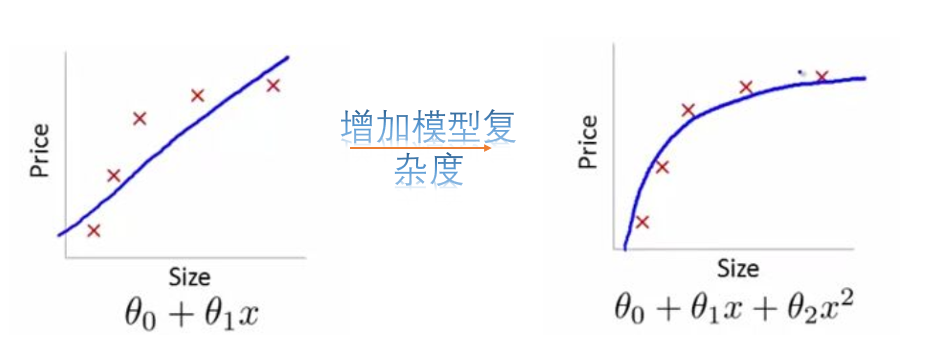
过拟合是指模型不仅仅学习了数据集中的有效信息,也学习到了其中的噪音数据,使得模型在训练集上的表现非常好,但是对于测试集的预测效果很差。解决方案:
(1) 导致过拟合的一个原因可能是由于数据不纯、包含大量的噪声数据,这时候我们需要重新清洗数据。
(2) 增加训练数据的样本量
(3) 采用正则化方法,降低模型参数复杂度(参数大小和参数量),从而降低模型复杂度
(4) 神经网络中常采用dropout方法:在训练的时候让神经元以一定的概率不工作。

如何判断你的模型是欠拟合还是过拟合?通常的做法就是将你的训练数据集拆分成训练集和验证集,通过观察训练误差和验证误差的情况来判断模型对训练数据的拟合情况。
正则化
监督学习问题无非就是在规则化参数的同时最小化误差。最小化误差是为了让我们模型更好的拟合数据,而规则化参数是为了防止模型对数据的过分拟合。前面我们也提到,当我们的模型处于过拟合时,我们可以通过在模型损失函数上添加正则化项,用于控制模型参数的复杂度,从而得到更为简单的参数,获得更为理想的模型。可见,正则化的一个根本目的就是使我们可以选择出那种既能够很好的拟合数据,相对来说又最简单的模型。
线性回归正则化后的表达式为:
![]()
这里的![]() 代表正则化系数,
代表正则化系数,![]() 是我们常说的正则化项,正则化项常用的形式有哪些呢?
是我们常说的正则化项,正则化项常用的形式有哪些呢?

该范数表示的是参数向量中非0元素的个数。这时候我们可以试想我们用![]() 范数正则化一个参数矩阵
范数正则化一个参数矩阵![]() 的话,就相当于让
的话,就相当于让![]() 中值为0元素非常多,也就是让参数矩阵
中值为0元素非常多,也就是让参数矩阵![]() 稀疏。
稀疏。
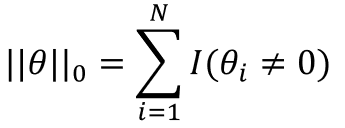
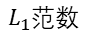
该范数表示的是参数向量中各元素绝对值之和。![]() 范数也称为稀疏规则算子。我们试想用
范数也称为稀疏规则算子。我们试想用![]() 范数正则化一个参数向量
范数正则化一个参数向量![]() 的话,就相当于让
的话,就相当于让![]() 中每一个元素都很小甚至是等于0。
中每一个元素都很小甚至是等于0。
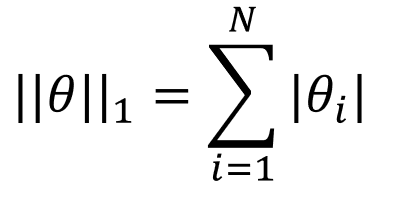
那问题来了Question1:![]() 范数为什么可以实现稀疏?
范数为什么可以实现稀疏?
加入![]() 范数后的代价函数可以表示为无约束形式
范数后的代价函数可以表示为无约束形式
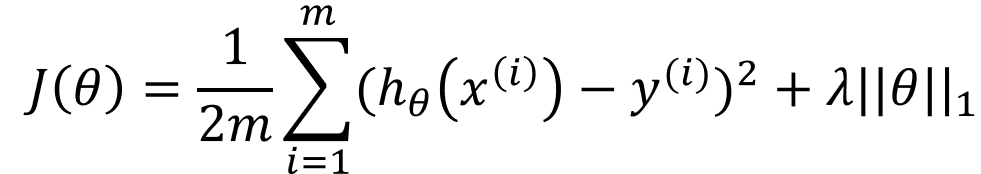
最小化![]() 又等价于约束问题
又等价于约束问题![]() 下最小化
下最小化![]()
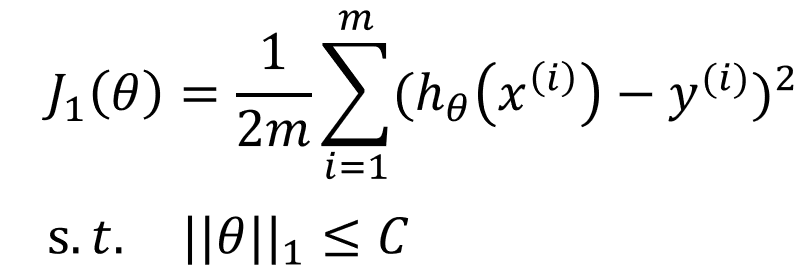
这里我们假设参数向量![]() 只有两个元素,我们可以在一个平面上画出
只有两个元素,我们可以在一个平面上画出![]() 的等高线图以及约束条件的表示,如图
的等高线图以及约束条件的表示,如图
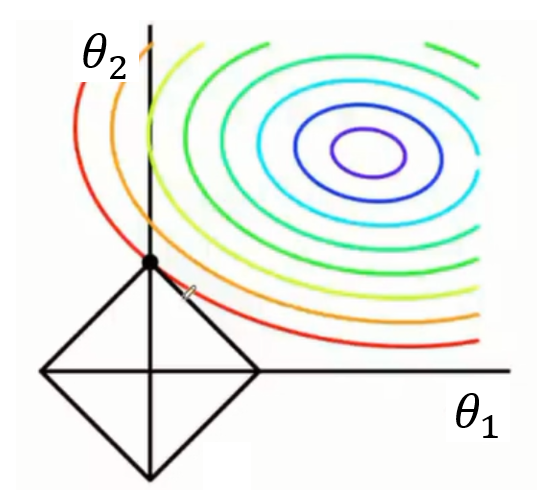
我们知道等高线越向外损失越大(凸函数),![]() 约束在图上可以表示为如图的正方形,两图形的第一个交点就是代价函数取最小时的情形。两图形第一个交点相交于正方形顶角上的概率远远大于相交于其他位置的概率(很明显)。顶点坐标只有一个参数不为0,另一个参数为0,也就是更加容易产生稀疏。在更高维的情况下也是如此,因此
约束在图上可以表示为如图的正方形,两图形的第一个交点就是代价函数取最小时的情形。两图形第一个交点相交于正方形顶角上的概率远远大于相交于其他位置的概率(很明显)。顶点坐标只有一个参数不为0,另一个参数为0,也就是更加容易产生稀疏。在更高维的情况下也是如此,因此![]() 会使得参数更多的为0,只是又较少的一部分不为0。
会使得参数更多的为0,只是又较少的一部分不为0。![]() 的这种特性使它可以应用于特征选择。
的这种特性使它可以应用于特征选择。
前面我们也提了![]() 范数也可以实现稀疏,那问题又来了Question2:为什么实现稀疏上基本上是使用
范数也可以实现稀疏,那问题又来了Question2:为什么实现稀疏上基本上是使用![]() 范数而很少使用
范数而很少使用![]() 范数呢?这主要有两个原因:
范数呢?这主要有两个原因:
(1) ![]() 范数很难优化求解
范数很难优化求解
(2) ![]() 范数是
范数是![]() 范数的最优凸近似,并且
范数的最优凸近似,并且![]() 范数更容易优化求解
范数更容易优化求解

![]() 范数是参数向量中各元素的平方和再开平方。在防止过拟合问题上
范数是参数向量中各元素的平方和再开平方。在防止过拟合问题上![]() 范数被广泛的应用。
范数被广泛的应用。
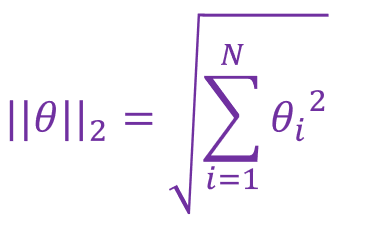
那么问题来了Question1:是什么使得它可以非常好的解决过拟合问题呢?我们再来试想:若我们最小化![]() 正则项,会使得参数向量发生什么样的变化? 会使得参数向量的每一个元素都很小,都接近于0,而非等于0(与
正则项,会使得参数向量发生什么样的变化? 会使得参数向量的每一个元素都很小,都接近于0,而非等于0(与![]() 最大的不同),这样就成功的降低了模型参数复杂度,从而避免了过拟合现象的出现。那么问题又来了Question2:为什么
最大的不同),这样就成功的降低了模型参数复杂度,从而避免了过拟合现象的出现。那么问题又来了Question2:为什么![]() 会使得参数元素都趋向于0,而非等于0呢?我们像
会使得参数元素都趋向于0,而非等于0呢?我们像![]() 那样给出代价函数的约束等价问题:
那样给出代价函数的约束等价问题:
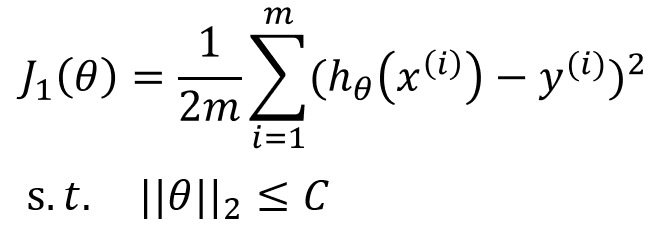
该约束问题在图形上的表示,如下:
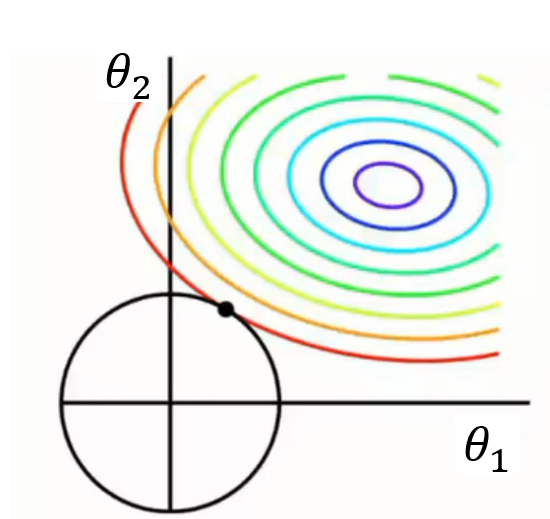
与![]() 不同,
不同,![]() 的约束条件表示为一个圆形,两个图形的第一个交点大多不会出现在非坐标轴上,因为要想交于坐标轴那么
的约束条件表示为一个圆形,两个图形的第一个交点大多不会出现在非坐标轴上,因为要想交于坐标轴那么![]() 的圆心也必须在坐标轴上,这种情况是很少发生的,故
的圆心也必须在坐标轴上,这种情况是很少发生的,故![]() 不会拥有
不会拥有![]() 的那种使得参数大部分都是0的特性。而最小化
的那种使得参数大部分都是0的特性。而最小化![]() 正则就会使得参数元素都很小,也就是都趋于0。
正则就会使得参数元素都很小,也就是都趋于0。
总结:![]() 会趋向于产生少量的特征,而其他特征的参数(权值)都为0,可以用来做特征选择; 而
会趋向于产生少量的特征,而其他特征的参数(权值)都为0,可以用来做特征选择; 而![]() 会选择更多的特征,这些特征的参数都趋于0,广泛应用与过拟合问题。
会选择更多的特征,这些特征的参数都趋于0,广泛应用与过拟合问题。
补充:Question1:其实![]() 除了有防止过拟合的特性,它还可以使得梯度下降的求解过程变得稳定而迅速,这又是如何实现的呢?
除了有防止过拟合的特性,它还可以使得梯度下降的求解过程变得稳定而迅速,这又是如何实现的呢?
我们前面给出了加入正则项![]() 和
和![]() 后的线性回归代价函数的表示形式:
后的线性回归代价函数的表示形式:
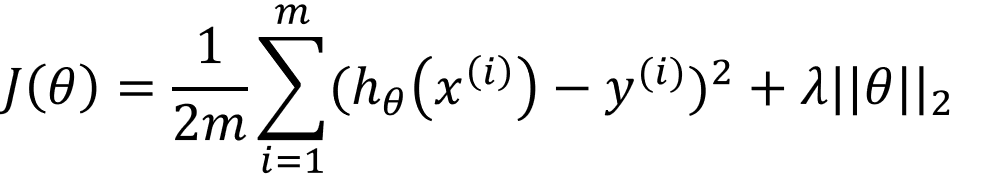
我们对其求导后得到了梯度下降的权值更新公式:
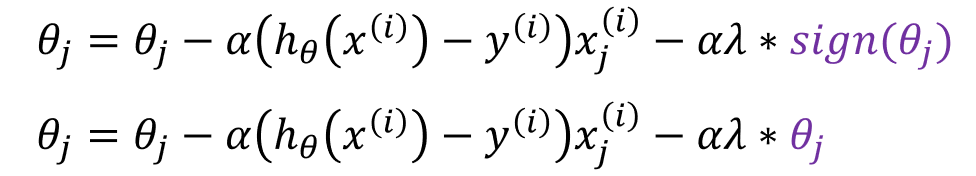
这时我们发现![]() 中的
中的![]() 是第j个参数的符号,是个定值; 而
是第j个参数的符号,是个定值; 而![]() 中的
中的![]() 是变得。故,
是变得。故,![]() 正则化后的参数更新速度会随着参数的更新而变动,参数大更新快,参数小更新慢,所以它会进一步优化梯度下降的求解。
正则化后的参数更新速度会随着参数的更新而变动,参数大更新快,参数小更新慢,所以它会进一步优化梯度下降的求解。
Question2:正则化系数![]() 要如何确定呢?
要如何确定呢?
可以尝试一系列数据 0, 0.01, 0.02,0.04, 0.08, ……, 10.24(10),…… 【2倍关系】
每一个![]() 的取值都会得到一组参数
的取值都会得到一组参数![]() ,这样会得到多组参数向量
,这样会得到多组参数向量
然后用每一组参数![]() 计算检验集的误差
计算检验集的误差
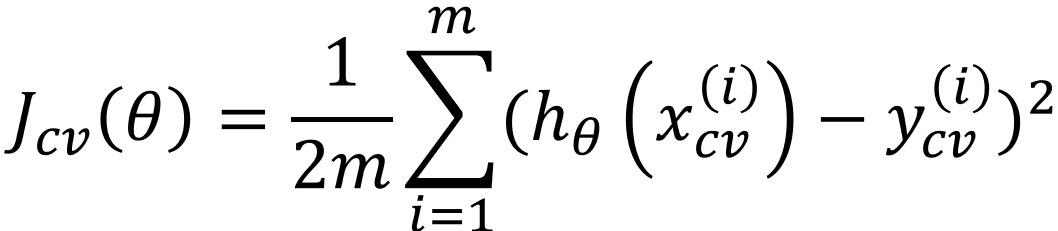
我们选择检验集的误差最小的那个![]() ,作为最优取值。
,作为最优取值。

