
python基础学习笔记 - 备忘
基础中的基础
Python标识符
命名规则:
- Python标识符区分大小写。
- 可以包括英文、数字以及下划线,但不能以数字开头。
- 以下划线开头的标识符是有特殊意义的:
a) 以单下划线开头(如_foo)的代表保护变量(protected),需要通过类提供的接口进行访问,不能用import导入。
b) 以双下划线开头(如_ _foo)代表类的私有成员(private)。文本上被替换为_classname_ _foo,其中classname是当前类名,并带上一个下划线做前缀。
c) 以双下划线开头并结尾(如_ _foo_ _)代表python中特殊方法专用的标识符,如_ _init_ _()代表类的构造函数。
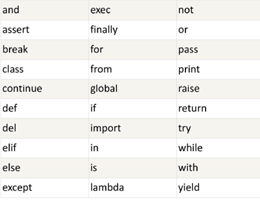
Python保留字
Python注释
单行注释使用 #
多行注释使用 3个单(双)引号
Python程序基本框架
键盘输入语句 str1 = raw_input(“input a string:”) – 将用户输入作为字符串
输出语句 print()
格式化输出:
查看变量类型 type()
查看变量地址 id()
x=12 和 x=13 -- x地址不同
y=13 和 x=13 -- x,y地址相同
故:变量变的不是内容而是指向内存中的地址
Python字符串基础
字符串中字符位置是从0开始的。
str1 = r”aa\nbb” r表示的是原样输出字符内容(关闭转义机制)
字符串的一些基本操作:
a) + 字符串连接;* 字符串重复;s[i:j]切片(i从0开始,不包含j);s[::-1]字符串反转。
b) len() 放回元素个数;
c) str1.find(s, beg, end) 找到返回索引值,否则返回-1。s – 查找字符串;beg – 起始索引(默认为0);end – 结束索引(默认为len(str1))。
d) str1.strip() 去除首位空格;str1.split() 拆分字符串。
e) str1.upper() 和str1.lower() 字符串大小写转化
f) str1.replace(‘ori’, ‘new’) 字符替换。
g) 判断字符串
i. str1.isalnum() 是字母或数字?
ii. str1.isalpha () 是字母?
iii. str1.isdigit() 是数字?
iv. str1.istitle() 是首字母大写?
v. str1.isspace() 是空白字符?
h) isinstance() 判断对象
i. isinstance(1, int) -> True
ii. isinstance(‘1’, float) -> False
iii. isinstance([1,2], (list, tuple, int)) -> True
Python列表基础
列表中的数据是可修改的!元组的数据是不可修改的!
基本操作:
a) li1.append() ; li1.extend(); li1.count(value);
b) li1.remove(value) 删除第一个出现的value; del li1[index] 删除li1中第index位元素;ch = li1.pop(index) 删除索引为index的元素,值返回ch。
c) li1.reverse() 逆序(直接对li1进行修改,无返回值);li1.sort() 从小到大排序(无返回值, li1.sort(reverse = True) 从大到小排序)。
d) x in y x在y中 -> True; x不在y中 -> False。
e) 复制问题 li1 = li2[:] 深拷贝(等同于 li1 = li2.copy()); 浅拷贝li1 = li2(li1会随li2的变化而变)
f) li1.clear() 清空列表,列表仍存在[]
Python 列表新知:
list是python的内置数据类型,list中的数据类型不必相同,而array中的数据类型必须完全相同。
list中保存的是数据的存放地址(指针),例如
list1 = [1, 2, 3, 'a']
实际list1的存储需要4个指针和4个数据,这就增加了大量的存储资源。那么怎么优化呢? 实际应用中当没有足够的资源可以用时,通常会使用array库而不是list,这样会省3-4倍的内存空间。
Python字典基础
字典可以以键值对的形式存储信息。
基本操作:
1. 创建字典
dict1 = {} # 创建空的字典
dict([1, 'one'], [2, 'two'], [3,'three']) # {1:'one' , 2:'two', 3:'three'}
dict1.fromkeys((1,2)) #{1: None, 2: None}
dict1.fromkeys((1,2), ‘number’) #{1: ‘number’, 2: ‘number’}
2. 访问与修改
dict1.keys() #每个键 dict1.values() #每个值 dict1.items() #每个项 dict1.get(2, '木有') # 有2的value 返回值; 无值返回‘木有’ #访问的三种形式 a[] -> 无key,报错 a.get() -> 无key,不报错,返回None a.setdefault(5, 'five') -> 无key,添加到a dict1.clear() #清空字典 del(dict1['key']) # 删除键为‘key’的item dict1.pop(keys) #给键弹出值 (整个items都没了) dict1.popitem() # 随机弹出item
3. 字典的排序
sorted(dict, value, reverse)
sorted(a.items, key = lambda asd:asd[0], reverse = True) # 键 降序排列 sorted(a.items, key = lambda asd:asd[1], reverse = False) # 值 升序排列 ##注: 排序后原字典没有变,顺序依旧
短路逻辑
3and4 == 4
3or4 == 3
作用域
python变量的作用域分成两种:全局作用域和局部作用域。
x = 1 # 全局变量 def func(): x = 10 #局部变量
全局变量可以被程序任何地方访问,但若要对其进行修改只能在全局进行操作!若要在局部修改全局变量就会报错。还要注意一点:局部访问变量时,如若没找到就会不断的逐步向外层查找,直到找到,找不到会报错。
x = 1 def func(): x += 10 # 报错!
进阶1:Python实用语法
三元操作符
small = x if x < y else y
相当于:
if x < y: small = x else: small = y
列表推导式
[有关于A的表达式 for A in B]
例如: [i*i for i in range(10)] --> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
特殊语法
filter(function, sequence)
对sequence中的item依次执行function(item),将执行结果为True的item组成一个List/String/Tuple(取决于sequence的类型)返回。
str = ['a', 'b', 'c', 'd'] def fun1(s): return True if s != 'a' else False ret = filter(fun1, str) print(ret) ## ['b', 'c', 'd']
map(function, sequence)
对sequence中的item依次执行function(item), 将执行结果组成一个List返回
str = ['a', 'b', 'c', 'd'] def fun2(s): return s + ".txt" ret = map(fun2, str) print(ret) ##['a.txt', 'b.txt', 'c.txt', 'd.txt']
lambda
lambda可以简化函数的定义的书写形式,使得代码更为简洁。
g = lambda x:x+1 """ 相当于 def g(x): return x+1 """ print(g(2)) #3 lambda x:x+1(3) #4

