

步骤一:查看所有的sql语句运行所占用的内存大小排名
select
A.creator,B.sql_text,
trunc(sum(a.total_size/1024/1024)) "分配大小(M)",
trunc(sum(a.DATA_size/1024/1024)) "占用大小(M)"
from v$mem_pool A, v$sessions B WHERE A.CREATOR=B.THRD_ID
GROUP BY A.CREATOR,B.SQL_TEXT ORDER BY 3 DESC
步骤二:根据步骤一查询的结果,选择内存占用大的SQL语句进行调优
办法一:DM数据库本身调优,如 v$mem_pool,v$bufferpool参数内设置
办法二:SQL优化
1、查看执行计化
a.sql语句窗口按F9,或者(fn+F9)两个键
b.在sql语句前加 explain
2、索引优化
少用CSCN2(聚集索引扫描),可以简单的理解为全表扫描。可添加索引,如:变成SSEK2二级索引数据定位
3、更新统计信息
对象统计信息描述了对象数据的分布特征。统计信息是优化器的代价计算的依据,可以帮助优化器较精确地估算成本,对执行计划的选择起着至关重要的作用。统计信息的收集频率是一把双刃剑频率太低导致统计信息滞后,频率太高又影响查询性能,因此,系统管理员需要根据实际情况,合理安排统计信息收集的频率。
当发现运行一直很快的SQL突然变慢了,建了索引的列执行计划不走索引,都可以考虑是不是统计信息太久没有更新,数据的分布特征已经发生了变化。
#对库上所有模式下的所有用户表以及表上的所有索引生成统计信息
CALL SP_DB_STAT_INIT ();
登录后复制
#更新用户的索引的统计信息
SP_INDEX_STAT_INIT(USER,'IDX C1 T1');
#更新某一个表上的指定索引
stat 100 on index EBASEINFO_UNISCID_INDEX:
#更新某一个表的某一列信息
stat 100 on E_FR_EPBBASEINFO(ENTNAME);
#收集表的统计信息
DBMS_STATS.GATHER_TABLE_STATS('模式名','表名',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO')
#收集列的统计信息
SP_COL_STAT_INIT('模式名' ,'表名','列名');
4、清除已有计划
您可能惊讶的是执行计划还是收集统计信息之前的那个,并没有采用最新EXPLAIN命令推荐的。究其原因,数据库为了缩短总体执行时间只进行一次硬解析,第一次解析生成的计划会被缓存到内存中。下次同样的SQL执行将重用缓存中的计划。
怎么办?
方法是清除旧的执行计划,再一次硬解析创建新的执行计划
方法:查询内存中执行计划的CACHE ITEM
根据sql语句文本在v$cachepIn视图内搜索对应的cache_item
select cache_item,sqlstr from v$cachepln
清除缓存的执行计划
SQL> sp_clear_plan_cache(cache_item字段值);
SQL> select cache_item,sqlstr from v$cachepln
where sqlstr like 'insert into test2 select%' and sglstr not like '%cache未选定行
清除执行计划除了采用sp clear plan cache过程以外。还可以在表上执行一个DDL语句,涉及的SQL的执行计划自动被清除。
通过在SQL中添加HINT改变执行计划
其实很多时候开发人员和用户对于数据分布是很清楚的,他们往往知道SQL语句按照哪种方法执行会更快。在这种情况下,用户可以有一种方法,指示优化器按照固定的方法选择SQL的执行计划。DM8把这种热工千预优化器的方法称为HINT。略,自行网上查找资料
5、执行计划使用简介
执行计划顺序:
各计划节点的执行顺序为: 缩进越多的越先执行,同样缩进的上面的先执行,下面的后执行,上下的优先级高于内外。
缩进最深的,最先执行,缩进深度相同的,先上后下口诀: 最右最上先执行
常见操作符:
BLKUP2 二次扫描 (回表)
CSCN2 聚族索引扫描 (全表扫描)
HASH2 INNER JOIN hash 内连接
NEST LOOP FULL JOIN2 嵌套连接
MERGE INNER JOIN3 归并连接
NSET2 结果集PRJT2 投影
SSCN 二级索引扫描
SSEK2 二级索引数据定位
CSEK2 聚族索引定位
SLCT:选择,用于查询条件的过滤
AAGR:简单聚集,用于没有GROUP BY的COUNT、SUM等聚集函数的计算:
执行计划中常见的操作符解释
常见的操作符有:
NSET2:结果集
PRJT2:投影,,用于选择表达式项的计算。
CSCN2 :聚集索引扫描
SSCN :直接使用二级索引进行扫描
SSEK2 :二级索引数据定位
CSEK2 :聚集索引数据定位
BLKUP2 :定位查找
SLCT2:关系的―选择‖(select)运算,用于查询条件的过滤。
SORT: SORT是做排序操作时使用到的操作符。
HAGR:HASH AGR操作,是最基础的分组方式,对于没有优化条件的分组语句,一般都会按这种方式进行分组。
SAGR: SORTED AGR操作,同一分组的数据按照顺序取出。
NEST LOOP INNER JOIN(嵌套循环连接) :最基础的连接方式,将一张表的一个值与另一张表的所有值拼接,形成一个大结果集,再从大结果集中过滤出满足条件的行。
HASH JOIN(哈希连接):没有索引的情况下,大多数连接的处理方式,将一张表的连接列做成HASH表,另一张表的数据向这个HASH表匹配,满足条件的返回。
INDEX JOIN(索引连接): 将一张表的数据拿出,去另外一张表上进行范围扫描找出需要的数据行,需要右表的连接列上存在索引。
MERGE JOIN(归并连接):两张表都扫描索引,按照索引顺序进行归并。
附:查看ET
ET是达梦自带的系统存储过程,能统计SQL每个操作符的时间花费,从而定位到有性能问题的操作,指导我们去优化;
达梦ET默认未启用,设置启动以下三个参数可以启用ET(ENABLE_MONITOR、MONITOR_TIME和MONITOR_SQL_EXEC);
其中,ENABLE_MONITOR和MONITOR_TIME默认已开启,如果未开启可以使用如下方法开启:
SP_SET_PARA_VALUE(1,‘ENABLE_MONITOR’,1);
SP_SET_PARA_VALUE(1,‘MONITOR_TIME’,1);
MONITOR_SQL_EXEC为会话级动态参数,可以设置只针对当前会话开启:
SF_SET_SESSION_PARA_VALUE(‘MONITOR_SQL_EXEC’,1);
执行SQL语句,我们会看到一个执行号,直接点这个执行号,即可调用ET;

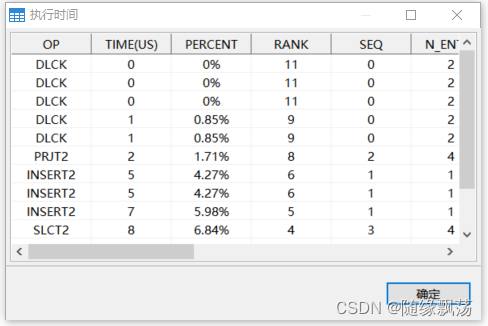
在知道执行号的情况下,也可以这样使用ET CALL ET(124571)
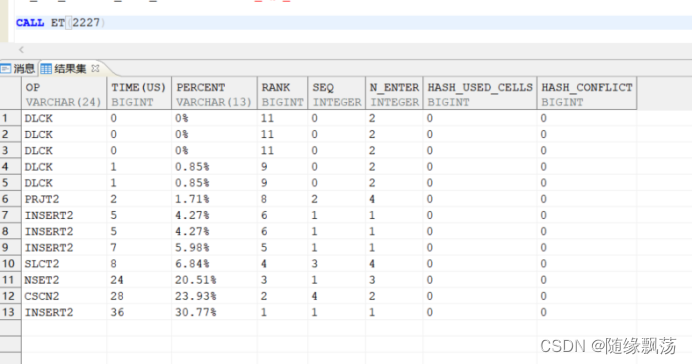
ET结果说明:
OP: 操作符
TIME(us): 时间开销,单位为微秒
PERCENT: 执行时间占总时间百分比
RANK: 执行时间耗时排序
SEQ: 执行计划节点号
N_ENTER: 进入次数
