链家网---JAVA架构师
链家网---JAVA架构师
本月7日去了一趟链家网面试,虽然没有面上,但仍有不少收获,在此做个简单的分享,当然了主要是分享给自己,让大家见笑了。因为这次是第一次面试JAVA网站架构师相关的职位,还是有些心虚的,毕竟之前大部分时间都是在做.NET相关的技术工作,并且自己所负责过的项目规模都是比较小,并且差异也较大。在高并发性,高伸缩性的互联网网站的架构方面没有太多的经验,只是在之前空闲时阅读李智慧老师的《大型网站技术架构》一书给了我不少的启发。面试过程比较简单,首先是笔试,架构师职位主要是一些知识的理解,也有一些数据库查询方面的基础试题。知识点方面比较偏重于NoSQL、缓存服务器集群、Session服务器等内容。大体做的还凑合,因此面试官也比较客气,和我更加深入的聊了相关方面的知识,也包括该公司主要的组织架构和盈利来源。
由于链家网到目前为止仍然不算特别出名,但在各大网站上已经能经常看到该公司基于房地产行业的研究报告。刚开始我最大的疑问就是这个公司和搜房网、安居客等有什么区别?这些网站都已经存在多年,那么该公司有什么特别的地方可以存活至今,并在这两年内发展迅速?在回答这些疑问之前,我稍微跑个题,介绍一下面试官老宋,这是我给他起的外号,那次见面应该是第一次也是最后一次见他了,但他给我留下了极深的印象。技术水平很高,很注意自己的外在气质,沟通时十分和善,影响最深的是在面试时他全程用钢笔记录相关的信息,非常的专业和尊重面试者。之所以提这个,主要是想说个人认为程序员在找一份工作时除了收入,公司的未来发展外,最重要的就是直属领导的性格契合度了,适合的才是最好的。只有这样,你才能无论遇到多大的困难,都坚信团队、项目能顺利发展,自己多奉献一些也是值得的,当然最终受益的也是自己了。
接下来,回答之前的问题,链家网是非常大型与房地产经纪相关的公司,组织架构比较复杂和特殊,因为他并不是一家企业慢慢发展起来的,而又由链家网牵头,和各地不同的房产经纪公司联合组建起来的。由于房地产政策的地区差异,各地客户群体需求差异,很难有一个非常统一的运营模式来进行管理。各地公司单独运营,总部主要是一个互联网的用户入口,数据信息服务系统也是各自独立,感觉比较像原来特许加盟的形式,也算是一种互联网+的实践了。该公司与搜房网、安居客的差异来源于它的数据完全来之于本公司,基本是真实有效的,而搜房网等公司的数据来源于各个房产经纪公司或者经纪人,信息非常的不可靠。简单举个例子,比如一套房子房东报价500万,但一般来说这里面都有一定的砍价空间,那么房产经纪人在网上挂售这套房产时就会进行一定的减价,比如说495万,于此同时,房东一般会和多家经纪公司联系,那么其他经纪人看到这个报价,为了做成生意,很自然的把价格报的更低,最后,甚至爆出400万这种不可能成交的价格,只是为了接到潜在购买者的电话。这样就形成了"劣币驱逐良币"的情况,使得网站信息不再可信,同时由于一套房屋可以由多家经纪公司挂售,因而网站上的房源数量往往远多于实际的数量,给潜在购买者产生了很大的困扰。此外,由于链家公司所辖房产经纪公司,比如说上海的德佑公司,已有一定的体量,为了更进一步的保证房产的真实性,经过房产局对在售房屋进行了全面的核查。借用老宋的话说就是,"搜房他们是淘宝,链家是京东"。以上是对该公司经营模式的介绍,对房产经纪类企业深入互联化有很大的借鉴作用。
然后开始技术部分的介绍,刚开始我也有很打困惑,为什么这家公司需要一个OA方面的架构师,经过沟通我才知道,该公司目前有大约3万名的房产经纪,所以该公司的企业信息系统,每天有将近1000万得PV,抵得上一个中型网站,每天的早上打卡(采用网上打卡)、争抢客户资源等活动会产生大量的并发,类似于电商网站的秒杀,因而需要有高并发相关经验的工程师。
最后,是几个主要的技术点,包括权限系统的设计,缓存服务器集群的架设,消息队列系统的构建等。在此主要介绍前两个,其他的会在之后补充。权限系统基本参考资深博主天空行马的方案,如下图所示。
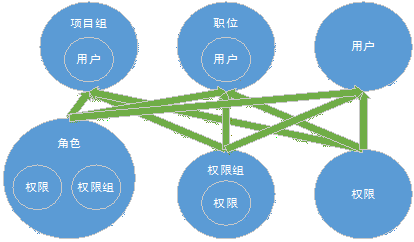
主体结构比较简单,职位和项目组的设置可以同时满足职能型和项目型的企业组织架构,角色则对之前两者进行了有限的补充,比如系统管理员等不能通过职位和项目组描述的情况。一般来说,系统中包含两种类型的权限:模块的权限;行为的权限。权限组通常用于表示某一模块中所有行为权限的集合。这个思路简单清晰,便于实现和未来的扩展。在实现中,可以通过相关的权限代码组合规则
来将权限信息保存在数据库中,例如权限的数字或字母的表示组合。
分布式缓存集群的伸缩性不同于Web服务器集群的伸缩性,对于后者来说,每一台Web服务器上内容相同,伸缩性只需要简单的负载均衡算法即可达到。但每一台分布式缓存服务器上数据各不相同,缓存访问请求不可以再集群中任意服务器上完成,需要先找到存储该数据的服务器后访问。同时新上线的服务器上没有缓存数据,下线的缓存服务器上有热点数据,会对分布式缓存集群的伸缩性设计造成很大的困难。为了更好的阐述相关概念,接下来将以最常见的Memcached为例介绍相关设计与实现,所图所示。
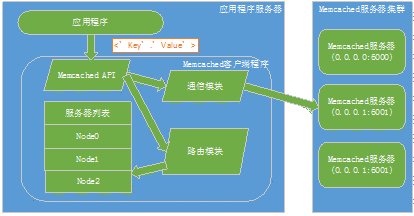
过程非常简单,Memcached API将应用程序传入的key进行哈希运算,然后使用简单余数Hash算法(例如11/3=2),得到指定的节点Node2,然后存储指定服务器。需要注意的一旦涉及到服务器的扩容,以上见余数Hash算法就会遇到很大的问题,例如当要将3台缓存服务器增加到4台时(11/4=3),这时再Node3上找不该缓存,缓存未命中的概率达到75%,并且会着扩容,为命中的概率不断增大(N/N+1)。这时就会使用到比较流行的一致性hash算法,该算法通过一致性Hash环的数据结构实现KEY到缓存服务器的Hash映射,过程若下图所示。
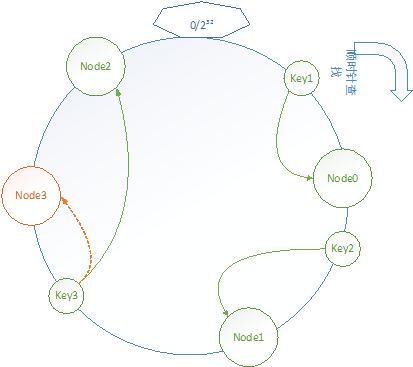
算法的具体过程为:首先构造一个232的整数环,根据节点名称的Hash值(极可能的散列)将缓存服务器节点防止在这个Hash环上,然后计算需要缓存数据KEY的Hash值,顺时针查找最近的节点,作为目标节点。如上图中,在集群扩容时,即在原有Node0-2的基础上加入Node3,可以看到,唯一受影响的数据为Key3,如此缓存的命中率就变为了N/N+1,能满足实际需要。实际代码中,该还一般由二叉查找树实现,通过链接最外侧的叶子节点形成环。但以上设计仍然存在一个问题,就是再扩容后,Node0和1的负载量是Node2和Node3的两倍。解决该痛点的方法是将物理缓存服务器节点虚拟化为N个虚拟节点,均匀的分散到环中去,使得负载尽可能的均衡。这样就做到了新增物理服务器对原有物理服务器的影响一致,也就是该算法名称的由来。
注:本文主要供自己学习,不妥之处望见谅。
参考资料:
[1]天空行马. OA系统权限管理设计方案[EB/OL]. http://www.cnblogs.com/kivenhou/archive/2009/10/19/1586106.html。
[2]李智慧. 大型网站架构技术[M]. 上海:电子工业出版社, 2012. 106-112


 浙公网安备 33010602011771号
浙公网安备 33010602011771号