kube-scheduler源码分析(3)-抢占调度分析
kube-scheduler源码分析(3)-抢占调度分析
kube-scheduler简介
kube-scheduler组件是kubernetes中的核心组件之一,主要负责pod资源对象的调度工作,具体来说,kube-scheduler组件负责根据调度算法(包括预选算法和优选算法)将未调度的pod调度到合适的最优的node节点上。
kube-scheduler架构图
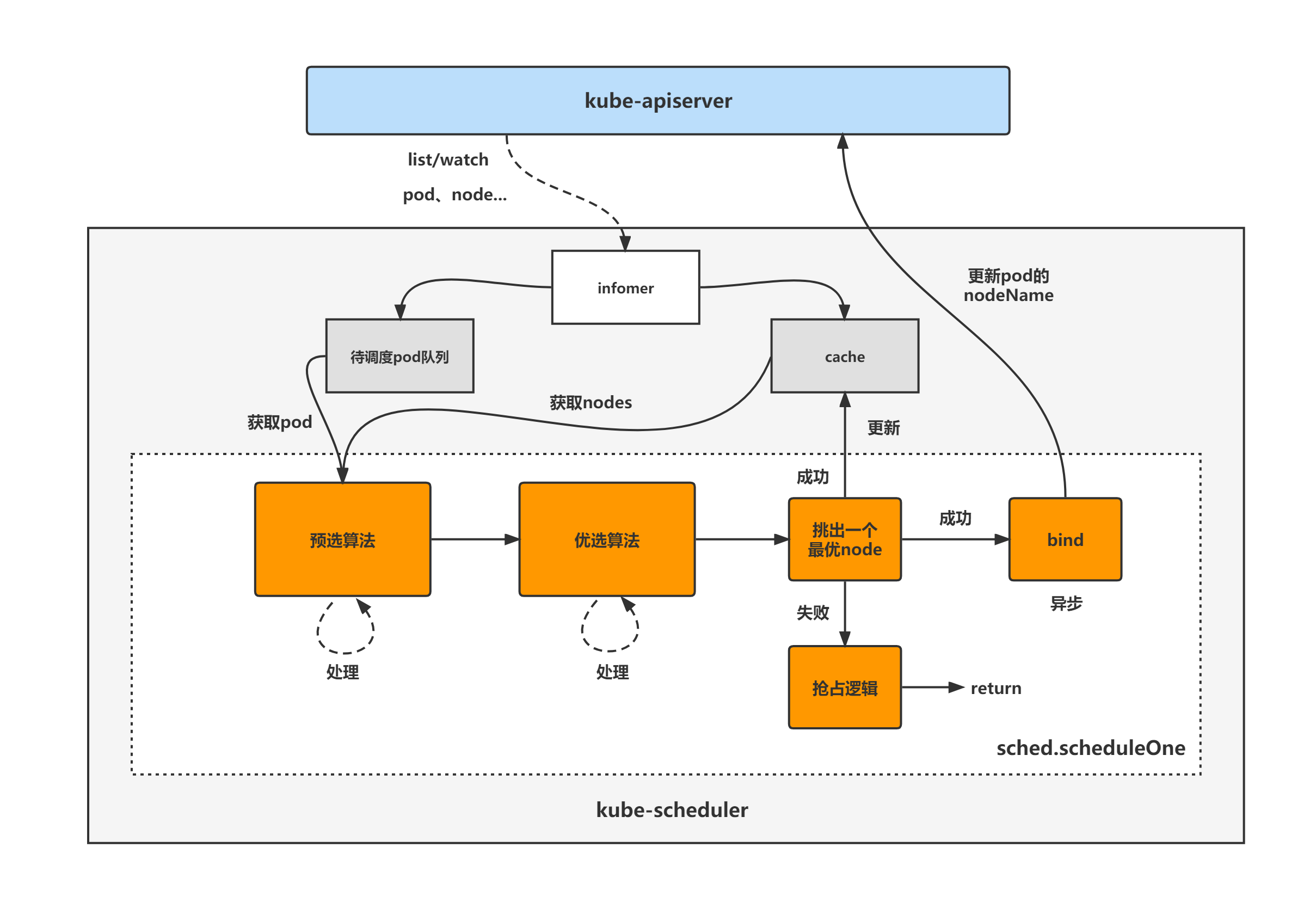
kube-scheduler的大致组成和处理流程如下图,kube-scheduler对pod、node等对象进行了list/watch,根据informer将未调度的pod放入待调度pod队列,并根据informer构建调度器cache(用于快速获取需要的node等对象),然后sched.scheduleOne方法为kube-scheduler组件调度pod的核心处理逻辑所在,从未调度pod队列中取出一个pod,经过预选与优选算法,最终选出一个最优node,上述步骤都成功则更新cache并异步执行bind操作,也就是更新pod的nodeName字段,失败则进入抢占逻辑,至此一个pod的调度工作完成。

kube-scheduler抢占调度概述
优先级和抢占机制,解决的是 Pod 调度失败时该怎么办的问题。
正常情况下,当一个 pod 调度失败后,就会被暂时 “搁置” 处于 pending 状态,直到 pod 被更新或者集群状态发生变化,调度器才会对这个 pod 进行重新调度。
但是有的时候,我们希望给pod分等级,即分优先级。当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod,这样一来就可以保证高优先级 Pod 会优先调度成功。
关于pod优先级,具体请参考:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/pod-priority-preemption/
抢占发生的原因,一定是一个高优先级的 pod 调度失败,我们称这个 pod 为“抢占者”,称被抢占的 pod 为“牺牲者”(victims)。
PDB概述
PDB全称PodDisruptionBudget,可以理解为是k8s中用来保证Deployment、StatefulSet等控制器在集群中存在的最小副本数量的一个对象。
具体请参考:
https://kubernetes.io/zh/docs/concepts/workloads/pods/disruptions/
https://kubernetes.io/zh/docs/tasks/run-application/configure-pdb/
抢占调度功能开启与关闭配置
kube-scheduler的抢占调度功能默认开启。
在 Kubernetes 1.15+版本,如果 NonPreemptingPriority被启用了(kube-scheduler组件启动参数--feature-gates=NonPreemptingPriority=true) ,PriorityClass 可以设置 preemptionPolicy: Never,则该 PriorityClass 的所有 Pod在调度失败后将不会执行抢占逻辑。
另外,在 Kubernetes 1.11+版本,kube-scheduler组件也可以配置文件参数设置将抢占调度功能关闭(注意:不能通过组件启动命令行参数设置)。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
...
disablePreemption: true
配置文件通过kube-scheduler启动参数--config指定。
kube-scheduler启动参数参考:https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-scheduler/
kube-scheduler配置文件参考:https://kubernetes.io/zh/docs/reference/scheduling/config/
kube-scheduler组件的分析将分为三大块进行,分别是:
(1)kube-scheduler初始化与启动分析;
(2)kube-scheduler核心处理逻辑分析;
(3)kube-scheduler抢占调度逻辑分析;
本篇进行抢占调度逻辑分析。
3.kube-scheduler抢占调度逻辑分析
基于tag v1.17.4
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
分析入口-scheduleOne
把scheduleOne方法作为kube-scheduler组件抢占调度的分析入口,这里只关注到scheduleOne方法中抢占调度相关的逻辑:
(1)调用sched.Algorithm.Schedule方法,调度pod;
(2)pod调度失败后,调用sched.DisablePreemption判断kube-scheduler组件是否关闭了抢占调度功能;
(3)如未关闭抢占调度功能,则调用sched.preempt进行抢占调度逻辑;
// pkg/scheduler/scheduler.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...
// 调度pod
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, state, pod)
if err != nil {
...
if fitError, ok := err.(*core.FitError); ok {
// 判断是否关闭了抢占调度功能
if sched.DisablePreemption {
klog.V(3).Infof("Pod priority feature is not enabled or preemption is disabled by scheduler configuration." +
" No preemption is performed.")
} else {
// 抢占调度逻辑
preemptionStartTime := time.Now()
sched.preempt(schedulingCycleCtx, state, fwk, pod, fitError)
...
}
...
}
...
sched.preempt
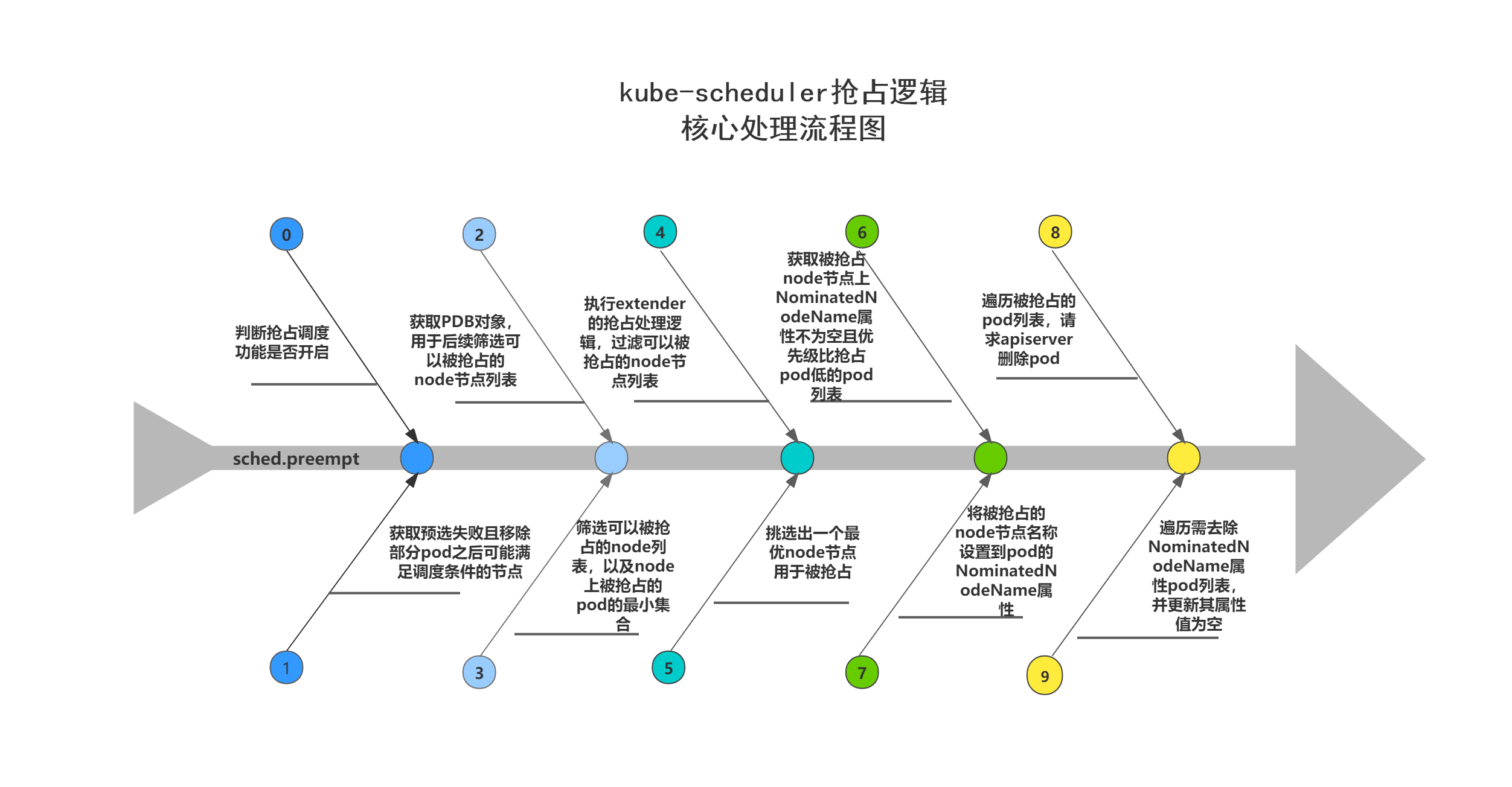
sched.preempt为kube-scheduler抢占调度处理逻辑所在,主要逻辑:
(1)调用sched.Algorithm.Preempt,模拟pod抢占调度过程,返回pod可以抢占的node节点、被抢占的pod列表、需要去除NominatedNodeName属性的pod列表;
(2)调用sched.podPreemptor.setNominatedNodeName,请求apiserver,将可以抢占的node节点名称设置到pod的NominatedNodeName属性值中,然后该pod会重新进入待调度pod队列,等待再一次调度;
(3)遍历被抢占的pod列表,请求apiserver,删除pod;
(4)遍历需要去除NominatedNodeName属性的pod列表,请求apiserver,更新pod,去除pod的NominatedNodeName属性值;
注意:抢占调度处理逻辑并马上把调度失败的pod再次抢占调度到node上,而是根据模拟抢占的结果,删除被抢占pod,空出相应的资源,最后把该调度失败的pod交给下一个调度周期再处理。
// pkg/scheduler/scheduler.go
func (sched *Scheduler) preempt(ctx context.Context, state *framework.CycleState, fwk framework.Framework, preemptor *v1.Pod, scheduleErr error) (string, error) {
...
// (1)模拟pod抢占调度过程,返回pod可以抢占的node节点、被抢占的pod列表、需要去除nominateName属性的pod列表
node, victims, nominatedPodsToClear, err := sched.Algorithm.Preempt(ctx, state, preemptor, scheduleErr)
if err != nil {
klog.Errorf("Error preempting victims to make room for %v/%v: %v", preemptor.Namespace, preemptor.Name, err)
return "", err
}
var nodeName = ""
if node != nil {
nodeName = node.Name
sched.SchedulingQueue.UpdateNominatedPodForNode(preemptor, nodeName)
// (2)请求apiserver,将可以抢占的node节点名称设置到pod的nominatedNode属性值中,然后该pod会重新进入待调度pod队列,等待再一次调度
err = sched.podPreemptor.setNominatedNodeName(preemptor, nodeName)
if err != nil {
klog.Errorf("Error in preemption process. Cannot set 'NominatedPod' on pod %v/%v: %v", preemptor.Namespace, preemptor.Name, err)
sched.SchedulingQueue.DeleteNominatedPodIfExists(preemptor)
return "", err
}
// (3)遍历被抢占的pod列表,请求apiserver,删除pod
for _, victim := range victims {
if err := sched.podPreemptor.deletePod(victim); err != nil {
klog.Errorf("Error preempting pod %v/%v: %v", victim.Namespace, victim.Name, err)
return "", err
}
// If the victim is a WaitingPod, send a reject message to the PermitPlugin
if waitingPod := fwk.GetWaitingPod(victim.UID); waitingPod != nil {
waitingPod.Reject("preempted")
}
sched.Recorder.Eventf(victim, preemptor, v1.EventTypeNormal, "Preempted", "Preempting", "Preempted by %v/%v on node %v", preemptor.Namespace, preemptor.Name, nodeName)
}
metrics.PreemptionVictims.Observe(float64(len(victims)))
}
// (4)遍历需要去除nominateName属性的pod列表,请求apiserver,更新pod,去除pod的nominateName属性值
for _, p := range nominatedPodsToClear {
rErr := sched.podPreemptor.removeNominatedNodeName(p)
if rErr != nil {
klog.Errorf("Cannot remove 'NominatedPod' field of pod: %v", rErr)
// We do not return as this error is not critical.
}
}
return nodeName, err
}
sched.Algorithm.Preempt
sched.Algorithm.Preempt方法模拟pod抢占调度过程,返回pod可以抢占的node节点、被抢占的pod列表、需要去除NominatedNodeName属性的pod列表,主要逻辑为:
(1)调用nodesWherePreemptionMightHelp,获取预选失败且移除部分pod之后可能可以满足调度条件的节点;
(2)获取PodDisruptionBudget对象,用于后续筛选可以被抢占的node节点列表(关于PodDisruptionBudget的用法,可自行搜索资料查看);
(3)调用g.selectNodesForPreemption,筛选可以被抢占的node节点列表,并返回node节点上被抢占的pod的最小集合;
(4)遍历scheduler-extender(kube-scheduler的一种webhook扩展机制),执行extender的抢占处理逻辑,根据处理逻辑过滤可以被抢占的node节点列表;
(5)调用pickOneNodeForPreemption,从可被抢占的node节点列表中挑选出一个node节点;
(6)调用g.getLowerPriorityNominatedPods,获取被抢占node节点上NominatedNodeName属性不为空且优先级比抢占pod低的pod列表;
// pkg/scheduler/core/generic_scheduler.go
func (g *genericScheduler) Preempt(ctx context.Context, state *framework.CycleState, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
// Scheduler may return various types of errors. Consider preemption only if
// the error is of type FitError.
fitError, ok := scheduleErr.(*FitError)
if !ok || fitError == nil {
return nil, nil, nil, nil
}
if !podEligibleToPreemptOthers(pod, g.nodeInfoSnapshot.NodeInfoMap, g.enableNonPreempting) {
klog.V(5).Infof("Pod %v/%v is not eligible for more preemption.", pod.Namespace, pod.Name)
return nil, nil, nil, nil
}
if len(g.nodeInfoSnapshot.NodeInfoMap) == 0 {
return nil, nil, nil, ErrNoNodesAvailable
}
// (1)获取预选失败且移除部分pod之后可能可以满足调度条件的节点;
potentialNodes := nodesWherePreemptionMightHelp(g.nodeInfoSnapshot.NodeInfoMap, fitError)
if len(potentialNodes) == 0 {
klog.V(3).Infof("Preemption will not help schedule pod %v/%v on any node.", pod.Namespace, pod.Name)
// In this case, we should clean-up any existing nominated node name of the pod.
return nil, nil, []*v1.Pod{pod}, nil
}
var (
pdbs []*policy.PodDisruptionBudget
err error
)
// (2)获取PodDisruptionBudget对象,用于后续筛选可以被抢占的node节点列表(关于PodDisruptionBudget的用法,可自行搜索资料查看);
if g.pdbLister != nil {
pdbs, err = g.pdbLister.List(labels.Everything())
if err != nil {
return nil, nil, nil, err
}
}
// (3)获取可以被抢占的node节点列表;
nodeToVictims, err := g.selectNodesForPreemption(ctx, state, pod, potentialNodes, pdbs)
if err != nil {
return nil, nil, nil, err
}
// (4)遍历scheduler-extender(kube-scheduler的一种webhook扩展机制),执行extender的抢占处理逻辑,根据处理逻辑过滤可以被抢占的node节点列表;
// We will only check nodeToVictims with extenders that support preemption.
// Extenders which do not support preemption may later prevent preemptor from being scheduled on the nominated
// node. In that case, scheduler will find a different host for the preemptor in subsequent scheduling cycles.
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
if err != nil {
return nil, nil, nil, err
}
// (5)从可被抢占的node节点列表中挑选出一个node节点;
candidateNode := pickOneNodeForPreemption(nodeToVictims)
if candidateNode == nil {
return nil, nil, nil, nil
}
// (6)获取被抢占node节点上nominateName属性不为空且优先级比抢占pod低的pod列表;
// Lower priority pods nominated to run on this node, may no longer fit on
// this node. So, we should remove their nomination. Removing their
// nomination updates these pods and moves them to the active queue. It
// lets scheduler find another place for them.
nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name)
if nodeInfo, ok := g.nodeInfoSnapshot.NodeInfoMap[candidateNode.Name]; ok {
return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
return nil, nil, nil, fmt.Errorf(
"preemption failed: the target node %s has been deleted from scheduler cache",
candidateNode.Name)
}
3.1 nodesWherePreemptionMightHelp
nodesWherePreemptionMightHelp函数主要是返回预选失败且移除部分pod之后可能可以满足调度条件的节点。
怎么判断某个预选失败的node节点移除部分pod之后可能可以满足调度条件呢?主要逻辑看到predicates.UnresolvablePredicateExists方法。
// pkg/scheduler/core/generic_scheduler.go
func nodesWherePreemptionMightHelp(nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo, fitErr *FitError) []*v1.Node {
potentialNodes := []*v1.Node{}
for name, node := range nodeNameToInfo {
if fitErr.FilteredNodesStatuses[name].Code() == framework.UnschedulableAndUnresolvable {
continue
}
failedPredicates := fitErr.FailedPredicates[name]
// If we assume that scheduler looks at all nodes and populates the failedPredicateMap
// (which is the case today), the !found case should never happen, but we'd prefer
// to rely less on such assumptions in the code when checking does not impose
// significant overhead.
// Also, we currently assume all failures returned by extender as resolvable.
if predicates.UnresolvablePredicateExists(failedPredicates) == nil {
klog.V(3).Infof("Node %v is a potential node for preemption.", name)
potentialNodes = append(potentialNodes, node.Node())
}
}
return potentialNodes
}
3.1.1 predicates.UnresolvablePredicateExists
只要预选算法执行失败的node节点,其失败的原因不属于unresolvablePredicateFailureErrors中任何一个原因时,则该预选失败的node节点移除部分pod之后可能可以满足调度条件。
unresolvablePredicateFailureErrors包括节点NodeSelector不匹配、pod反亲和规则不符合、污点不容忍、节点属于NotReady状态、节点内存不足等等。
// pkg/scheduler/algorithm/predicates/error.go
var unresolvablePredicateFailureErrors = map[PredicateFailureReason]struct{}{
ErrNodeSelectorNotMatch: {},
ErrPodAffinityRulesNotMatch: {},
ErrPodNotMatchHostName: {},
ErrTaintsTolerationsNotMatch: {},
ErrNodeLabelPresenceViolated: {},
// Node conditions won't change when scheduler simulates removal of preemption victims.
// So, it is pointless to try nodes that have not been able to host the pod due to node
// conditions. These include ErrNodeNotReady, ErrNodeUnderPIDPressure, ErrNodeUnderMemoryPressure, ....
ErrNodeNotReady: {},
ErrNodeNetworkUnavailable: {},
ErrNodeUnderDiskPressure: {},
ErrNodeUnderPIDPressure: {},
ErrNodeUnderMemoryPressure: {},
ErrNodeUnschedulable: {},
ErrNodeUnknownCondition: {},
ErrVolumeZoneConflict: {},
ErrVolumeNodeConflict: {},
ErrVolumeBindConflict: {},
}
// UnresolvablePredicateExists checks if there is at least one unresolvable predicate failure reason, if true
// returns the first one in the list.
func UnresolvablePredicateExists(reasons []PredicateFailureReason) PredicateFailureReason {
for _, r := range reasons {
if _, ok := unresolvablePredicateFailureErrors[r]; ok {
return r
}
}
return nil
}
3.2 g.selectNodesForPreemption
g.selectNodesForPreemption方法,用于获取可以被抢占的node节点列表,并返回node节点上被抢占的pod的最小集合,主要逻辑如下:
(1)定义checkNode函数,主要是调用g.selectVictimsOnNode方法,方法返回某node是否适合被抢占,并返回该node节点上被抢占的pod的最小集合、被抢占pod中定义了PDB的pod数量;
(2)拉起16个goroutine,并发调用checkNode函数,对预选失败的node节点列表进行是否适合被抢占的检查;
// pkg/scheduler/core/generic_scheduler.go
// selectNodesForPreemption finds all the nodes with possible victims for
// preemption in parallel.
func (g *genericScheduler) selectNodesForPreemption(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
potentialNodes []*v1.Node,
pdbs []*policy.PodDisruptionBudget,
) (map[*v1.Node]*extenderv1.Victims, error) {
nodeToVictims := map[*v1.Node]*extenderv1.Victims{}
var resultLock sync.Mutex
// (1)定义checkNode函数
// We can use the same metadata producer for all nodes.
meta := g.predicateMetaProducer(pod, g.nodeInfoSnapshot)
checkNode := func(i int) {
nodeName := potentialNodes[i].Name
if g.nodeInfoSnapshot.NodeInfoMap[nodeName] == nil {
return
}
nodeInfoCopy := g.nodeInfoSnapshot.NodeInfoMap[nodeName].Clone()
var metaCopy predicates.Metadata
if meta != nil {
metaCopy = meta.ShallowCopy()
}
stateCopy := state.Clone()
stateCopy.Write(migration.PredicatesStateKey, &migration.PredicatesStateData{Reference: metaCopy})
// 调用g.selectVictimsOnNode方法,方法返回某node是否适合被抢占,并返回该node节点上被抢占的pod的最小集合、与PDB冲突的pod数量;
pods, numPDBViolations, fits := g.selectVictimsOnNode(ctx, stateCopy, pod, metaCopy, nodeInfoCopy, pdbs)
if fits {
resultLock.Lock()
victims := extenderv1.Victims{
Pods: pods,
NumPDBViolations: int64(numPDBViolations),
}
nodeToVictims[potentialNodes[i]] = &victims
resultLock.Unlock()
}
}
// (2)拉起16个goroutine,并发调用checkNode函数,对预选失败的node节点列表进行是否适合被抢占的检查;
workqueue.ParallelizeUntil(context.TODO(), 16, len(potentialNodes), checkNode)
return nodeToVictims, nil
}
3.2.1 g.selectVictimsOnNode
g.selectVictimsOnNode方法用于判断某node是否适合被抢占,并返回该node节点上被抢占的pod的最小集合、被抢占pod中定义了PDB的pod数量。
主要逻辑:
(1)首先,假设把该node节点上比抢占pod优先级低的所有pod都删除掉,然后调用预选算法,看pod在该node上是否满足调度条件,假如还是不符合调度条件,则该node节点不适合被抢占,直接return;
(2)将所有比抢占pod优先级低的pod按优先级高低进行排序,优先级最低的排在最前面;
(3)将排好序的pod列表按是否定义了PDB分成两个pod列表;
(4)先遍历定义了PDB的pod列表,逐一删除pod(被删除的pod称为被抢占pod),每删除一个pod,调度预选算法,看pod在该node上是否满足调度条件,如满足则直接返回该node适合被抢占、被抢占的pod列表、被抢占pod中定义了PDB的pod数量;
(5)假如遍历完定义了PDB的pod列表后,抢占pod在该node上任然不满足调度条件,则继续遍历没有定义PDB的pod列表,逐一删除pod,每删除一个pod,调度预选算法,看pod在该node上是否满足调度条件,如满足则直接返回该node适合被抢占、被抢占的pod列表、被抢占pod中定义了PDB的pod数量;
(6)如果上述两个pod列表里的pod都被删除后,抢占pod在该node上任然不满足调度条件,则该node不适合被抢占,return。
注意:以上说的删除pod并不是真正的删除,而是模拟删除后,抢占pod是否满足调度条件而已。真正的删除被抢占pod的操作在后续确定了要抢占的node节点后,再删除该node节点上被抢占的pod。
// pkg/scheduler/core/generic_scheduler.go
func (g *genericScheduler) selectVictimsOnNode(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
meta predicates.Metadata,
nodeInfo *schedulernodeinfo.NodeInfo,
pdbs []*policy.PodDisruptionBudget,
) ([]*v1.Pod, int, bool) {
var potentialVictims []*v1.Pod
removePod := func(rp *v1.Pod) error {
if err := nodeInfo.RemovePod(rp); err != nil {
return err
}
if meta != nil {
if err := meta.RemovePod(rp, nodeInfo.Node()); err != nil {
return err
}
}
status := g.framework.RunPreFilterExtensionRemovePod(ctx, state, pod, rp, nodeInfo)
if !status.IsSuccess() {
return status.AsError()
}
return nil
}
addPod := func(ap *v1.Pod) error {
nodeInfo.AddPod(ap)
if meta != nil {
if err := meta.AddPod(ap, nodeInfo.Node()); err != nil {
return err
}
}
status := g.framework.RunPreFilterExtensionAddPod(ctx, state, pod, ap, nodeInfo)
if !status.IsSuccess() {
return status.AsError()
}
return nil
}
// (1)首先,假设把该node节点上比抢占pod优先级低的所有pod都删除掉,然后调用预选算法,看pod在该node上是否满足调度条件,假如还是不符合调度条件,则该node节点不适合被抢占,直接return
// As the first step, remove all the lower priority pods from the node and
// check if the given pod can be scheduled.
podPriority := podutil.GetPodPriority(pod)
for _, p := range nodeInfo.Pods() {
if podutil.GetPodPriority(p) < podPriority {
potentialVictims = append(potentialVictims, p)
if err := removePod(p); err != nil {
return nil, 0, false
}
}
}
// If the new pod does not fit after removing all the lower priority pods,
// we are almost done and this node is not suitable for preemption. The only
// condition that we could check is if the "pod" is failing to schedule due to
// inter-pod affinity to one or more victims, but we have decided not to
// support this case for performance reasons. Having affinity to lower
// priority pods is not a recommended configuration anyway.
if fits, _, _, err := g.podFitsOnNode(ctx, state, pod, meta, nodeInfo, false); !fits {
if err != nil {
klog.Warningf("Encountered error while selecting victims on node %v: %v", nodeInfo.Node().Name, err)
}
return nil, 0, false
}
var victims []*v1.Pod
numViolatingVictim := 0
// (2)将所有比抢占pod优先级低的pod按优先级高低进行排序,优先级最低的排在最前面;
sort.Slice(potentialVictims, func(i, j int) bool { return util.MoreImportantPod(potentialVictims[i], potentialVictims[j]) })
// Try to reprieve as many pods as possible. We first try to reprieve the PDB
// violating victims and then other non-violating ones. In both cases, we start
// from the highest priority victims.
// (3)将排好序的pod列表按是否定义了PDB分成两个pod列表;
violatingVictims, nonViolatingVictims := filterPodsWithPDBViolation(potentialVictims, pdbs)
reprievePod := func(p *v1.Pod) (bool, error) {
if err := addPod(p); err != nil {
return false, err
}
fits, _, _, _ := g.podFitsOnNode(ctx, state, pod, meta, nodeInfo, false)
if !fits {
if err := removePod(p); err != nil {
return false, err
}
victims = append(victims, p)
klog.V(5).Infof("Pod %v/%v is a potential preemption victim on node %v.", p.Namespace, p.Name, nodeInfo.Node().Name)
}
return fits, nil
}
// (4)先遍历定义了PDB的pod列表,逐一删除pod(被删除的pod称为被抢占pod),每删除一个pod,调度预选算法,看pod在该node上是否满足调度条件,如满足则直接返回该node适合被抢占、被抢占的pod列表、被抢占pod中定义了PDB的pod数量;
for _, p := range violatingVictims {
if fits, err := reprievePod(p); err != nil {
klog.Warningf("Failed to reprieve pod %q: %v", p.Name, err)
return nil, 0, false
} else if !fits {
numViolatingVictim++
}
}
// (5)假如遍历完定义了PDB的pod列表后,抢占pod在该node上任然不满足调度条件,则继续遍历没有定义PDB的pod列表,逐一删除pod,每删除一个pod,调度预选算法,看pod在该node上是否满足调度条件,如满足则直接返回该node适合被抢占、被抢占的pod列表、被抢占pod中定义了PDB的pod数量;
// Now we try to reprieve non-violating victims.
for _, p := range nonViolatingVictims {
if _, err := reprievePod(p); err != nil {
klog.Warningf("Failed to reprieve pod %q: %v", p.Name, err)
return nil, 0, false
}
}
// (6)如果上述两个pod列表里的pod都被删除后,抢占pod在该node上任然不满足调度条件,则该node不适合被抢占,return。
return victims, numViolatingVictim, true
}
3.3 pickOneNodeForPreemption
pickOneNodeForPreemption函数,从可被抢占的node节点列表中挑选出一个node节点,该函数将按顺序参照下列规则来挑选最优的被抢占node,直到某个条件能够选出唯一的一个node节点:
(1)node节点没有被抢占pod的,优先选择;
(2)被抢占pod中定义了PDB的pod数量最少的节点;
(3)高优先级pod数量最少的节点;
(4)对node节点上所有被抢占pod的优先级进行相加,选取其值最小的节点;
(5)选择被抢占pod数量最少的node节点;
(6)选择被抢占pod中运行时间最短的pod所在node节点;
(7)返回符合上述条件的最后一个node节点;
// pkg/scheduler/core/generic_scheduler.go
func pickOneNodeForPreemption(nodesToVictims map[*v1.Node]*extenderv1.Victims) *v1.Node {
if len(nodesToVictims) == 0 {
return nil
}
minNumPDBViolatingPods := int64(math.MaxInt32)
var minNodes1 []*v1.Node
lenNodes1 := 0
for node, victims := range nodesToVictims {
// (1)node节点没有被抢占pod的,优先选择
if len(victims.Pods) == 0 {
// We found a node that doesn't need any preemption. Return it!
// This should happen rarely when one or more pods are terminated between
// the time that scheduler tries to schedule the pod and the time that
// preemption logic tries to find nodes for preemption.
return node
}
//(2)与PDB冲突的pod数量最少的节点
numPDBViolatingPods := victims.NumPDBViolations
if numPDBViolatingPods < minNumPDBViolatingPods {
minNumPDBViolatingPods = numPDBViolatingPods
minNodes1 = nil
lenNodes1 = 0
}
if numPDBViolatingPods == minNumPDBViolatingPods {
minNodes1 = append(minNodes1, node)
lenNodes1++
}
}
if lenNodes1 == 1 {
return minNodes1[0]
}
// (3)高优先级pod数量最少的节点
// There are more than one node with minimum number PDB violating pods. Find
// the one with minimum highest priority victim.
minHighestPriority := int32(math.MaxInt32)
var minNodes2 = make([]*v1.Node, lenNodes1)
lenNodes2 := 0
for i := 0; i < lenNodes1; i++ {
node := minNodes1[i]
victims := nodesToVictims[node]
// highestPodPriority is the highest priority among the victims on this node.
highestPodPriority := podutil.GetPodPriority(victims.Pods[0])
if highestPodPriority < minHighestPriority {
minHighestPriority = highestPodPriority
lenNodes2 = 0
}
if highestPodPriority == minHighestPriority {
minNodes2[lenNodes2] = node
lenNodes2++
}
}
if lenNodes2 == 1 {
return minNodes2[0]
}
// (4)对node节点上所有被抢占pod的优先级进行相加,选取其值最小的节点
// There are a few nodes with minimum highest priority victim. Find the
// smallest sum of priorities.
minSumPriorities := int64(math.MaxInt64)
lenNodes1 = 0
for i := 0; i < lenNodes2; i++ {
var sumPriorities int64
node := minNodes2[i]
for _, pod := range nodesToVictims[node].Pods {
// We add MaxInt32+1 to all priorities to make all of them >= 0. This is
// needed so that a node with a few pods with negative priority is not
// picked over a node with a smaller number of pods with the same negative
// priority (and similar scenarios).
sumPriorities += int64(podutil.GetPodPriority(pod)) + int64(math.MaxInt32+1)
}
if sumPriorities < minSumPriorities {
minSumPriorities = sumPriorities
lenNodes1 = 0
}
if sumPriorities == minSumPriorities {
minNodes1[lenNodes1] = node
lenNodes1++
}
}
if lenNodes1 == 1 {
return minNodes1[0]
}
// (5)选择被抢占pod数量最少的node节点;
// There are a few nodes with minimum highest priority victim and sum of priorities.
// Find one with the minimum number of pods.
minNumPods := math.MaxInt32
lenNodes2 = 0
for i := 0; i < lenNodes1; i++ {
node := minNodes1[i]
numPods := len(nodesToVictims[node].Pods)
if numPods < minNumPods {
minNumPods = numPods
lenNodes2 = 0
}
if numPods == minNumPods {
minNodes2[lenNodes2] = node
lenNodes2++
}
}
if lenNodes2 == 1 {
return minNodes2[0]
}
// (6)选择被抢占pod中运行时间最短的pod所在node节点;
// There are a few nodes with same number of pods.
// Find the node that satisfies latest(earliestStartTime(all highest-priority pods on node))
latestStartTime := util.GetEarliestPodStartTime(nodesToVictims[minNodes2[0]])
if latestStartTime == nil {
// If the earliest start time of all pods on the 1st node is nil, just return it,
// which is not expected to happen.
klog.Errorf("earliestStartTime is nil for node %s. Should not reach here.", minNodes2[0])
return minNodes2[0]
}
nodeToReturn := minNodes2[0]
for i := 1; i < lenNodes2; i++ {
node := minNodes2[i]
// Get earliest start time of all pods on the current node.
earliestStartTimeOnNode := util.GetEarliestPodStartTime(nodesToVictims[node])
if earliestStartTimeOnNode == nil {
klog.Errorf("earliestStartTime is nil for node %s. Should not reach here.", node)
continue
}
if earliestStartTimeOnNode.After(latestStartTime.Time) {
latestStartTime = earliestStartTimeOnNode
nodeToReturn = node
}
}
// (7)返回符合上述条件的最后一个node节点
return nodeToReturn
}
总结
kube-scheduler简介
kube-scheduler组件是kubernetes中的核心组件之一,主要负责pod资源对象的调度工作,具体来说,kube-scheduler组件负责根据调度算法(包括预选算法和优选算法)将未调度的pod调度到合适的最优的node节点上。
kube-scheduler架构图
kube-scheduler的大致组成和处理流程如下图,kube-scheduler对pod、node等对象进行了list/watch,根据informer将未调度的pod放入待调度pod队列,并根据informer构建调度器cache(用于快速获取需要的node等对象),然后sched.scheduleOne方法为kube-scheduler组件调度pod的核心处理逻辑所在,从未调度pod队列中取出一个pod,经过预选与优选算法,最终选出一个最优node,上述步骤都成功则更新cache并异步执行bind操作,也就是更新pod的nodeName字段,失败则进入抢占逻辑,至此一个pod的调度工作完成。
kube-scheduler抢占调度概述
优先级和抢占机制,解决的是 Pod 调度失败时该怎么办的问题。
正常情况下,当一个 pod 调度失败后,就会被暂时 “搁置” 处于 pending 状态,直到 pod 被更新或者集群状态发生变化,调度器才会对这个 pod 进行重新调度。
但是有的时候,我们希望给pod分等级,即分优先级。当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod,这样一来就可以保证高优先级 Pod 会优先调度成功。
抢占发生的原因,一定是一个高优先级的 pod 调度失败,我们称这个 pod 为“抢占者”,称被抢占的 pod 为“牺牲者”(victims)。
kube-scheduler抢占逻辑流程图
下方处理流程图展示了kube-scheduler抢占逻辑的核心处理步骤,在开始抢占逻辑处理之前,会先进行抢占调度功能是否开启的判断。