
k8s replicaset controller源码分析(2)-核心处理逻辑分析
replicaset controller分析
replicaset controller简介
replicaset controller是kube-controller-manager组件中众多控制器中的一个,是 replicaset 资源对象的控制器,其通过对replicaset、pod 2种资源的监听,当这2种资源发生变化时会触发 replicaset controller 对相应的replicaset对象进行调谐操作,从而完成replicaset期望副本数的调谐,当实际pod的数量未达到预期时创建pod,当实际pod的数量超过预期时删除pod。
replicaset controller主要作用是根据replicaset对象所期望的pod数量与现存pod数量做比较,然后根据比较结果创建/删除pod,最终使得replicaset对象所期望的pod数量与现存pod数量相等。
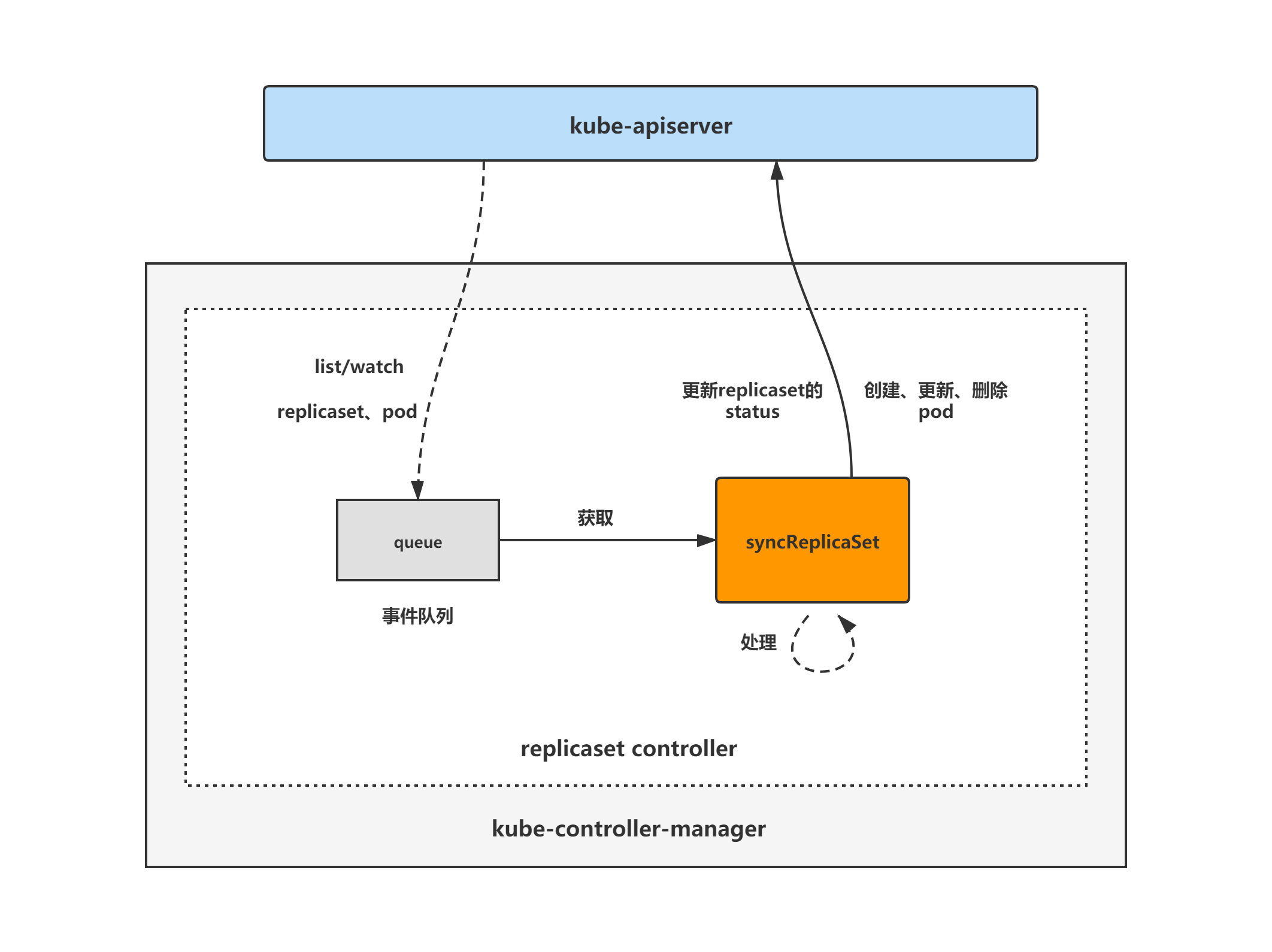
replicaset controller架构图
replicaset controller的大致组成和处理流程如下图,replicaset controller对pod和replicaset对象注册了event handler,当有事件时,会watch到然后将对应的replicaset对象放入到queue中,然后syncReplicaSet方法为replicaset controller调谐replicaset对象的核心处理逻辑所在,从queue中取出replicaset对象,做调谐处理。
replicaset controller分析分为3大块进行,分别是:
(1)replicaset controller初始化和启动分析;
(2)replicaset controller核心处理逻辑分析;
(3)replicaset controller expectations机制分析。
本篇博客进行replicaset controller核心处理逻辑分析。
replicaset controller核心处理逻辑分析
基于v1.17.4
经过前面分析的replicaset controller的初始化与启动,知道了replicaset controller监听replicaset、pod对象的add、update与delete事件,然后对replicaset对象做相应的调谐处理,这里来接着分析replicaset controller的调谐处理(核心处理)逻辑,从rsc.syncHandler作为入口进行分析。
rsc.syncHandler
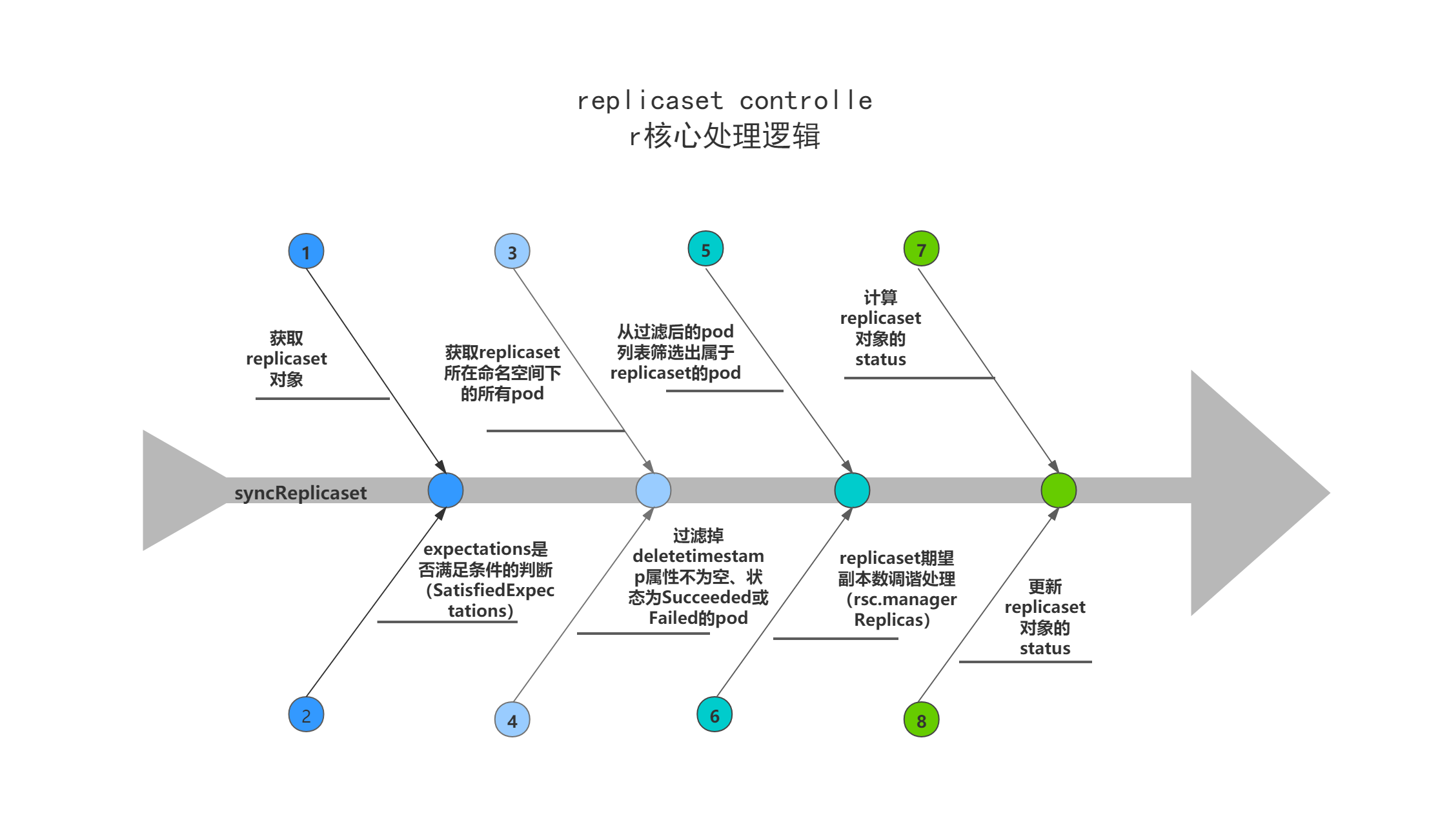
rsc.syncHandler即rsc.syncReplicaSet方法,主要逻辑:
(1)获取replicaset对象以及关联的pod对象列表;
(2)调用rsc.expectations.SatisfiedExpectations,判断上一轮对replicaset期望副本的创删操作是否完成,也可以认为是判断上一次对replicaset对象的调谐操作中,调用的rsc.manageReplicas方法是否执行完成;
(3)如果上一轮对replicaset期望副本的创删操作已经完成,且replicaset对象的DeletionTimestamp字段为nil,则调用rsc.manageReplicas做replicaset期望副本的核心调谐处理,即创删pod;
(4)调用calculateStatus计算replicaset的status,并更新。
// syncReplicaSet will sync the ReplicaSet with the given key if it has had its expectations fulfilled,
// meaning it did not expect to see any more of its pods created or deleted. This function is not meant to be
// invoked concurrently with the same key.
func (rsc *ReplicaSetController) syncReplicaSet(key string) error {
startTime := time.Now()
defer func() {
klog.V(4).Infof("Finished syncing %v %q (%v)", rsc.Kind, key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(4).Infof("%v %v has been deleted", rsc.Kind, key)
rsc.expectations.DeleteExpectations(key)
return nil
}
if err != nil {
return err
}
rsNeedsSync := rsc.expectations.SatisfiedExpectations(key)
selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector)
if err != nil {
utilruntime.HandleError(fmt.Errorf("error converting pod selector to selector: %v", err))
return nil
}
// list all pods to include the pods that don't match the rs`s selector
// anymore but has the stale controller ref.
// TODO: Do the List and Filter in a single pass, or use an index.
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
if err != nil {
return err
}
// Ignore inactive pods.
filteredPods := controller.FilterActivePods(allPods)
// NOTE: filteredPods are pointing to objects from cache - if you need to
// modify them, you need to copy it first.
filteredPods, err = rsc.claimPods(rs, selector, filteredPods)
if err != nil {
return err
}
var manageReplicasErr error
if rsNeedsSync && rs.DeletionTimestamp == nil {
manageReplicasErr = rsc.manageReplicas(filteredPods, rs)
}
rs = rs.DeepCopy()
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
// Always updates status as pods come up or die.
updatedRS, err := updateReplicaSetStatus(rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
if err != nil {
// Multiple things could lead to this update failing. Requeuing the replica set ensures
// Returning an error causes a requeue without forcing a hotloop
return err
}
// Resync the ReplicaSet after MinReadySeconds as a last line of defense to guard against clock-skew.
if manageReplicasErr == nil && updatedRS.Spec.MinReadySeconds > 0 &&
updatedRS.Status.ReadyReplicas == *(updatedRS.Spec.Replicas) &&
updatedRS.Status.AvailableReplicas != *(updatedRS.Spec.Replicas) {
rsc.queue.AddAfter(key, time.Duration(updatedRS.Spec.MinReadySeconds)*time.Second)
}
return manageReplicasErr
}
1 rsc.expectations.SatisfiedExpectations
该方法主要是判断上一轮对replicaset期望副本的创删操作是否完成,也可以认为是判断上一次对replicaset对象的调谐操作中,调用的rsc.manageReplicas方法是否执行完成。待上一次创建删除pod的操作完成后,才能进行下一次的rsc.manageReplicas方法调用。
若某replicaset对象的调谐中从未调用过rsc.manageReplicas方法,或上一轮调谐时创建/删除pod的数量已达成或调用rsc.manageReplicas后已达到超时期限(超时时间5分钟),则返回true,代表上一次创建删除pod的操作完成,可以进行下一次的rsc.manageReplicas方法调用,否则返回false。
expectations记录了replicaset对象在某一次调谐中期望创建/删除的pod数量,pod创建/删除完成后,该期望数会相应的减少,当期望创建/删除的pod数量小于等于0时,说明上一次调谐中期望创建/删除的pod数量已经达到,返回true。
关于Expectations机制后面会做详细分析。
// pkg/controller/controller_utils.go
func (r *ControllerExpectations) SatisfiedExpectations(controllerKey string) bool {
if exp, exists, err := r.GetExpectations(controllerKey); exists {
if exp.Fulfilled() {
klog.V(4).Infof("Controller expectations fulfilled %#v", exp)
return true
} else if exp.isExpired() {
klog.V(4).Infof("Controller expectations expired %#v", exp)
return true
} else {
klog.V(4).Infof("Controller still waiting on expectations %#v", exp)
return false
}
} else if err != nil {
klog.V(2).Infof("Error encountered while checking expectations %#v, forcing sync", err)
} else {
// When a new controller is created, it doesn't have expectations.
// When it doesn't see expected watch events for > TTL, the expectations expire.
// - In this case it wakes up, creates/deletes controllees, and sets expectations again.
// When it has satisfied expectations and no controllees need to be created/destroyed > TTL, the expectations expire.
// - In this case it continues without setting expectations till it needs to create/delete controllees.
klog.V(4).Infof("Controller %v either never recorded expectations, or the ttl expired.", controllerKey)
}
// Trigger a sync if we either encountered and error (which shouldn't happen since we're
// getting from local store) or this controller hasn't established expectations.
return true
}
func (exp *ControlleeExpectations) isExpired() bool {
return clock.RealClock{}.Since(exp.timestamp) > ExpectationsTimeout // ExpectationsTimeout = 5 * time.Minute
}
2 核心创建删除pod方法-rsc.manageReplicas
核心创建删除pod方法,主要是根据replicaset所期望的pod数量与现存pod数量做比较,然后根据比较结果来创建/删除pod,最终使得replicaset对象所期望的pod数量与现存pod数量相等,需要特别注意的是,每一次调用rsc.manageReplicas方法,创建/删除pod的个数上限为500。
在replicaset对象的调谐中,rsc.manageReplicas方法不一定每一次都会调用执行,只有当rsc.expectations.SatisfiedExpectations方法返回true,且replicaset对象的DeletionTimestamp属性为空时,才会进行rsc.manageReplicas方法的调用。
先简单的看一下代码,代码后面会做详细的逻辑分析。
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) manageReplicas(filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("Couldn't get key for %v %#v: %v", rsc.Kind, rs, err))
return nil
}
if diff < 0 {
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
// TODO: Track UIDs of creates just like deletes. The problem currently
// is we'd need to wait on the result of a create to record the pod's
// UID, which would require locking *across* the create, which will turn
// into a performance bottleneck. We should generate a UID for the pod
// beforehand and store it via ExpectCreations.
rsc.expectations.ExpectCreations(rsKey, diff)
glog.V(2).Infof("Too few replicas for %v %s/%s, need %d, creating %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
// Batch the pod creates. Batch sizes start at SlowStartInitialBatchSize
// and double with each successful iteration in a kind of "slow start".
// This handles attempts to start large numbers of pods that would
// likely all fail with the same error. For example a project with a
// low quota that attempts to create a large number of pods will be
// prevented from spamming the API service with the pod create requests
// after one of its pods fails. Conveniently, this also prevents the
// event spam that those failures would generate.
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
boolPtr := func(b bool) *bool { return &b }
controllerRef := &metav1.OwnerReference{
APIVersion: rsc.GroupVersion().String(),
Kind: rsc.Kind,
Name: rs.Name,
UID: rs.UID,
BlockOwnerDeletion: boolPtr(true),
Controller: boolPtr(true),
}
err := rsc.podControl.CreatePodsWithControllerRef(rs.Namespace, &rs.Spec.Template, rs, controllerRef)
if err != nil && errors.IsTimeout(err) {
// Pod is created but its initialization has timed out.
// If the initialization is successful eventually, the
// controller will observe the creation via the informer.
// If the initialization fails, or if the pod keeps
// uninitialized for a long time, the informer will not
// receive any update, and the controller will create a new
// pod when the expectation expires.
return nil
}
return err
})
// Any skipped pods that we never attempted to start shouldn't be expected.
// The skipped pods will be retried later. The next controller resync will
// retry the slow start process.
if skippedPods := diff - successfulCreations; skippedPods > 0 {
glog.V(2).Infof("Slow-start failure. Skipping creation of %d pods, decrementing expectations for %v %v/%v", skippedPods, rsc.Kind, rs.Namespace, rs.Name)
for i := 0; i < skippedPods; i++ {
// Decrement the expected number of creates because the informer won't observe this pod
rsc.expectations.CreationObserved(rsKey)
}
}
return err
} else if diff > 0 {
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
glog.V(2).Infof("Too many replicas for %v %s/%s, need %d, deleting %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
// Choose which Pods to delete, preferring those in earlier phases of startup.
podsToDelete := getPodsToDelete(filteredPods, diff)
// Snapshot the UIDs (ns/name) of the pods we're expecting to see
// deleted, so we know to record their expectations exactly once either
// when we see it as an update of the deletion timestamp, or as a delete.
// Note that if the labels on a pod/rs change in a way that the pod gets
// orphaned, the rs will only wake up after the expectations have
// expired even if other pods are deleted.
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
errCh := make(chan error, diff)
var wg sync.WaitGroup
wg.Add(diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
if err := rsc.podControl.DeletePod(rs.Namespace, targetPod.Name, rs); err != nil {
// Decrement the expected number of deletes because the informer won't observe this deletion
podKey := controller.PodKey(targetPod)
glog.V(2).Infof("Failed to delete %v, decrementing expectations for %v %s/%s", podKey, rsc.Kind, rs.Namespace, rs.Name)
rsc.expectations.DeletionObserved(rsKey, podKey)
errCh <- err
}
}(pod)
}
wg.Wait()
select {
case err := <-errCh:
// all errors have been reported before and they're likely to be the same, so we'll only return the first one we hit.
if err != nil {
return err
}
default:
}
}
return nil
}
diff = 现存pod数量 - 期望的pod数量
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
(1)当现存pod数量比期望的少时,需要创建pod,进入创建pod的逻辑代码块。
(2)当现存pod数量比期望的多时,需要删除pod,进入删除pod的逻辑代码块。
一次同步操作中批量创建或删除pod的个数上限为rsc.burstReplicas,即500个。
// pkg/controller/replicaset/replica_set.go
const (
// Realistic value of the burstReplica field for the replica set manager based off
// performance requirements for kubernetes 1.0.
BurstReplicas = 500
// The number of times we retry updating a ReplicaSet's status.
statusUpdateRetries = 1
)
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
接下来分析一下创建/删除pod的逻辑代码块。
2.1 创建pod逻辑代码块
主要逻辑:
(1)运算获取需要创建的pod数量,并设置数量上限500;
(2)调用rsc.expectations.ExpectCreations,将本轮调谐期望创建的pod数量设置进expectations;
(3)调用slowStartBatch函数来对pod进行创建逻辑处理;
(4)调用slowStartBatch函数完成后,计算获取创建失败的pod的数量,然后调用相应次数的rsc.expectations.CreationObserved方法,减去本轮调谐中期望创建的pod数量。
为什么要减呢?因为expectations记录了replicaset对象在某一次调谐中期望创建/删除的pod数量,pod创建/删除完成后,replicaset controller会watch到pod的创建/删除事件,从而调用rsc.expectations.CreationObserved方法来使期望创建/删除的pod数量减少。当有相应数量的pod创建/删除失败后,replicaset controller是不会watch到相应的pod创建/删除事件的,所以必须把本轮调谐期望创建/删除的pod数量做相应的减法,否则本轮调谐中的期望创建/删除pod数量永远不可能小于等于0,这样的话,rsc.expectations.SatisfiedExpectations方法就只会等待expectations超时期限到达才会返回true了。
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
rsc.expectations.ExpectCreations(rsKey, diff)
glog.V(2).Infof("Too few replicas for %v %s/%s, need %d, creating %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
boolPtr := func(b bool) *bool { return &b }
controllerRef := &metav1.OwnerReference{
APIVersion: rsc.GroupVersion().String(),
Kind: rsc.Kind,
Name: rs.Name,
UID: rs.UID,
BlockOwnerDeletion: boolPtr(true),
Controller: boolPtr(true),
}
err := rsc.podControl.CreatePodsWithControllerRef(rs.Namespace, &rs.Spec.Template, rs, controllerRef)
if err != nil && errors.IsTimeout(err) {
// Pod is created but its initialization has timed out.
// If the initialization is successful eventually, the
// controller will observe the creation via the informer.
// If the initialization fails, or if the pod keeps
// uninitialized for a long time, the informer will not
// receive any update, and the controller will create a new
// pod when the expectation expires.
return nil
}
return err
})
if skippedPods := diff - successfulCreations; skippedPods > 0 {
glog.V(2).Infof("Slow-start failure. Skipping creation of %d pods, decrementing expectations for %v %v/%v", skippedPods, rsc.Kind, rs.Namespace, rs.Name)
for i := 0; i < skippedPods; i++ {
// Decrement the expected number of creates because the informer won't observe this pod
rsc.expectations.CreationObserved(rsKey)
}
}
return err
2.1.1 slowStartBatch
来看到slowStartBatch,可以看到创建pod的算法为:
(1)每次批量创建的 pod 数依次为 1、2、4、8......,呈指数级增长,起与要创建的pod数量相同的goroutine来负责创建pod。
(2)创建pod按1、2、4、8...的递增趋势分多批次进行,若某批次创建pod有失败的(如apiserver限流,丢弃请求等,注意:超时除外,因为initialization处理有可能超时),则后续批次不再进行,结束本次函数调用。
// pkg/controller/replicaset/replica_set.go
// slowStartBatch tries to call the provided function a total of 'count' times,
// starting slow to check for errors, then speeding up if calls succeed.
//
// It groups the calls into batches, starting with a group of initialBatchSize.
// Within each batch, it may call the function multiple times concurrently.
//
// If a whole batch succeeds, the next batch may get exponentially larger.
// If there are any failures in a batch, all remaining batches are skipped
// after waiting for the current batch to complete.
//
// It returns the number of successful calls to the function.
func slowStartBatch(count int, initialBatchSize int, fn func() error) (int, error) {
remaining := count
successes := 0
for batchSize := integer.IntMin(remaining, initialBatchSize); batchSize > 0; batchSize = integer.IntMin(2*batchSize, remaining) {
errCh := make(chan error, batchSize)
var wg sync.WaitGroup
wg.Add(batchSize)
for i := 0; i < batchSize; i++ {
go func() {
defer wg.Done()
if err := fn(); err != nil {
errCh <- err
}
}()
}
wg.Wait()
curSuccesses := batchSize - len(errCh)
successes += curSuccesses
if len(errCh) > 0 {
return successes, <-errCh
}
remaining -= batchSize
}
return successes, nil
}
rsc.podControl.CreatePodsWithControllerRef
前面定义的创建pod时调用的方法为rsc.podControl.CreatePodsWithControllerRef。
func (r RealPodControl) CreatePodsWithControllerRef(namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
if err := validateControllerRef(controllerRef); err != nil {
return err
}
return r.createPods("", namespace, template, controllerObject, controllerRef)
}
func (r RealPodControl) createPods(nodeName, namespace string, template *v1.PodTemplateSpec, object runtime.Object, controllerRef *metav1.OwnerReference) error {
pod, err := GetPodFromTemplate(template, object, controllerRef)
if err != nil {
return err
}
if len(nodeName) != 0 {
pod.Spec.NodeName = nodeName
}
if len(labels.Set(pod.Labels)) == 0 {
return fmt.Errorf("unable to create pods, no labels")
}
newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(pod)
if err != nil {
// only send an event if the namespace isn't terminating
if !apierrors.HasStatusCause(err, v1.NamespaceTerminatingCause) {
r.Recorder.Eventf(object, v1.EventTypeWarning, FailedCreatePodReason, "Error creating: %v", err)
}
return err
}
accessor, err := meta.Accessor(object)
if err != nil {
klog.Errorf("parentObject does not have ObjectMeta, %v", err)
return nil
}
klog.V(4).Infof("Controller %v created pod %v", accessor.GetName(), newPod.Name)
r.Recorder.Eventf(object, v1.EventTypeNormal, SuccessfulCreatePodReason, "Created pod: %v", newPod.Name)
return nil
}
2.2 删除逻辑代码块
主要逻辑:
(1)运算获取需要删除的pod数量,并设置数量上限500;
(2)根据要缩容删除的pod数量,先调用getPodsToDelete函数找出需要删除的pod列表;
(3)调用rsc.expectations.ExpectCreations,将本轮调谐期望删除的pod数量设置进expectations;
(4)每个pod拉起一个goroutine,调用rsc.podControl.DeletePod来删除该pod;
(5)对于删除失败的pod,会调用rsc.expectations.DeletionObserved方法,减去本轮调谐中期望创建的pod数量。
至于为什么要减,原因跟上面创建逻辑代码块中分析的一样。
(6)等待所有gorouutine完成,return返回。
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
glog.V(2).Infof("Too many replicas for %v %s/%s, need %d, deleting %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
// Choose which Pods to delete, preferring those in earlier phases of startup.
podsToDelete := getPodsToDelete(filteredPods, diff)
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
errCh := make(chan error, diff)
var wg sync.WaitGroup
wg.Add(diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
if err := rsc.podControl.DeletePod(rs.Namespace, targetPod.Name, rs); err != nil {
// Decrement the expected number of deletes because the informer won't observe this deletion
podKey := controller.PodKey(targetPod)
glog.V(2).Infof("Failed to delete %v, decrementing expectations for %v %s/%s", podKey, rsc.Kind, rs.Namespace, rs.Name)
rsc.expectations.DeletionObserved(rsKey, podKey)
errCh <- err
}
}(pod)
}
wg.Wait()
select {
case err := <-errCh:
// all errors have been reported before and they're likely to be the same, so we'll only return the first one we hit.
if err != nil {
return err
}
default:
}
2.2.1 getPodsToDelete
getPodsToDelete:根据要缩容删除的pod数量,然后返回需要删除的pod列表。
// pkg/controller/replicaset/replica_set.go
func getPodsToDelete(filteredPods, relatedPods []*v1.Pod, diff int) []*v1.Pod {
// No need to sort pods if we are about to delete all of them.
// diff will always be <= len(filteredPods), so not need to handle > case.
if diff < len(filteredPods) {
podsWithRanks := getPodsRankedByRelatedPodsOnSameNode(filteredPods, relatedPods)
sort.Sort(podsWithRanks)
}
return filteredPods[:diff]
}
func getPodsRankedByRelatedPodsOnSameNode(podsToRank, relatedPods []*v1.Pod) controller.ActivePodsWithRanks {
podsOnNode := make(map[string]int)
for _, pod := range relatedPods {
if controller.IsPodActive(pod) {
podsOnNode[pod.Spec.NodeName]++
}
}
ranks := make([]int, len(podsToRank))
for i, pod := range podsToRank {
ranks[i] = podsOnNode[pod.Spec.NodeName]
}
return controller.ActivePodsWithRanks{Pods: podsToRank, Rank: ranks}
}
筛选要删除的pod逻辑
按照下面的排序规则,从上到下进行排序,各个条件相互互斥,符合其中一个条件则排序完成:
(1)优先删除没有绑定node的pod;
(2)优先删除处于Pending状态的pod,然后是Unknown,最后才是Running;
(3)优先删除Not ready的pod,然后才是ready的pod;
(4)按同node上所属replicaset的pod数量排序,优先删除所属replicaset的pod数量多的node上的pod;
(5)按pod ready的时间排序,优先删除ready时间最短的pod;
(6)优先删除pod中容器重启次数较多的pod;
(7)按pod创建时间排序,优先删除创建时间最短的pod。
// pkg/controller/controller_utils.go
func (s ActivePodsWithRanks) Less(i, j int) bool {
// 1. Unassigned < assigned
// If only one of the pods is unassigned, the unassigned one is smaller
if s.Pods[i].Spec.NodeName != s.Pods[j].Spec.NodeName && (len(s.Pods[i].Spec.NodeName) == 0 || len(s.Pods[j].Spec.NodeName) == 0) {
return len(s.Pods[i].Spec.NodeName) == 0
}
// 2. PodPending < PodUnknown < PodRunning
if podPhaseToOrdinal[s.Pods[i].Status.Phase] != podPhaseToOrdinal[s.Pods[j].Status.Phase] {
return podPhaseToOrdinal[s.Pods[i].Status.Phase] < podPhaseToOrdinal[s.Pods[j].Status.Phase]
}
// 3. Not ready < ready
// If only one of the pods is not ready, the not ready one is smaller
if podutil.IsPodReady(s.Pods[i]) != podutil.IsPodReady(s.Pods[j]) {
return !podutil.IsPodReady(s.Pods[i])
}
// 4. Doubled up < not doubled up
// If one of the two pods is on the same node as one or more additional
// ready pods that belong to the same replicaset, whichever pod has more
// colocated ready pods is less
if s.Rank[i] != s.Rank[j] {
return s.Rank[i] > s.Rank[j]
}
// TODO: take availability into account when we push minReadySeconds information from deployment into pods,
// see https://github.com/kubernetes/kubernetes/issues/22065
// 5. Been ready for empty time < less time < more time
// If both pods are ready, the latest ready one is smaller
if podutil.IsPodReady(s.Pods[i]) && podutil.IsPodReady(s.Pods[j]) {
readyTime1 := podReadyTime(s.Pods[i])
readyTime2 := podReadyTime(s.Pods[j])
if !readyTime1.Equal(readyTime2) {
return afterOrZero(readyTime1, readyTime2)
}
}
// 6. Pods with containers with higher restart counts < lower restart counts
if maxContainerRestarts(s.Pods[i]) != maxContainerRestarts(s.Pods[j]) {
return maxContainerRestarts(s.Pods[i]) > maxContainerRestarts(s.Pods[j])
}
// 7. Empty creation time pods < newer pods < older pods
if !s.Pods[i].CreationTimestamp.Equal(&s.Pods[j].CreationTimestamp) {
return afterOrZero(&s.Pods[i].CreationTimestamp, &s.Pods[j].CreationTimestamp)
}
return false
}
2.2.2 rsc.podControl.DeletePod
删除pod的方法。
// pkg/controller/controller_utils.go
func (r RealPodControl) DeletePod(namespace string, podID string, object runtime.Object) error {
accessor, err := meta.Accessor(object)
if err != nil {
return fmt.Errorf("object does not have ObjectMeta, %v", err)
}
klog.V(2).Infof("Controller %v deleting pod %v/%v", accessor.GetName(), namespace, podID)
if err := r.KubeClient.CoreV1().Pods(namespace).Delete(podID, nil); err != nil && !apierrors.IsNotFound(err) {
r.Recorder.Eventf(object, v1.EventTypeWarning, FailedDeletePodReason, "Error deleting: %v", err)
return fmt.Errorf("unable to delete pods: %v", err)
}
r.Recorder.Eventf(object, v1.EventTypeNormal, SuccessfulDeletePodReason, "Deleted pod: %v", podID)
return nil
}
3 calculateStatus
calculateStatus函数计算并返回replicaset对象的status。
怎么计算status呢?
(1)根据现存pod数量、Ready状态的pod数量、availabel状态的pod数量等,给replicaset对象的status的Replicas、ReadyReplicas、AvailableReplicas等字段赋值;
(2)根据replicaset对象现有status中的condition配置以及前面调用rsc.manageReplicas方法后是否有错误,来决定给status新增condition或移除condition,conditionType为ReplicaFailure。
当调用rsc.manageReplicas方法出错,且replicaset对象的status中,没有conditionType为ReplicaFailure的condition,则新增conditionType为ReplicaFailure的condition,表示该replicaset创建/删除pod出错;
当调用rsc.manageReplicas方法没有任何错误,且replicaset对象的status中,有conditionType为ReplicaFailure的condition,则去除该condition,表示该replicaset创建/删除pod成功。
func calculateStatus(rs *apps.ReplicaSet, filteredPods []*v1.Pod, manageReplicasErr error) apps.ReplicaSetStatus {
newStatus := rs.Status
// Count the number of pods that have labels matching the labels of the pod
// template of the replica set, the matching pods may have more
// labels than are in the template. Because the label of podTemplateSpec is
// a superset of the selector of the replica set, so the possible
// matching pods must be part of the filteredPods.
fullyLabeledReplicasCount := 0
readyReplicasCount := 0
availableReplicasCount := 0
templateLabel := labels.Set(rs.Spec.Template.Labels).AsSelectorPreValidated()
for _, pod := range filteredPods {
if templateLabel.Matches(labels.Set(pod.Labels)) {
fullyLabeledReplicasCount++
}
if podutil.IsPodReady(pod) {
readyReplicasCount++
if podutil.IsPodAvailable(pod, rs.Spec.MinReadySeconds, metav1.Now()) {
availableReplicasCount++
}
}
}
failureCond := GetCondition(rs.Status, apps.ReplicaSetReplicaFailure)
if manageReplicasErr != nil && failureCond == nil {
var reason string
if diff := len(filteredPods) - int(*(rs.Spec.Replicas)); diff < 0 {
reason = "FailedCreate"
} else if diff > 0 {
reason = "FailedDelete"
}
cond := NewReplicaSetCondition(apps.ReplicaSetReplicaFailure, v1.ConditionTrue, reason, manageReplicasErr.Error())
SetCondition(&newStatus, cond)
} else if manageReplicasErr == nil && failureCond != nil {
RemoveCondition(&newStatus, apps.ReplicaSetReplicaFailure)
}
newStatus.Replicas = int32(len(filteredPods))
newStatus.FullyLabeledReplicas = int32(fullyLabeledReplicasCount)
newStatus.ReadyReplicas = int32(readyReplicasCount)
newStatus.AvailableReplicas = int32(availableReplicasCount)
return newStatus
}
4 updateReplicaSetStatus
主要逻辑:
(1)判断新计算出来的status中的各个属性如Replicas、ReadyReplicas、AvailableReplicas以及Conditions是否与现存replicaset对象的status中的一致,一致则不用做更新操作,直接return;
(2)调用c.UpdateStatus更新replicaset的status。
// pkg/controller/replicaset/replica_set_utils.go
func updateReplicaSetStatus(c appsclient.ReplicaSetInterface, rs *apps.ReplicaSet, newStatus apps.ReplicaSetStatus) (*apps.ReplicaSet, error) {
// This is the steady state. It happens when the ReplicaSet doesn't have any expectations, since
// we do a periodic relist every 30s. If the generations differ but the replicas are
// the same, a caller might've resized to the same replica count.
if rs.Status.Replicas == newStatus.Replicas &&
rs.Status.FullyLabeledReplicas == newStatus.FullyLabeledReplicas &&
rs.Status.ReadyReplicas == newStatus.ReadyReplicas &&
rs.Status.AvailableReplicas == newStatus.AvailableReplicas &&
rs.Generation == rs.Status.ObservedGeneration &&
reflect.DeepEqual(rs.Status.Conditions, newStatus.Conditions) {
return rs, nil
}
// Save the generation number we acted on, otherwise we might wrongfully indicate
// that we've seen a spec update when we retry.
// TODO: This can clobber an update if we allow multiple agents to write to the
// same status.
newStatus.ObservedGeneration = rs.Generation
var getErr, updateErr error
var updatedRS *apps.ReplicaSet
for i, rs := 0, rs; ; i++ {
klog.V(4).Infof(fmt.Sprintf("Updating status for %v: %s/%s, ", rs.Kind, rs.Namespace, rs.Name) +
fmt.Sprintf("replicas %d->%d (need %d), ", rs.Status.Replicas, newStatus.Replicas, *(rs.Spec.Replicas)) +
fmt.Sprintf("fullyLabeledReplicas %d->%d, ", rs.Status.FullyLabeledReplicas, newStatus.FullyLabeledReplicas) +
fmt.Sprintf("readyReplicas %d->%d, ", rs.Status.ReadyReplicas, newStatus.ReadyReplicas) +
fmt.Sprintf("availableReplicas %d->%d, ", rs.Status.AvailableReplicas, newStatus.AvailableReplicas) +
fmt.Sprintf("sequence No: %v->%v", rs.Status.ObservedGeneration, newStatus.ObservedGeneration))
rs.Status = newStatus
updatedRS, updateErr = c.UpdateStatus(rs)
if updateErr == nil {
return updatedRS, nil
}
// Stop retrying if we exceed statusUpdateRetries - the replicaSet will be requeued with a rate limit.
if i >= statusUpdateRetries {
break
}
// Update the ReplicaSet with the latest resource version for the next poll
if rs, getErr = c.Get(rs.Name, metav1.GetOptions{}); getErr != nil {
// If the GET fails we can't trust status.Replicas anymore. This error
// is bound to be more interesting than the update failure.
return nil, getErr
}
}
return nil, updateErr
}
c.UpdateStatus
// staging/src/k8s.io/client-go/kubernetes/typed/apps/v1/replicaset.go
func (c *replicaSets) UpdateStatus(replicaSet *v1.ReplicaSet) (result *v1.ReplicaSet, err error) {
result = &v1.ReplicaSet{}
err = c.client.Put().
Namespace(c.ns).
Resource("replicasets").
Name(replicaSet.Name).
SubResource("status").
Body(replicaSet).
Do().
Into(result)
return
}
总结
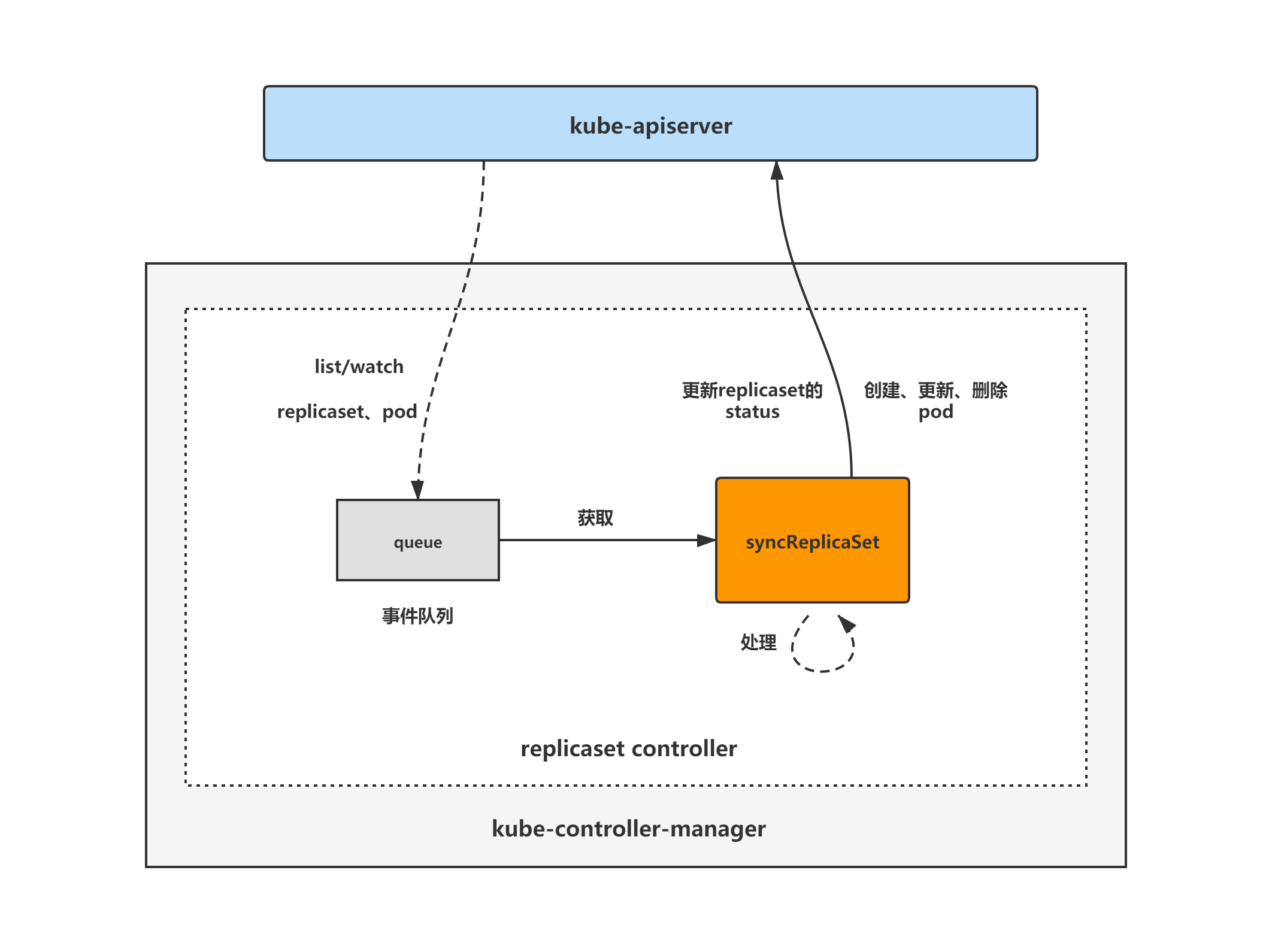
replicaset controller架构图
replicaset controller的大致组成和处理流程如下图,replicaset controller对pod和replicaset对象注册了event handler,当有事件时,会watch到然后将对应的replicaset对象放入到queue中,然后syncReplicaSet方法为replicaset controller调谐replicaset对象的核心处理逻辑所在,从queue中取出replicaset对象,做调谐处理。
replicaset controller核心处理逻辑
replicaset controller的核心处理逻辑是根据replicaset对象里期望的pod数量以及现存pod数量的比较,当期望pod数量比现存pod数量多时,调用创建pod算法创建出新的pod,直至达到期望数量;当期望pod数量比现存pod数量少时,调用删除pod算法,并根据一定的策略对现存pod列表做排序,从中按顺序选择多余的pod然后删除,直至达到期望数量。
replicaset controller创建pod算法
replicaset controller创建pod的算法是,按1、2、4、8...的递增趋势分多批次进行(每次调谐中创建pod的数量上限为500个,超过上限的会在下次调谐中再创建),若某批次创建pod有失败的(如apiserver限流,丢弃请求等,注意:超时除外,因为initialization处理有可能超时),则后续批次的pod创建不再进行,需等待该repliaset对象下次调谐时再触发该pod创建算法,进行pod的创建,直至达到期望数量。
replicaset controller删除pod算法
replicaset controller删除pod的算法是,先根据一定的策略将现存pod列表做排序,然后按顺序从中选择指定数量的pod,拉起与要删除的pod数量相同的goroutine来删除pod(每次调谐中删除pod的数量上限为500个),并等待所有goroutine执行完成。删除pod有失败的(如apiserver限流,丢弃请求)或超过500上限的部分,需等待该repliaset对象下次调谐时再触发该pod删除算法,进行pod的删除,直至达到期望数量。
筛选要删除的pod逻辑
按照下面的排序规则,从上到下进行排序,各个条件相互互斥,符合其中一个条件则排序完成:
(1)优先删除没有绑定node的pod;
(2)优先删除处于Pending状态的pod,然后是Unknown,最后才是Running;
(3)优先删除Not ready的pod,然后才是ready的pod;
(4)按同node上所属replicaset的pod数量排序,优先删除所属replicaset的pod数量多的node上的pod;
(5)按pod ready的时间排序,优先删除ready时间最短的pod;
(6)优先删除pod中容器重启次数较多的pod;
(7)按pod创建时间排序,优先删除创建时间最短的pod。
expectations机制
关于expectations机制的分析,会在下一篇博客中进行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号