Hadoop-2.7.5完全分布式搭建
1、在虚拟机上安装Hadoop完全分布式准备工作
1)这里使用的是VMWare软件,在VMWare上安装一个CentOS6.5,并再克隆两个机器配置相关MAC地址,以及配置机器名
2)三台虚拟机配置好静态IP以及网络环境,以及SSH免密码登录(自行参考资料)
3)安装Java环境(自行参考资料)
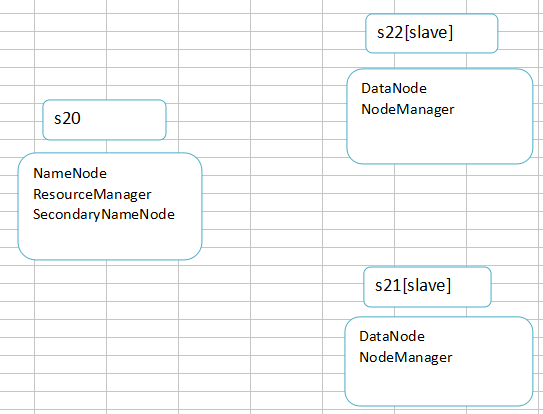
4)Hadoop完全分布式结构及拓扑
2、Hadoop相关配置
1)在apache官方网站上下载hadoop-2.7.5.tar.gz包
将下载好的gz包上传到s20机器上,解压到/opt/soft目录下
2)配置hadoop的环境变量
编辑/etc/profile文件,配置内容如下,编辑完成后使其生效 source /etc/profile
export HADOOP_HOME=/opt/soft/hadoop-2.7.5
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3)Hadoop配置文件
[core-site.xml]
3、启动
1)在一个节点上执行完上述配置操作之后将hadoop-2.7.5整个文件夹复制到其他两个节点的相同目录,并配置其他两个节点Hadoop环境变量
2)上述操作都完成之后,执行格式化
hdfs namenode -format
3)执行启动脚本
start-dfs.sh:启动hdfs
start-yarn.sh:启动yarn
4)分别查看进程,是否启动的进程与拓扑图中的一致,如果不一致则可能有进程没有启动成功,需要检查配置
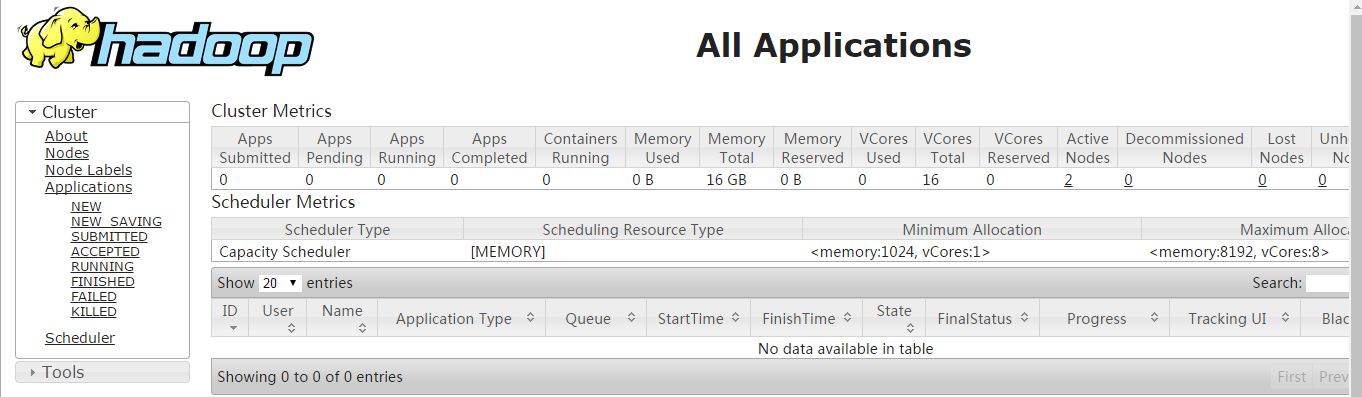
5)查看hdfs管理页面
http://192.168.137.120:50070

6)查看yarn管理页面
http://192.168.137.120:8088