第十一章:Python高级编程-协程和异步IO
第十一章:Python高级编程-协程和异步IO
Python3高级核心技术97讲 笔记
目录
- 第十一章:Python高级编程-协程和异步IO
- 11.1 并发、并行、同步、异步、阻塞、非阻塞
- 11.2 C10K问题和IO多路复用(select、poll、epoll)
- 11.2.1 C10K问题
- 11.2.2 Unix下五种I/O模型
- 11.3 select+回调+事件循环
- 11.4 回调之痛
- 11.5 什么是协程
- 11.5.1 C10M问题
- 11.5.2 协程
- 11.6 生成器进阶-send、close和throw方法
- 11.7生成器进阶-yield from
- 11.8 yield from how
- 11.9 async和await
- 11.10 生成器实现协程
11.1 并发、并行、同步、异步、阻塞、非阻塞
并发
并发是指一个时间段内,有几个程序在同一个CPU上运行,但是任意时刻只有一个程序在CPU上运行。
并行
并行是指任意时刻点上,有多个程序同时运行在多个CPU上。
同步
同步是指代码调用IO操作是,必须等待IO操作完成才返回的调用方式。
异步
异步是指代码调用IO操作是,不必等IO操作完成就返回的调用方式。
阻塞
阻塞是指调用函数时候当前线程被挂起。
非阻塞
阻塞是指调用函数时候当前线程不会被挂起,而是立即返回。
11.2 C10K问题和IO多路复用(select、poll、epoll)
11.2.1 C10K问题
如何在一颗1GHz CPU,2G内存,1gbps网络环境下,让单台服务器同时为一万个客户端提供FTP服务。
11.2.2 Unix下五种I/O模型
阻塞式IO

非阻塞IO

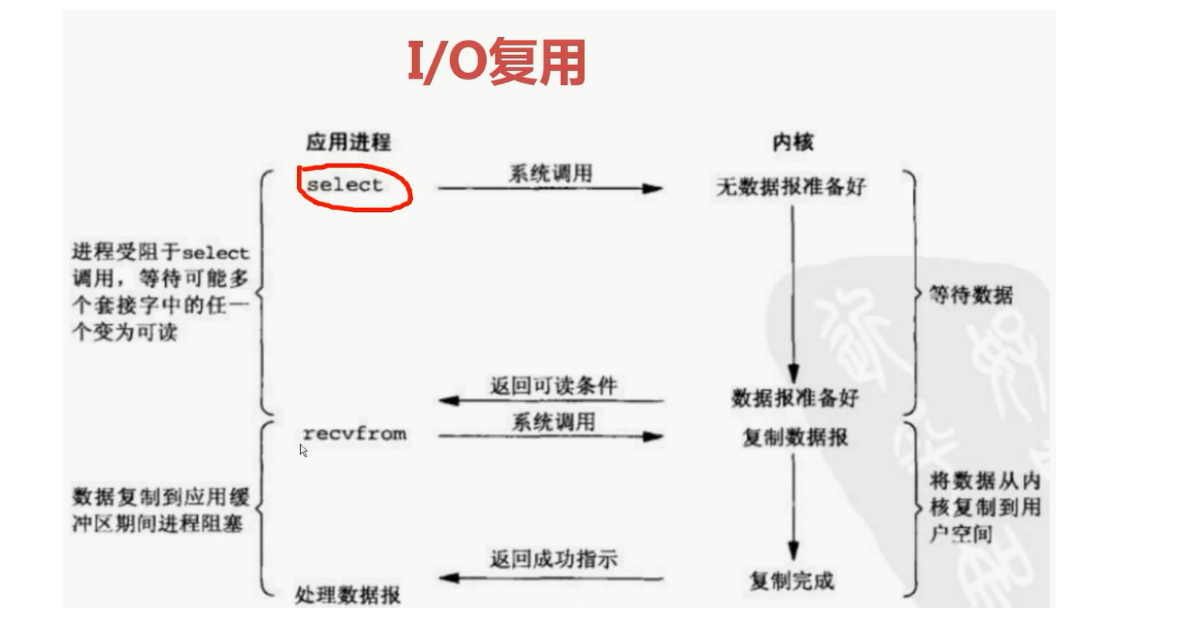
IO复用
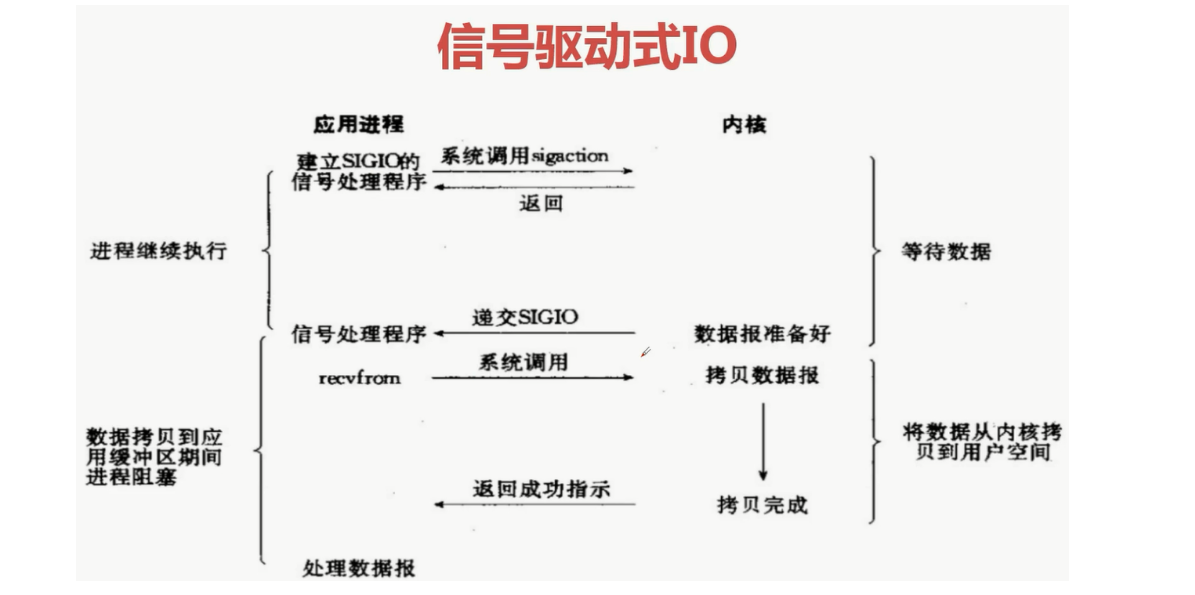
信息驱动式IO
异步IO(POSIX的aio_系列函数

select、poll、epoll
select、poll、epoll都是IO多路复用的机制。IO多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但是select、poll、epoll本质上都是同步IO,因为他们都需要在读写时间就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步IO则无需自己负责进行读写,异步IO的实现会负责把数据从内核拷贝到用户空间。
select
select函数监视的文件描述符分为3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是他的一个优点。select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll
不同于select使用三个位图来表示三个fdset的方式,pollshiyongyigepollfd的指针实现。
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。和select函数一样,poll返回后,需要伦轮询pollfd来获取就绪的描述符
从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
11.3 select+回调+事件循环
#1. epoll并不代表一定比select好
# 在并发高的情况下,连接活跃度不是很高, epoll比select
# 并发性不高,同时连接很活跃, select比epoll好
#通过非阻塞io实现http请求
import socket
from urllib.parse import urlparse
#使用非阻塞io完成http请求
def get_url(url):
#通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
#建立socket连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.setblocking(False)
try:
client.connect((host, 80)) #阻塞不会消耗cpu
except BlockingIOError as e:
pass
#不停的询问连接是否建立好, 需要while循环不停的去检查状态
#做计算任务或者再次发起其他的连接请求
while True:
try:
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
break
except OSError as e:
pass
data = b""
while True:
try:
d = client.recv(1024)
except BlockingIOError as e:
continue
if d:
data += d
else:
break
data = data.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
client.close()
if __name__ == "__main__":
get_url("http://www.baidu.com")
Copy#1. epoll并不代表一定比select好
# 在并发高的情况下,连接活跃度不是很高, epoll比select
# 并发性不高,同时连接很活跃, select比epoll好
#通过非阻塞io实现http请求
# select + 回调 + 事件循环
# 并发性高
# 使用单线程
import socket
from urllib.parse import urlparse
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE
selector = DefaultSelector()
#使用select完成http请求
urls = []
stop = False
class Fetcher:
def connected(self, key):
selector.unregister(key.fd)
self.client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(self.path, self.host).encode("utf8"))
selector.register(self.client.fileno(), EVENT_READ, self.readable)
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
self.client.close()
urls.remove(self.spider_url)
if not urls:
global stop
stop = True
def get_url(self, url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b""
if self.path == "":
self.path = "/"
# 建立socket连接
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80)) # 阻塞不会消耗cpu
except BlockingIOError as e:
pass
#注册
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
def loop():
#事件循环,不停的请求socket的状态并调用对应的回调函数
#1. select本身是不支持register模式
#2. socket状态变化以后的回调是由程序员完成的
while not stop:
ready = selector.select()
for key, mask in ready:
call_back = key.data
call_back(key)
#回调+事件循环+select(poll\epoll)
if __name__ == "__main__":
fetcher = Fetcher()
import time
start_time = time.time()
for url in range(20):
url = "http://shop.projectsedu.com/goods/{}/".format(url)
urls.append(url)
fetcher = Fetcher()
fetcher.get_url(url)
loop()
print(time.time()-start_time)
# def get_url(url):
# #通过socket请求html
# url = urlparse(url)
# host = url.netloc
# path = url.path
# if path == "":
# path = "/"
#
# #建立socket连接
# client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# client.setblocking(False)
# try:
# client.connect((host, 80)) #阻塞不会消耗cpu
# except BlockingIOError as e:
# pass
#
# #不停的询问连接是否建立好, 需要while循环不停的去检查状态
# #做计算任务或者再次发起其他的连接请求
#
# while True:
# try:
# client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
# break
# except OSError as e:
# pass
#
#
# data = b""
# while True:
# try:
# d = client.recv(1024)
# except BlockingIOError as e:
# continue
# if d:
# data += d
# else:
# break
#
# data = data.decode("utf8")
# html_data = data.split("\r\n\r\n")[1]
# print(html_data)
# client.close()
11.4 回调之痛
如果回调函数执行不正常该如何?
如果回调里面还要嵌套回调该怎么办?要嵌套很多层怎么办?
如果嵌套了多层,其中某个环节出错了会造成什么后果?
如果有个数据需要被每个回调都处理怎么办?
....
- 可读性差
- 共享状态管理困难
- 异常处理困难
11.5 什么是协程
11.5.1 C10M问题
如何利用8核心CPU,64G内存,在10gbps的网络上保持1000万并发连接
11.5.2 协程
# def get_url(url):
# #do someting 1
# html = get_html(url) #此处暂停,切换到另一个函数去执行
# # #parse html
# urls = parse_url(html)
#
# def get_url(url):
# #do someting 1
# html = get_html(url) #此处暂停,切换到另一个函数去执行
# # #parse html
# urls = parse_url(html)
#传统函数调用 过程 A->B->C
#我们需要一个可以暂停的函数,并且可以在适当的时候恢复该函数的继续执行
#出现了协程 -> 有多个入口的函数, 可以暂停的函数, 可以暂停的函数(可以向暂停的地方传入值)
11.6 生成器进阶-send、close和throw方法
def gen_func():
#1. 可以产出值, 2. 可以接收值(调用方传递进来的值)
html = yield "http://projectsedu.com"
print(html)
return "bobby"
#1. throw, close
#1. 生成器不只可以产出值,还可以接收值
if __name__ == "__main__":
gen = gen_func()
#在调用send发送非none值之前,我们必须启动一次生成器, 方式有两种1. gen.send(None), 2. next(gen)
url = gen.send(None)
#download url
html = "bobby"
print(gen.send(html)) #send方法可以传递值进入生成器内部,同时还可以重启生成器执行到下一个yield位置
print(gen.send(html))
#1.启动生成器方式有两种, next(), send
# print(next(gen))
# print(next(gen))
# print(next(gen))
# print(next(gen))
Copydef gen_func():
#1. 可以产出值, 2. 可以接收值(调用方传递进来的值)
try:
yield "http://projectsedu.com"
except BaseException:
pass
yield 2
yield 3
return "bobby"
if __name__ == "__main__":
gen = gen_func()
print(next(gen))
gen.close()
print("bobby")
#GeneratorExit是继承自BaseException, Exception
Copydef gen_func():
#1. 可以产出值, 2. 可以接收值(调用方传递进来的值)
try:
yield "http://projectsedu.com"
except Exception as e:
pass
yield 2
yield 3
return "bobby"
if __name__ == "__main__":
gen = gen_func()
print(next(gen))
gen.throw(Exception, "download error")
print(next(gen))
gen.throw(Exception, "download error")
11.7生成器进阶-yield from
#python3.3新加了yield from语法
from itertools import chain
my_list = [1,2,3]
my_dict = {
"bobby1":"http://projectsedu.com",
"bobby2":"http://www.imooc.com",
}
#yield from iterable
# def g1(iterable):
# yield iterable
#
# def g2(iterable):
# yield from iterable
#
# for value in g1(range(10)):
# print(value)
# for value in g2(range(10)):
# print(value)
def my_chain(*args, **kwargs):
for my_iterable in args:
yield from my_iterable
# for value in my_iterable:
# yield value
for value in my_chain(my_list, my_dict, range(5,10)):
print(value)
def g1(gen):
yield from gen
def main():
g = g1()
g.send(None)
#1. main 调用方 g1(委托生成器) gen 子生成器
#1. yield from会在调用方与子生成器之间建立一个双向通道
Copyfinal_result = {}
# def middle(key):
# while True:
# final_result[key] = yield from sales_sum(key)
# print(key+"销量统计完成!!.")
#
# def main():
# data_sets = {
# "bobby牌面膜": [1200, 1500, 3000],
# "bobby牌手机": [28,55,98,108 ],
# "bobby牌大衣": [280,560,778,70],
# }
# for key, data_set in data_sets.items():
# print("start key:", key)
# m = middle(key)
# m.send(None) # 预激middle协程
# for value in data_set:
# m.send(value) # 给协程传递每一组的值 # 发送到字生成器里
# m.send(None)
# print("final_result:", final_result)
#
# if __name__ == '__main__':
# main()
def sales_sum(pro_name):
total = 0
nums = []
while True:
x = yield
print(pro_name+"销量: ", x)
if not x:
break
total += x
nums.append(x)
return total, nums
if __name__ == "__main__":
my_gen = sales_sum("bobby牌手机")
my_gen.send(None)
my_gen.send(1200)
my_gen.send(1500)
my_gen.send(3000)
try:
my_gen.send(None)
except StopIteration as e:
result = e.value
print(result)
11.8 yield from how
#pep380
#1. RESULT = yield from EXPR可以简化成下面这样
#一些说明
"""
_i:子生成器,同时也是一个迭代器
_y:子生成器生产的值
_r:yield from 表达式最终的值
_s:调用方通过send()发送的值
_e:异常对象
"""
_i = iter(EXPR) # EXPR是一个可迭代对象,_i其实是子生成器;
try:
_y = next(_i) # 预激子生成器,把产出的第一个值存在_y中;
except StopIteration as _e:
_r = _e.value # 如果抛出了`StopIteration`异常,那么就将异常对象的`value`属性保存到_r,这是最简单的情况的返回值;
else:
while 1: # 尝试执行这个循环,委托生成器会阻塞;
_s = yield _y # 生产子生成器的值,等待调用方`send()`值,发送过来的值将保存在_s中;
try:
_y = _i.send(_s) # 转发_s,并且尝试向下执行;
except StopIteration as _e:
_r = _e.value # 如果子生成器抛出异常,那么就获取异常对象的`value`属性存到_r,退出循环,恢复委托生成器的运行;
break
RESULT = _r # _r就是整个yield from表达式返回的值。
"""
1. 子生成器可能只是一个迭代器,并不是一个作为协程的生成器,所以它不支持.throw()和.close()方法;
2. 如果子生成器支持.throw()和.close()方法,但是在子生成器内部,这两个方法都会抛出异常;
3. 调用方让子生成器自己抛出异常
4. 当调用方使用next()或者.send(None)时,都要在子生成器上调用next()函数,当调用方使用.send()发送非 None 值时,才调用子生成器的.send()方法;
"""
_i = iter(EXPR)
try:
_y = next(_i)
except StopIteration as _e:
_r = _e.value
else:
while 1:
try:
_s = yield _y
except GeneratorExit as _e:
try:
_m = _i.close
except AttributeError:
pass
else:
_m()
raise _e
except BaseException as _e:
_x = sys.exc_info()
try:
_m = _i.throw
except AttributeError:
raise _e
else:
try:
_y = _m(*_x)
except StopIteration as _e:
_r = _e.value
break
else:
try:
if _s is None:
_y = next(_i)
else:
_y = _i.send(_s)
except StopIteration as _e:
_r = _e.value
break
RESULT = _r
"""
看完代码,我们总结一下关键点:
1. 子生成器生产的值,都是直接传给调用方的;调用方通过.send()发送的值都是直接传递给子生成器的;如果发送的是 None,会调用子生成器的__next__()方法,如果不是 None,会调用子生成器的.send()方法;
2. 子生成器退出的时候,最后的return EXPR,会触发一个StopIteration(EXPR)异常;
3. yield from表达式的值,是子生成器终止时,传递给StopIteration异常的第一个参数;
4. 如果调用的时候出现StopIteration异常,委托生成器会恢复运行,同时其他的异常会向上 "冒泡";
5. 传入委托生成器的异常里,除了GeneratorExit之外,其他的所有异常全部传递给子生成器的.throw()方法;如果调用.throw()的时候出现了StopIteration异常,那么就恢复委托生成器的运行,其他的异常全部向上 "冒泡";
6. 如果在委托生成器上调用.close()或传入GeneratorExit异常,会调用子生成器的.close()方法,没有的话就不调用。如果在调用.close()的时候抛出了异常,那么就向上 "冒泡",否则的话委托生成器会抛出GeneratorExit异常。
"""
11.9 async和await
#python为了将语义变得更加明确,就引入了async和await关键词用于定义原生的协程
# async def downloader(url):
# return "bobby"
import types
@types.coroutine
def downloader(url):
yield "bobby"
async def download_url(url):
#dosomethings
html = await downloader(url)
return html
if __name__ == "__main__":
coro = download_url("http://www.imooc.com")
# next(None)
coro.send(None)
11.10 生成器实现协程
#生成器是可以暂停的函数
import inspect
# def gen_func():
# value=yield from
# #第一返回值给调用方, 第二调用方通过send方式返回值给gen
# return "bobby"
#1. 用同步的方式编写异步的代码, 在适当的时候暂停函数并在适当的时候启动函数
import socket
def get_socket_data():
yield "bobby"
def downloader(url):
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.setblocking(False)
try:
client.connect((host, 80)) # 阻塞不会消耗cpu
except BlockingIOError as e:
pass
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
source = yield from get_socket_data()
data = source.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
def download_html(html):
html = yield from downloader()
if __name__ == "__main__":
#协程的调度依然是 事件循环+协程模式 ,协程是单线程模式
pass
