第五章:Python高级编程-深入Python的dict和set
5.1 dict的abc继承关系
和list(Sequence)相似,都继承于Collection,添加了一些方法
from collections.abc import Mapping,MutableMapping
# dict是属于Mapping类型的
a = {}
print(type(a)) # dict
print(isinstance(a,MutableMapping)) # 是属于MutableMapping类型的
"""
<class 'dict'>
True
"""
# 但是它不是通过继承的方式,而是实现了这个类中的一些方法,通过MutableMapping.register(dict)的方法
collections.abc模块
class Mapping(Collection):
__slots__ = ()
"""A Mapping is a generic container for associating key/value
pairs.
This class provides concrete generic implementations of all
methods except for __getitem__, __iter__, and __len__.
"""
@abstractmethod
def __getitem__(self, key):
raise KeyError
def get(self, key, default=None):
'D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.'
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
try:
self[key]
except KeyError:
return False
else:
return True
def keys(self):
"D.keys() -> a set-like object providing a view on D's keys"
return KeysView(self)
def items(self):
"D.items() -> a set-like object providing a view on D's items"
return ItemsView(self)
def values(self):
"D.values() -> an object providing a view on D's values"
return ValuesView(self)
def __eq__(self, other):
if not isinstance(other, Mapping):
return NotImplemented
return dict(self.items()) == dict(other.items())
__reversed__ = None
class MutableMapping(Mapping):
__slots__ = ()
"""A MutableMapping is a generic container for associating
key/value pairs.
This class provides concrete generic implementations of all
methods except for __getitem__, __setitem__, __delitem__,
__iter__, and __len__.
"""
@abstractmethod
def __setitem__(self, key, value):
raise KeyError
@abstractmethod
def __delitem__(self, key):
raise KeyError
__marker = object()
def pop(self, key, default=__marker):
'''D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised.
'''
try:
value = self[key]
except KeyError:
if default is self.__marker:
raise
return default
else:
del self[key]
return value
def popitem(self):
'''D.popitem() -> (k, v), remove and return some (key, value) pair
as a 2-tuple; but raise KeyError if D is empty.
'''
try:
key = next(iter(self))
except StopIteration:
raise KeyError from None
value = self[key]
del self[key]
return key, value
def clear(self):
'D.clear() -> None. Remove all items from D.'
try:
while True:
self.popitem()
except KeyError:
pass
def update(*args, **kwds):
''' D.update([E, ]**F) -> None. Update D from mapping/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k, v in F.items(): D[k] = v
'''
if not args:
raise TypeError("descriptor 'update' of 'MutableMapping' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('update expected at most 1 arguments, got %d' %
len(args))
if args:
other = args[0]
if isinstance(other, Mapping):
for key in other:
self[key] = other[key]
elif hasattr(other, "keys"):
for key in other.keys():
self[key] = other[key]
else:
for key, value in other:
self[key] = value
for key, value in kwds.items():
self[key] = value
def setdefault(self, key, default=None):
'D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D'
try:
return self[key]
except KeyError:
self[key] = default
return default
5.2 dict的常用方法
浅拷贝
a = {'LYQ1':{'SWPU':'软件工程'},
'LYQ2':{'SWPU2':'软件工程2'}}
#这是浅拷贝,指向的是同一值,修改一个,另一个也会修改,所以我们看到下面a和b输出是一样的
b=a.copy()
b['LYQ1']['SWPU']='我是浅拷贝'
print(b)
print(a)
"""
{'LYQ1': {'SWPU': '我是浅拷贝'}, 'LYQ2': {'SWPU2': '软件工程2'}}
{'LYQ1': {'SWPU': '我是浅拷贝'}, 'LYQ2': {'SWPU2': '软件工程2'}}
"""
# 值是不可变对象,copy方法是浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
c = {"a": "b"}
d = c.copy()
d["a"] = "sx"
print(c)
print(d)
"""
{'a': 'b'}
{'a': 'sx'}
"""
深拷贝
a = {'LYQ1':{'SWPU':'软件工程'},
'LYQ2':{'SWPU2':'软件工程2'}}
import copy
#深拷贝,指向不同的对象
deep_b=copy.deepcopy(a)
deep_b['LYQ1']['SWPU']='我是深拷贝'
print(deep_b)
print(a)
"""
{'LYQ1': {'SWPU': '我是深拷贝'}, 'LYQ2': {'SWPU2': '软件工程2'}}
{'LYQ1': {'SWPU': '软件工程'}, 'LYQ2': {'SWPU2': '软件工程2'}}
"""
fromkeys():
#把一个可迭代对象转换为dict,{'SWPU':'软件工程'}为默认值
my_list=['Stu1','Stu2']
my_dict=dict.fromkeys(my_list,{'SWPU':'软件工程'})
print(my_dict)
"""
{'Stu1': {'SWPU': '软件工程'}, 'Stu2': {'SWPU': '软件工程'}}
"""
get(key, value)
# 为了预防keyerror
new_dict = {'Stu1': {'SWPU': '软件工程'}, 'Stu2': {'SWPU': '软件工程'}}
aa = new_dict.get("stu6", {"age": 18})
print(aa)
items():循环,返回key,value
new_dict = {'Stu1': {'SWPU': '软件工程'}, 'Stu2': {'SWPU': '软件工程'}}
for k, v in new_dict.items():
print(k, v)
"""
Stu1 {'SWPU': '软件工程'}
Stu2 {'SWPU': '软件工程'}
"""
setdefault(): 有值直接取值,没有值则将值设置进去,并获取该值返回
new_dict = {'Stu1': {'SWPU': '软件工程'}, 'Stu2': {'SWPU': '软件工程'}}
default_value1 = new_dict.setdefault("Stu12", "kobe")
default_value2 = new_dict.setdefault("Stu2", "kobe")
print(default_value1)
print(default_value2)
print(new_dict)
"""
kobe
{'SWPU': '软件工程'}
{'Stu1': {'SWPU': '软件工程'}, 'Stu2': {'SWPU': '软件工程'}, 'Stu12': 'kobe'}
"""
update():添加键值对或更新键值对
a = {'kobe':{'SWPU':'软件工程'},
'james':{'SWPU2':'软件工程2'}}
#添加新键值对(即合并两个字典)
a.update({'LYQ3':'NEW'})
#第二种方式
a.update(LYQ4='NEW2',LYQ5='NEW3')
#第三种方式,list里面放tuple,tuple里面放tuple等(可迭代就行)
a.update([('LYQ6','NEW6')])
print(a)
print("*"*60)
#修改键值对
a.update({'kobe':'我修改了'})
print(a)
"""
{'kobe': {'SWPU': '软件工程'}, 'james': {'SWPU2': '软件工程2'}, 'LYQ3': 'NEW', 'LYQ4': 'NEW2', 'LYQ5': 'NEW3', 'LYQ6': 'NEW6'}
************************************************************
{'kobe': '我修改了', 'james': {'SWPU2': '软件工程2'}, 'LYQ3': 'NEW', 'LYQ4': 'NEW2', 'LYQ5': 'NEW3', 'LYQ6': 'NEW6'}
"""
dict源码:
class dict(object):
"""
dict() -> new empty dictionary
dict(mapping) -> new dictionary initialized from a mapping object's
(key, value) pairs
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
"""
def clear(self): # real signature unknown; restored from __doc__
""" D.clear() -> None. Remove all items from D. """
pass
def copy(self): # real signature unknown; restored from __doc__
""" D.copy() -> a shallow copy of D """
pass
@staticmethod # known case
def fromkeys(*args, **kwargs): # real signature unknown
""" Create a new dictionary with keys from iterable and values set to value. """
pass
def get(self, *args, **kwargs): # real signature unknown
""" Return the value for key if key is in the dictionary, else default. """
pass
def items(self): # real signature unknown; restored from __doc__
""" D.items() -> a set-like object providing a view on D's items """
pass
def keys(self): # real signature unknown; restored from __doc__
""" D.keys() -> a set-like object providing a view on D's keys """
pass
def pop(self, k, d=None): # real signature unknown; restored from __doc__
"""
D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised
"""
pass
def popitem(self): # real signature unknown; restored from __doc__
"""
D.popitem() -> (k, v), remove and return some (key, value) pair as a
2-tuple; but raise KeyError if D is empty.
"""
pass
def setdefault(self, *args, **kwargs): # real signature unknown
"""
Insert key with a value of default if key is not in the dictionary.
Return the value for key if key is in the dictionary, else default.
"""
pass
def update(self, E=None, **F): # known special case of dict.update
"""
D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]
"""
pass
def values(self): # real signature unknown; restored from __doc__
""" D.values() -> an object providing a view on D's values """
pass
def __contains__(self, *args, **kwargs): # real signature unknown
""" True if the dictionary has the specified key, else False. """
pass
def __delitem__(self, *args, **kwargs): # real signature unknown
""" Delete self[key]. """
pass
def __eq__(self, *args, **kwargs): # real signature unknown
""" Return self==value. """
pass
def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass
def __getitem__(self, y): # real signature unknown; restored from __doc__
""" x.__getitem__(y) <==> x[y] """
pass
def __ge__(self, *args, **kwargs): # real signature unknown
""" Return self>=value. """
pass
def __gt__(self, *args, **kwargs): # real signature unknown
""" Return self>value. """
pass
def __init__(self, seq=None, **kwargs): # known special case of dict.__init__
"""
dict() -> new empty dictionary
dict(mapping) -> new dictionary initialized from a mapping object's
(key, value) pairs
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
# (copied from class doc)
"""
pass
def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass
def __len__(self, *args, **kwargs): # real signature unknown
""" Return len(self). """
pass
def __le__(self, *args, **kwargs): # real signature unknown
""" Return self<=value. """
pass
def __lt__(self, *args, **kwargs): # real signature unknown
""" Return self<value. """
pass
@staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass
def __ne__(self, *args, **kwargs): # real signature unknown
""" Return self!=value. """
pass
def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass
def __setitem__(self, *args, **kwargs): # real signature unknown
""" Set self[key] to value. """
pass
def __sizeof__(self): # real signature unknown; restored from __doc__
""" D.__sizeof__() -> size of D in memory, in bytes """
pass
__hash__ = None
5.3 dict的子类
当我们要自定义一个字典的时候,不要使用直接继承自dict,因为有些操作会不生效
"""
不建议直接继承dict,而是collections.UserDict
"""
# 不建议继承list和dict
class MyDict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, value * 2)
#未调用自己写的方法, c语言编写的dict某些时候不会去调用覆盖的方法
my_dict=MyDict(one=1)
print(my_dict)
print("*"*10)
#调用自己写的方法
my_dict['one']=1
print(my_dict)
"""
{'one': 1}
**********
{'one': 2}
"""
使用继承UserDict的方式来实现自定义的字典.
from collections import UserDict
class MyDict2(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value * 2)
my_dict2=MyDict2(one=1)
print(my_dict2)

Userdict源码:当取不到某个key时,就会调用__missing__方法(如果有__missing__)获取默认值
创建带有默认值的字典. collections中的defaultdict

字典之所以可以实现带有默认值,其实是它内部实现了__missing__方法,在UserDict类里面的__getitem__方法中会调用__missing__方法
from collections import defaultdict
#可以时dict,int,str,list,tuple等等
my_dict=defaultdict(dict)
#找不到key,实际调用的时__missing__方法
print(my_dict['haha'])
defaultdict源码: 之所以可以设置默认值就是因为实现了__missing__方法
5.4 set和frozenset
"""
set 集合
frozenset(不可变集合) 无序 不重复
"""
s = set("abcde") # 接受迭代类型;字符串,列表...
print(s)
# 向set添加数据
s.add()
s.update()
difference() # 差值
- # 差集 实现于__ior__魔法函数
# / & -
#set 集合 fronzenset (不可变集合) 无序, 不重复
# s = set('abcdee')
# s = set(['a','b','c','d','e'])
s = {'a','b', 'c'}
# s = frozenset("abcde") # frozenset 可以作为dict的key
# print(s)
# clear() 清空集合
# copy() 浅拷贝集合
# pop() 弹出最后一个元素
# remove() 删除一个集合元素
#向set添加数据
another_set = set("cef")
re_set = s.difference(another_set)
re_set = s - another_set
re_set = s & another_set # 交集
re_set = s | another_set # 并集
#set性能很高
# | & - #集合运算
print(re_set)
print (s.issubset(re_set))
# 也可以用if in判断(实现于__contains__魔法函数)
# if "c" in re_set:
# print ("i am in set")
5.5 dict和set的实现原理
"""
测试list和dict的性能
"""
from random import randint
def load_list_data(total_nums, target_nums):
"""
从文件中读取数据,以list的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = []
target_data = []
file_name = "D:/note/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data.append(line)
else:
break
for x in range(target_nums):
random_index = randint(0, total_nums)
if all_data[random_index] not in target_data:
target_data.append(all_data[random_index])
if len(target_data) == target_nums:
break
return all_data, target_data
def load_dict_data(total_nums, target_nums):
"""
从文件中读取数据,以dict的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = {}
target_data = []
## 1000万或上百万字符串的文本
file_name = "D:/note/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data[line] = 0
else:
break
all_data_list = list(all_data)
for x in range(target_nums):
random_index = randint(0, total_nums-1)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
if len(target_data) == target_nums:
break
return all_data, target_data
def find_test(all_data, target_data):
#测试运行时间
test_times = 100
total_times = 0
import time
for i in range(test_times):
find = 0
start_time = time.time()
for data in target_data:
if data in all_data:
find += 1
last_time = time.time() - start_time
total_times += last_time
return total_times/test_times
if __name__ == "__main__":
# all_data, target_data = load_list_data(10000, 1000)
# all_data, target_data = load_list_data(100000, 1000)
# all_data, target_data = load_list_data(1000000, 1000)
# all_data, target_data = load_dict_data(10000, 1000)
# all_data, target_data = load_dict_data(100000, 1000)
# all_data, target_data = load_dict_data(1000000, 1000)
all_data, target_data = load_dict_data(2000000, 1000)
last_time = find_test(all_data, target_data)
#dict查找的性能远远大于list
#在list中随着list数据的增大 查找时间会增大
#在dict中查找元素不会随着dict的增大而增大
print(last_time)
"""
1.dict的key或者set的值,都必须是可以hash的(不可变对象都是可以hash的,如str,frozenset,tuple,自己实现的类【实现__hash__魔法函数】);
2.dict内存花销大,但是查询速度快,自定义的对象或者python内置的对象都是用dict包装的;
3.dict的存储顺序与元素添加顺序有关;
4.添加数据有可能改变已有数据的顺序;
5.取数据的时间复杂度为O(1)
"""
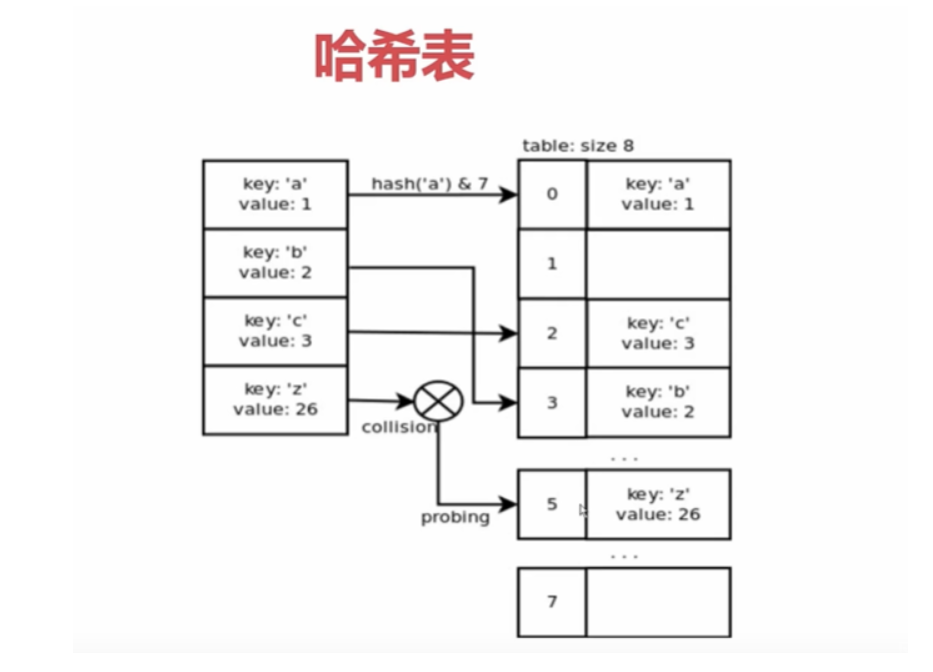
通过hash函数计算key(有很多的算法),这里是通过hash函数计算然后与7进行与运算,在计算过程中有可能冲突,得到同样的位置(有很多的解决方法),如’abc‘取一位'c'加一位随机数,如果冲突,就向前多取一位再计算...(还有先声明一个很小的内存空间,可能存在一些空白,计算空白,如果小于1/3,然后声明一个更大的空间,拷贝过去,减少冲突)
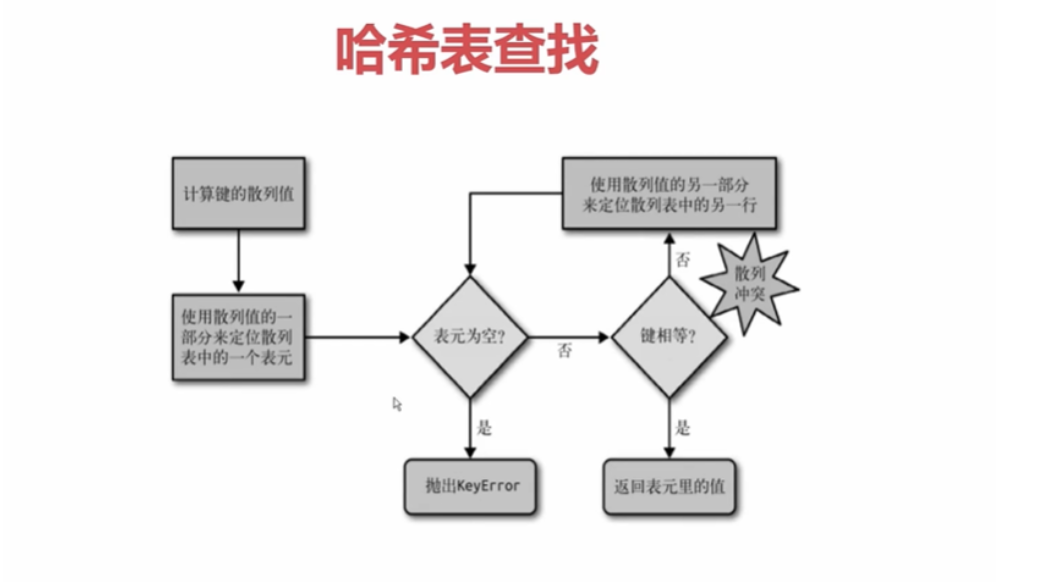
查找数据,先计算hash值定位,查找是否为空,为空就抛出错误,如果不为空查看是否相等,如果被其他占领就不相等,然后又进行冲突解决
