
Redis 入门权威指北
前言
看看业务遇到了什么问题?
我们要从互联网架构的演变之路开始说起Redis的前世今生。
在我们小的时候,网络世界好像就是只有通过大屁股台式机才能进入一样,彼时的手机只是用来打打电话,发发短信,网上购物还没有在中国普及,Jack Ma 的TB还没有走进千家万户,能上网的用户只是很少的一部分人群。那时候的场景是登录着QQ,玩着单机的游戏,连在线视频观看都不是那么流畅。互联网项目的架构是多么简单:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0wLvxoP-1623849610589)(D:\Source\image\Redis\web初始架构.png)]](https://img-blog.csdnimg.cn/20210616212127220.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODg5NzM2NA==,size_16,color_FFFFFF,t_70)
网站初期
那时候的网络项目特点:网站访问量低,大多数都是以静态网页为主,很少有动态交互应用,单个数据库就可以满足要求。
网站中期
随着互联网迅速的普及,大量的用户开始使用互联网,终端设备越来越多的入门,流量开始急剧增加。大部分使用MySQL架构的网站在数据库上都开始出现性能问题,Web程序不能再仅仅专注在功能上,同时也在追求性能。开始使用缓存技术缓解数据库压力,优化数据库的结构和索引。刚开始时比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大,文件缓存中的数据不能在多台Web服务器之间共享,大量的小文件IO也带来了比较高的IO压力。在这种情况下,Memcache就成了一款非常有效的解决方案。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nreu5z7-1623849610591)(D:\Source\image\Redis\MemCache缓存.png)]](https://img-blog.csdnimg.cn/20210616212144999.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODg5NzM2NA==,size_16,color_FFFFFF,t_70)
Memcache作为一个独立的分布式缓存服务器,为多个Web服务器提供了一个共享的高性能缓存服务,在Memcache服务器上,又发展了根据hash算法来进行多台Memcache缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效问题。
网站后期
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了:

网站再后期
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
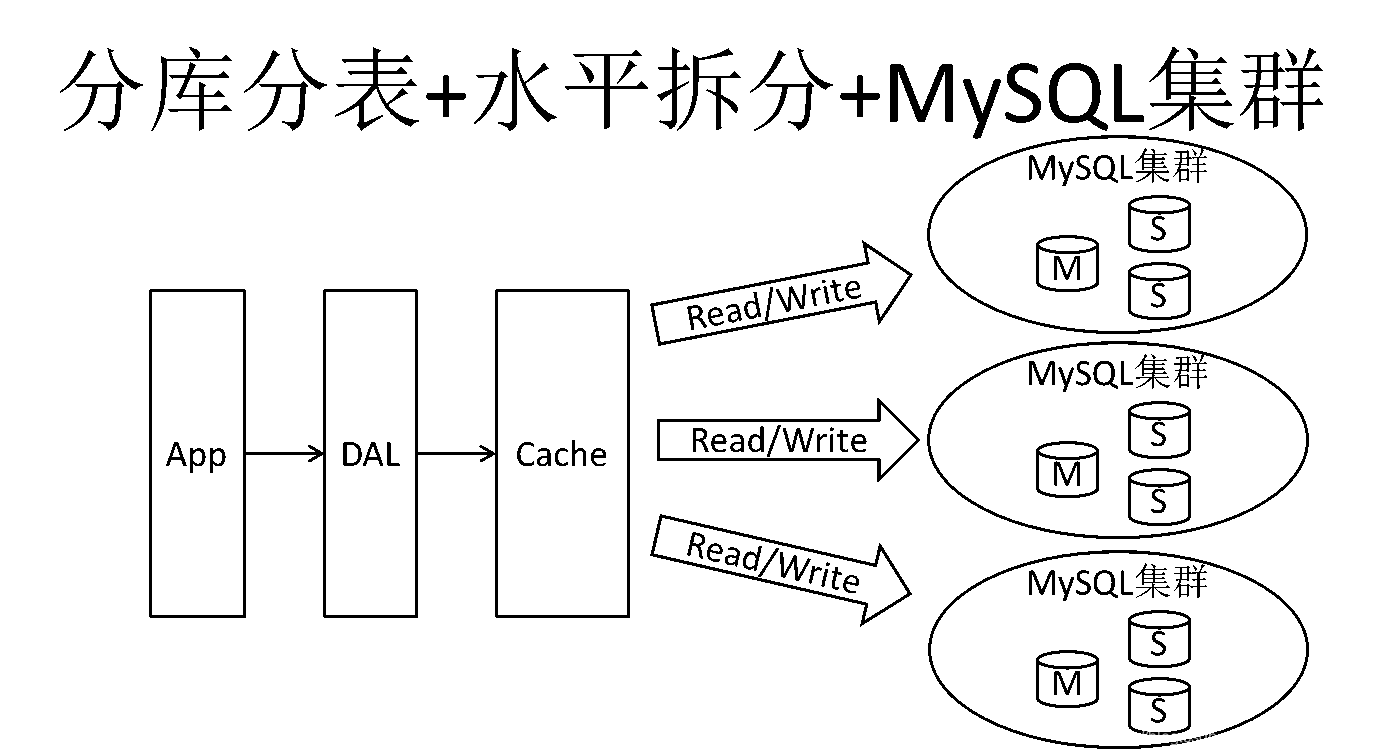
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
现阶段大致架构
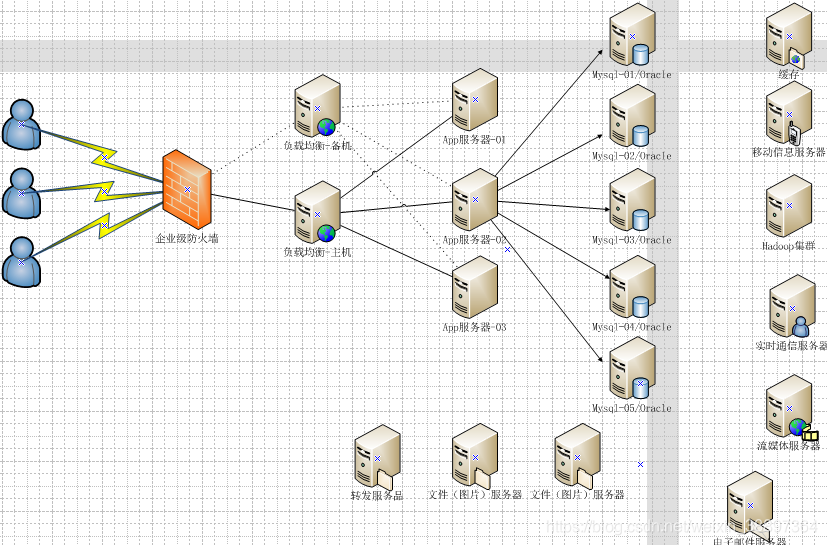
随着数据获取终端越来越多,以及更多的更快的网络带宽,信息不仅仅是之前的业务数据,伴随着数据多样化的大数据时代,互联网时代下如何提升:高可扩、高性能、高并发成为不断需要提升和攻克的问题。数据的体量急剧增加、数据样式(不满足于以前的表格型,如文本、图片、音频、视频,各类终端等等)和数据实时性的要求(比如直播、金融证券。。。。)。如何在各个模块之间提升数据存储和检索效率也变得更为重要。
当传统的关系型数据库对于一些半结构化、非结构化数据的处理表现不佳的时候,如何存储处理这些非结构化数据,开始有了新的思考和应对策略。
NoSQL解决方案
直到所谓NoSQL的解决方案问世了,NoSQL是为“为新兴的新数据存储空间命名”问题而创造的一个名词。Not only SQL。其思想不提供SQL查询数据的手段,只提供一些比较简单的、类似于API接口的方式来存取数据。当然,也会有一些工具为NoSQL数据存储提供了SQL语言的入口。
ACP 定理
一个分布式系统只能同时实现一致性、可用性和分区容错性中的两个。例如:Vogels(亚马逊首席技术官 Werner Vogels)提到的很有现实代表性的一句话:
“在一系列研究结果中发现,在较大型的分布式系统中,由于网络分隔,一致性与可用性不能同时满足。意味着三个要素最多只能同时实现两个,不可能三者兼顾;放宽一致性的要求会提升系统的可用性,提升一致性意味着系统需要牺牲一定的可用性。”

NoSQL优势:
-
易扩展
- NoSQL数据库种类繁多,但它们都有一个共通的特点:就是去除关系型数据库的“关系型”特点。数据之间无关系,这样就变得非常容易扩展,而相对应的来看:关系型数据库修改表结构非常困难。这就为项目架构设计提供了更大的扩展空间。
-
大数据量高性能
-
NoSQL数据库都具有非常高的读写性能,尤其在大数据量的情况下,表现同样优秀。这得益于NoSQL数据库中数据之间没有“关系”,数据库结构简单。
-
从缓存角度来看,MySQL的Query Cache是表级别的粗粒度缓存,假设存储了100条数据,其中有一条数据修改了,整个缓存失效,效率很低。而NoSQL数据库的缓存是记录级的细粒度缓存,任何一条记录的修改都不影响其他记录,效率很高。
-
-
多样灵活的数据模型
- NoSQL数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增减修改字段简直就是一个噩梦。
Redis
1. 简介:
Redis:Remote Dictionary Server(远程字典服务器): 是用C语言开发基于内存完全开源免费的,遵守 BSD 协议高性能的key-value 存储系统,是跨平台的非关系型数据库。
支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
以上说明来自官网
整理一下其特性:
- 1.支持多种数据结构(是指Value的类型,Key的类型只能是String):
- String:字符串
- Hashes:哈希,类似于Map<String ,String>,且其KV值只能是String类型
- list:列表,可以重复的集合且有序,有序既可以通过索引进行操作
- sets:集合,不可以重复的集合,无序
- ZSets:有序集合,sorted sets,通过指定score值进行排序的集合
- 支持数据持久化,可以将内存中的数据保存在磁盘中,重新启动的时候依据配置进行加载使用
- Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis的优势
-
1)性能极高 – Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。
-
2)丰富的数据类型 – Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及Ordered Sets 数据类型操作。
-
3)原子 – Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC指令包起来。
-
4)丰富的特性 – Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 与其他 key-value 存储有什么不同?
-
1.Redis 有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis 的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
-
2.Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样 Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Redis的应用场景
- 热点数据加速查询(主要场景),如热点商品、热点信息等访问量较高的数据
- 即时信息查询,如公交到站信息、在线人数信息等
- 时效性信息控制,如验证码控制、投票控制等
- 分布式数据共享,如分布式集群架构中的session分离消息队列
2.Redis的安装
-
凡是技术必登其官网,在官网下载redis-xx.xx.xx.tar.gz安装包并上传到Linux的/opt目录;
-
在/opt目录下,解压安装包到指定的子目录下:命令:tar -zxvf redis-xx.xx.xx.tar.gz
-
安装gcc环境,我们需要将源码编译后再安装,因此需要安装c语言的编译环境!不能直接make!我们可以先检测是否有gcc环境:

若没有gcc直接make会报错:
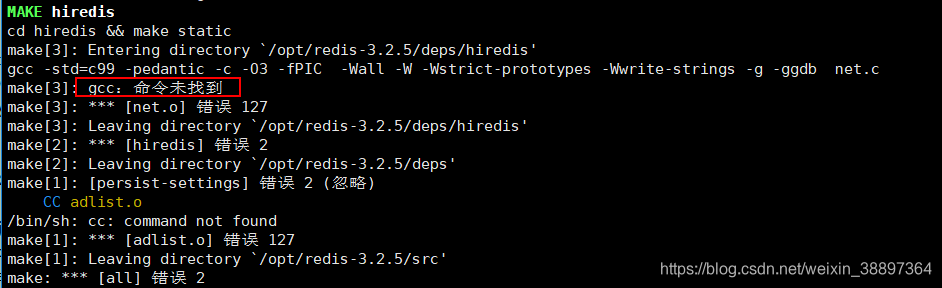
安装gcc:sudo yum install -y gcc-c++
使用sudo权限安装。如果在没有安装gcc环境下,如果执行了make,不会成功!安装环境后,
第二次make有可能报错:Jemalloc/jemalloc.h:没有那个文件
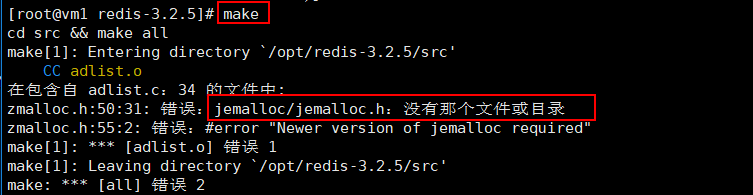
**解决方案:运行make distclean** 然后再进行make编译
-
编译,执行make命令!
-
编译完成后,安装,执行make install命令!
-
默认文件会被安装到 /usr/local/bin目录
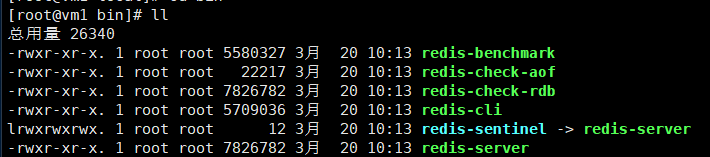
| bin目录下文件名称 | 文件作用 |
|---|---|
| Redis-benchmark | 压力测试。标准是每秒80000次写操作,110000次读操作 (服务启动起来后执行,类似安兔兔跑分) |
| Redis-check-aof | 修复有问题的AOF文件 |
| Redis-check-dump | 修复有问题的dump.rdb文件 |
| Redis-sentinel | 启动哨兵,集群使用 |
| redis-server | 启动服务器 |
| redis-cli | 启动客户端 |
Redis相应的shell命令的操作可以参见菜鸟教程https://www.runoob.com/redis/redis-install.html
3.Redis配置文件
redis配置文件为redis安装的bin目录下redis.conf文件
1.单位配置
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
1k和1kb是不同的,单位的大小写不敏感
2.include参数
可以将公共的配置放入到一个公共的配置文件中,然后通过子配置文件引入父配置文件中的内容!
将配置按照模块分开!一般将引用公共配置的文件表示放在配置最前边:redis 服务启动需要指定对应的配置文件,默认是bin下的redis.conf文件。
################################## INCLUDES ###################################
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
3.Network参数配置
| 属性 | 含义 | 备注 |
|---|---|---|
| bind | 限定访问的主机地址 | 如果没有bind,就是任意ip地址都可以访问。生产环境下,需要写自己应用服务器的ip地址。 |
| protected-mode | 安全防护模式 | 如果没有指定bind指令,也没有配置密码,那么保护模式就开启,只允许本机访问(loaclhost或127.0.0.1)。 |
| port | 端口号 | 默认是6379 |
| tcp-backlog | 网络连接过程中,某种状态的队列的长度 | redis是单线程的,指定高并发时访问时排队的长度。超过后,就呈现阻塞状态。可以理解是一个请求到达后至到接受进程处理前的队列长度。(一般情况下是运维根据集群性能调控)高并发情况下,此值可以适当调高。 |
| timeout | 超时时间 | 默认永不超时 |
| tcp-keepalive | 对客户端的心跳检测间隔时间 |
4.general参数配置
| 属性 | 含义 | 备注 |
|---|---|---|
| daemonize | 是否为守护进程模式运行 | 守护进程模式可以在后台运行 |
| pidfile | 进程id文件保存的路径 | 配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面 |
| loglevel | 定义日志级别 | debug(记录大量日志信息,适用于开发、测试阶段) verbose(较多日志信息) notice(适量日志信息,使用于生产环境) warning(仅有部分重要、关键信息才会被记录) |
| logfile | 日志文件的位置 | 当指定为空字符串时,为标准输出,如果redis以守护进程模式运行,那么日志将会输出到/dev/null |
| syslog-enabled | 是否记录到系统日志 | 要想把日志记录到系统日志服务中,就把它改成 yes |
| syslog-ident | 设置系统日志的ID | |
| syslog-facility | 指定系统日志设置 | 必须是 USER 或者是 LOCAL0-LOCAL7 之间的值 |
| databases | 设置数据库数量 | 默认16,索引为0-15,通过select num 进行选择 |
5.其他
| 属性 | 含义 | 备注 |
|---|---|---|
| requirepass | 设置密码 | |
| maxclients | 最大连接数 | |
| maxmemory | 最大占用多少内存 | 一旦占用内存超限,就开始根据缓存清理策略移除数据如果Redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”, 那么Redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。 |
| maxmemory-policy noeviction | 缓存清理策略 | (1)volatile-lru:使用LRU算法移除key,只对设置了过期时间的键 (2)allkeys-lru:使用LRU算法移除key (3)volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键 (4)allkeys-random:移除随机的key (5)volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key (6)noeviction:不进行移除。针对写操作,只是返回错误信息 |
| maxmemory-samples | 样本数 | 样本数越小,准确率越低,但是性能越好。 LRU算法和最小TTL算法都并非是精确的算法,而是估算值, 所以你可以设置样本的大小。一般设置3到7的数字。 |
4.持久化
Redis是怎么进行持久化的?Redis数据都在内存中,内存本身就不是一个持久化设备,一断电或者重启不就木有了嘛?
如何避免这个问题或者尽可能减少数据丢失。
我们在开篇的时候介绍redis的时候也讲到redis是支持持久化,为此,redis提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔对数据进行快照存储;
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以append-only模式追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
- 如果只希望数据在服务器运行的时候存在,也可以不采用任何持久化方式
- 也可以同时开启两种持久化方式。在此情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据。因为通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整;
以上的持久化级别只是两种持久化方式的组合。那我们现在就分别看看这两种持久化方式的具体实现。
4.1.RDB持久化方式
4.1.1RDB简介:
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
4.1.2 工作机制
每隔一段时间,就把内存中的数据保存到硬盘上的指定文件中。
RDB是默认开启的!
4.1.3 RDB特点
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
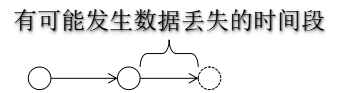
最后一次持久化后的数据可能丢失。
比如:两次保存的时间间隔内,服务器宕机,或者发生断电问题。
4.1.4 RDB保存策略和触发机制
保存策略
-
save 900 1 900 秒内如果至少有 1 个 key 的值变化,则保存
-
save 300 10 300 秒内如果至少有 10 个 key 的值变化,则保存
-
save 60 10000 60 秒内如果至少有 10000 个 key 的值变化,则保存
-
save “” 就是禁用RDB模式(一般不用该模式,默认开启上边三个)
RDB触发机制
-
①基于自动保存的策略,就是满足保存策略条件
-
②执行save,或者bgsave命令!执行时,是阻塞状态。
-
③执行flushall命令,也会产生dump.rdb,但里面是空的,没有意义。
-
④当执行shutdown命令时,也会主动地备份数据。
4.1.5 RDB优缺点
优点:
- RDB是一个非常紧凑的文件,它保存了某个时间点的数据集,非常适用于数据集的备份。比如你可以在每个小时保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题也可以根据需求恢复到不同版本的数据集
- RDB 是一个紧凑的单一文件,很方便传送到另一个远端数据中,非常适合用于灾难恢复
- RDB在保存RDB文件时,父进程fork出一个子进程。接下来的工作全部由子进程来做,父进程不需要做其他IO操作,所以RDB持久化方式可以最大化redis的性能
- 与AOF方式相比,再回复大的数据集的时候,RDB方式会更快一些
缺点
- 如果redis意外停止工作的情况下丢失数据最少的话,RDB方式不满足当前需求。虽然我们可以配置不同的save 时间点(例如每隔5分钟并且数据集有100个写的操作)时,Redis要完整的保存整个数据集是一个比较繁重的工作,通常在save间隔中间发生redis服务崩溃重启,会丢失这个save间隔中的数据
- RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求。如果数据集巨大且CPU性能不佳的情况下,持续时间会达到秒级。
4.2 AOF持久化方式
4.2.1 AOF简介
AOF是以日志的形式来记录每个写操作,将每一次对数据进行修改,都把新建、修改数据的命令保存到指定文件中。Redis重新启动时读取这个文件,重新执行新建、修改数据的命令恢复数据。
默认不开启,需要手动开启
AOF文件的保存路径,同RDB的路径一致。
AOF在保存命令的时候,只会保存对数据有修改的命令,也就是写操作!
当RDB和AOF存的不一致的情况下,按照AOF来恢复。因为AOF是对RDB的补充。备份周期更短,也就更可靠。
4.2.2 AOF 保存策略
-
appendfsync always:每次产生一条新的修改数据的命令都执行保存操作;效率低,但是安全!
-
appendfsync everysec:每秒执行一次保存操作。如果在未保存当前秒内操作时发生了断电,仍然会导致一部分数据丢失(即1秒钟的数据)。
-
appendfsync no:从不保存,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
4.2.3 AOF文件修复
如果AOF文件中出现了残余命令,会导致服务器无法重启。此时需要借助redis-check-aof工具来修复!
redis-check-aof --fix 文件
4.2.4 AOF的优缺点
优点
- 使用AOF会让Redis更加耐久:可以使用不同的fsync策略,默认使用每秒fsync 的策略,Redis的性能依然很好,一旦出现故障,最多丢失1秒的数据
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间不足,写过程宕机等)未执行完整的写入命令,也可以使用redis-check-aof工具修复这些问题
- Redis 可以在AOF文件体积变得过大时,自动的在后台对AOF进行重写:重写的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新AOF文件的过程中,会继续将命令追加到现有的AOF文件里面,即使重写过程中发生宕机,现有的AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新的AOF文件,并开始对新AOF文件进行追加操作
- AOF文件有序地保存了对数据执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此AOF文件的非常容易让人读懂,对文件进行分析(parse)也很轻松。导出AOF文件也非常简单。举个例子:如果不小心执行了flushall命令,只要AOF文件未被重写,那么只要停止服务器,移除AOF文件末尾的FLUSHALL命令,并重启Redis,就可以恢复数据集到FLUSHALL执行前的状态。
缺点
- 对于相同的数据集来说,AOF文件的体积通常大于RDB文件的体积。
- 根据使用的fsync策略,AOF的速度可能会慢于RDB。一般情况下,每秒fsync的效率已经很高,而fsync可以让AOF速度和RDB一样快,即使在高负荷下也是如此。不过处理巨大的写入载入时,RDB可以提供更有保证的最大延迟时间。
- 每次读写都同步的时候,有一定的性能压力
4.3 如何选择?
小孩子才做选择,要学会全都要,你单独用RDB你会丢失很多数据,你单独用AOF,你数据恢复没RDB来的快,真出什么问题的时候第一时间用RDB恢复,然后AOF做数据补全,真香!冷备热备一起上,才是互联网时代一个高健壮性系统的王道。
Redis作为内存数据库从本质上来说,如果不想牺牲性能,就不可能做到数据的“绝对”安全。
RDB和AOF都只是尽可能在兼顾性能的前提下降低数据丢失的风险,如果真的发生数据丢失问题,尽可能减少损失。
在整个项目的架构体系中,Redis大部分情况是扮演“二级缓存”角色。二级缓存适合保存的数据
-
经常要查询,很少被修改的数据。
-
不是非常重要,允许出现偶尔的并发问题。
-
不会被其他应用程序修改。
如果Redis是作为缓存服务器,那么说明数据在MySQL这样的传统关系型数据库中是有正式版本的。数据最终以MySQL中的为准。
5. 事务
5.1 redis中事务简介
-
Redis中事务,不同于传统的关系型数据库中的事务。
-
Redis中的事务指的是一个单独的隔离操作。
-
Redis的事务中的所有命令都会序列化、按顺序地执行且不会被其他客户端发送来的命令请求所打断。
-
Redis事务的主要作用是串联多个命令防止别的命令插队
5.2 redis事务常用命令(shell)
| MULTI | 标记一个事务块的开始 |
|---|---|
| EXEC | 执行事务中所有在排队等待的指令并将链接状态恢复到正常 当使用WATCH 时,只有当被监视的键没有被修改, 且允许检查设定机制时,EXEC会被执行 |
| DISCARD | 刷新一个事务中所有在排队等待的指令,并且将连接状态恢复到正常。 如果已使用WATCH,DISCARD将释放所有被WATCH的key。 |
| WATCH | 标记所有指定的key 被监视起来,在事务中有条件的执行(乐观锁) |
5.3 Redis事务演示
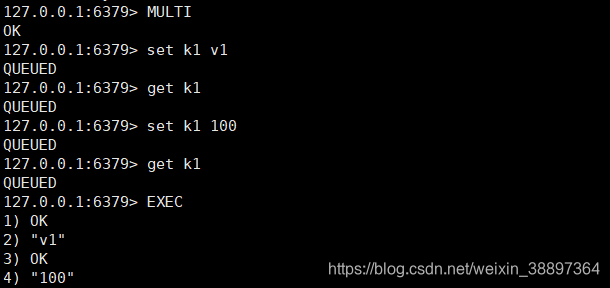
5.3.1 简单组队
MULTI开启组队,EXEC依次执行队列中的命令。
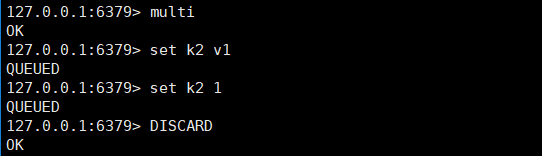
DISCARD中途取消组队
5.3.2 组队失败
”殃及池鱼“
在编译的过程中,Redis检测出来了错误的语法命令,因此它认为这条组队,一定会发生错误,因此全体取消
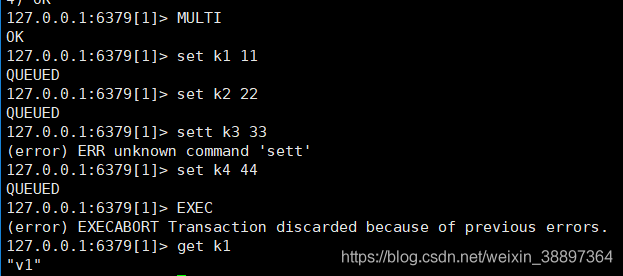
”自作自受“
此种情况,语法符合规范,Redis只有在执行中,才可以发现错误。而在Redis中,并没有回滚机制,因此错误的命令,无法执行,正确的命令会全部执行!
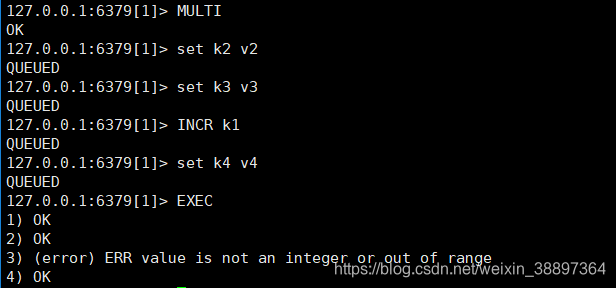
为什么Redis不支持回滚
如果使用关系型数据如MySQL、SQL Server、Oracle等,事务不支持回滚会觉得有点出乎意料,有点奇怪。
引用官方的说明:
- redis命令只会因为错误的语法而失败(并且这些问题在入队是不能发现),或是命令用在了错误类型的键上面,这就是说,失败的命令是由编译错误造成的,而这些错误应该在开发的过程中被发现,而不是在生产中。意思就:你丫的,给了你语法怎么用,你还用错了,就自己承担自己写错的成本。
- redis不需要对回滚进行处理,就可以让Redis内部保持简单快速。
5.4redis 锁及策略
Redis不支持悲观锁。Redis作为缓存服务器使用时,以读操作为主,很少写操作,相应的操作被打断的几率较少。不采用悲观锁是为了防止降低性能。
策略
-
Redis采用了乐观锁策略(通过watch操作)。乐观锁支持读操作,适用于多读少写的情况!
-
在事务中,可以通过watch命令来加锁;使用 UNWATCH可以取消加锁;
-
如果在事务之前,执行了WATCH(加锁),那么执行EXEC 命令或 DISCARD 命令后,锁对自动释放,即不需要再执行 UNWATCH 了
6.主从复制
6.1 什么是Redis主从复制
当单机Redis的性能是有限的,而Redis常用其读高并发的特性,当一台Redis有要读又要写的时候,这就顶不住了啊。太过于压榨就会崩溃的哦。那就把读写分离,又因为读的需求是大于写的操作并发,就可以用一个master机器去写,其他多个salve机器去完成读的任务请求。不仅实现了redis存储的扩容,还实现了水平扩容。
配置多台Redis服务器,以主机和备机的身份分开。主机数据更新后,根据配置和策略,自动同步到备机的master/salver机制,Master以写为主,Slave以读为主,二者之间自动同步数据。
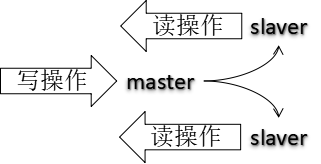
主从目的:
-
读写分离提高Redis性能;
-
避免单点故障,容灾快速恢复
机制原理:
每次从机联通后,都会给主机发送sync指令,主机立刻进行存盘操作,发送RDB文件到从机,从机收到RDB文件后,进行全盘加载。之后每次主机的写操作命令,都会立刻发送给从机,从机执行相同的命令来保证主从的数据一致!
注意:主库接收到SYNC的命令时会执行RDB过程,即使在配置文件中禁用RDB持久化也会生成,但是如果主库所在的服务器磁盘IO性能较差,那么这个复制过程就会出现瓶颈,庆幸的是,Redis在2.8.18版本开始实现了无磁盘复制功能(不过该功能还是处于试验阶段),设置repl-diskless-sync yes。即Redis在与从数据库进行复制初始化时将不会将快照存储到磁盘,而是直接通过网络发送给从数据库,避免了IO性能差问题。
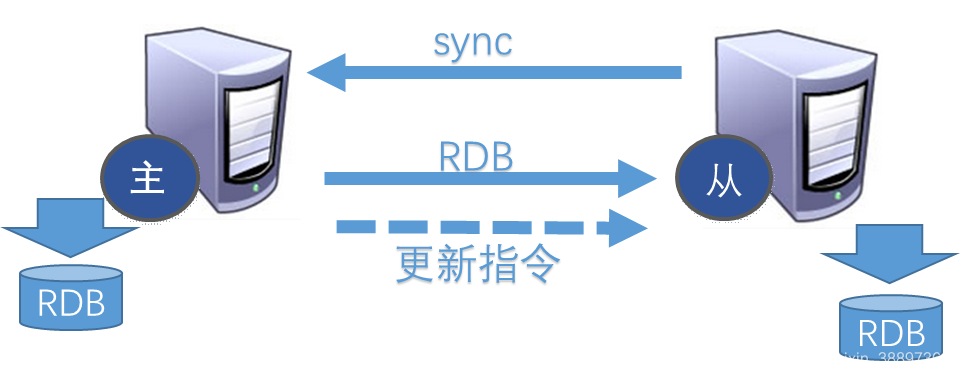
6.2 配置redis主从复制
6.2.1 准备
不同的主机配置不同的Redis服务,否则在一台机器上面跑多个Redis服务,需要配置多个Redis配置文件。
- ①准备Redis配置文件,每个配置文件,需要配置以下属性
daemonize yes: 服务在后台运行
port:端口号
pidfile:pid保存文件
logfile:日志文件(如果没有指定的话,就不需要)
dump.rdb: RDB
appendonly 关掉,或者是更改appendonly文件的名称。
- ②根据配置文件,启动多个Redis服务
6.2.2 配置
原则:配从不配主
一、临时建立主从关系
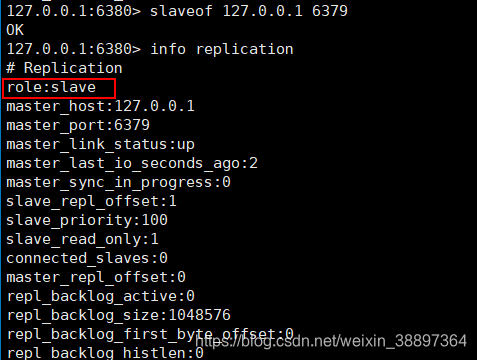
- 在从服务器上执行SLAVEOF ip:port命令;
- 执行info replication命令
二 永久建立
在从节点配置文件中,编写slaveof属性配置
# slaveof <masterip> <masterport>
三 恢复身份
命令:slaveof no one
7.哨兵模式
7.1 简介
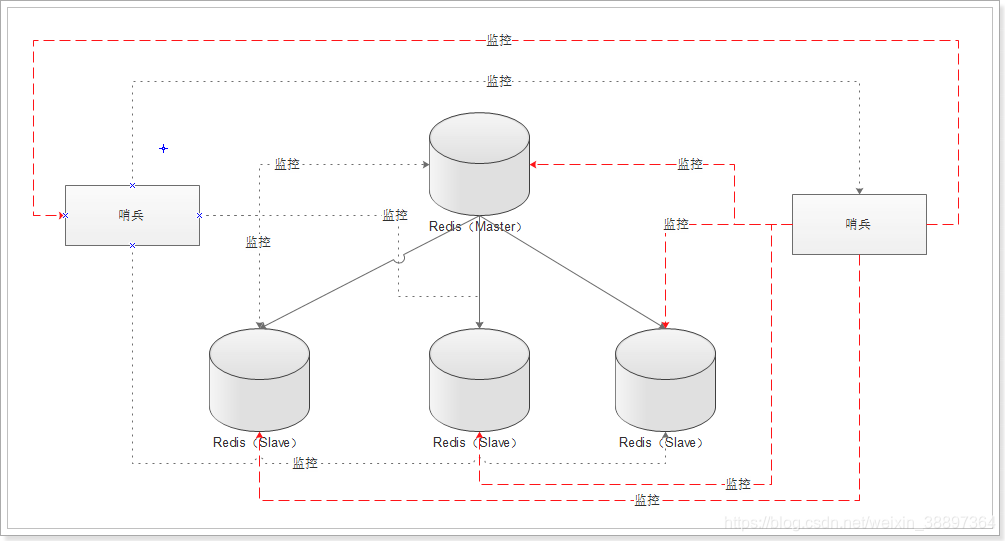
在主从复制下,只有一个master,那master如果挂了,整个redis就不能保证可用了。如果某一个slave节点崩溃了,同样我们不能在分配对应的请求到该节点进行读操作。如何监控主从状态,并解决master单点故障问题?哨兵模式应用而生。
作用:
-
集群监控:主从状态检测
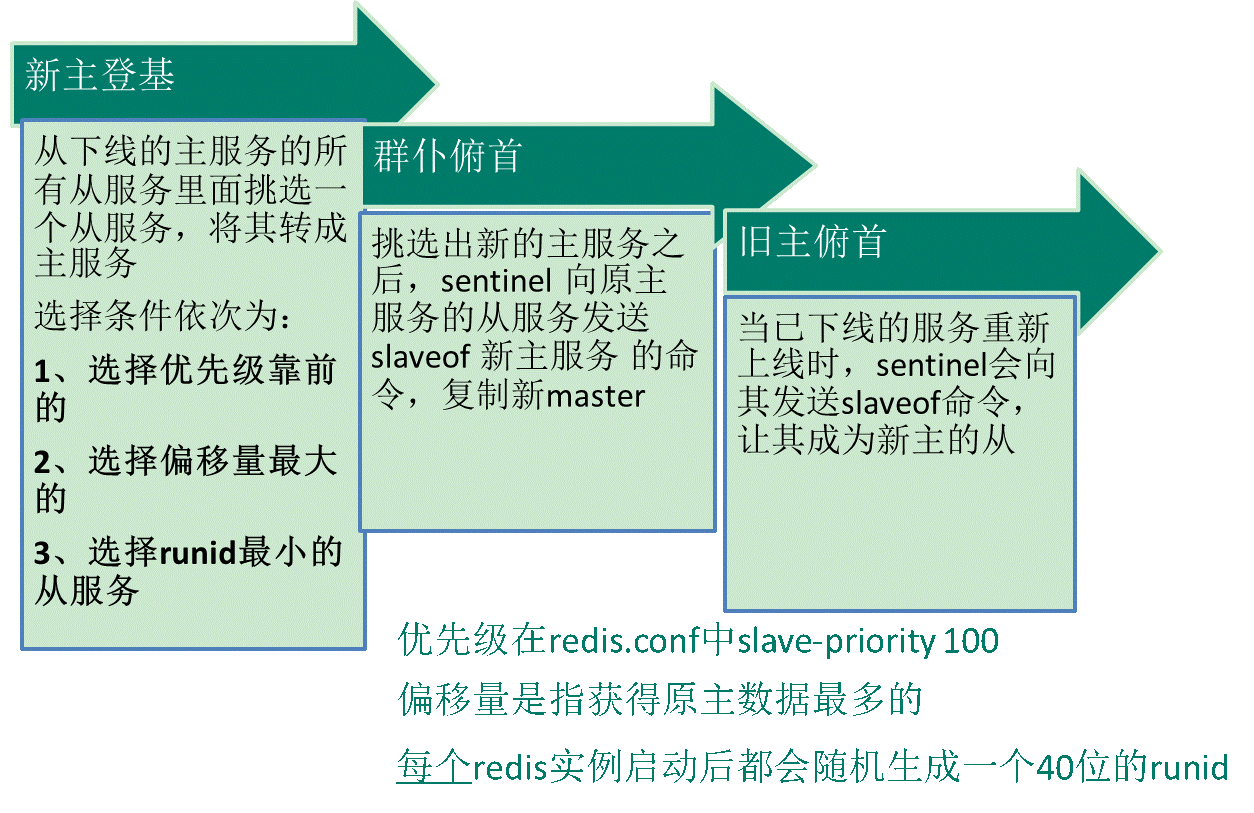
-
故障转移:如果Master异常,则会进行Master-Slave切换,将其中一个Slave作为Master,将之前的Master作为Slave(如果重启成功 )
-
消息通知:如果某个 Redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
-
配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并不能保证数据不丢失,但是可以保证集群的高可用
多个哨兵,不仅同时监控主从状态,且哨兵之间也互相监控!
下线:
①主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。
②客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover.
工作原理:
-
①每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令 ;
-
②如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线;
-
③如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态;
-
④当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 ;
-
⑤在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
-
⑥当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 ;
-
⑦若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的主观下线状态就会被移除;
-
若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的客观下线状态就会被移除
总结
好了,今天的文章就结束了,我们从互联网的架构演变来看各个组件服务的需求,从而引出了NoSQL。Redis作为当前缓存服务器的弄潮儿,我们从Redis的官网介绍分析了redis的特点,也给出了Redis安装的示例以及我们一般关注的配置参数的作用。接着从Redis的持久化了解了RDB持久化方式特点以及其优缺点、AOF持久化机理 与优缺点。接着对于Redis的主从复制以及事务了解了Redis的高可用,了解了哨兵模式的背景和机制。部分操作文章没有列出,因为觉得官网已经很详尽了,另外菜鸟教程网站对于命令也算详尽就没有重复列出。建议大家手动在Linux环境下安装redis,眼过千遍不如手敲一遍。
我是清风,希望这篇文章对你有帮助,怕什么真理无穷,进一寸有一寸的欢喜。奥利给。

