

阅读目录
内容回顾
标准三流
logging模块
re模块
##内容回顾
# random: random() randint() choice() sample() # 序列化:对象需要持久化存储或传送 对象 => 字符串 # json: 用于传输 # -- 1.支持{} [] int float bool str null # -- 2.是{}与[]的嵌套组合,最外层只能由一个根:要么所有数据由{}起始包裹,要么由[]起始包裹,就是单一1支持的类型数据 # -- 3.字符串必须由""包裹 # pickle: 用于存储,支持所有数据类型,采用二进制进行操作 # 序列化:dump dumps # 反序列化:load loads # shelve: 采用字典形式进行序列化与反序列化 shv_dic = shelve.open('序列化文件') # 序列化 shv_dic[key] = value # 反序列化 shv_dic[key] # open('序列化文件', writeback=True) 可以是序列化的值为可变类型,更新其值,能实时同步到文件 # shutil:操作文件与文件夹的模块 # 加密:碰撞解密 # hashlib:lock_obj = hashlib.md5('创建对象时的数据可有可无') # hmac: lock_obj = hmac.new('必须提前给数据') # 更新加密的数据:lock_obj.update('二进制的数据'.encode('utf-8')) # 获取加密结果:lock_obj.hexdigest()
##标准三流
import sys # sys.stdin:input的底层 res = sys.stdin.readline() # sys.stdout:print的底层 sys.stdout.write('输出的信息\n') # sys.stderr:异常及logging默认打印方式的底层 sys.stderr.write('输出的信息\n')
##logging模块
# 操作日志的模块 # 日志:日常的流水,将程序运行过程中的状态或数据进行记录,一般都是记录到日志文件中 # 在正常的项目中,项目运行的一些打印信息,采用loging打印到文件中,这个过程就称之为 记录日志 #日志级别 CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置 import logging # logging为默认打印者,名字叫root,配置采用以下方式 h1 = logging.StreamHandler() h2 = logging.FileHandler('d.log') logging.basicConfig( # filename='my.log', # filemode='w', # stream=sys.stderr, # 往控制台打印采用具体的输出流 format='%(asctime)s [%(levelname)s]- %(name)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S', level=logging.DEBUG, # 10, 代表DEBUG及DEBUG级别以上都能输出 handlers=[h1, h2] ---同时输出到控制台和文件 ) logging.debug("debug") logging.info("info") logging.warning("warning") logging.error("error") logging.critical("critical")
##logging四大成员
# 1.新建打印者 logger = logging.getLogger("Owen") # 2.创建句柄:输出的位置 stream_handler = logging.StreamHandler() a_file_handler = logging.FileHandler('a.log',encoding='utf-8')#可以指定编码,不然中文写到文件中会出现乱码 b_file_handler = logging.FileHandler('b.log') # 3.打印者绑定句柄 logger.addHandler(stream_handler) logger.addHandler(a_file_handler) logger.addHandler(b_file_handler) # 4.设置格式 fmt1 = logging.Formatter('%(asctime)s - %(msg)s') fmt2 = logging.Formatter('%(asctime)s [%(name)s] - %(msg)s') # 5.为句柄绑定输出格式 stream_handler.setFormatter(fmt1) a_file_handler.setFormatter(fmt1) b_file_handler.setFormatter(fmt2) logger.critical('msg')
##
1.由logger 产生日志 -> 2.交给过滤器判断是否被过滤 -> 3.将日志消息分发给绑定的所有处理器 -> 4处理器按照绑定的格式化对象输出日志
其中 第一步 会先检查日志级别 如果低于设置的级别则不执行
第二步 使用场景不多 需要使用面向对象的技术点 后续用到再讲
第三步 也会检查日志级别,如果得到的日志低于自身的日志级别则不输出
```
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要注意的是
生成器的级别应低于句柄否则给句柄设置级别是没有意义的,
例如 handler设置为20 生成器设置为30
30以下的日志压根不会产生
```
第四步 如果不指定格式则按照默认格式
##多个输出者
import logging # 1.创建logger log1 = logging.getLogger('Owen') log2 = logging.getLogger('Zero') r_log = logging # 2.logger设置级别 log1.setLevel(logging.DEBUG) # 3.设置句柄 h1 = logging.StreamHandler() # 4.设置句柄级别: # 1)系统句柄默认级别warning, # 2)自定义的句柄级别默认同logger,也可以在logger基础上在加以限制 h1.setLevel(logging.DEBUG) # 5.logger添加句柄 log1.addHandler(h1) # log1可以打印DEBUG以上的信息,但往不同位置打印,采用不同句柄的二次级别限制 h2 = logging.FileHandler('c.log') h2.setLevel(logging.WARNING) log1.addHandler(h2) log1.debug('debug') log1.info('info') log1.warning('warning') log1.error('error') log1.critical('critical') log2.critical('00000') r_log.critical('00000')
##通过字典配置日志文件的使用(重点会用)
##1-------单一文件模式(不建议)
# 1.配置 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'o_fmt1': { 'format': '%(name)s:%(asctime)s - %(message)s' }, 'o_fmt2': { 'format': '%(name)s:%(asctime)s [%(levelname)s] - %(message)s' } }, 'filters': {}, 'handlers': { 'o_cmd': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', 'formatter': 'o_fmt1' }, 'o_file': { 'level': 'WARNING', 'class': 'logging.handlers.RotatingFileHandler', 'formatter': 'o_fmt2', 'filename': r'F:\python8期\课堂内容\day20\代码\part4\logging.log', # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, #日志文件最大个数 'encoding': 'utf-8', # 日志文件的编码 } }, 'loggers': { 'o_owen': { 'level': 'DEBUG', 'handlers': ['o_cmd', 'o_file'] }, 'o_zero': { 'level': 'DEBUG', 'handlers': ['o_file'] } } } # 2.加载配置 import logging.config logging.config.dictConfig(LOGGING_DIC) # 3.使用 log = logging.getLogger('o_owen') log.warning('123')
##2、一个项目形式(常用)
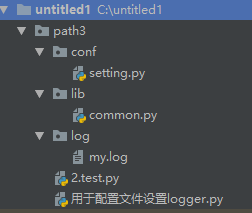
#setting.py import os import sys BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(__file__))) # print(BASE_DIR) sys.path.append(BASE_DIR) LOG_DIR = os.path.join(BASE_DIR, 'path3', 'log') MY_LOG = os.path.join(LOG_DIR, 'my.log') # print(MY_LOG) LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': True, 'formatters': { 'o_fmt1': { 'format': '%(name)s:%(asctime)s - %(message)s' }, 'o_fmt2': { 'format': '%(name)s:%(asctime)s [%(levelname)s] - %(message)s' } }, 'filters': {}, 'handlers': { 'o_cmd': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', 'formatter': 'o_fmt1' }, 'o_file': { 'level': 'WARNING', 'class': 'logging.handlers.RotatingFileHandler', 'formatter': 'o_fmt2', 'filename': MY_LOG, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, #日志文件最大个数 'encoding': 'utf-8', # 日志文件的编码 } }, 'loggers': { 'o_owen': { 'level': 'DEBUG', 'handlers': ['o_cmd', 'o_file'] }, 'o_zero': { 'level': 'DEBUG', 'handlers': ['o_cmd', 'o_file'] } } } #common.py # 提供共有资源的模块----让执行文件调用接口对setting文件进行访问 import logging import logging.config from path3.conf import setting def fn(): print(setting.LOGGING_DIC) # fn() # import logging.config def getLogger(name): logging.config.dictConfig(setting.LOGGING_DIC) logger = logging.getLogger(name) return logger #用于配置文件设置logger.py -------用于执行,会调用common文件-----在调用setting文件 import os import sys BASE_DIR = os.path.dirname(os.path.dirname(__file__)) sys.path.append(BASE_DIR) from path3.lib import common # common.fn() o_log = common.getLogger('o_owen') o_log.debug('owen打印的debug信息') o_log.warning('aaaa')
#2.test.py ----调用公告文件common.py-----日志文件会写到my.log文件中
from path3.lib import common
# log = common.getLogger('o_owen')
# log.warning('1234')
log1 = common.getLogger('o_zero')
log1.critical('严重警告')
##配置文件优化
注意注意注意: #1、有了上述方式我们的好处是:所有与logging模块有关的配置都写到字典中就可以了,更加清晰,方便管理 #2、我们需要解决的问题是: 1、从字典加载配置:logging.config.dictConfig(settings.LOGGING_DIC) 2、拿到logger对象来产生日志 logger对象都是配置到字典的loggers 键对应的子字典中的 按照我们对logging模块的理解,要想获取某个东西都是通过名字,也就是key来获取的 于是我们要获取不同的logger对象就是 logger=logging.getLogger('loggers子字典的key名') 但问题是:如果我们想要不同logger名的logger对象都共用一段配置,那么肯定不能在loggers子字典中定义n个key 'loggers': { 'l1': { 'handlers': ['default', 'console'], # 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, 'l2: { 'handlers': ['default', 'console' ], 'level': 'DEBUG', 'propagate': False, # 向上(更高level的logger)传递 }, 'l3': { 'handlers': ['default', 'console'], # 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, } #我们的解决方式是,定义一个空的key 'loggers': { '': { 'handlers': ['default', 'console'], 'level': 'DEBUG', 'propagate': True, }, } 这样我们再取logger对象时 logging.getLogger(__name__),不同的文件__name__不同,这保证了打印日志时标识信息不同,但是拿着该名字去loggers里找key名时却发现找不到,于是默认使用key=''的配置 !!!关于如何拿到logger对象的详细解释!!!
##re模块
# 正则:是有语法的字符串,用来匹配目标字符串的 # 将目标字符串中的所以数字找出 data = '123abc呵呵' res = re.findall(r'\d', data) # \d就代表数字 print(res) # ['1', '2', '3']
##re单个字符
# re.I不区分大小写的匹配 print(re.findall(r'a', 'abc123嘿嘿abcABC', flags=re.I)) # ['a', 'a', 'A'] # a|b a或b单个字符 print(re.findall(r'a|b', 'abc123嘿嘿abcABC', flags=re.I)) # ['a', 'b', 'a', 'b', 'A', 'B'] # [a,b] a或,或b单个字符 print(re.findall(r'[a,b]', 'abc,123嘿嘿abcABC', flags=re.I)) # ['a', 'b', ',', 'a', 'b', 'A', 'B'] # [^ab]非a及非b的所有单个字符 print(re.findall(r'[^ab]', 'abc,123嘿嘿abcABC')) # ['c', ',', '1', '2', '3', '嘿', '嘿', 'c', 'A', 'B', 'C'] # [a-z]所有单个小写字母 [A-Z]所有单个大写字母 [0-9]所有单个数字 print(re.findall(r'[a-z]', 'abc,123嘿嘿abcABC')) # ['a', 'b', 'c', 'a', 'b', 'c'] print(re.findall(r'[0-9]', 'abc,123嘿嘿abcABC')) # ['1', '2', '3'] # 所有小写大写数字单个字符 print(re.findall(r'[a-z]|[A-Z]|[0-9]', 'abc,123嘿嘿abcABC')) # ['a', 'b', 'c', '1', '2', '3', 'a', 'b', 'c', 'A', 'B', 'C'] print(re.findall(r'[A-Za-z0-9]', 'abc,123嘿嘿[abcABC')) # ['a', 'b', 'c', '1', '2', '3', 'a', 'b', 'c', 'A', 'B', 'C'] # .会匹配除\n以为的所有单个字符 print(re.findall(r'.', '*\_+=\n \r\t')) # ['*', '\\', '_', '+', '=', ' ', '\r', '\t'] # re.S会让.能匹配所有单个字符 print(re.findall(r'.', '*\_+=\n \r\t', flags=re.S)) # ['*', '\\', '_', '+', '=', '\n', ' ', '\r', '\t'] # \d单个数字 == [0-9] print(re.findall(r'\d', 'abc,123嘿嘿[abcABC')) # ['1', '2', '3'] # \w == [A-Za-z0-9_] 将常见的汉字就理解为单个字母 print(re.findall(r'\w', 'abc,123嘿[_')) # ['a', 'b', 'c', '1', '2', '3', '嘿', '_'] # \s == [\f\n\r\t\v ] 单个空:空格、制表符、换页符等 print(re.findall(r'\s', '\f\n\r\t\v ')) # ['\x0c', '\n', '\r', '\t', '\x0b', ' '] # \D就是\d的对立面:非数字的所有单个字符 \W就是\w的对立面 \S就是\s的对立面 print(re.findall(r'\D', 'abc,123嘿[_')) # ['a', 'b', 'c', ',', '嘿', '[', '_'] # 单个汉字 [\u4e00-\u9fa5] print(re.findall(r'[\u4e00-\u9fa5]', 'abc,123嘿[_')) # ['嘿'] # 建议使用 [0-9] [A-Za-z0-9_] [\f\n\r\t\v ] [^0-9] [\u4e00-\u9fa5] # 不建议使用 \d \w \s \D \w
##正则匹配步骤
import re # 1.将r'\\'的正则语法字符串转换成 正则对象 '\', 用来匹配 '\' 字符的 # 2.拿着转换后的正则对象,来匹配目标字符串 print(re.findall(r'\\', r'a\d\p\\')) # ['\\', '\\', '\\', '\\'] re_obj = re.compile(r'\n') # 转换成匹配 换行符 的正则对象 res = re_obj.findall('\n') print(res) # ['\n'] re_obj = re.compile(r'\\d') # 转换成匹配 \d 的正则对象 res = re_obj.findall('\d') print(res) # ['\\d'] re_obj = re.compile(r'\d') # 转换成匹配 数字 的正则对象 res = re_obj.findall('\d') # \d不是数字 print(res) # [] re_obj = re.compile(r'\\n') # 转换成匹配 \n 的正则对象 res = re_obj.findall('\n') # 代表换行,不能被匹配 print(res) # [] res = re_obj.findall(r'\n') # 就代表\n,能被匹配 print(res) # ['\\n']
##多个字符
# 明确个数的重复 # {n} print(re.findall(r'a', 'aaabbb')) # ['a', 'a', 'a'] print(re.findall(r'a{2}', 'aaabbb')) # ['aa'] print(re.findall(r'ab', 'aabbababab')) # ['ab', 'ab', 'ab', 'ab'] print(re.findall(r'a{2}b{2}', 'aabbababab')) # ['aabb'] print(re.findall(r'ab{2}', 'aabbababab')) # ['abb'] # {n,} 匹配n到无数个,题中最少匹配abb, 贪婪匹配 abbb 能被匹配为 abb 和 abbb,优先匹配多的 print(re.findall(r'ab{2,}', 'ababbabbbabbbb')) # ['abb', 'abbb', 'abbbb'] # {,n} 匹配0到n个,ab{,2} 优先匹配abb,没有ab也行,如果还没有a也将就 print(re.findall(r'ab{,2}', 'aababbabbbabbbb')) # ['a', 'ab', 'abb', 'abb', 'abb'] # {n,m} 匹配n到m个,ab{1,3} 优先匹配 abbb,再考虑abb, ab print(re.findall(r'ab{1,3}', 'aababbabbbabbbb')) # ['ab', 'abb', 'abbb', 'abbb'] # 特殊符号的重复 # *: 匹配0到无数个 print(re.findall(r'ab*', 'aababbabbbabbbb')) # ['a', 'ab', 'abb', 'abbb', 'abbbb'] # +: 匹配1到无数个 print(re.findall(r'ab+', 'aababbabbbabbbb')) # ['ab', 'abb', 'abbb', 'abbbb'] # ?: 匹配0到1个 print(re.findall(r'ab?', 'aababbabbbabbbb')) # ['a', 'ab', 'ab', 'ab', 'ab'] # 需求:匹配所以单词 print(re.findall(r'[a-z]+', 'abc def hello print')) # ['abc', 'def', 'hello', 'print'] print(re.findall(r'[a-z]+\b', 'abc def hello print')) # ['abc', 'def', 'hello', 'print'] # \b代表单词边界,用空格(字符串的结尾也包括)作为匹配规则 print(re.findall(r'[a-z]*c', 'abc def hello print acb zc')) # ['abc', 'ac', 'zc'] print(re.findall(r'[a-z]*c\b', 'abc def hello print acb zc')) # ['abc', 'zc']
##多行匹配
import re s = """http://www.baidu.com https://sina.com.cn https://youku.com haam abchttp://www.oldboy.com """ # ^代表以什么开头,$代表以什么结尾,必须结合flags=re.M来完成多行匹配 print(re.findall(r'^http.+com$', s, re.M)) # ['http://www.baidu.com', 'https://youku.com']
##分组
import re url = 'https://www.baidu.com, http://www.youku.com' # 需求:拿到url的域名的 baidu , youku print(re.findall(r'www.([a-z]+).com', url)) # ['baidu', 'youku'] # ()代表分组 # findall匹配,如果匹配规则用有分组语法,只存放分组结果 print(re.findall(r'(www).([a-z]+).com', url)) # [('www', 'baidu'), ('www', 'youku')] # 分组的编号:分组的顺序编号按照左括号的前后顺序 print(re.findall(r'(((w)ww).([a-z]+).com)', url)) # [('www.baidu.com', 'www', 'w', 'baidu'), ('www.youku.com', 'www', 'w', 'youku')] # findall是全文匹配,可以从任意位置开始,匹配多次 # match非全文匹配,必须从头开始匹配,只能匹配一次 # 专门处理分组的方法:分组,分组编号,有名分组,取消分组 # 取消分组: 必须写(),但是()为分组语法,我们只是想通过()将一些数据作为整体,所以()必须,再取消分组即可 # (?:) 取消分组只是作为整体 (?P<名字>) 有名分组 url = 'www.baidu.com,www.youku.com' res = re.match(r'((?:www).(?P<name>[a-z]+).com)', url) # print(res) # <_sre.SRE_Match object; span=(0, 13), match='www.baidu.com'> print(res.group(1)) # www.baidu.com print(res.group(2)) # baidu print(res.group('name')) # baidu
##拆分与替换
import re s = 'a b ac def' print(s.split(' ')) # ['a', 'b', 'ac', 'def'] # 正则拆分 s = 'a b,ac@def' print(re.split(r'[ ,@]', s)) # ['a', 'b', 'ac', 'def'] s = 'python abc python' print(re.sub('python', 'Python', s)) # Python abc Python print(re.sub('python', 'Python', s, count=1)) # Python abc python # 结合分组可以完成信息的重组与替换 s = 'day a good!!!' # 'a good good day' print(re.sub('(day) (a) (good)', r'today is \2 \3 \3 \1', s))
##非贪婪匹配
'''非贪婪匹配:尽可能少的匹配 {n,}? {,n}? {n,m}? *? +? ?? ''' # 应用场景: 正则一定会有首尾标识,中间匹配的结果会有非贪婪匹配的语法 s = '<a>abc</a><a></a>' # 匹配标签 print(re.findall(r'<.*>', s)) # ['<a>abc</a><a></a>'] print(re.findall(r'<.*?>', s)) # ['<a>', '</a>', '<a>', '</a>'] # 匹配标签的内容 print(re.findall(r'<a>(.*)</a>', s)) # ['abc</a><a>'] print(re.findall(r'<a>(.*?)</a>', s)) # ['abc', '']
print(re.findall(r'ab{0,}', 'aababbabbb')) # ['a', 'ab', 'abb', 'abbb']
print(re.findall(r'ab{0,}?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab{0,}?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab{,3}', 'aababbabbb')) # ['a', 'ab', 'abb', 'abbb']
print(re.findall(r'ab{,3}?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab{,3}?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab{1,3}', 'aababbabbb')) # ['ab', 'abb', 'abbb']
print(re.findall(r'ab{1,3}?', 'aababbabbb')) # ['ab', 'ab', 'ab']
print(re.findall(r'ab{1,3}?', 'aababbabbb')) # ['ab', 'ab', 'ab']
print(re.findall(r'ab*', 'aababbabbb')) # ['a', 'ab', 'abb', 'abbb']
print(re.findall(r'ab*?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab*?', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab+', 'aababbabbb')) # ['ab', 'abb', 'abbb']
print(re.findall(r'ab+?', 'aababbabbb')) # ['ab', 'ab', 'ab']
print(re.findall(r'ab+?', 'aababbabbb')) # ['ab', 'ab', 'ab']
print(re.findall(r'ab?', 'aababbabbb')) # ['a', 'ab', 'ab', 'ab']
print(re.findall(r'ab??', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'ab??', 'aababbabbb')) # ['a', 'a', 'a', 'a']
print(re.findall(r'', '')) # ['']
print(re.findall(r'a{0}', 'a')) # ['', '']
# 非贪婪匹配结合单个匹配结果是没有任何意义的
print(re.findall(r'b*?', 'bbbbbbbb'))
print(re.findall(r'(?:ab)*?', 'bbbbbbbb'))
print(re.findall(r'b*?', 'bbbbbbbb'))
print(re.findall(r'(?:ab)*?', 'bbbbbbbb'))
# 非贪婪匹配的应用场景,正则一定会有首尾标识,中间匹配的结果会有非贪婪匹配的语法
s = '<a>abc</a><a></a>'
print(re.findall(r'<.*>', s)) # ['<a>abc</a><a></a>']
print(re.findall(r'<.*?>', s)) # ['<a>', '</a>', '<a>', '</a>']
s = '<a>abc</a><a></a>'
print(re.findall(r'<.*>', s)) # ['<a>abc</a><a></a>']
print(re.findall(r'<.*?>', s)) # ['<a>', '</a>', '<a>', '</a>']
print(re.findall(r'<a>(.*)</a>', s)) # ['abc</a><a>']
print(re.findall(r'<a>(.*?)</a>', s)) # ['abc', '']
print(re.findall(r'<a>(.*?)</a>', s)) # ['abc', '']
