Transformer结构与源码详细分析(Pytorch版)
Transformer是 Google 在2017年由论文《Attention is All You Need》提出的一个新模型,Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了6层 Encoder-Decoder 结构。它的结构如下图。
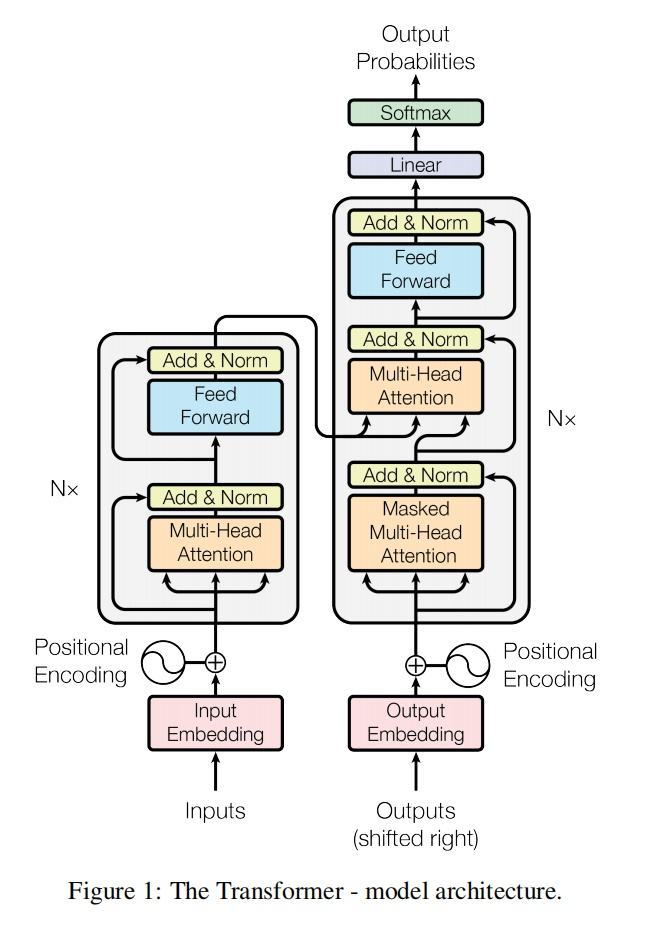
本文将以机器翻译为例子介绍Transformer的工作流程
1. Transformer整体网络结构
整体的网络结构分为编码器、解码器和输出层;输入数据包括编码器的输入enc_inputs(即待翻译的句子)、解码器的输入dec_inputs(即翻译句子的标签数据)。enc_inputs的数据形状为[batch_size, src_len],dec_inputs的数据形状为[batch_size, tgt_len],其中src_len和tgt_len分别为编码器和解码器输入序列的长度。
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## 编码层
self.decoder = Decoder() ## 解码层
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) ## 输出层 d_model 是我们解码层每个token输出的维度大小
## 之后会做一个 tgt_vocab_size 大小的softmax
def forward(self, enc_inputs, dec_inputs):
## 这里有两个数据进行输入,一个是enc_inputs 形状为[batch_size, src_len],主要是作为编码段的输入
## 一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入。
## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,想要什么指定输出什么
## 可以是全部tokens的输出,可以是特定每一层的输出;也可以是中间某些参数的输出。
## enc_outputs就是主要的输出,enc_self_attns这里没记错的是QK转置相乘之后softmax之后的矩阵值,代表的是每个单词和其他单词相关性;
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
## dec_outputs 是decoder主要输出,用于后续的linear映射;
## dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性;
## dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
## dec_outputs做映射到词表大小
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
2. 编码器部分(Encoder)
Encoder部分包含三个部分:词嵌入(word embedding),位置嵌入,注意力层及后续的前馈神经网络;数据经过word embedding和position embedding后的维度是[batch_size, src_len, embedding_dim],其中embedding_dim为嵌入的维度。embedding层后的编码器部分通常由6个编码器层堆叠成,返回的数据包括编码后的结果以及注意力得分。
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) ## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model
self.pos_emb = PositionalEncoding(d_model) ## 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;
def forward(self, enc_inputs):
## 这里我们的 enc_inputs 形状是: [batch_size x source_len]
## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model]
enc_outputs = self.src_emb(enc_inputs)
## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
## 去看EncoderLayer 层函数 5.
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
3. 位置嵌入(position embedding)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;
## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;
## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127
## 假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,补长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,补长为2,其实代表的就是奇数位置
## 上面代码获取之后得到的pe:[max_len*d_model]
## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号