python找到文件特定内容的位置:pandas包的loc和index
pandas包提供了数据读取的方法,上一篇内容介绍了用pandas.read_csv函数读取文件的选项。(链接https://www.cnblogs.com/liangxuran/p/13544390.html)
本文介绍读取文件后如何锁定特定内容的位置(行号)。
输入文件
输入文件是reskb0(注意pandas.read_csv不仅能读取.csv文件,也可以读取.txt文件,甚至没有后缀名的文件)
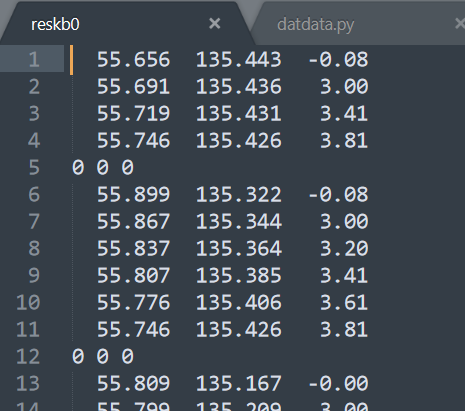
该文件有三列数据,数据之间用空格分割,分别代表射线路径中每个节点的纬(p)经(r)深(h)度。
不同射线之间用“0 0 0”间隔。部分数据截图如下:
程序目标
为锁定所有“0 0 0”字段的行号,以下程序提供了两种方法.loc方法和.index方法
1 import pandas as pd 2 import numpy as np 3 4 file_in = "reskb0" #输入文件 5 6 #使用panda中的read_csv读取txt文件 7 #type(pd_data)=<class 'pandas.core.frame.DataFrame'> 8 pd_data=pd.read_csv(file_in,delim_whitespace=True,names='prh') 9 10 #方法1:使用.loc定位 11 pd_pos =pd_data.loc[(pd_data['p']==0)&(pd_data['r']==0)&(pd_data['h']==0)] 12 print('1st way:',pd_pos.shape,type(pd_pos)) 13 14 #方法2:使用.index定位 15 pd_loc =pd_data[(pd_data.p==0)&(pd_data.r==0)&(pd_data.h==0)].index 16 print('2nd way:',pd_loc.shape,type(pd_loc))
输出结果
![]()
输出结果表面,第一种方法用.loc返回的数据类型是pandas.core.frame.DataFrame,第二种方法用.index返回的数据类型是pandas.core.indexs.numeric.Int64Index
后期还可以用“list=pd_data.tolist()”将pandas数据变为列表
本文来自博客园,作者:Philbert,转载请注明原文链接:https://www.cnblogs.com/liangxuran/p/13616458.html
