python写入二维netCDF文件(txt转nc文件)
netCDF文件后缀名是.nc,是一种二进制的网格文件,无法直接打开,下面给出基于python的netCDF文件生成的脚本。
(该程序目前已发布更新版本,链接是https://www.cnblogs.com/liangxuran/p/13659283.html)
输入数据说明:
数据为31°N-40°N,130°E-142°E区域表层的地震波速,网格分布大小不均匀。数据存储在txt文件中,分为三列,无表头。
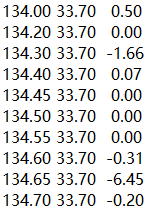
部分数据记录见下图,第一列是经度,第二列是维度,第三列是波速扰动值%
过程与代码
为了将其生成均匀网格的二维nc文件,我们需要1.文件读取,2.数据插值,3.写入nc文件。

1 ''' 2 program: ncdata.py 3 goal: interpolate txt data and generate grd file 4 input: vp1_02.txt 5 output: vp1_03.nc 6 author: Liang Xuran 7 e-mail: xuranliang@hotmail.com 8 time: 2020.08.23 9 ''' 10 import netCDF4 as nc 11 import pandas as pd 12 import numpy as np 13 import copy 14 15 file_txt = "vp1_02.txt"#txt文件位置 16 file_nc = "vp1_03.nc" #nc文件输出位置 17 npa = 37 #纬向格点数(uninpolate) 18 nra = 45 #经向格点数(uninpolate) 19 npx = 180 #纬向格点数(inpolate) 20 nrx = 240 #经向格点数(inpolate) 21 22 #使用Dataset创建nc文件 23 nc_pro = nc.Dataset("vp1_03.nc", 'w', format = 'NETCDF4') 24 25 #命名nc文件变量,None为自由维度,name='pna',size=npa 26 nc_pro.createDimension('pna',npx+1) 27 nc_pro.createDimension('rna',nrx+1) 28 29 #设置nc文件中变量类型,这里使用的是float64 30 pna = nc_pro.createVariable('pna',np.float64,('pna',)) 31 rna = nc_pro.createVariable('rna',np.float64,('rna',)) 32 dv = nc_pro.createVariable('dv',np.float64,('pna','rna')) 33 34 #定义变量单位 35 pna.units = 'degree' 36 rna.units = 'degree' 37 dv.units = '%' 38 39 #使用panda中的read_csv读取txt文件 40 #type(nc_data)=<class 'pandas.core.frame.DataFrame'> 41 nc_data=pd.read_csv("vp1_02.txt",delim_whitespace=True,names='rpv') 42 43 #插值操作:精度0.05degree,范围rna=130:142;pna=31:40 44 pnx = nc_data['p'].values[0:1665:nra] 45 rnx = nc_data['r'].values[0:nra] 46 dvx = nc_data['v'].values.reshape(npa,nra) 47 rx = np.linspace(130,142,241) 48 px = np.linspace(31,40,181) 49 vx = np.full([181,241],np.nan) 50 for i in range(npa): 51 for j in range(nra): 52 m = int(round((pnx[i]-pnx[0])/0.05)) 53 n = int(round((rnx[j]-rnx[0])/0.05)) 54 vx[m,n]=dvx[i,j] 55 #纵向插值,从vx[181,241]获得中间量dv_inpolate1[181,241] 56 nc_v_uninpo = pd.DataFrame(vx) #transfer np.array into pandas.DataFrame 57 nc_v_inpo1 = nc_v_uninpo.interpolate() #pandas.DataFrame interpolate 58 dv_inpolate1 = nc_v_inpo1.values #tansfer pandas.DataFrame into np.array 59 #横向插值,从dv_inpolate1[181,241]获得中间量dv_inpolate2[181,241] 60 nc_v_inpo = pd.DataFrame(dv_inpolate1.T) 61 nc_v_inpo2 = nc_v_inpo.interpolate() 62 dv_inpolate2 = nc_v_inpo2.values.T 63 64 #将数值输入到nc文件中,input must be np.array 65 nc_pro.variables['pna'][:] = px 66 nc_pro.variables['rna'][:] = rx 67 nc_pro.variables['dv'][:,:] = dv_inpolate2[:,:] 68 #为避免内存的占用,写完一个关闭一个 69 nc_pro.close() 70
踩坑指南:
1.文件路径最好写相对路径,第15-16行写绝对路径/mnt/f/research/vp1_02.txt会出现报错。
2.插值前后格点数量有所扩充,由于经纬度的变量检索是从0开始的,因此,26-27行创建变量的维度需要加1,也可以定位None,代表自由维度。
3.元组只有一个元素时,需要在括号末尾加“,”,例如30-31行。
4.用pandas.read_csv读取文件时,第41行,默认数据之间时用“,”逗号连接的,需要修改默认值delim_whitespace代表用空格连接。names代表每一列的元素名称。
5.二维数据pandas.DataFrame进行赋值/输出内容时,需要使用其values属性,例如44-46行。在插值过程中,也需要将numpy.array矩阵转为pandas.DataFrame网格后进行,例如55-62行。
6.nc文件的变量被赋值的时候,只接受numpy.array数据,例如65-67行;二维的numpy.array数据索引是一个中括号而不是两个中括号[0:181,0:241],例如54行和67行。
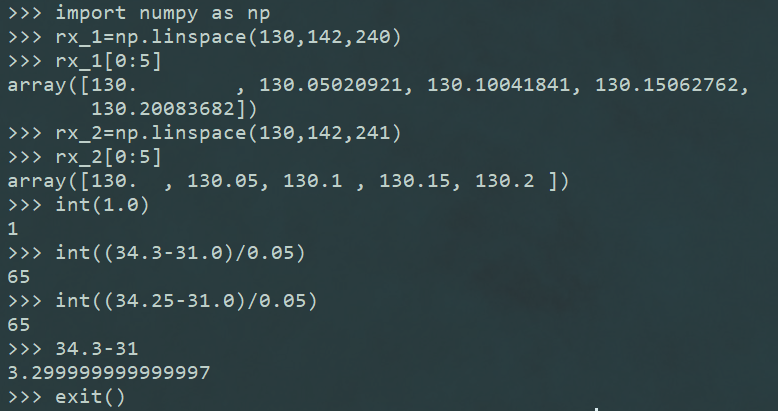
7.python的浮点型数据和整形数据加减运算的时候要小心,例如52-53行计算mn的时候,出现了以下现象:
8.关于变量的索引和插值前后数据的对比检验。可以参考下图:
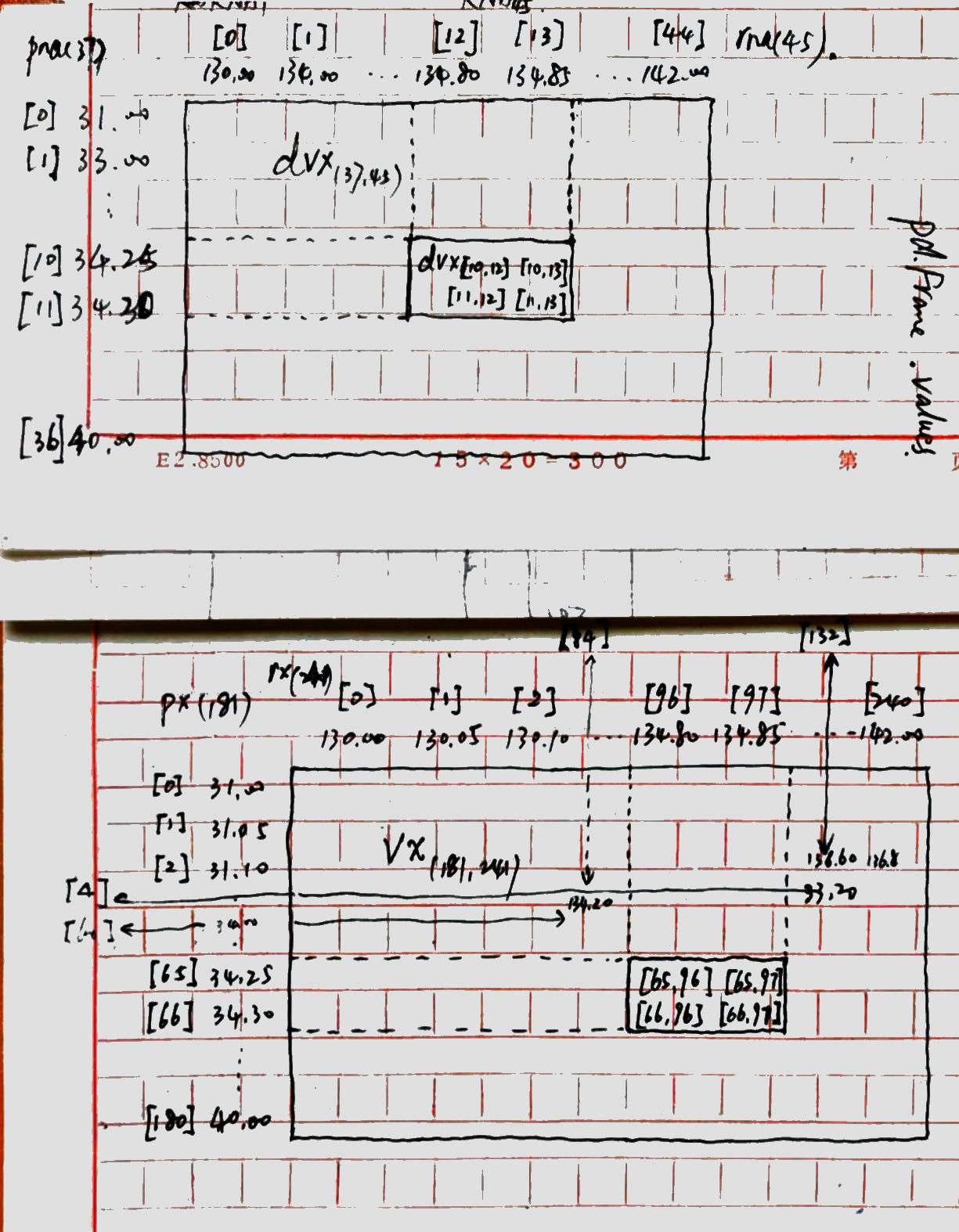
检验未插值部分的数据,选择34.25°N-34.30°N,134.80°E-134.85°E区域: dvx[10:12,12:14] vx[65:67,96:98]
检验已插值部分的数据,选择33.2°N-33.4°N,136.6°E-136.8°E的区域: dvx[2:4,41:43] vx[4:9,132:137]
本文来自博客园,作者:Philbert,转载请注明原文链接:https://www.cnblogs.com/liangxuran/p/13551134.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现