lxml beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路。太菜了,若有错误的地方,欢迎大家随时指正。。。。。。。(come on.......)
爬取网页数据一般会经过 获取信息->提取信息->保存信息 这三个步骤。而解析库的使用,则可以帮助我们快速的提取出我们需要的那被部分信息,免去了写复杂的正则表达式的麻烦。在使用解析库的时候,个人理解也会有三个步骤 建立文档树->搜索文档树->获取属性和文本 。
建立文档树:就是把我们获取到的网页源码利用解析库进行解析,只有这样,后面才能使用这个解析库的方法。
搜索文档树:就是在已经建立的文档树里面,利用标签的属性,搜索出我们需要的那部分信息,比如一个包含一部分网页内容的div标签,一个ul标签等。
获取索性和文本:在上一步的基础上,进一步获取到具体某个标签的文本或属性,比如一个a标签的href属性,title属性,或它的文本。
先来介绍lxml,这个库用到了 Xpath 语法,不过在Google里可以直接copy某个元素的xpath路径,非常的方便。
首先,定义一个html的字符串,用它来模拟已经获取到的网页源码



html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> '''
1.建立文档树:在获取到网页源码后,只需要使用etree的HTML方法,就可以把复杂的html建立成 一棵文档树了
from lxml import etree xpath_tree = etree.HTML(html)
这里首先导入lxml库的etree模块,然后声明了一段HTML文本,调用HTML类进行初始化,这样就成功构造了一个XPath解析对象。可以使用type查看一下xpath_tree的类型,是这样的 <class 'lxml.etree._Element'>
2.搜索文档树:先看一下xpath几个常用的规则
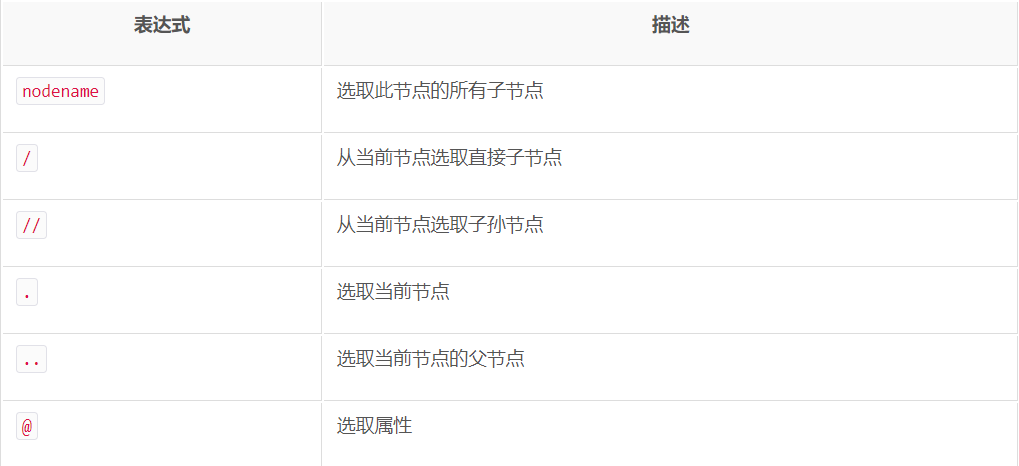
(1)从整个文档树中搜索标签:一般会用//开头的XPath规则来选取所有符合要求的节点。这里以前面的HTML文本为例。例如搜索 ul 标签
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('ul') //括号里面也可以是元素的xpath路径,在google里复制过来粘贴就行 3 print(result) 4 print(type(result)) 5 print(type(result[0]))
输出结果如下:
[<Element ul at 0x2322b7e8608>, <Element ul at 0x2322b7e8648>]
<class 'list'>
<class 'lxml.etree._Element'>
上面第二行代码表示从整个文档树中搜索出所有的ul标签,可以看到,返回结果是一个列表,里面的每个元素都是lxml.etree._Element类型,当然,也可以对这个列表进行一个遍历,然后对每个lxml.etree._Element对象进行操作。
(2)搜索当前节点的子节点:比如,找到每一个ul标签里面的 li 标签:
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li') 5 print(li_list)
输出结果如下:
[<Element li at 0x23433127748>, <Element li at 0x23433127788>, <Element li at 0x23433127a88>, <Element li at 0x23433127988>, <Element li at 0x23433127ac8>]
[<Element li at 0x23433127cc8>, <Element li at 0x23433127d08>, <Element li at 0x23433127d48>, <Element li at 0x23433127d88>, <Element li at 0x23433127dc8>]
第四行代码表示,选取当前的这个ul标签,并获取到它里面的所有li标签。
(3)根据属性过滤:如果你需要根据标签的属性进行一个过滤,则可以这样来做
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 print(li_list)
输出结果如下:
[<Element li at 0x15c436695c8>, <Element li at 0x15c436698c8>]
[<Element li at 0x15c43669988>, <Element li at 0x15c436699c8>]
与之前的代码相比,旨在第四行的后面加了 [@class="item-0"] ,它表示找到当前ul标签下所有class属性值为item-0的li标签,当然,也可以在整个文档树搜索某个标签时,在标签后面加上某个属性,进行过滤,下面例子中有用到
(4)获取文本:获取具体某个标签的文本内容
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./text()'))
输出结果如下:
['first item']
[]
['first item']
[]
首先,在第二行的ul标签后面加了属性过滤,但因为两个ul标签的class属性值都是list,所以结果没加之前是一样的。然后又加了一个for循环,用来获取列表里面每一个元素的文本,因为第二个li标签里面没有文本内容,所以是空
(5)获取属性:获取具体某个标签的某个属性内容
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./@class'))
输出结果如下:
['item-0']
['item-0']
['item-0']
['item-0']
把第六行的text()方法换成@符号,并在后面加上想要的属性,就获取到了该属性的属性值。
这是xpath这个解析库基本的使用方法,也有一些没说到的地方,大家可以看一下大佬的文章。https://cuiqingcai.com/5545.html
另外两个解析库,放在后面两篇随笔里面
beautifulsoup解析库:https://www.cnblogs.com/liangxiyang/p/11302525.html
pyquery解析库:https://www.cnblogs.com/liangxiyang/p/11303142.html
*************************不积跬步,无以至千里。*************************


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· autohue.js:让你的图片和背景融为一体,绝了!
· 10亿数据,如何做迁移?